
本文介绍Kubernetes集群中容器Pod在域名解析过程中的解析策略和缓存策略。
DNS解析链路全景图
以下介绍三种应用部署形式下应用解析域名的链路:
关于图中的timeout、attempts等术语的含义,请参考下文解析策略和缓存策略。
非容器化应用直接运行于ECS之上。
示例:App运行于ECS上。

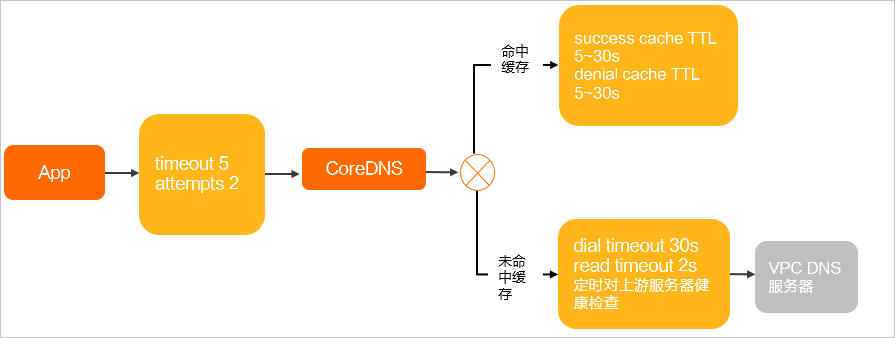
容器化应用运行于Kubernetes中,DNSPolicy注入ClusterFirst的Pod里。
示例:App运行于Kubernetes容器Pod中。
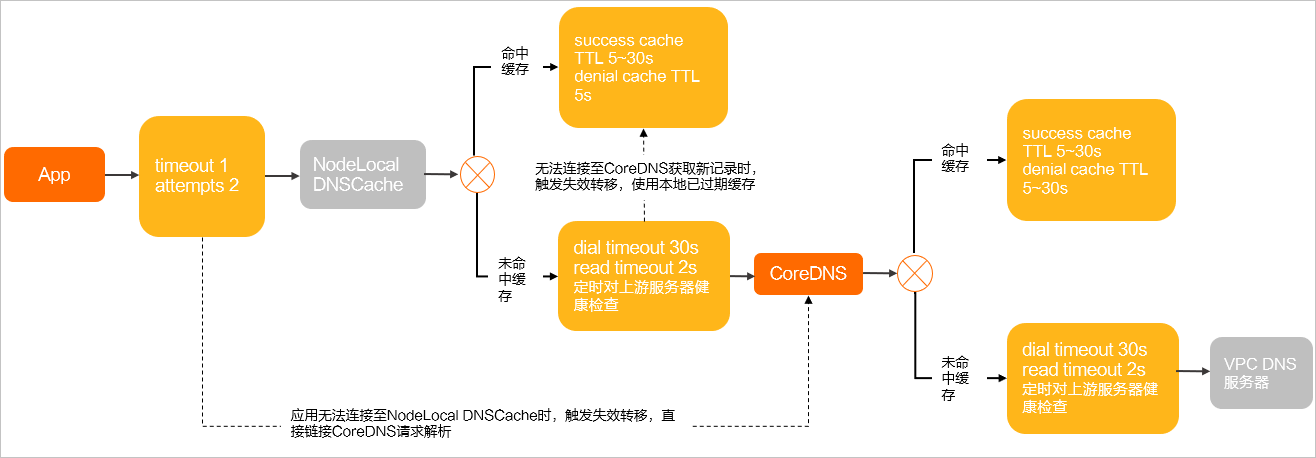
容器化应用运行于Kubernetes中,DNSPolicy注入了NodeLocal DNSCache的Pod里。
示例:App运行于Kubernetes容器Pod中,同时部署了NodeLocal DNSCache。
解析策略
客户端侧
一般情况下,应用解析域名是通过Glibc提供的接口完成的,下表参数为/etc/resolv.conf中暴露的域名解析参数,即Glibc解析域名时的可配置参数。
参数 | 说明 | Glibc中默认值 | ECS | DNSPolicy为ClusterFirst的Pod | DNSPolicy为Default的Pod | 注入了NodeLocal DNSCache的Pod | DNSPolicy为Default且采用主机网络的Pod |
| 解析域名时使用的DNS服务器 | 空 | VPC DNS服务器② | CoreDNS ClusterIP③ | VPC DNS服务器 |
| VPC DNS服务器 |
| 请求非完整域名(非FQDN)时,域名会被拼接上 | 空 | 空 | <ns>.svc.cluster.local svc.cluster.local cluster.local | 空 | <ns>.svc.cluster.local svc.cluster.local cluster.local | 空 |
| 访问的域名字符串内的点字符数量超过ndots值,则认为是完整域名(FQDN),并被直接解析;如果不足ndots值,则追加search段后缀再进行查询。 | 1 | 1 | 5 | 1 | 3 | 1 |
| 对于单个域名解析请求的超时时间,单位为秒 | 5 | 2 | 5 | 5 | 1 | 2 |
| 解析域名失败时重试的次数 | 2 | 3 | 2 | 2 | 2 | 3 |
| 以Round Robin的形式轮询DNS服务器 | 关闭 | 开启 | 关闭 | 关闭 | 关闭 | 开启 |
| 开启该配置后,一旦需要处理同一Socket发送的两次请求时,解析端会在发送第一次请求后关闭Socket,并在发送第二次请求前打开新的socket。 | 关闭 | 开启 | 关闭 | 关闭 | 关闭 | 开启 |
①attempts参数仅在部分场景下起到重试的效果,例如服务端返回SERVFAIL、NOTIMP、REFUSED时,或服务端返回NOERROR,但没有解析结果时。更多信息,请参见attempts参数解析请求说明。
②VPC DNS服务器是指ECS上默认配置的DNS服务器,IP为100.100.2.136和100.100.2.138,负责PrivateZone和权威域名的解析。
③CoreDNS ClusterIP是指Kubernetes集群内默认部署的CoreDNS在kube-system命名空间下提供的kube-dns服务的IP地址,负责集群内部服务域名的解析,以及PrivateZone、权威域名的解析转发。
④NodeLocal DNSCache IP是指部署了NodeLocal DNSCache组件后,组件在每个节点上监听的169.254.20.10的IP地址。
关于resolv.conf配置的更多信息,请参见resolv.conf。
部分情况下,客户端侧的域名解析策略可能与上述配置不同:
当采用Alpine作为容器镜像时,其内置了Musl库代替Glibc实现,解析行为会有较大不同,例如:
Alpine不遵循/etc/resolv.conf里面的single-request和single-request-reopen。
