Syslog是一个常见的日志通道,几乎所有的SIEM(例如IBM Qradar, HP Arcsight)都支持通过Syslog渠道接收日志。本文主要介绍如何通过Syslog将日志服务中的日志投递到SIEM。
背景
Syslog主要是基于RFC5424和RFC3164定义相关格式规范,RFC3164协议是2001年发布的,RFC5424协议是2009年发布的升级版本。因为新版兼容旧版,且新版本解决了很多问题,因此推荐使用RFC5424协议。更多信息,请参见RFC5424和RFC3164。
Syslog over TCP/TLS:Syslog只规定日志格式,理论上TCP和UDP都支持Syslog,可以较好的保证数据传输稳定性。RFC5425协议也定义了TLS的安全传输层,如果您的SIEM支持TCP通道或者TLS通道,则建议优先使用。更多信息,请参见RFC5425。
Syslog facility:早期Unix定义的程序组件,此处选择user作为默认组件。更多信息,请参见程序组件。
Syslog severity:定义日志级别,您可以根据需求设置指定内容的日志为较高的级别。默认一般用info。更多信息,请参见日志级别。
投递流程
推荐使用日志服务消费组构建程序来进行实时消费,消费程序可以托管在ECS主机或者容器环境,然后通过Syslog over TCP/TLS来发送日志给SIEM,流程如下。
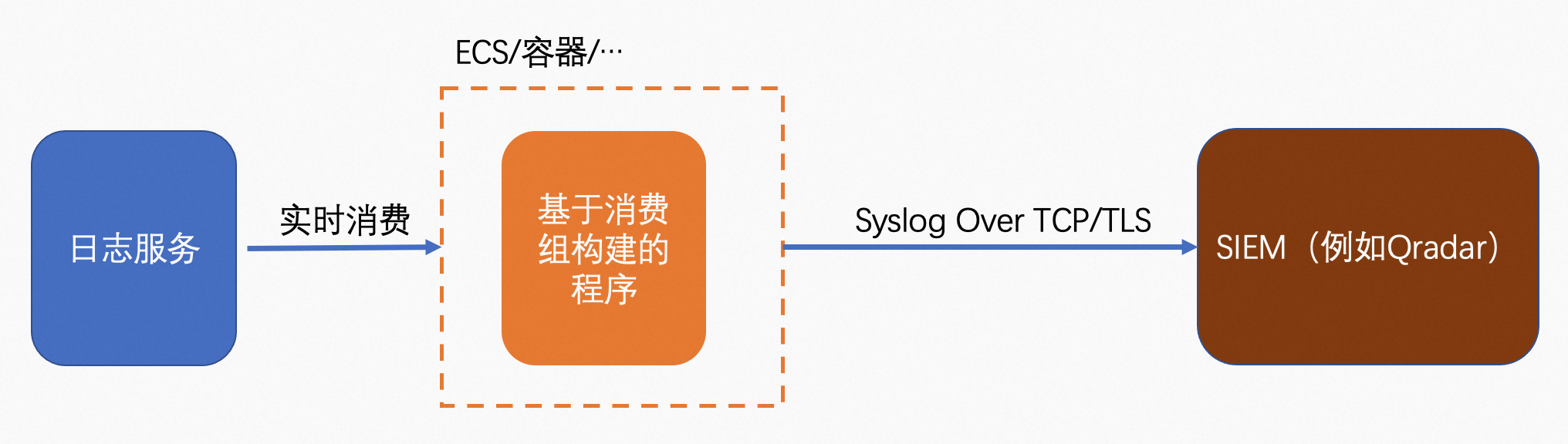
投递示例
本文以SLS的Logstore为数据源,通过Python的方式实现消费组,并使用Syslog协议投递到SIEM平台,本文选择的SIEM平台是IBM Qradar。
投递过程
编写消费组代码
创建项目目录qradar-demo
mkdir qradar-demo
创建index.py,并复制如下代码
其中大部分代码参考自通过Syslog投递日志到SIEM,做了部分修改,包括环境变量和注释,用户也可以根据注释,自行修改其中的配置。
# -*- coding: utf-8 -*-
import os
import logging
import threading
import six
from datetime import datetime
from logging.handlers import RotatingFileHandler
from multiprocessing import current_process
from aliyun.log import PullLogResponse
from aliyun.log.consumer import LogHubConfig, CursorPosition, ConsumerProcessorBase, ConsumerWorker
from aliyun.log.ext import syslogclient
from pysyslogclient import SyslogClientRFC5424 as SyslogClient
user = logging.getLogger()
handler = RotatingFileHandler("{0}_{1}.log".format(os.path.basename(__file__), current_process().pid),
maxBytes=100 * 1024 * 1024, backupCount=5)
handler.setFormatter(logging.Formatter(
fmt='[%(asctime)s] - [%(threadName)s] - {%(module)s:%(funcName)s:%(lineno)d} %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'))
user.setLevel(logging.INFO)
user.addHandler(handler)
user.addHandler(logging.StreamHandler())
logger = logging.getLogger(__name__)
def get_option():
##########################
# 基本选项
##########################
# 从环境变量中加载日志服务参数与选项。
endpoint = os.environ.get('SLS_ENDPOINT', '')
accessKeyId = os.environ.get('SLS_AK_ID', '')
accessKey = os.environ.get('SLS_AK_KEY', '')
