
Knative提供了简单易用的自动扩缩容KPA(Knative Pod Autoscaler)功能。您可以基于Pod并发数(Concurrency)、每秒请求数(RPS)配置自动扩缩容的条件。此外,Knative默认会在没有业务请求时将Pod数量缩减至0,您可以通过KPA配置缩容相关参数(例如缩容至0的等待时间),以及是否需要缩容至0。
前提条件
已在集群中部署Knative,请参见部署与管理Knative组件。
实现原理
Knative Serving会为每个Pod注入一个名为queue-proxy的QUEUE代理容器,该容器负责向Autoscaler报告业务容器的并发指标。Autoscaler接收到这些指标之后,会根据并发请求数及相应的算法,调整Deployment的Pod数量,从而实现自动扩缩容。

算法
Knative Pod Autoscaler(KPA)基于每个Pod的平均请求数(或并发数)进行自动扩缩容,Knative默认使用基于并发数的自动弹性,每个Pod的最大并发数为100。此外,Knative还提供了目标使用率(target-utilization-percentage)的概念,用于指定自动扩缩容的目标使用率。
基于并发数弹性为例,Pod数计算方式如为:Pod数=并发请求总数/(Pod最大并发数*目标使用率)
例如,如果服务中Pod最大并发数设置为10,目标使用率设置为0.7,此时如果接收到了100个并发请求,则Autoscaler就会创建15个Pod(即100/(0.7 x 10)≈15)。
KPA基于每个Pod的平均请求数(或并发数)来进行自动扩缩容,并结合了Stable稳定模式和Panic恐慌模式两个概念,以实现精细化的弹性。
Stable稳定模式
在稳定模式中,KPA会在默认的稳定窗口期(默认为60秒)内计算Pod的平均并发数。根据这个平均并发数,KPA会调整Pod的数量,以保持稳定的负载水平。
Panic恐慌模式
在恐慌模式中,KPA会在恐慌窗口期(默认为6秒)内计算Pod的平均并发数。
恐慌窗口期=稳定窗口期 x panic-window-percentage(panic-window-percentage取值是0~1,默认是0.1)。当请求突然增加导致当前Pod的使用率超过恐慌窗口百分比时,KPA会快速增加Pod的数量以满足负载需求。
