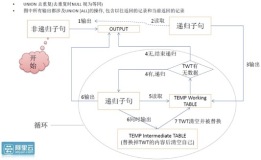
背景
PolarDB 的云原生存算分离架构, 具备低廉的数据存储、高效扩展弹性、高速多机并行计算能力、高速数据搜索和处理; PolarDB与计算算法结合, 将实现双剑合璧, 推动业务数据的价值产出, 将数据变成生产力.
本文将介绍PolarDB结合图式算法, 实现高效率的刑侦、社交、风控、族谱、推荐等业务图谱类关系数据搜索.
age是什么
https://age.apache.org/age-manual/master/intro/overview.html
Apache AGE is a PostgreSQL extension that provides graph database functionality. AGE is an acronym for A Graph Extension, and is inspired by Bitnine’s fork of PostgreSQL 10, AgensGraph, which is a multi-model database. The goal of the project is to create single storage that can handle both relational and graph model data so that users can use standard ANSI SQL along with openCypher, the Graph query language.
简单来说就是一个支持图式数据和搜索的多模数据库插件.
将age整合到PolarDB
https://age.apache.org/age-manual/master/intro/setup.html
https://age.apache.org/download
https://github.com/apache/age/tree/release/1.1.0
下载最新分支并安装
git clone --branch release/1.1.0 --depth 1 https://github.com/apache/age
cd age
git branch
* release/1.1.0
which pg_config
~/tmp_basedir_polardb_pg_1100_bld/bin/pg_config 修复代码错误, 原因是RTE解析未兼容.
USE_PGXS=1 PG_CONFIG=~/tmp_basedir_polardb_pg_1100_bld/bin/pg_config make
报错如下:
src/backend/parser/cypher_analyze.c: In function ‘convert_cypher_walker’:
src/backend/parser/cypher_analyze.c:178:17: error: ‘QTW_EXAMINE_RTES’ undeclared (first use in this function); did you mean ‘QTW_EXAMINE_RTES_AFTER’?
178 | flags = QTW_EXAMINE_RTES | QTW_IGNORE_RT_SUBQUERIES |
| ^~~~~~~~~~~~~~~~
| QTW_EXAMINE_RTES_AFTER
src/backend/parser/cypher_analyze.c:178:17: note: each undeclared identifier is reported only once for each function it appears in
make: *** [<builtin>: src/backend/parser/cypher_analyze.o] Error 1 原因如下:
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=18c0da88a5d9da566c3bfac444366b73bd0b57da
Split QTW_EXAMINE_RTES flag into QTW_EXAMINE_RTES_BEFORE/_AFTER.
This change allows callers of query_tree_walker() to choose whether
to visit an RTE before or after visiting the contents of the RTE
(i.e., prefix or postfix tree order). All existing users of
QTW_EXAMINE_RTES want the QTW_EXAMINE_RTES_BEFORE behavior, but
an upcoming patch will want QTW_EXAMINE_RTES_AFTER, and it seems
like a potentially useful change on its own.
Andreas Karlsson (extracted from CTE inlining patch)
Discussion: https://postgr.es/m/8810.1542402910@sss.pgh.pa.us https://git.postgresql.org/gitweb/?p=postgresql.git;a=blobdiff;f=src/include/nodes/nodeFuncs.h;h=a9f76bbb330a3a271363be317fd8caea3e09fe7d;hp=7739600db26e55628778d93d1e2a3833d90954d9;hb=18c0da88a5d9da566c3bfac444366b73bd0b57da;hpb=ff750ce2d82979e9588c629955e161a9379b05f3
-#define QTW_EXAMINE_RTES 0x10 /* examine RTEs */
-#define QTW_DONT_COPY_QUERY 0x20 /* do not copy top Query */
+#define QTW_EXAMINE_RTES_BEFORE 0x10 /* examine RTE nodes before their
+ * contents */
+#define QTW_EXAMINE_RTES_AFTER 0x20 /* examine RTE nodes after their
+ * contents */
+#define QTW_DONT_COPY_QUERY 0x40 /* do not copy top Query */ 修复如下:
cd age
vi src/backend/parser/cypher_analyze.c
/*
* QTW_EXAMINE_RTES
* We convert RTE_FUNCTION (cypher()) to RTE_SUBQUERY (SELECT)
* in-place.
*
* QTW_IGNORE_RT_SUBQUERIES
* After the conversion, we don't need to traverse the resulting
* RTE_SUBQUERY. However, we need to traverse other RTE_SUBQUERYs.
* This is done manually by the RTE_SUBQUERY case above.
*
* QTW_IGNORE_JOINALIASES
* We are not interested in this.