project = os.environ.get('SLS_PROJECT', '')
logstore = os.environ.get('SLS_LOGSTORE', '')
consumer_group = os.environ.get('SLS_CG', '')
syslog_server_host = os.environ.get('SYSLOG_HOST', '')
syslog_server_port = int(os.environ.get('SYSLOG_PORT', '514'))
syslog_server_protocol = os.environ.get('SYSLOG_PROTOCOL', 'tcp')
# 消费的起点。这个参数在首次运行程序的时候有效,后续再次运行时将从上一次消费的保存点继续消费。
# 可以使用“begin”、“end”,或者特定的ISO时间格式。
cursor_start_time = "2023-03-15 0:0:0"
##########################
# 高级选项
##########################
# 一般不要修改消费者名称,尤其是需要并发消费时。
consumer_name = "{0}-{1}".format(consumer_group, current_process().pid)
# 心跳时长,当服务器在2倍时间内没有收到特定Shard的心跳报告时,服务器会认为对应消费者离线并重新调配任务。
# 所以当网络环境不佳的时候,不建议将时长设置的比较小。
heartbeat_interval = 20
# 消费数据的最大间隔,如果数据生成的速度很快,不需要调整这个参数。
data_fetch_interval = 1
# 构建一个消费组和消费者
option = LogHubConfig(endpoint, accessKeyId, accessKey, project, logstore, consumer_group, consumer_name,
cursor_position=CursorPosition.SPECIAL_TIMER_CURSOR,
cursor_start_time=cursor_start_time,
heartbeat_interval=heartbeat_interval,
data_fetch_interval=data_fetch_interval)
# syslog options
settings = {
"host": syslog_server_host, # 必选
"port": syslog_server_port, # 必选,端口
"protocol": syslog_server_protocol, # 必选,TCP、UDP或TLS(仅Python3)。
"sep": "||", # 必选,key=value键值对的分隔符,这里用双竖线(||)分隔。
"cert_path": None, # 可选,TLS的证书位置。
"timeout": 120, # 可选,超时时间,默认120秒。
"facility": syslogclient.FAC_USER, # 可选,可以参考其他syslogclient.FAC_*的值。
"severity": syslogclient.SEV_INFO, # 可选,可以参考其他syslogclient.SEV_*的值。
"hostname": "aliyun.example.com", # 可选,机器名,默认选择本机机器名。
"tag": "tag" # 可选,标签,默认是短划线(-)。
}
return option, settings
class SyncData(ConsumerProcessorBase):
"""
消费者从日志服务消费数据并发送给Syslog server。
"""
def __init__(self, target_setting):
"""初始化并验证Syslog server连通性。"""
super(SyncData, self).__init__()
assert target_setting, ValueError("You need to configure settings of remote target")
assert isinstance(target_setting, dict), ValueError(
"The settings should be dict to include necessary address and confidentials.")