在KPA中,弹性生效的判断是基于恐慌模式下计算得出的Pod数量是否超过恐慌阈值(PanicThreshold)。恐慌阈值=panic-threshold-percentage/100,panic-threshold-percentage默认为200,即恐慌阈值默认为2。
综上所述,如果在恐慌模式下计算得出的Pod数量大于或等于当前Ready Pod数量的两倍,那么KPA将使用恐慌模式下计算得出的Pod数量进行弹性生效;否则,将使用稳定模式下计算得出的Pod数量。
KPA配置介绍
部分配置支持通过Annotation在Revision级别生效,也支持通过ConfigMap配置针对全局生效。如果您同时配置两种方式,那么Revision级别配置的优先级将高于全局配置。
config-autoscaler配置介绍
配置KPA,需要配置config-autoscaler,该参数默认已配置,以下为重点参数介绍。
执行以下命令,查看config-autoscaler。
kubectl -n knative-serving describe cm config-autoscaler预期输出(config-autoscaler默认的ConfigMap):
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
# 默认Pod最大并发数,默认值为100。
container-concurrency-target-default: "100"
# 并发数目标使用率。默认值为70,70实际表示0.7。
container-concurrency-target-percentage: "70"
# 默认每秒请求数(RPS)。默认值为200。
requests-per-second-target-default: "200"
# 突发请求容量参数主要是为了应对突发流量,以防止Pod业务容器被过载。当前默认值211,也就意味着当前如果服务设置的目标阈值*Ready的Pod数小于 211,那么会通过Activator进行路由
# 它通过Activator作为请求缓冲区,通过这个参数的计算结果,来调节是否请求通过Activator组件。
# 当该值为0时,只有Pod缩容到0时,才切换到Activator。
