
CoreDNS是集群中的默认DNS Server,集群中Service和集群外域名的解析全部需要通过CoreDNS完成。CoreDNS的服务不可用会严重影响集群内的其他服务。在不同场景中,CoreDNS性能和可用性的要求有所区别,默认配置无法适配所有场景。请根据实际业务场景,采用本文中的建议对CoreDNS组件进行配置。
影响评估
在非托管模式下,CoreDNS如同集群中的其他工作负载,其可用性与性能取决于Pod数量、资源限制、调度策略、节点分布等因素。
在高负载或配置不当的情况下,都会直接影响集群的DNS服务质量。CoreDNS可能面临两类主要问题:
可用性问题:
配置不正确的情况下,无法实现节点级和可用区级的高可用,形成单点故障风险。
资源不足引发Pod被驱逐,服务中断。
性能问题:
与同节点工作负载资源争用,响应延迟增加。
节点负载过高导致网络I/O丢包,从而导致DNS请求失败。
调整CoreDNS Pod数量
由于UDP报文缺少重传机制,当集群节点存在IPVS UDP缺陷导致的丢包风险时,CoreDNS Pod的缩容或重启可能会导致长达五分钟的整个集群域名解析超时或异常。关于IPVS缺陷导致解析异常的解决方案,请参见DNS解析异常问题排查。
请勿使用工作负载自动伸缩:虽然工作负载自动伸缩,例如容器水平伸缩(HPA)、容器定时水平伸缩(CronHPA)等也可以自动调整Pod数量,但是它们会频繁执行扩缩容。由于Pod缩容时导致的解析异常,请勿使用工作负载自动伸缩控制CoreDNS Pod数量。
评估组件压力
包括DNSPerf在内的许多开源工具可评估集群内的整体DNS压力。如果无法准确评估,推荐参照下方的标准:
在任何情况下,建议设置CoreDNS Pod数应至少为2,单个Pod的资源limit不小于1核1G。
CoreDNS所能提供的域名解析QPS与CPU消耗成正相关,使用NodeLocal DNSCache的情况下,每CPU核可以支撑10000+ QPS的域名解析请求。不同类型的业务对域名请求的QPS需求存在较大差异,可以观察每个CoreDNS Pod的峰值CPU使用量,如果其在业务峰值期间占用CPU大于一核,建议对CoreDNS进行副本扩容。无法确定峰值CPU使用量时,可以保守地采用Pod数和集群节点数1:8的比值来部署,即每扩容8个集群节点,增加一个CoreDNS Pod。
评估完成后,请参照配置自动调整(推荐)或手动调整执行调整。
配置自动调整(推荐)
