在使用Kubernetes集群实现GPU计算时,为了有效利用GPU设备,可使用GPU节点卡型属性标签将应用调度至目标节点。本文介绍GPU节点卡型属性标签基本信息以及如何使业务运行或不运行在指定卡型上。
GPU节点卡型属性标签说明
在ACK集群中扩容GPU节点或者添加GPU节点时,添加节点脚本会自动为该GPU节点打上如下的三个标签。
标签名称 | 描述 |
aliyun.accelerator/nvidia_name | GPU节点的GPU卡型名称。 |
aliyun.accelerator/nvidia_mem | GPU节点的每张卡的显存容量。 |
aliyun.accelerator/nvidia_count | GPU节点总共拥有的GPU卡数。 |
上述三个标签的值可以使用节点上nvidia-smi工具查询。
查询类型 | 查询命令 |
查询卡型 |
|
查询每张卡显存容量 |
|
查询节点上总共拥有的GPU卡数 |
|
在集群中使用如下命令可以查询节点的GPU卡型。
kubectl get nodes -L aliyun.accelerator/nvidia_name
NAME STATUS ROLES AGE VERSION NVIDIA_NAME
cn-shanghai.192.XX.XX.176 Ready <none> 17d v1.26.3-aliyun.1 Tesla-V100-SXM2-32GB
cn-shanghai.192.XX.XX.177 Ready <none> 17d v1.26.3-aliyun.1 Tesla-V100-SXM2-32GB
cn-shanghai.192.XX.XX.130 Ready <none> 18d v1.26.3-aliyun.1 Tesla-V100-SXM2-32GB
cn-shanghai.192.XX.XX.131 Ready <none> 17d v1.26.3-aliyun.1 Tesla-V100-SXM2-32GB
cn-shanghai.192.XX.XX.132 Ready <none> 17d v1.26.3-aliyun.1 Tesla-V100-SXM2-32GB使业务运行在指定卡型上
利用上述GPU属性标签,可以让您的业务运行在指定卡型的节点上,以下为举例说明。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在任务页面右上角,单击使用YAML创建资源。效果如下。
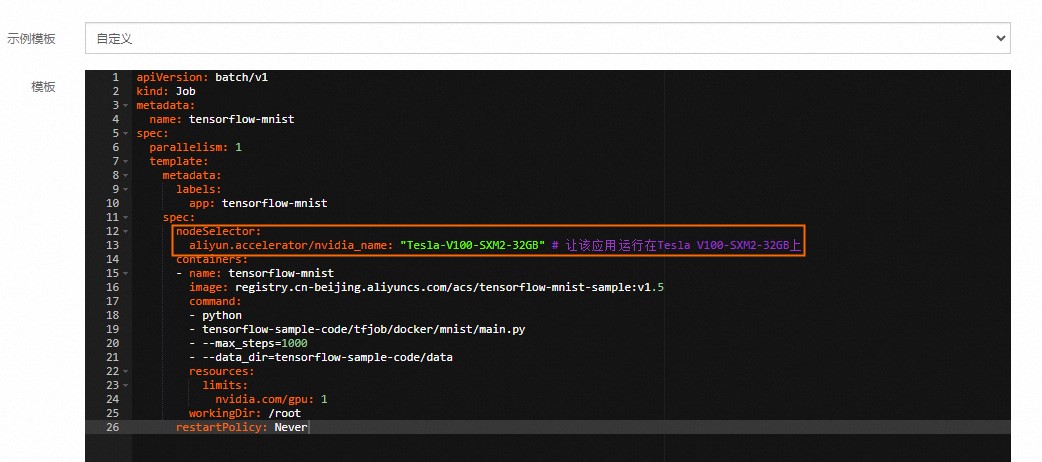
创建成功后,您可以在左侧导航栏中选择。在容器组列表中,您可看到一个示例Pod(容器组)成功调度到对应的节点上,从而实现基于GPU节点标签的灵活调度。
避免业务运行在某些卡型上
您可以利用节点亲和性与反亲和性避免让业务运行在某些卡型上,以下为举例说明。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在任务页面右上角,单击使用YAML创建资源。效果如下。
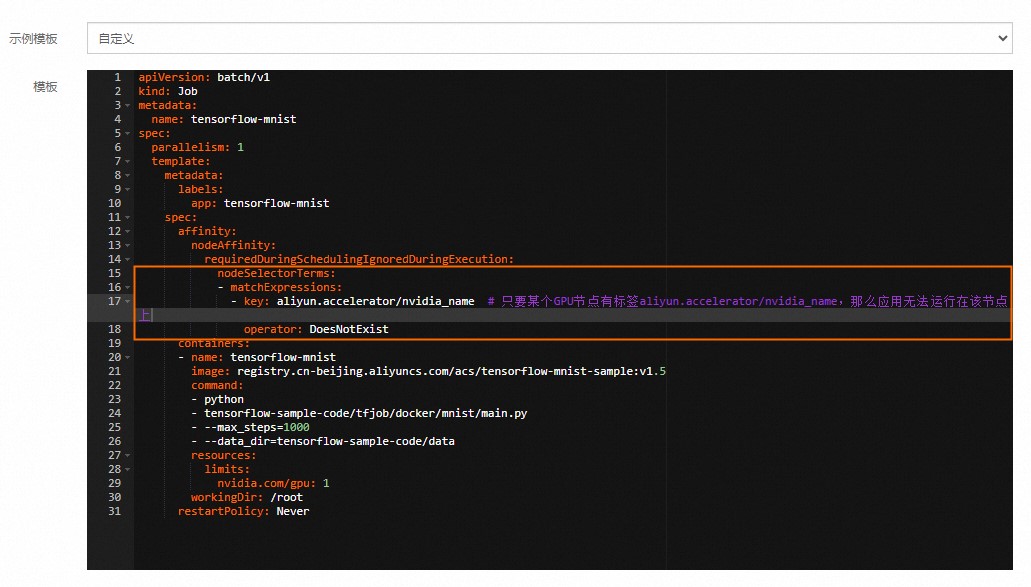
创建成功后,您可以在左侧导航栏中选择。在容器组列表中,您可以看到一个示例Pod(容器组)成功调度到没有标签aliyun.accelerator/nvidia_name的GPU节点上,从而实现基于GPU节点标签的灵活调度。
相关文档
安装云原生AI套件的调度组件ack-ai-installer之后,您可以为GPU节点打上调度属性标签,帮助GPU节点启用共享GPU调度、GPU拓扑感知调度等能力。详细信息,请参见GPU节点调度属性标签。