
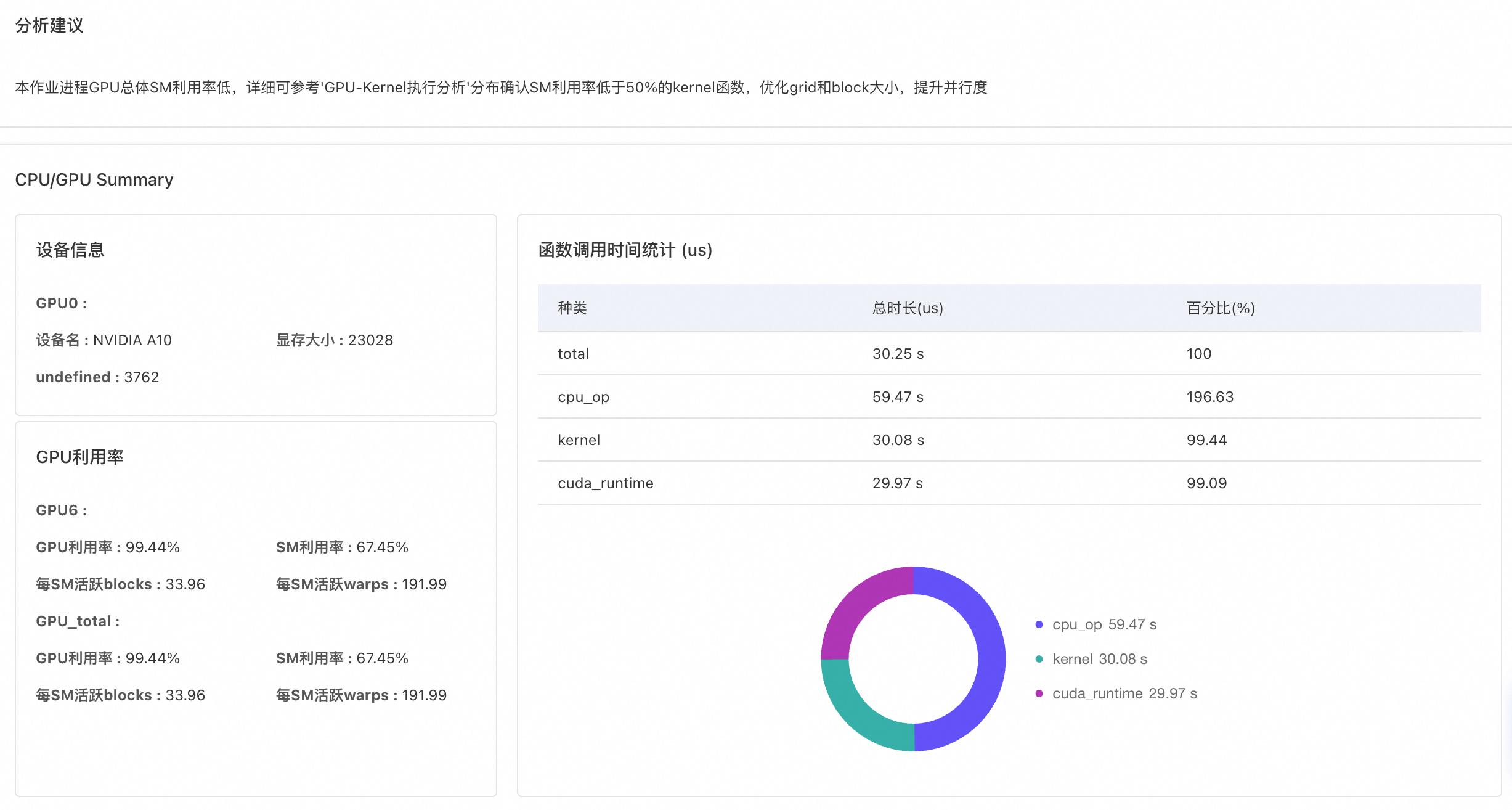
LLM的普及推动了对AI训练与推理的精细化性能检测与调优需求,众多在GPU节点上运行的业务,期望对GPU容器进行在线性能分析。AI Profiling作为基于eBPF和动态进程注入的无侵入式性能分析工具,原生面向Kubernetes容器场景提供,支持对运行GPU任务的容器进程进行在线检测,涵盖多方面的数据采集能力,可以在正在运行的GPU任务上动态启停性能数据采集。而对线上业务来说,可动态挂卸载的Profiling工具可以实时地对在线业务进行较为细致的分析,且无需对业务代码进行修改。本文介绍如何通过控制台触发AI Profiling并查看结果。
操作步骤
AI Profiling 控制台现采用白名单机制,存量用户UID已自动纳入白名单,新用户需通过提交工单申请加入白名单后方可使用。
步骤一:发起诊断
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在故障与性能诊断页面,单击AI Profiling进入AI Profiling页面。