# 当该值大于0并且container-concurrency-target-percentage设置为100时,请求总是会通过Activator。
# 当该值为-1,表示无限的请求突发容量。请求也总是会通过Activator。其他负值无效。
# 如果当前Ready Pod数*最大并发数-突发请求容量-恐慌模式计算出来的并发数<0,意味着突发流量超过了容量阈值,则切换到Activator进行请求缓冲。
target-burst-capacity: "211"
# 稳定窗口,默认值为60秒。
stable-window: "60s"
# 恐慌窗口比例,默认值为10,则表示默认恐慌窗口期为6秒(60*0.1=6)。
panic-window-percentage: "10.0"
# 恐慌阈值比例,默认值200。
panic-threshold-percentage: "200.0"
# 最大扩缩容速率,表示一次扩容最大数。实际计算方式:math.Ceil(MaxScaleUpRate*readyPodsCount) 。
max-scale-up-rate: "1000.0"
# 最大缩容速率,默认值为2,表示每次缩容一半。
max-scale-down-rate: "2.0"
# 是否开始缩容到0,默认开启。
enable-scale-to-zero: "true"
# 优雅缩容到0的时间,即延迟多久缩容到0,默认30秒。
scale-to-zero-grace-period: "30s"
# Pod缩容到0保留期,该参数适用于Pod启动成本较高的情况
scale-to-zero-pod-retention-period: "0s"
# 弹性插件类型,当前支持的弹性插件包括:KPA、HPA、AHPA。
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
# activator请求容量。
activator-capacity: "100.0"
# 创建revision时,初始化启动的Pod数,默认1。
initial-scale: "1"
# 是否允许创建revision时,初始化0个Pod, 默认false,表示不允许。
allow-zero-initial-scale: "false"