3.3及更早版本Alpine不支持search参数,不支持搜索域,无法完成服务发现。
并发请求/etc/resolv.conf中配置的多个DNS服务器,导致NodeLocal DNSCache优化失效。
并发使用同一Socket请求A和AAAA记录,在旧版本内核上触发Conntrack源端口冲突导致丢包问题。
说明关于解析行为的更多信息,请参见musl libc。
当使用Golang、NodeJS等编程语言时,应用可能会采用语言内置的域名解析器,其行为也存在较大区别。
集群内DNS服务器
CoreDNS的/etc/resolv.conf默认沿用ECS的配置,但在实际转发DNS请求时,会使用内置的Forward插件完成。
NodeLocal DNSCache内置了CoreDNS实现DNS服务转发,与CoreDNS配置方式一致。
Forward插件的解析策略控制的参数如下表所示。关于CoreDNS Forward插件的更多配置,请参见Forward。
参数 | 说明 | CoreDNS默认值 | NodeLocal DNSCache默认值 |
| 优先使用UDP协议与上游通信 | 开启 | 关闭 |
| 强制使用TCP协议与上游通信 | 关闭 | 开启 |
| 连续多少次健康检查失败就认为upstream不健康 | 2 | 2 |
| 与upstream的链接保持10秒 | 10s | 10s |
| 选择upstream的策略 | random | random |
| 健康检查时间间隔 | 0.5s | 0.5s |
| 最大请求upstream的链接并发数 | 无 | 无 |
| 连接upstream的超时 | 30s,根据实际耗时动态减小 | 30s,根据实际耗时动态减小 |
| 从upstream等待数据的超时 | 2s | 2s |
缓存策略
客户端侧
客户端侧的缓存策略是因容器和应用而异的,实际的缓存策略取决于具体配置。
集群内DNS服务器
参数 | 说明 | CoreDNS社区默认配置 | NodeLocal DNSCache ACK默认配置 | CoreDNS ACK默认配置 |
success Max TTL | 成功的域名解析结果缓存最大TTL | 3600s | 30s | 30s |
success Min TTL | 成功的域名解析结果缓存最小TTL | 5s | 5s | 5s |
success Capacity | 成功的域名解析结果缓存数目 | 9984 | 9984 | 9984 |
denial Max TTL | 失败的域名解析结果缓存最大TTL | 1800s | 5s | 30s |
denial Min TTL | 失败的域名解析结果缓存最小TTL | 5s | 5s | 5s |
denial Capacity | 失败的域名解析结果缓存数目 | 9984 | 9984 | 9984 |
ServerError TTL | 上游DNS服务器异常时解析结果TTL | 5s | 0s(NodeLocal DNSCache Helm Chart版本低于1.5.0时,默认为5s) | 0s(CoreDNS低于1.8.4.2版本时默认为5s) |
serve_stale | 允许无法连接上游DNS服务器时使用已过期的本地缓存 | 关闭 | 开启(NodeLocal DNSCache Helm Chart版本低于1.5.0时,默认关闭) | CoreDNS版本低于1.12.1时默认关闭,1.12.1及以上版本默认开启。 |
实际生效的缓存时间TTL由域名解析结果自身TTL、最大TTL、最小TTL共同决定,规则如下:
解析结果TTL>Max TTL时,实际生效的TTL为Max TTL。
解析结果TTL<Min TTL时,实际生效的TTL为Min TTL。
Min TTL<解析结果TTL<Max TTL时,实际生效的TTL为解析结果TTL。
优化建议
本文介绍了Kubernetes集群的解析路径及各环节参数配置,请通过修改Pod Yaml、CoreDNS ConfigMap、NodeLocal DNSCache ConfigMap等方式修改参数,示例如下。
