在ACK托管集群Pro版集群中部署GPU计算任务时,可通过为GPU节点分配调度属性标签(如独占、共享、拓扑感知等)和指定卡型标签(卡型调度),实现资源利用率优化与应用精准调度。
调度标签介绍
GPU调度标签通过标识GPU型号、资源分配策略等信息,实现资源精细化管理与高效调度。
调度功能 | 标签值 | 适用场景 |
独占调度(默认) |
| 性能要求高、需独占整卡的任务,如模型训练、HPC等。 |
共享调度 |
| 提升 GPU 利用率,适用于多租户、推理等多个轻量级任务并发运行的场景。
|
| 适用于在开启
| |
拓扑感知调度 |
| 根据单机内GPU物理拓扑关系,为Pod自动分配通信带宽最优的GPU组合,适用于对GPU之间通信延迟敏感的任务。 |
卡型调度 |
配合卡型调度设置GPU任务的显存容量、总GPU卡数。 | 将任务调度到指定 GPU 型号的节点上,或避开特定型号。 |
开启调度功能
独占调度
节点未添加任何GPU调度标签,则默认启用独占调度。此时,节点以单张GPU卡为最小分配单元,为Pod提供GPU资源。
若已开启其他GPU调度功能,仅删除标签无法恢复独占调度,需手动将标签值修改为ack.node.gpu.schedule: default才能恢复独占调度能力。共享调度
共享调度,仅支持ACK托管集群Pro版。具体信息,请参见使用限制。
安装共享调度组件
ack-ai-installer。登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在云原生AI套件页面,单击一键部署。在一键部署云原生AI套件页面,选中调度策略扩展(批量任务调度、GPU共享、GPU拓扑感知)。
如何设置cGPU服务支持的算力调度Policy策略,请参见安装并使用cGPU服务。
在云原生AI套件页面,单击部署云原生AI套件。
在云原生AI套件页面组件列表,查看已安装的共享GPU组件ack-ai-installer。
开启共享调度功能。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在节点池页面,单击创建节点池配置节点标签,单击确认配置。
其余配置项信息可保持默认。关于节点标签的使用场景,请参见调度标签介绍。
配置基础共享调度。
单击节点标签(Labels)的
 ,设置键为
,设置键为ack.node.gpu.schedule,可选择配置cgpu、core_mem、share、mps(需安装MPS Control Daemon组件)标签值之一。配置多卡共享调度。
当节点含多张GPU卡,优化多GPU卡资源的分配策略时,可在基础共享调度上,进一步配置多卡共享调度。
单击节点标签(Labels)的
,设置键为ack.node.gpu.placement,可选择配置binpack、spread标签值之一。
验证是否已开启共享调度功能。
cgpu/share/mps将变量<NODE_NAME>替换为目标节点名称后,执行以下命令,验证节点池是否开启
cgpu/share/mps共享调度功能。kubectl get nodes <NODE_NAME> -o yaml | grep -q "aliyun.com/gpu-mem"预期输出:
aliyun.com/gpu-mem: "60"aliyun.com/gpu-mem字段不为0,说明已开启cgpu/share/mps共享调度功能。core_mem将变量