下方的cluster-proportional-autoscaler会参照上方的推荐策略(Pod数和集群节点数1:8)实时自动调整CoreDNS的Pod数量。相较于容器水平伸缩(HPA),它不依赖CoreDNS CPU负载指标,适用于副本数量需求与集群规模成正比的服务。
示例中Pod数量的计算公式为replicas = max (ceil (cores × 1/coresPerReplica), ceil (nodes × 1/nodesPerReplica) ),且通过min、max限制了最小Pod数量为2,最大为100。
手动调整
也可通过下方的命令手动调整CoreDNS所属的Pod数量。
kubectl scale --replicas=<target> deployment/coredns -n kube-system # target替换为目标Pod数量调整CoreDNS Pod规格
在ACK托管集群Pro版中,CoreDNS Pod默认的内存限制为2Gi,CPU则未限制。推荐将CPU Limit设置为4096m, 最小应不低于1024m。可通过控制台对CoreDNS Pod配置进行调整。
调整CoreDNS Pod规格的操作可能导致Pod暂时失效,可能会导致集群中出现概率性DNS延迟超时、解析失败的情况,建议在业务低峰期进行操作。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
单击网络页签,找到CoreDNS卡片。单击卡片上的配置。

修改CoreDNS配置,然后单击确认。

采用独占节点池部署
将CoreDNS Pod组件使用独占节点池的方式部署,可使CoreDNS负载与集群中其他应用完全隔离,不受资源抢占的影响。
调度CoreDNS Pod部署到独占节点池的操作可能导致Pod暂时失效,可能会导致集群中出现概率性DNS延迟超时、解析失败的情况,建议在业务低峰期进行操作。
新建CoreDNS专属节点池
为CoreDNS Pod新建专属节点池。请注意下列事项:
CoreDNS对计算资源要求不高,但是需要较高网络性能。建议选择网络增强型实例,规格可选4核8GB。
CoreDNS默认部署两个Pod,节点池中至少需要两个节点。
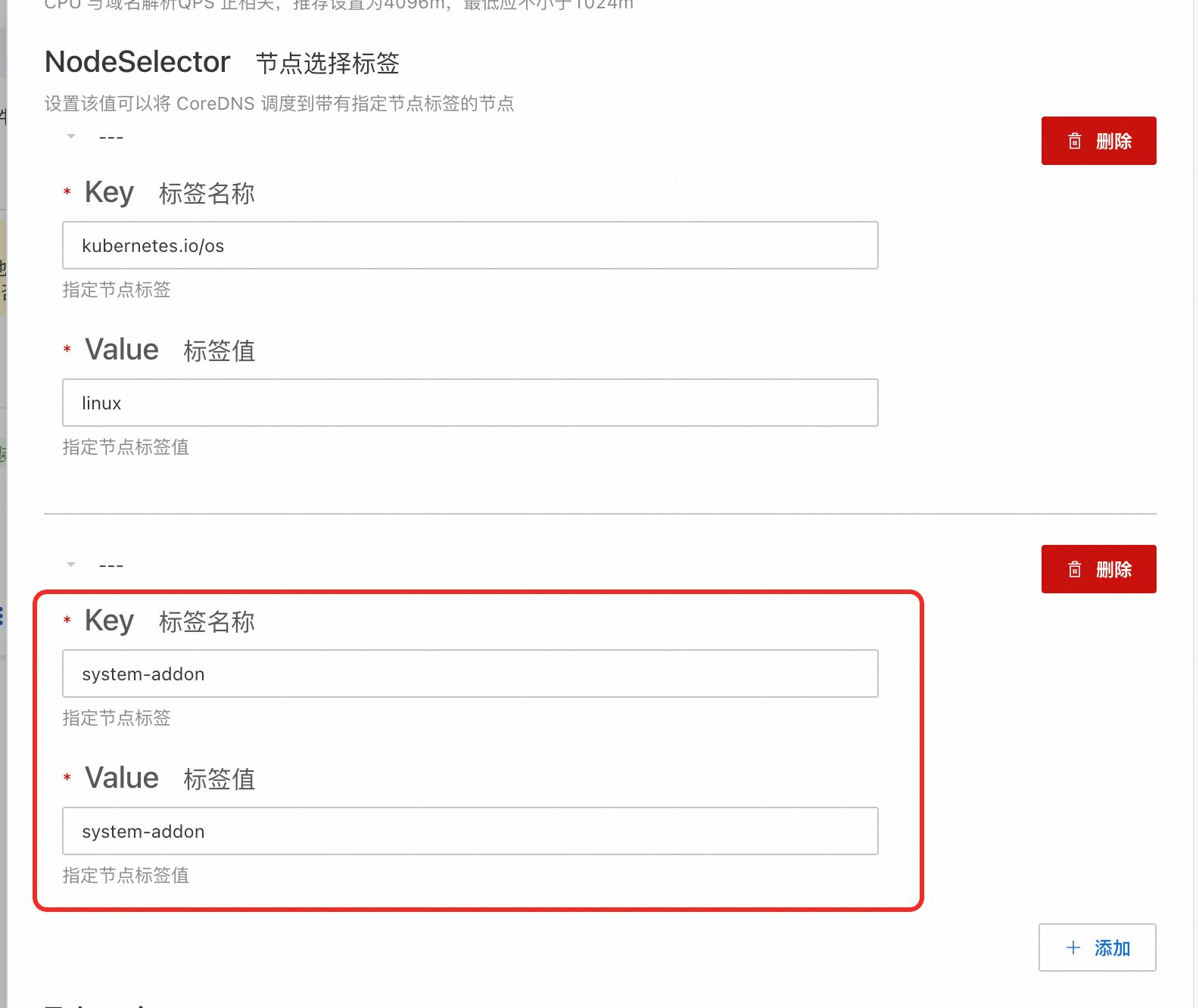
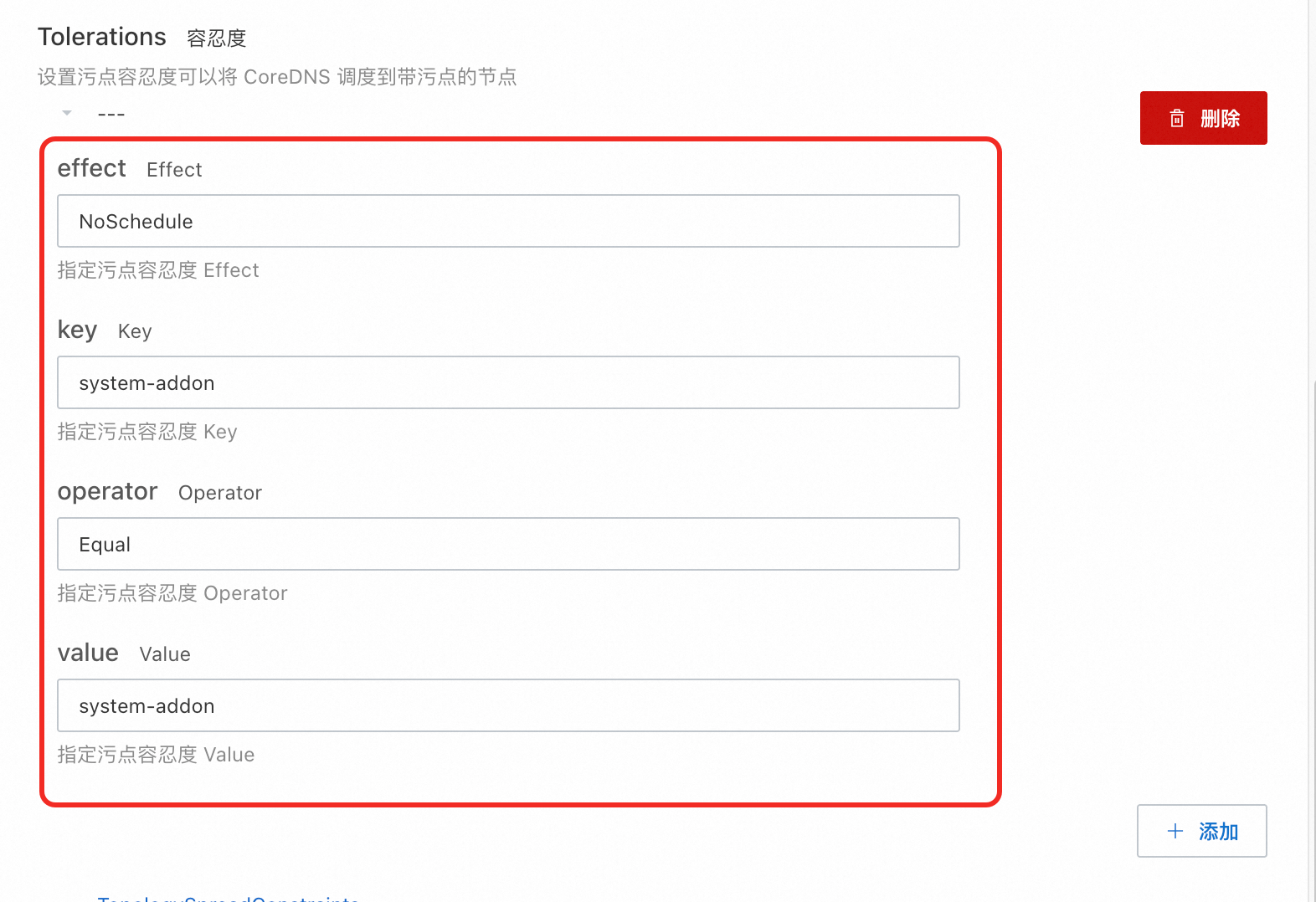
节点池需要进行污点和标签配置以避免其他Pod调度。例如,可在污点和标签中都添加