# revision级别最小保留的Pod数量。默认0,表示最小值可以为0。
min-scale: "0"
# revision级别最大扩容的Pod数量。默认0,表示无最大扩容上限。
max-scale: "0"
# 表示延迟缩容时间。默认0,表示立即缩容。
scale-down-delay: "0s"指标配置介绍
您可以通过autoscaling.knative.dev/metricAnnotation为每个Revision配置指标,不同的弹性插件支持的指标配置不同。
支持的指标:
"concurrency"、"rps"、"cpu"、"memory"以及其他自定义指标。默认指标:
"concurrency"。
目标阈值配置介绍
您可以通过autoscaling.knative.dev/targetAnnotation为每一个Revision配置目标阈值,也通过container-concurrency-target-defaultAnnotation为ConfigMap全局配置目标阈值。
Revision级别
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
# 在Revision级别设置伸缩目标阈值为50
autoscaling.knative.dev/target: "50"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全局级别
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"缩容到0配置介绍
通过全局配置是否缩容到0
enable-scale-to-zero参数可取值为"false"或"true",用于指定Knative服务在空闲时是否自动缩减为零副本。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false" # 值被设置为"false",表示自动缩容功能被禁用,即Knative服务在空闲时不会自动缩减为零副本。全局配置优雅缩容到0的时间
scale-to-zero-grace-period参数用于指定Knative服务在缩减为0副本之前的等待时间。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-grace-period: "40s"Pod缩容到0保留期