*/
// flags = QTW_EXAMINE_RTES | QTW_IGNORE_RT_SUBQUERIES |
flags = QTW_EXAMINE_RTES_BEFORE | QTW_IGNORE_RT_SUBQUERIES |
QTW_IGNORE_JOINALIASES; 以上参考12分支:
https://github.com/apache/age/blob/release/PG12/1.1.0/src/backend/parser/cypher_analyze.c
/*
* QTW_EXAMINE_RTES
* We convert RTE_FUNCTION (cypher()) to RTE_SUBQUERY (SELECT)
* in-place.
*
* QTW_IGNORE_RT_SUBQUERIES
* After the conversion, we don't need to traverse the resulting
* RTE_SUBQUERY. However, we need to traverse other RTE_SUBQUERYs.
* This is done manually by the RTE_SUBQUERY case above.
*
* QTW_IGNORE_JOINALIASES
* We are not interested in this.
*/
flags = QTW_EXAMINE_RTES_BEFORE | QTW_IGNORE_RT_SUBQUERIES |
QTW_IGNORE_JOINALIASES; 修复后继续安装即可
USE_PGXS=1 PG_CONFIG=~/tmp_basedir_polardb_pg_1100_bld/bin/pg_config make
USE_PGXS=1 PG_CONFIG=~/tmp_basedir_polardb_pg_1100_bld/bin/pg_config make install 使用age
postgres=# LOAD 'age';
LOAD
postgres=# SET search_path = ag_catalog, "$user", public;
SET
-- 以上也可以根据需要配置到数据库参数postgresql.conf 中, 即自动加载age:
-- #shared_preload_libraries = '' # (change requires restart)
-- #local_preload_libraries = ''
-- #session_preload_libraries = ''
-- #search_path = '"$user", public' # schema names
postgres=# create extension age ;
CREATE EXTENSION 一些图式查询语法例子
postgres=# SELECT * FROM ag_catalog.create_graph('graph_name');
NOTICE: graph "graph_name" has been created
create_graph
--------------
(1 row)
postgres=# SELECT *
postgres-# FROM cypher('graph_name', $$
postgres$# RETURN 1
postgres$# $$) AS (int_result agtype);
int_result
------------
1
(1 row)
postgres=# SELECT *
postgres-# FROM cypher('graph_name', $$
postgres$# WITH [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] as lst
postgres$# RETURN lst
postgres$# $$) AS (lst agtype);
lst
------------------------------------
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
(1 row)
postgres=# SELECT *
postgres-# FROM cypher('graph_name', $$
postgres$# WITH {listKey: [{inner: 'Map1'}, {inner: 'Map2'}], mapKey: {i: 0}} as m
postgres$# RETURN m.listKey[0]
postgres$# $$) AS (m agtype);
m
-------------------
{"inner": "Map1"}
(1 row)
postgres=# SELECT *
postgres-# FROM cypher('graph_name', $$
postgres$# WITH {id: 0, label: "label_name", properties: {i: 0}}::vertex as v
postgres$# RETURN v
postgres$# $$) AS (v agtype);
v
------------------------------------------------------------------
{"id": 0, "label": "label_name", "properties": {"i": 0}}::vertex
(1 row)
postgres=# SELECT *
postgres-# FROM cypher('graph_name', $$
postgres$# WITH {id: 2, start_id: 0, end_id: 1, label: "label_name", properties: {i: 0}}::edge as e
postgres$# RETURN e
postgres$# $$) AS (e agtype);
e
--------------------------------------------------------------------------------------------
{"id": 2, "label": "label_name", "end_id": 1, "start_id": 0, "properties": {"i": 0}}::edge
(1 row)
postgres=# SELECT *
postgres-# FROM cypher('graph_name', $$
postgres$# WITH [{id: 0, label: "label_name_1", properties: {i: 0}}::vertex,
postgres$# {id: 2, start_id: 0, end_id: 1, label: "edge_label", properties: {i: 0}}::edge,
postgres$# {id: 1, label: "label_name_2", properties: {}}::vertex
postgres$# ]::path as p
postgres$# RETURN p
postgres$# $$) AS (p agtype);
p
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------
[{"id": 0, "label": "label_name_1", "properties": {"i": 0}}::vertex, {"id": 2, "label": "edge_label", "end_id": 1, "start_id": 0, "properties": {"i": 0}}::edge, {"id": 1, "label": "label_name_2", "prop
erties": {}}::vertex]::path
(1 row)
postgres=# WITH graph_query as (
postgres(# SELECT *
postgres(# FROM cypher('graph_name', $$
postgres$# MATCH (n)
postgres$# RETURN n.name, n.age
postgres$# $$) as (name agtype, age agtype)
postgres(# )
postgres-# SELECT * FROM graph_query;
name | age
------+-----
(0 rows)
postgres=# SELECT *
postgres-# FROM cypher('graph_name', $$
postgres$# MATCH (n)
postgres$# RETURN n.name
postgres$# ORDER BY n.name
postgres$# SKIP 3
postgres$# $$) as (names agtype);
names
-------
(0 rows) 更多用法请参考age文档:
https://age.apache.org/age-manual/master/intro/overview.html