self.option = target_setting
self.protocol = self.option['protocol']
self.timeout = int(self.option.get('timeout', 120))
self.sep = self.option.get('sep', "||")
self.host = self.option["host"]
self.port = int(self.option.get('port', 514))
self.cert_path = self.option.get('cert_path', None)
# try connection
client = SyslogClient(self.host, self.port, proto=self.protocol)
def process(self, log_groups, check_point_tracker):
logs = PullLogResponse.loggroups_to_flattern_list(log_groups, time_as_str=True, decode_bytes=True)
logger.info("Get data from shard {0}, log count: {1}".format(self.shard_id, len(logs)))
try:
client = SyslogClient(self.host, self.port, proto=self.protocol)
for log in logs:
# suppose we only care about audit log
timestamp = datetime.fromtimestamp(int(log[u'__time__']))
del log['__time__']
io = six.StringIO()
# 可以根据需要修改格式化内容,这里使用Key=Value传输,并使用默认的双竖线(||)进行分割。
for k, v in six.iteritems(log):
io.write("{0}{1}={2}".format(self.sep, k, v))
data = io.getvalue()
# 可以根据需要修改facility或者severity。
client.log(data,
facility=self.option.get("facility", None),
severity=self.option.get("severity", None),
timestamp=timestamp,
program=self.option.get("tag", None),
hostname=self.option.get("hostname", None))
except Exception as err:
logger.debug("Failed to connect to remote syslog server ({0}). Exception: {1}".format(self.option, err))
# 需要添加一些错误处理的代码,例如重试或者通知等。
raise err