<NODE_NAME>替换为目标节点名称后,执行以下命令,验证节点池是否开启core_mem共享调度功能。kubectl get nodes <NODE_NAME> -o yaml | grep -E 'aliyun\.com/gpu-core\.percentage|aliyun\.com/gpu-mem'预期输出:
aliyun.com/gpu-core.percentage:"80" aliyun.com/gpu-mem:"6"字段
aliyun.com/gpu-core.percentage和aliyun.com/gpu-mem均不为0,说明已开启core_mem共享调度功能。binpack使用共享GPU调度GPU资源查询工具,执行以下命令,查询节点GPU资源分配情况:
kubectl inspect cgpu预期输出:
NAME IPADDRESS GPU0(Allocated/Total) GPU1(Allocated/Total) GPU2(Allocated/Total) GPU3(Allocated/Total) GPU Memory(GiB) cn-shanghai.192.0.2.109 192.0.2.109 15/15 9/15 0/15 0/15 24/60 -------------------------------------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 24/60 (40%)输出结果表明,GPU0资源已全部分配15/15,GPU1已分配资源为9/15,符合优先填满一张GPU后再分配下一张的调度策略,
binpack策略生效。spread使用共享调度GPU资源查询工具,执行以下命令,查询节点GPU资源分配情况:
kubectl inspect cgpu预期输出:
NAME IPADDRESS GPU0(Allocated/Total) GPU1(Allocated/Total) GPU2(Allocated/Total) GPU3(Allocated/Total) GPU Memory(GiB) cn-shanghai.192.0.2.109 192.0.2.109 4/15 4/15 0/15 4/15 12/60 -------------------------------------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 12/60 (20%)输出结果表明,GPU0已分配资源4/15,GPU1已分配资源为4/15,GPU3已分配资源为4/15,符合优先将Pod分散到不同GPU上的调度策略,
spread策略生效。
拓扑感知调度
拓扑感知调度,仅支持ACK托管集群Pro版。具体信息,请参见系统组件版本要求。
开启拓扑感知调度功能。
将变量<NODE_NAME>替换为目标节点名称后,执行以下命令,为节点增加Label,显式激活节点的GPU拓扑感知调度功能。
kubectl label node <NODE_NAME> ack.node.gpu.schedule=topology节点激活GPU拓扑感知调度后,不再支持非拓扑感知GPU资源的调度。可以执行
kubectl label node <NODE_NAME> ack.node.gpu.schedule=default --overwrite命令更改Label,恢复独占调度。验证是否已开启拓扑感知调度功能。