system-addon: system-addon键值对,将污点Effect设置为NoSchedule,并在下一步骤中使用。
创建节点池的具体操作,请参见创建和管理节点池。
配置CoreDNS组件调度Pod
在组件管理页面找到CoreDNS卡片,单击配置。
在NodeSelector中添加专属节点池标签。
请勿删除已有的NodeSelector标签
在Tolerations中添加专属节点池标签
单击确认保存组件配置。然后执行下方命令,确认CoreDNS Pod是否已调度到专属节点池。
kubectl -n kube-system get pod -o wide --show-labels | grep coredns
使用调度策略实现CoreDNS高可用
CoreDNS的节点亲和性策略、Pod反亲和性策略、拓扑感知调度策略仅在部署时生效。如果节点和可用区配置发生了变化,请通过容器服务管理控制台找到coredns Deployment,在其右侧选择重新部署,以保证CoreDNS Pod分布符合高可用预期。
Pod反亲和性
CoreDNS默认部署2个Pod,并通过Pod反亲和性(Pod Anti-Affinity)策略,将Pod分布在不同的节点上,从而实现节点级别的容灾。为实现Pod反亲和性策略,在集群中至少保留2个可用且资源充足(基于Pod资源request)的节点。同时节点不包含下列标签:
k8s.aliyun.com: true(开启了节点伸缩功能的节点)type: virtual-kubelet(虚拟节点)alibabacloud.com/lingjun-worker: true(灵骏节点)
拓扑感知调度
CoreDNS默认通过拓扑感知调度,尽可能将Pod均匀分布到不同的可用区,并在无法满足均衡条件时拒绝调度 (DoNotSchedule),以实现可用区级容灾。此机制有一定的限制,为确保机制有效,请执行下列操作:
确保集群中的节点至少处于两个不同可用区中,且所有可用区都需要至少一台可供CoreDNS调度、资源充足的节点。
确认节点拥有正确且一致的
topology.kubernetes.io/zone标签(默认拥有),否则会导致拓扑感知错误,或Pod集中部署在一个可用区。升级集群版本至v1.27或更高,升级CoreDNS版本至v1.12.1.3或更高。集群版本低于v1.27时,拓扑感知调度不支持matchLabelKeys,CoreDNS发生滚动更新时,可能会导致Pod最终分布并不均衡,甚至未能覆盖所有可用区。