logger.info("Complete send data to remote")
self.save_checkpoint(check_point_tracker)
def main():
option, settings = get_option()
logger.info("*** start to consume data...")
worker = ConsumerWorker(SyncData, option, args=(settings,))
worker.start(join=True)
if __name__ == '__main__':
main()
在qradar-demo目录下执行依赖安装
cd qradar-demo
pip install aliyun-log-python-sdk -t .
pip install pysyslogclient -t .并发运行程序
配置环境变量
SLS_AK_ID: SLS的AccessKeyId,具有消费Logstore的权限
SLS_AK_KEY: SLS的AccessKeySecret,具有消费Logstore的权限
SLS_CG:消费Logstore数据的消费组名称,例如qradar_demo_cg
SLS_ENDPOINT:SLS的Project的Endpoint,如果ECS与SLS的Project在同一个地域,可以使用内网域名。
SLS_PROJECT:SLS的Project名称
SLS_LOGSTORE:SLS的Logstore名称
SYSLOG_HOST:Syslog的Host
SYSLOG_PORT:Syslog的端口,默认为514
SYSLOG_PROTOCOL:Syslog的协议,默认为tcp.
export SLS_ENDPOINT=<Endpoint of your region>
export SLS_AK_ID=<YOUR AK ID>
export SLS_AK_KEY=<YOUR AK KEY>
export SLS_PROJECT=<SLS Project Name>
export SLS_LOGSTORE=<SLS Logstore Name>
export SLS_CG=<消费组名,可以简单命名为"syc_data">
export SYSLOG_HOST=<syslog 服务端的Host>
export SYSLOG_PORT=<syslog 服务端端口,默认为514>
export SYSLOG_PROTOCOL=<syslog 协议,默认为tcp>启动消费程序
基于上述消费组的程序,可以直接启动多个进程并发消费。
cd qradar-demo
nohup python3 index.py &
nohup python3 index.py &
nohup python3 index.py &IBM Qradar查看结果
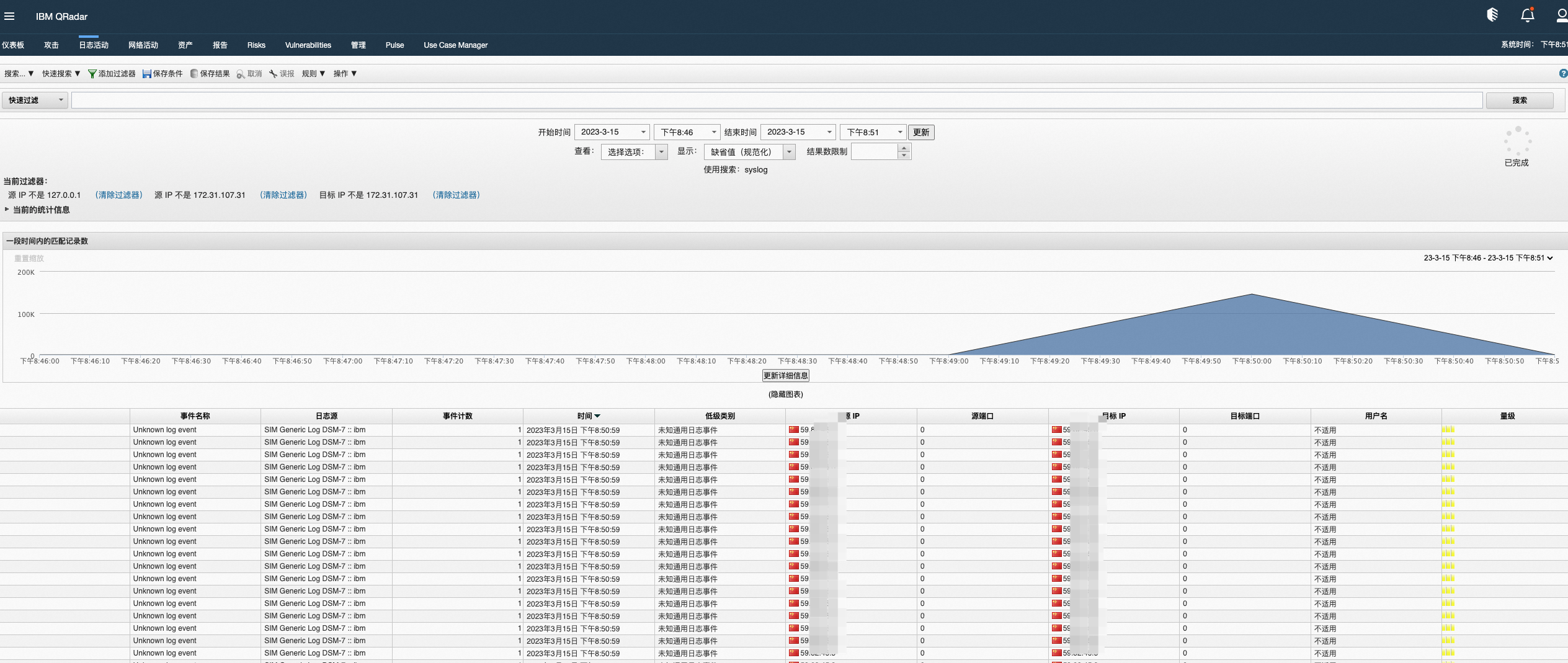
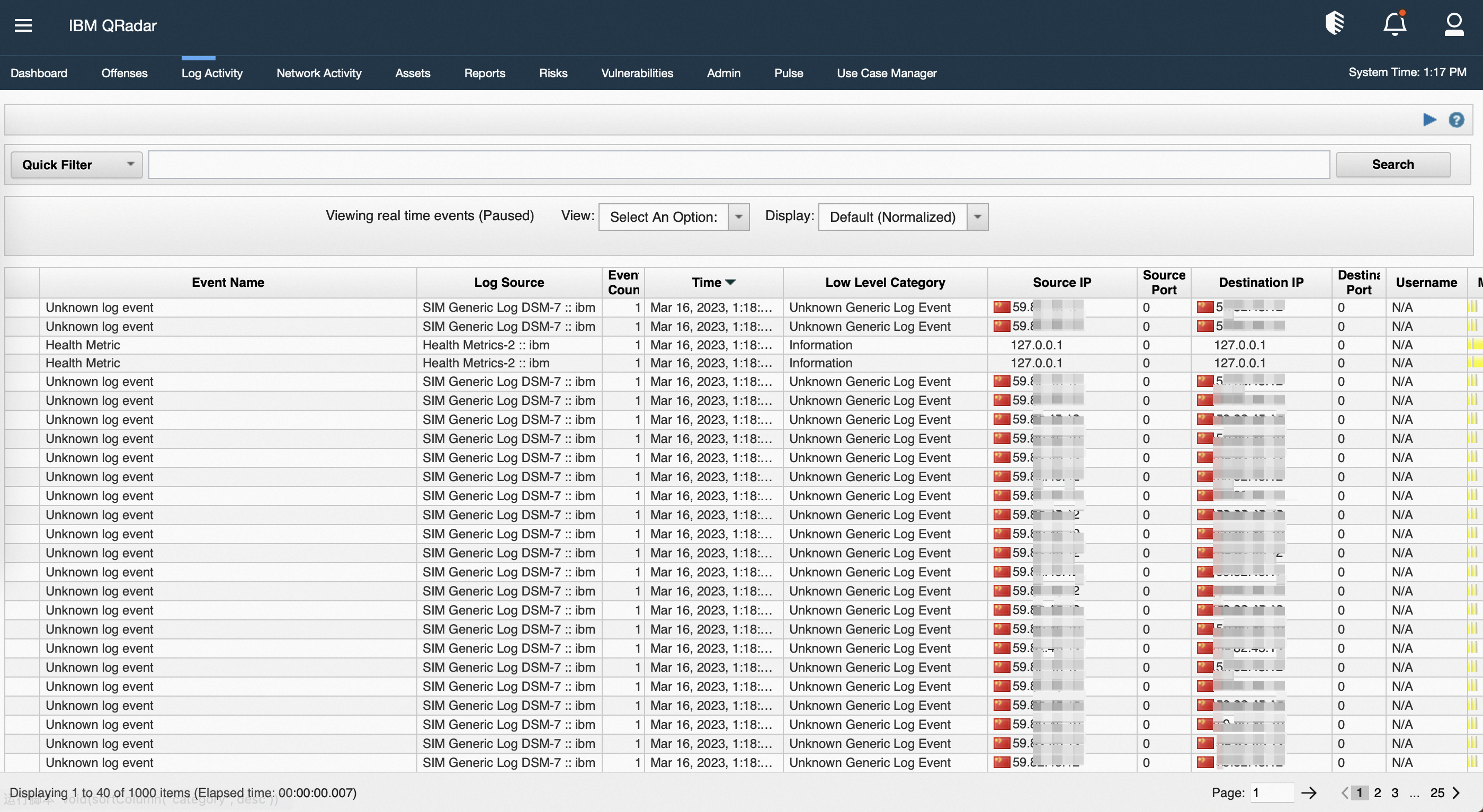
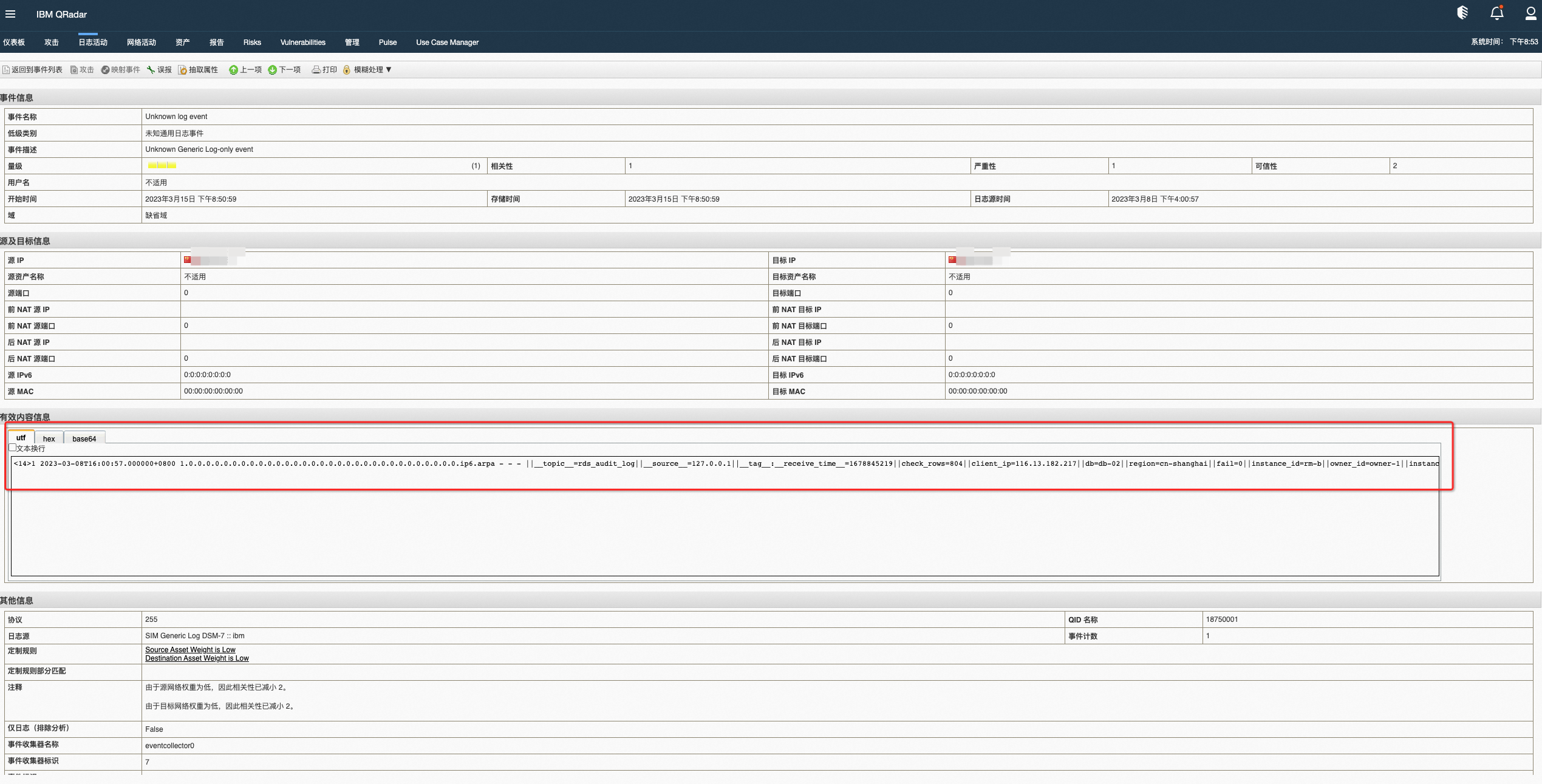
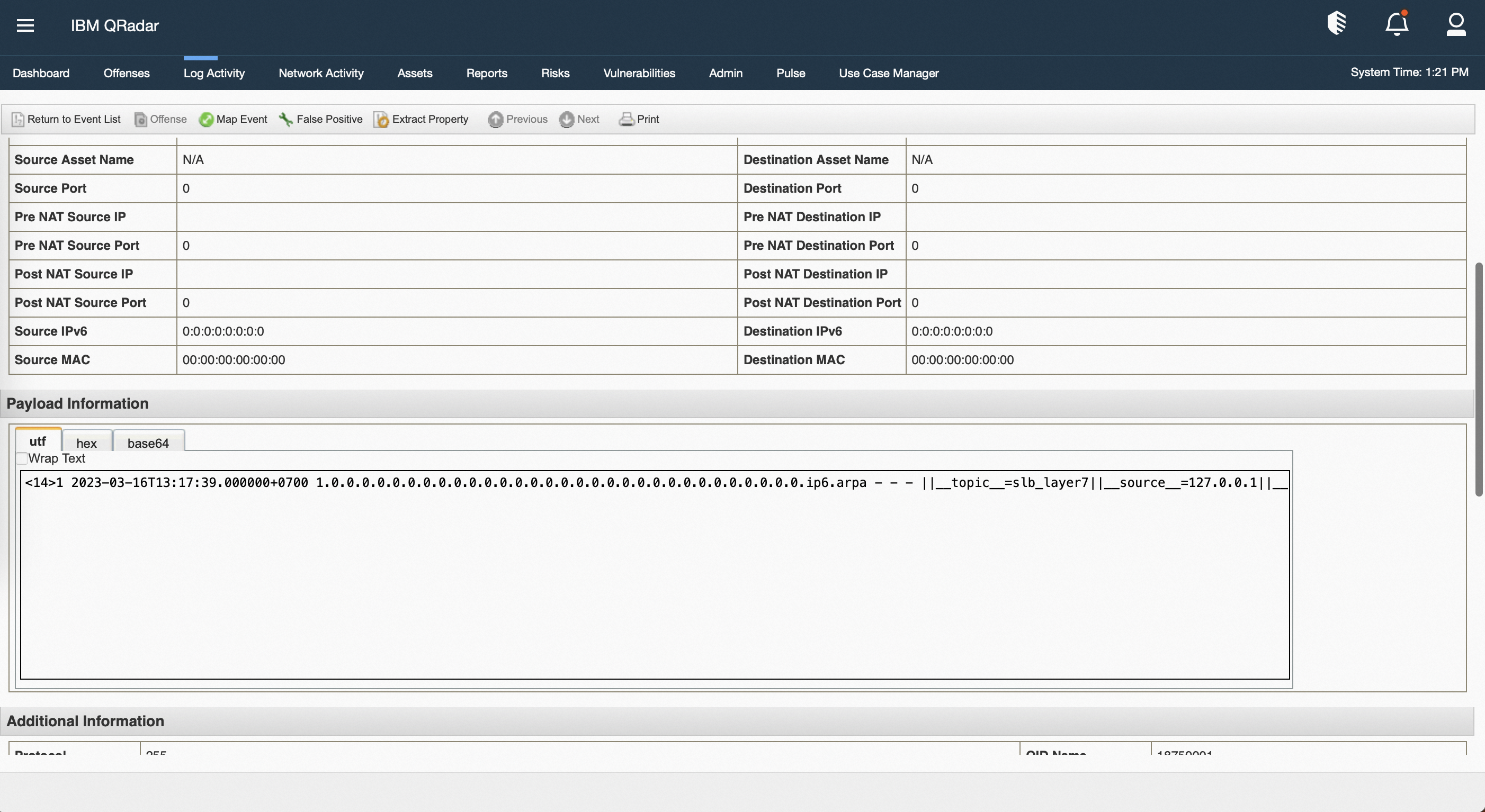