将变量<NODE_NAME>替换为目标节点名称后,执行以下命令,验证节点池是否开启
topology拓扑感知调度功能。kubectl get nodes <NODE_NAME> -o yaml | grep aliyun.com/gpu预期输出:
aliyun.com/gpu: "2"aliyun.com/gpu字段不为0,说明已开启topology拓扑感知调度功能。
卡型调度
将任务调度到指定 GPU 型号的节点上,或避开特定型号。
查看节点GPU卡型。
执行以下命令,在集群中查询节点的GPU卡型。
节点GPU卡型名称:NVIDIA_NAME字段。
kubectl get nodes -L aliyun.accelerator/nvidia_name预期输出如下:
NAME STATUS ROLES AGE VERSION NVIDIA_NAME cn-shanghai.192.XX.XX.176 Ready <none> 17d v1.26.3-aliyun.1 Tesla-V100-SXM2-32GB cn-shanghai.192.XX.XX.177 Ready <none> 17d v1.26.3-aliyun.1 Tesla-V100-SXM2-32GB在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。在创建的容器所在行(例如tensorflow-mnist-multigpu-***),单击操作列的终端。然后从下拉列表中选择需要登录的容器,执行如下命令。
查询卡型:
nvidia-smi --query-gpu=gpu_name --format=csv,noheader --id=0 | sed -e 's/ /-/g'查询每张卡显存容量:
nvidia-smi --id=0 --query-gpu=memory.total --format=csv,noheader | sed -e 's/ //g'查询节点上总共拥有的GPU卡数:
nvidia-smi -L | wc -l

开启卡型调度。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在任务页面,单击使用YAML创建资源。使用如下示例创建应用,并开启卡型调度功能。
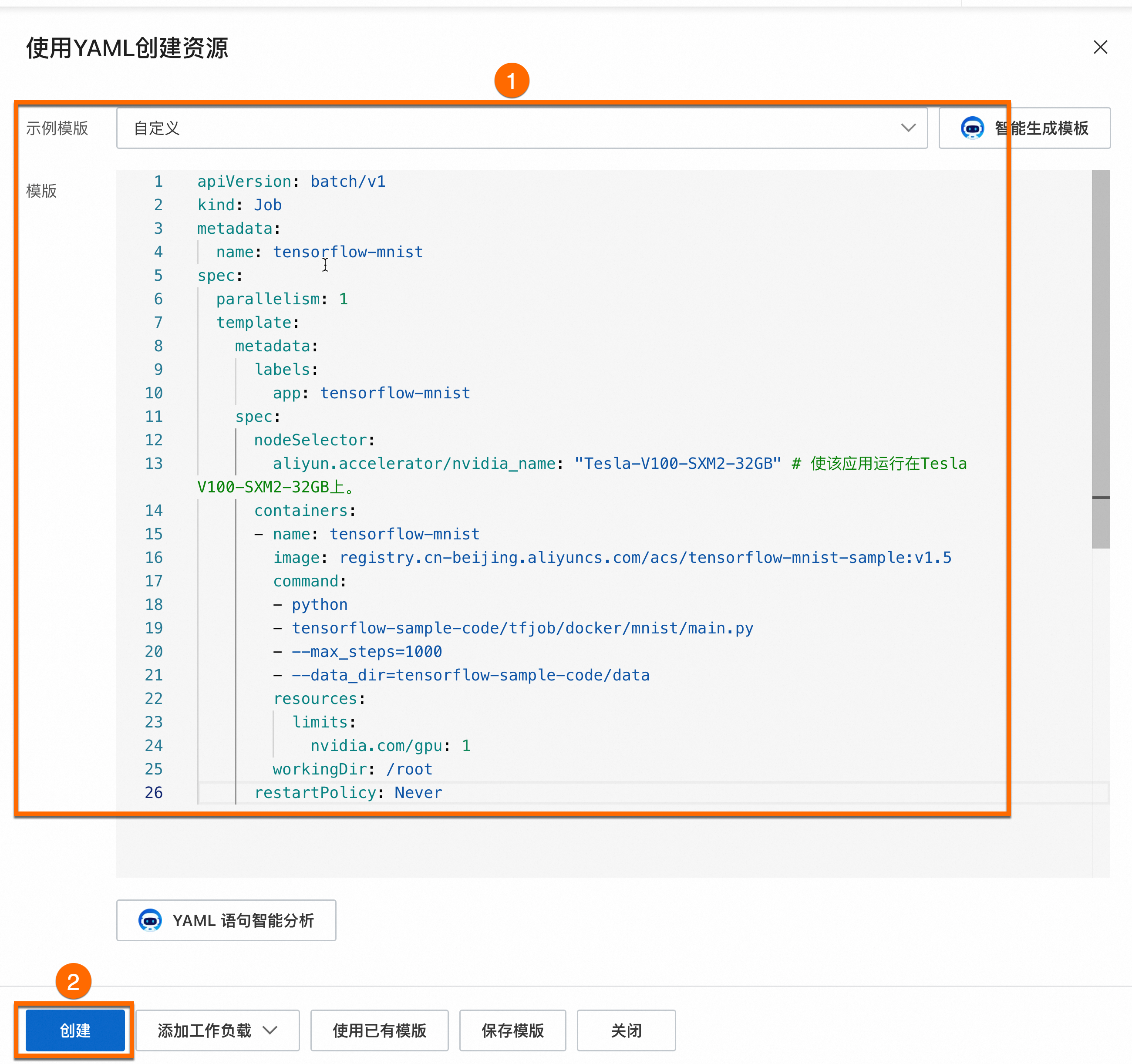
指定特定卡型
利用GPU卡型调度标签,让业务运行在指定卡型的节点上。
将
aliyun.accelerator/nvidia_name: "Tesla-V100-SXM2-32GB"代码中Tesla-V100-SXM2-32GB替换为节点实际卡型。创建成功后,可以在左侧导航栏中选择。在容器组列表中,可看到一个示例Pod(容器组)成功调度到对应的节点上,从而实现基于GPU卡型调度标签的灵活调度。
屏蔽特定卡型
利用GPU卡型调度标签,通过节点亲和性与反亲和性,避免让业务运行在某些卡型上。
将
values: - "Tesla-V100-SXM2-32GB"中Tesla-V100-SXM2-32GB替换为节点实际卡型。创建成功后,应用不会调度到标签键为
aliyun.accelerator/nvidia_name且对应值为Tesla-V100-SXM2-32GB的节点,但允许调度到其他卡型的GPU节点。