Revision级别
autoscaling.knative.dev/scale-to-zero-pod-retention-periodAnnotation用于配置Knative服务的自动缩容功能,指定在服务空闲一段时间后保留的Pod的时间周期。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全局级别
scale-to-zero-pod-retention-period的配置项用于指定Knative服务在缩减为零副本之前保留的Pod的时间周期。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-pod-retention-period: "42s"并发数配置介绍
并发数表示单个Pod能同时处理的最大请求数量。可以通过并发软限制配置、并发硬限制配置、目标使用率配置、每秒请求数(RPS)配置来设置并发数。
并发软限制配置
并发软限制是有针对性的限制,而不是严格执行的界限。在某些情况下,特别是请求突然爆发时,可能会超过该值。
Revision级别
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "200"全局级别
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200" # 指定Knative服务的默认容器并发目标。
并发硬限制配置(Revision级别)
仅当您的应用程序有明确的执行并发上限时,才建议使用硬限制配置。因为指定较低的硬限制可能会对应用程序的吞吐量和延迟产生负面影响。
并发硬限制是强制上限。如果并发达到硬限制,多余的请求将被queue-proxy或者activator缓冲,直到有足够的可用资源来执行请求。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56
containerConcurrency: 50目标使用率
使用目标利用率值调整并发值,该值指定Autoscaler实际目标值的百分比。这也称为资源预热,可以在请求达到定义的硬限制之前进行扩容。