双击事件条目可以查看详情,文中以模拟的rds审计日志为例查看。
吞吐量
在python 3运行示例的情况下,单个消费组大约占用20%的单核CPU,消费可以达到10MB/s的原始日志消费速率,10个消费者并行理论上可以达到100MB/s的原始日志,每个CPU核每天可以消费0.9TB原始日志。
高可用
断点续传:消费组将检测点(check-point)保存在服务器端,当一个消费者停止,另外一个消费者将自动接管并从断点继续消费。可以在不同机器上启动消费者,这样在一台机器停止或者损坏的情况下,其他机器上的消费者可以自动接管并从断点进行消费。为了备用,也可以通过不同机器启动大于Shard数量的消费者。
进程守护:为了保证python程序的高可用,可以使用守护进程程序supervisor对python消费者进行守护,当进程因为各种原因崩溃时,会自动重新启动程序。
Shard变化自适应
Logstore使用Shard来控制读写能力,根据实际日志的数据量,可能需要进行Shard的分裂、合并等操作,本文程序的原理是使用消费组来消费日志,本质上是根据Shard在消费数据,在Shard数量变化时,消费组SDK会自动探测到Shard的变化,调整对Shard的消费。
总结
本文主要参考自SLS文档:通过Syslog投递日志到SIEM实现,其中程序的托管在了阿里云ECS,完成了对SLS的Logstore数据进行消费,并且通过Syslog协议投递到IBM Qradar。可以使用守护程序supervisor进行程序保护,也可以将程序部署在容器环境实现弹性高可用。