当客户端Pod配置dnsPolicy:Default时,ECS上VPC DNS服务器会被拷贝至容器内/etc/resolv.conf配置文件中。
apiVersion: v1
kind: Pod
metadata:
name: example
namespace: default
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/example-ns/example:v1
name: example
#Pod YAML中dnsPolicy值为Default。
dnsPolicy: Default
# 此时容器内/etc/resolv.conf。
# cat /etc/resolv.conf
nameserver 100.100.2.136
nameserver 100.100.2.138容器内对比ECS上,缺少了rotate single-request-reopen timeout:2 attempts:3的options参数,可能会使一个偶发的网络链路抖动导致业务侧域名解析异常,需要补充这些参数以提升容错能力。调整Pod YAML如下:
apiVersion: v1
kind: Pod
metadata:
name: example
namespace: default
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/example-ns/example:v1
name: example
# Pod YAML中dnsPolicy值为Default。
dnsPolicy: Default
# 增加以下容错配置。
dnsConfig:
options:
- name: timeout
value: "2"
- name: attempts
value: "3"
- name: rotate
- name: single-request-reopen
# 修改后重新部署Pod,容器内/etc/resolv.conf新增了options参数。
# cat /etc/resolv.conf
nameserver 100.100.2.136
nameserver 100.100.2.138
options rotate single-request-reopen timeout:2 attempts:3使用serve_stale保证DNS稳定性
serve_stale是CoreDNS cache插件对serving stale功能的一个具体实现。当开启serve_stale后,上游DNS服务无法访问时,CoreDNS将通过缓存继续提供过期条目。使用该功能可以提高DNS解析的可靠性,避免上游DNS服务抖动或偶发异常导致的DNS解析失败问题。
非托管CoreDNS在1.12.1及以上版本默认开启了此配置。该功能的详细说明,请参见RFC-8767。
配置格式
serve_stale [DURATION] [REFRESH_MODE]
DURATION:过期条目的有效时长,默认值为1h。缓存过期时间到达有效时长且仍未更新时,CoreDNS将不再提供该条目。REFRESH_MODE:提供过期条目时的策略:verify:在将过期条目发送到客户端之前,先验证上游DNS服务是否可用。该方式可能会增加客户端的解析时延,但如果检测到更新,可以立即提供新的条目。immediate:立即将过期条目发送给客户端,再验证上游DNS服务是否可用。可以立即提供响应,但更新时间落后于上游DNS服务更新。
配置示例
非托管CoreDNS v1.12.1.2及以上版本中默认使用下方配置。
cache 30 {
...
serve_stale 30s verify
}非托管CoreDNS v1.12.1.1-4035d7a99-aliyun版本的默认配置:
cache 30 {
...
serve_stale 1h immediate
}使用上述默认配置时,在一些极端场景下(例如客户端在Headless Service迭代更新时进行DNS解析)可能会产生DNS返回已过期条目的情况。如果该类情况经常发生,可以调整为上方配置示例中的verify策略。