例如,containerConcurrency设置为10,目标利用率值设置为70(百分比),则当所有现有Pod的平均并发请求数达到7时,Autoscaler将创建一个新Pod。因为Pod从创建到Ready需要一定的时间,通过降低目标利用率值可以提前扩容Pod,从而减少冷启动导致的响应延迟等问题。
Revision级别
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target-utilization-percentage: "70" # 配置Knative服务的自动缩放功能,指定了目标资源利用率的百分比。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全局级别
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-percentage: "70" # Knative将尽量确保每个Pod的并发数不超过当前可用资源的70%。每秒请求数(RPS)配置
RPS表示单个Pod每秒能处理的请求数。
Revision级别
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "150"
autoscaling.knative.dev/metric: "rps" # 表示服务的自动缩放将根据每秒请求数(RPS)来调整副本数。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全局级别
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
requests-per-second-target-default: "150"场景一:设置并发请求数实现自动扩缩容
设置并发请求数,通过KPA实现自动扩缩容。
为集群部署Knative,具体操作,请参见在ACK集群中部署Knative、在ACK Serverless集群中部署Knative。
创建autoscale-go.yaml,并部署到集群中。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" # 设置当前最大并发请求数为10。 spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yaml获取服务访问网关。
ALB
执行以下命令,获取服务访问网关。
kubectl get albconfig knative-internet预期输出:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
执行以下命令,获取服务访问网关。
kubectl -n knative-serving get ing stats-ingress预期输出:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
执行以下命令,获取服务访问网关。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"预期输出:
121.XX.XX.XXKourier
执行以下命令,获取服务访问网关。
kubectl -n knative-serving get svc kourier预期输出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m使用Hey压测工具,执行30s内保持50个并发请求。
说明Hey压测工具的详细介绍,请参见Hey。
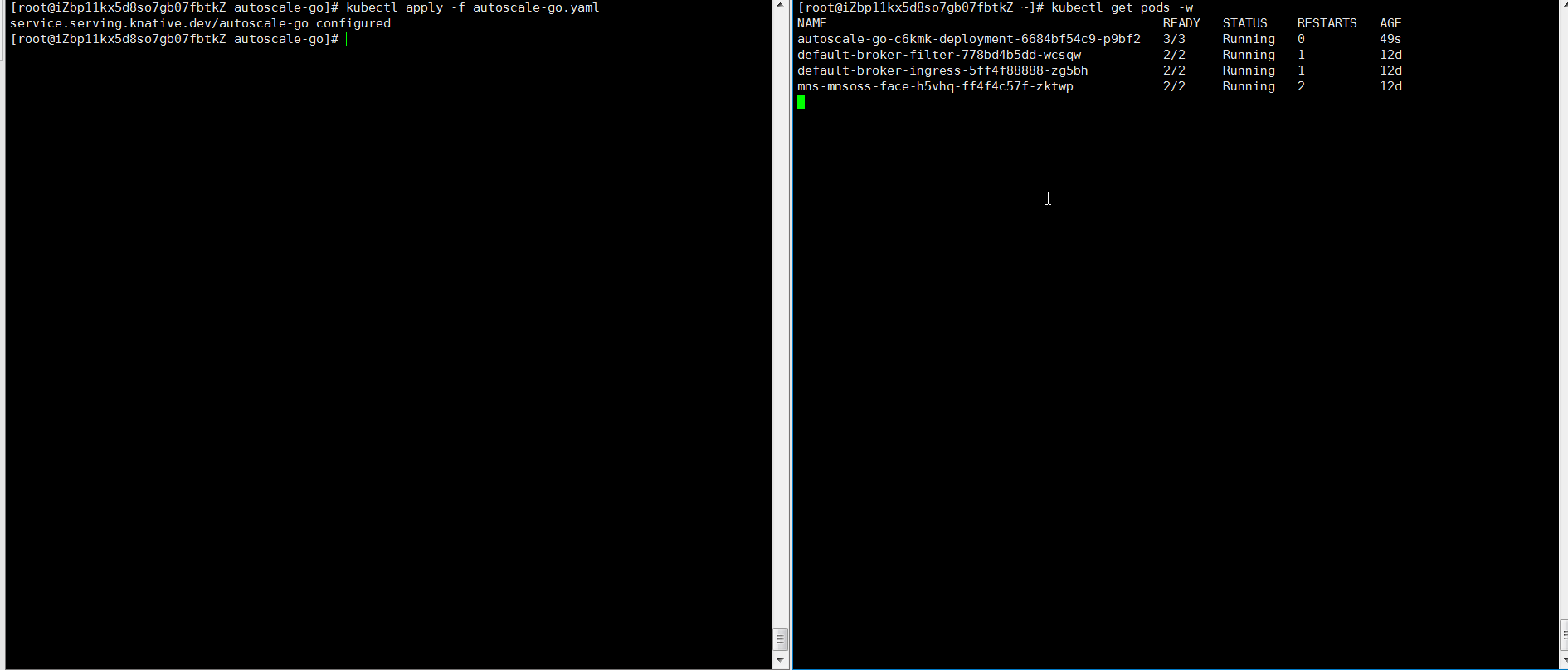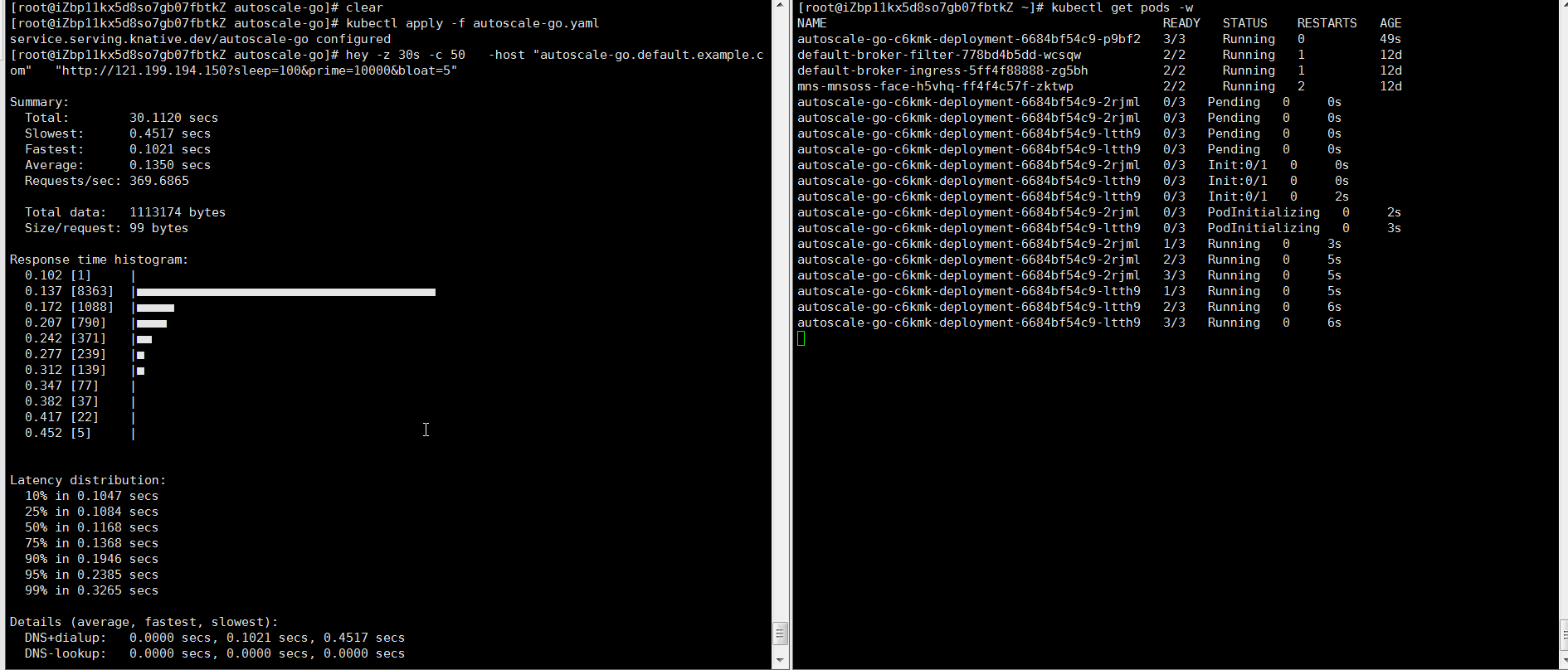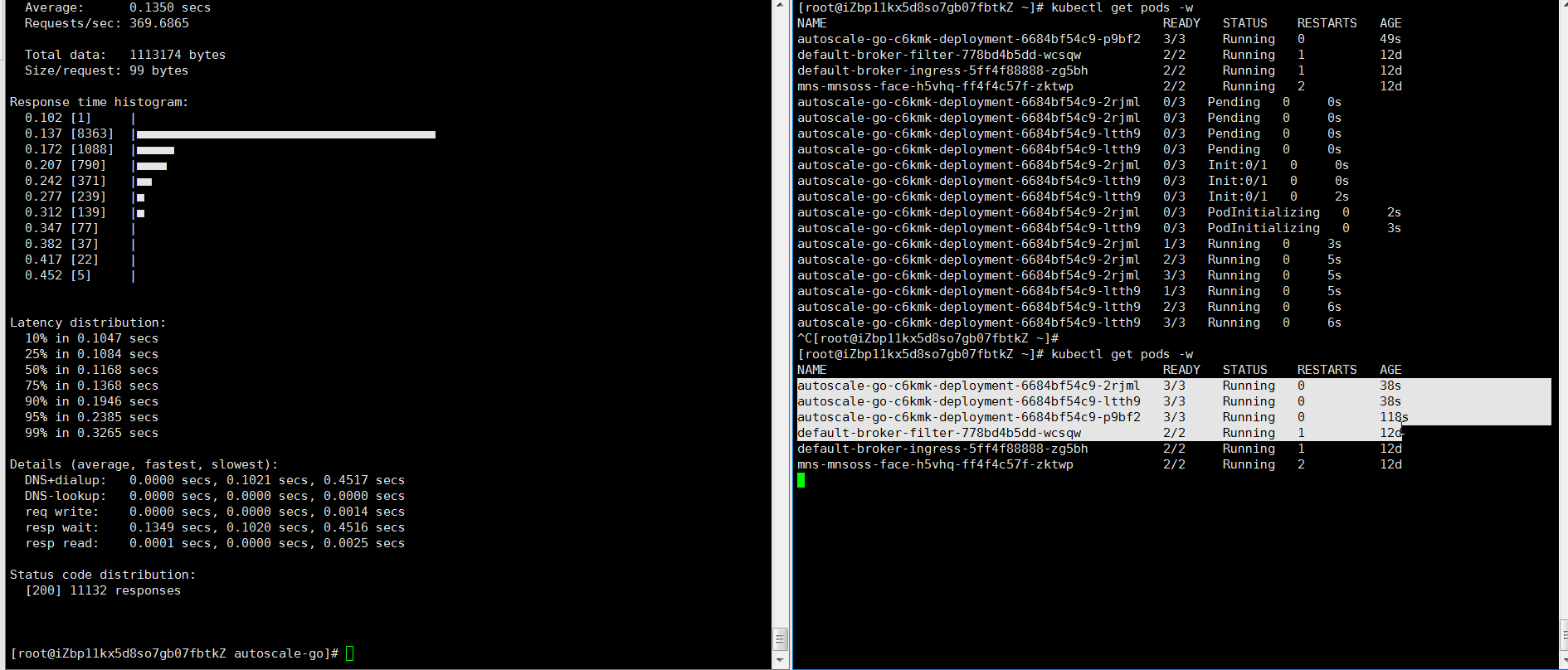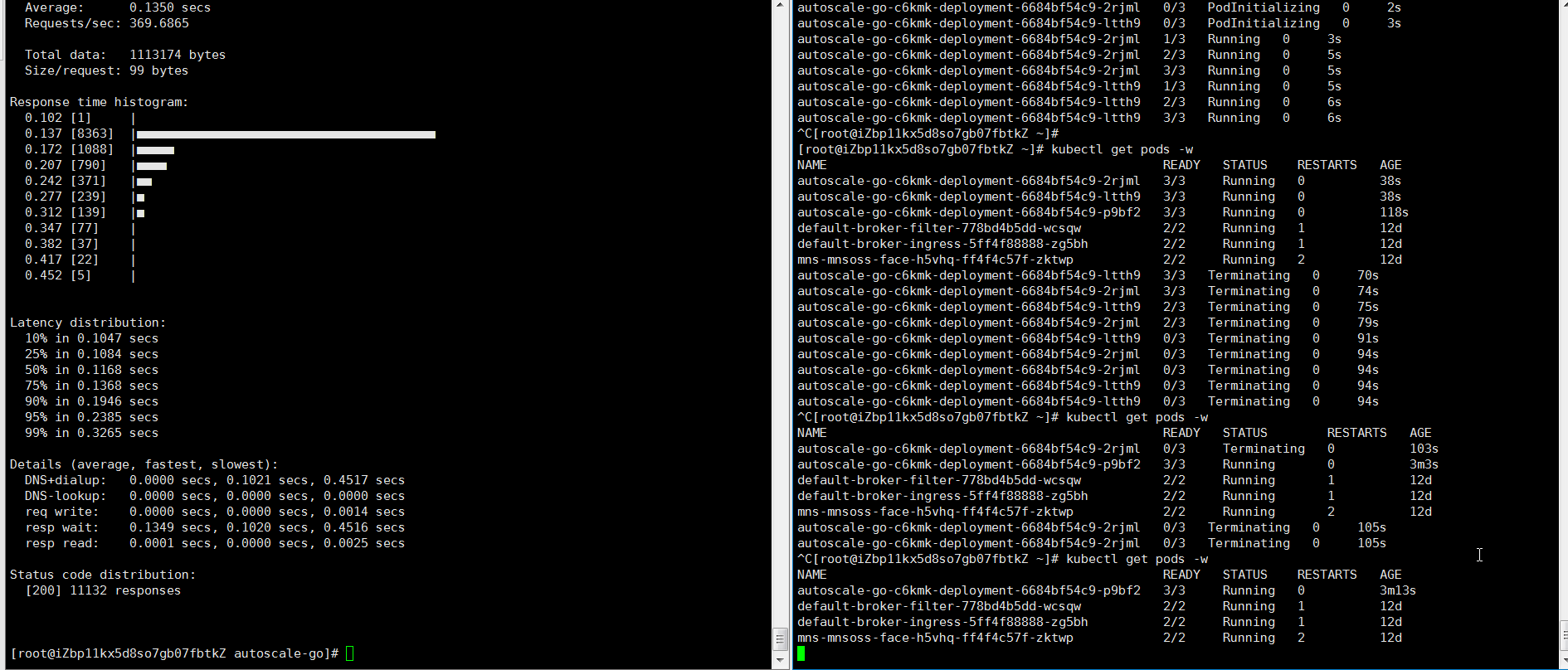
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX为网关IP。预期输出:
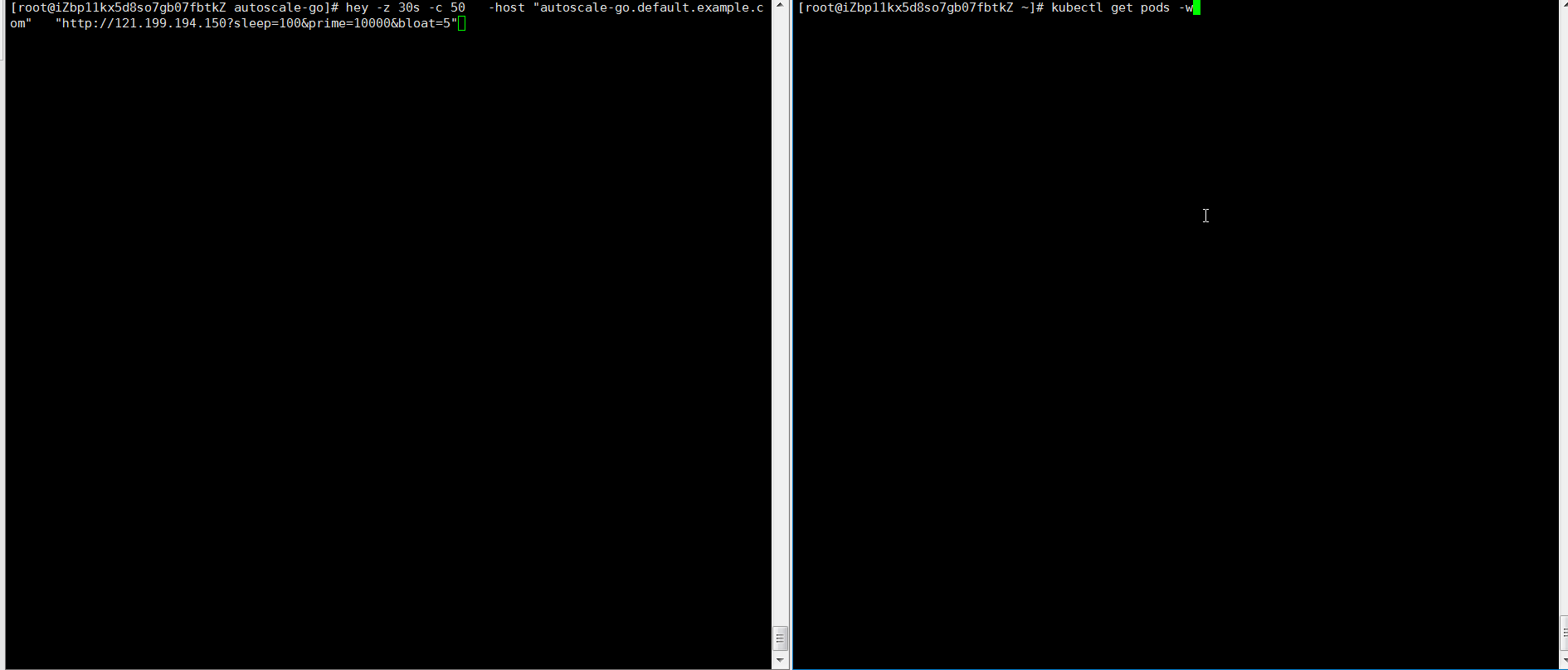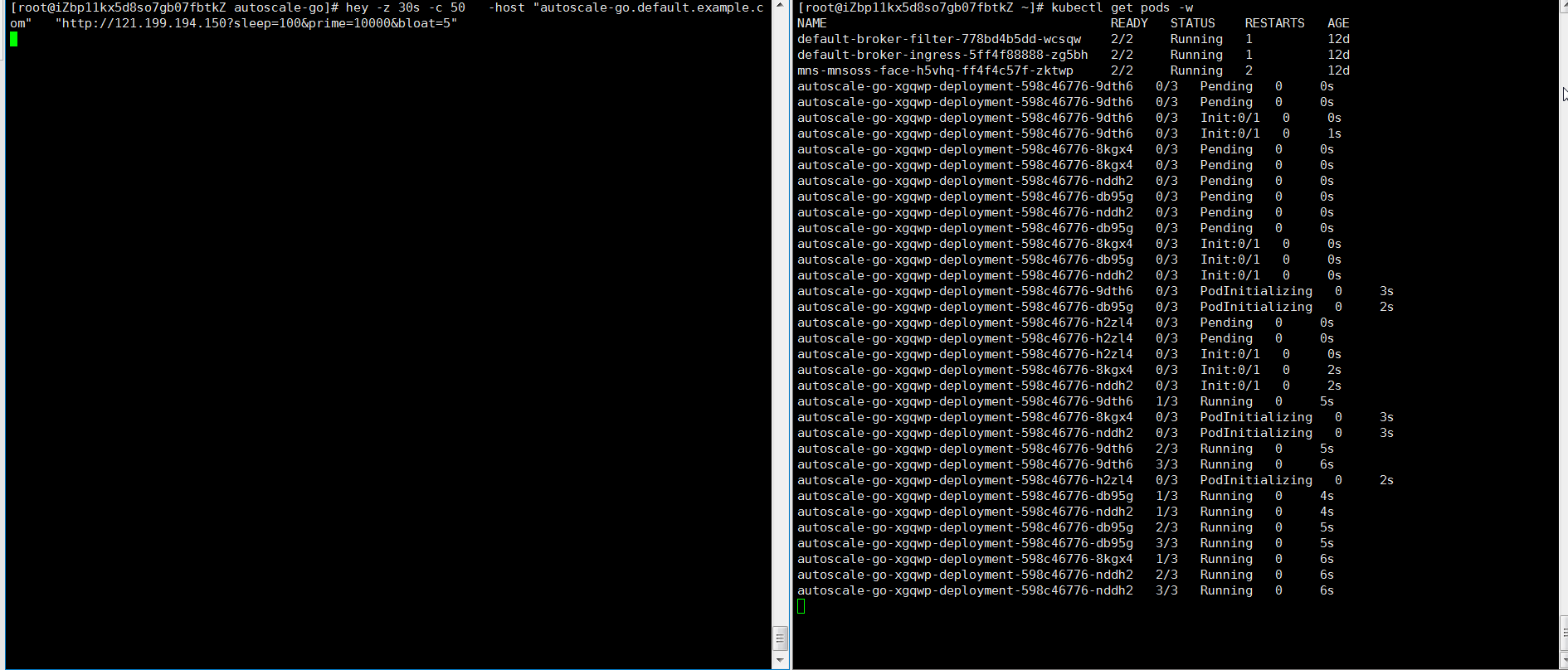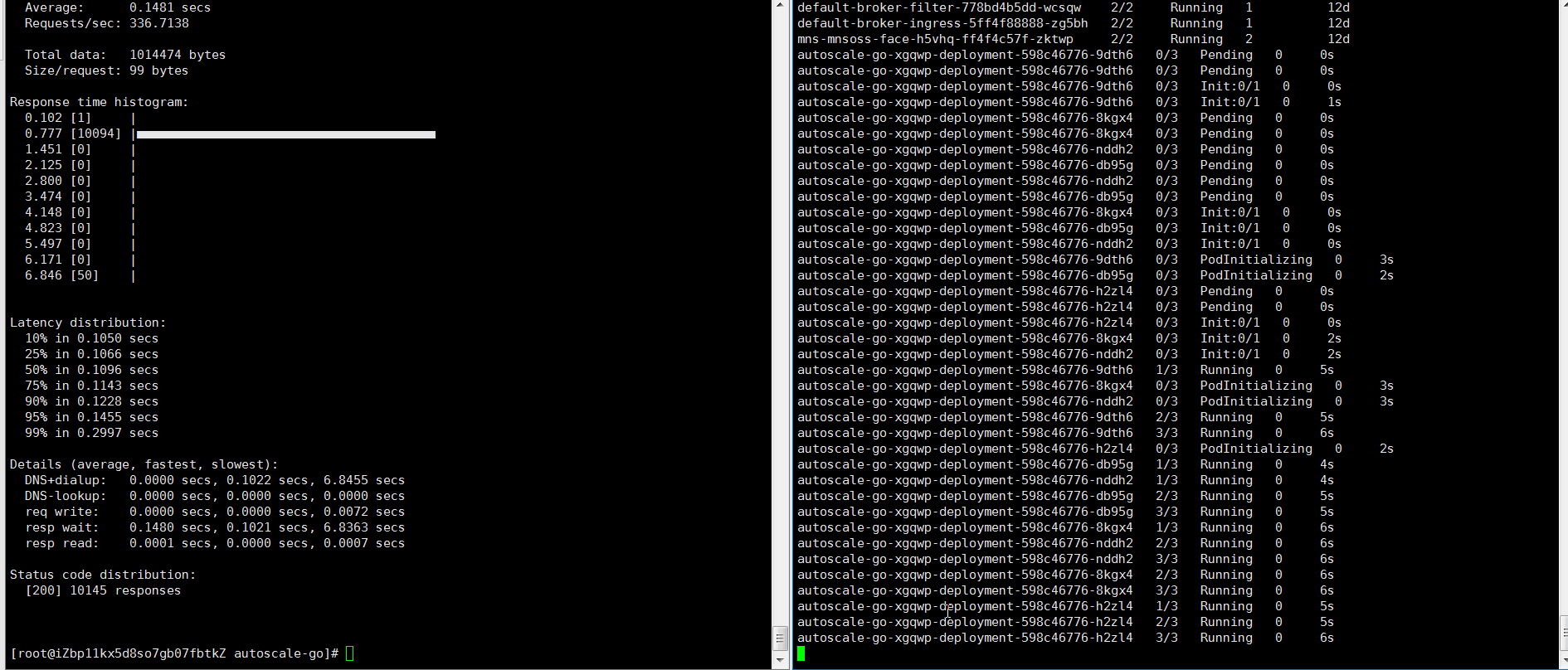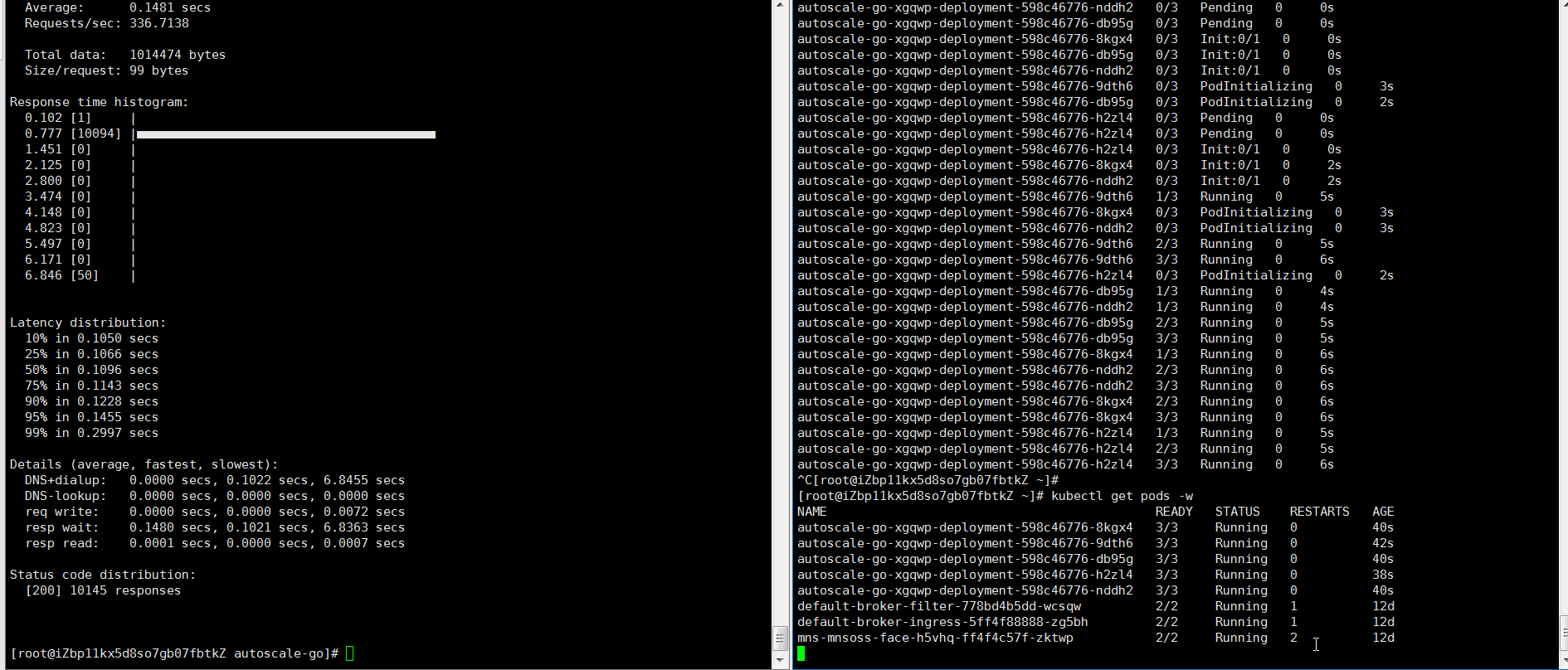
扩容了5个Pod,符合预期。
场景二:设置扩缩容边界实现自动扩缩容
扩缩容边界指应用程序提供服务的最小和最大Pod数量。通过设置应用程序提供服务的最小和最大Pod数量实现自动扩缩容。
为集群部署Knative,具体操作,请参见在ACK集群中部署Knative、在ACK Serverless集群中部署Knative。
创建autoscale-go.yaml,并部署到集群中。
示例YAML设置最大并发请求数为10,
min-scale最小保留实例数为1,max-scale最大扩容实例数为3。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/min-scale: "1" autoscaling.knative.dev/max-scale: "3" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yaml获取服务访问网关。
ALB
执行以下命令,获取服务访问网关。
kubectl get albconfig knative-internet预期输出:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
执行以下命令,获取服务访问网关。
kubectl -n knative-serving get ing stats-ingress预期输出:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
执行以下命令,获取服务访问网关。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"预期输出:
121.XX.XX.XXKourier
执行以下命令,获取服务访问网关。
kubectl -n knative-serving get svc kourier预期输出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m使用Hey压测工具,执行30s内保持50个并发请求。
说明Hey压测工具的详细介绍,请参见Hey。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX为网关IP。预期输出:
最多扩容出3个Pod,并且即使在无访问请求流量的情况下,保持了1个Pod处于运行中,符合预期。