单击诊断进入AI Profiling配置页面,按照页面提示完成配置,其中检测项的可选项参考下表。
采集项
采集项含义
环境支持
示例图
gpu
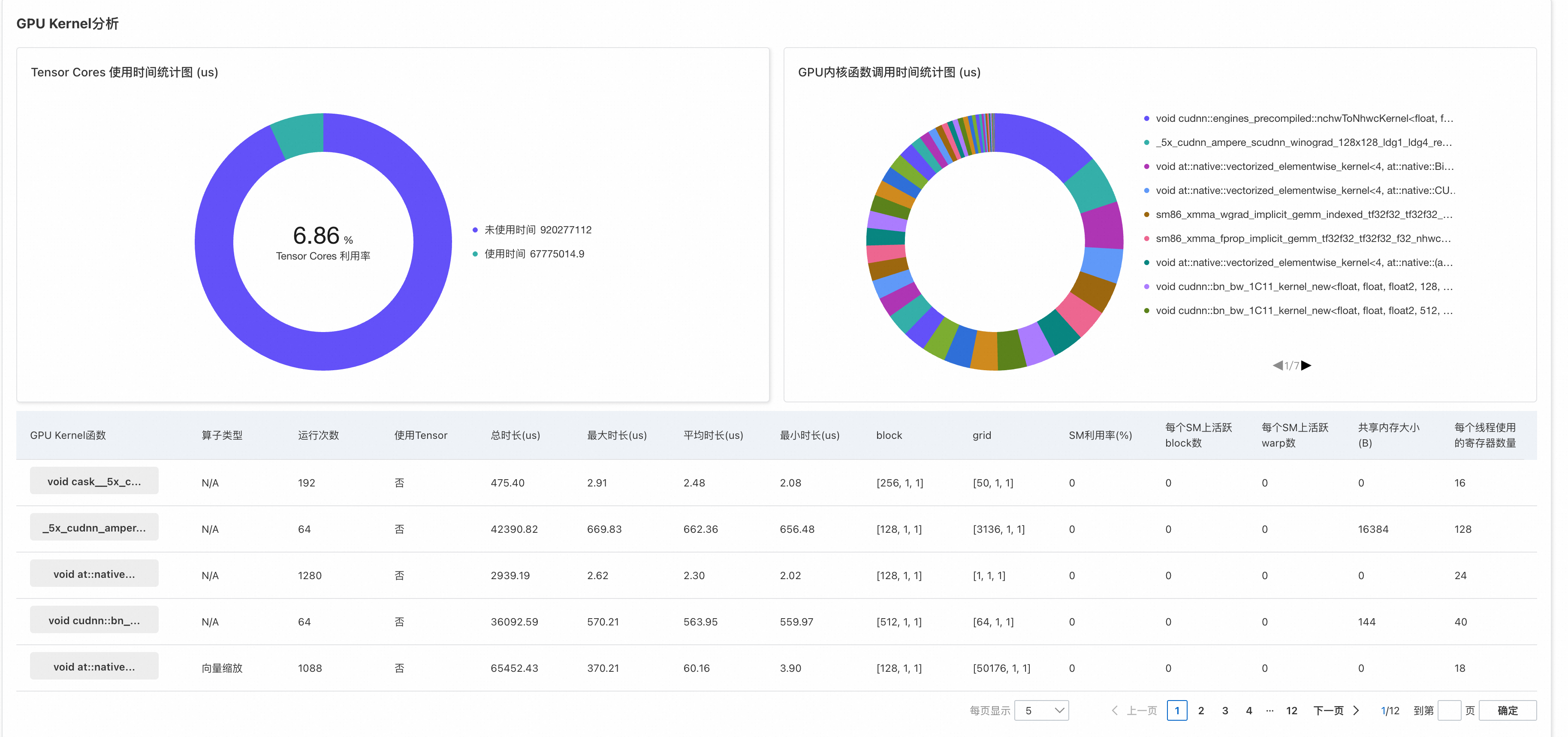
GPU Kernel相关信息
CUDA版本:12.0 ~ 12.8

torch
注入Torch Profiler采集Torch相关信息
Torch版本:≥2.1.0
Python版本:3.9 ~ 3.12
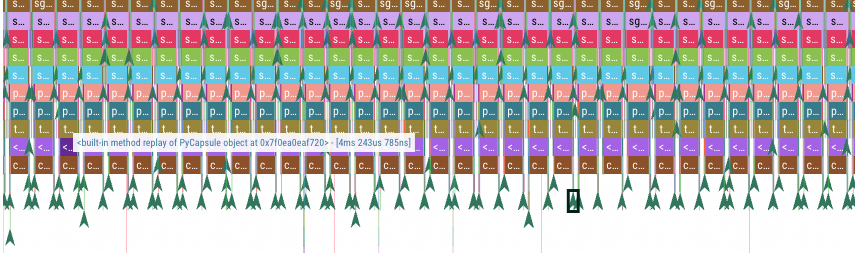
pystack
Python方法调用信息
Python版本:3.9 ~ 3.12
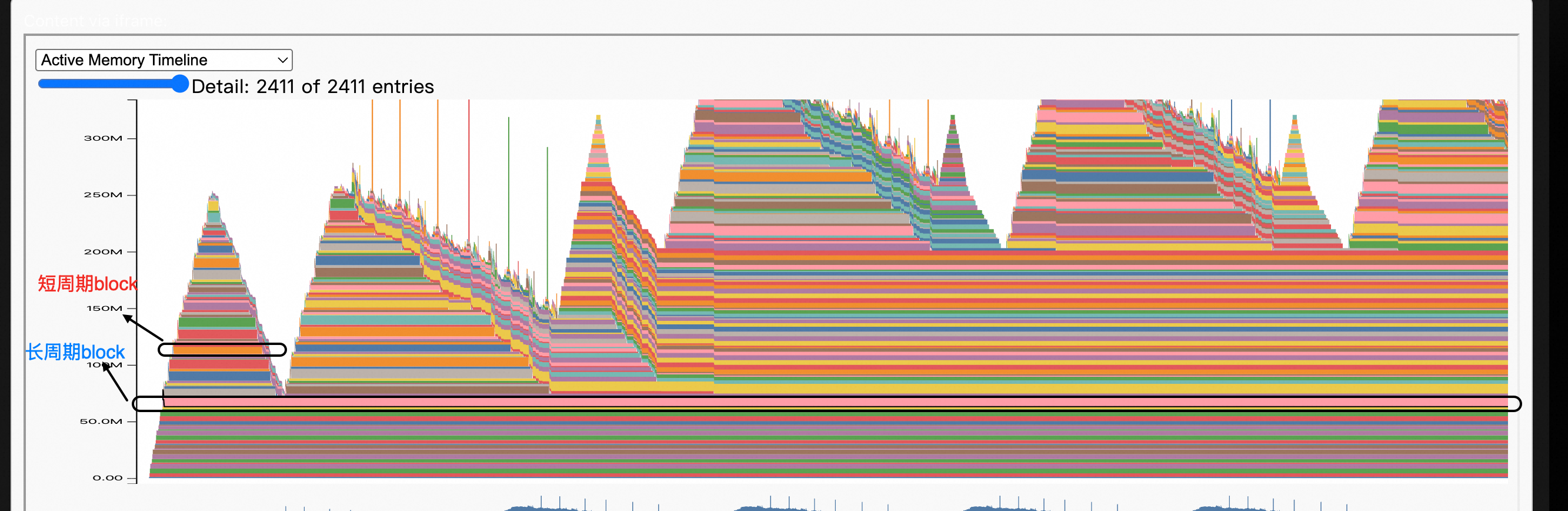
snapshot
采集GPU显存分配、碎片、分配栈等情况
Torch版本:≥2.1.0
Python版本:3.9 ~ 3.12
rdma
RDMA监控信息
需要存在RDMA网卡

dcgm
DCGM监控信息
N/A

nvtx
自定义的NVTX标记
Torch版本:≥2.1.0
代码中标记了NVTX
Python版本:3.9 ~ 3.12
N/A
flops
Torch中的Flops信息
Torch版本:≥2.1.0
Python版本:3.9 ~ 3.12
N/A
shapes
Torch中的Shapes信息
Torch版本:≥2.1.0
Python版本:3.9 ~ 3.12
N/A
net
TCP发送/接收网络数据包的信息
内核版本≥5.10
N/A
依据下表选择参数 Profiling配置 完成后,单击发起诊断。
配置项
说明
示例值
Profiling 配置
检测项
需要选择对应检测项,检测项参考4.中的检测项介绍
gpu, torch, pystack, snapshot, rdma, dcgm, nvtx, flops, shapes, net
检测时长
检测时长建议控制在30s以内,Profiling为实时采集,采集数据过多可能会对您的内存和磁盘产生压力。
5

步骤二:结果展示
等待状态栏变为成功后,可单击诊断详情,查看相应信息。
诊断列表还展示报告ID、诊断类别、诊断对象和诊断时间等信息,操作列中还提供重新诊断入口。
AI Profiling默认使用SysOM对采集结果进行分析和图表展示,单击诊断结果下的点击查看图表,跳转至SysOM控制台查看分析结果。
可以看到如下效果展示:
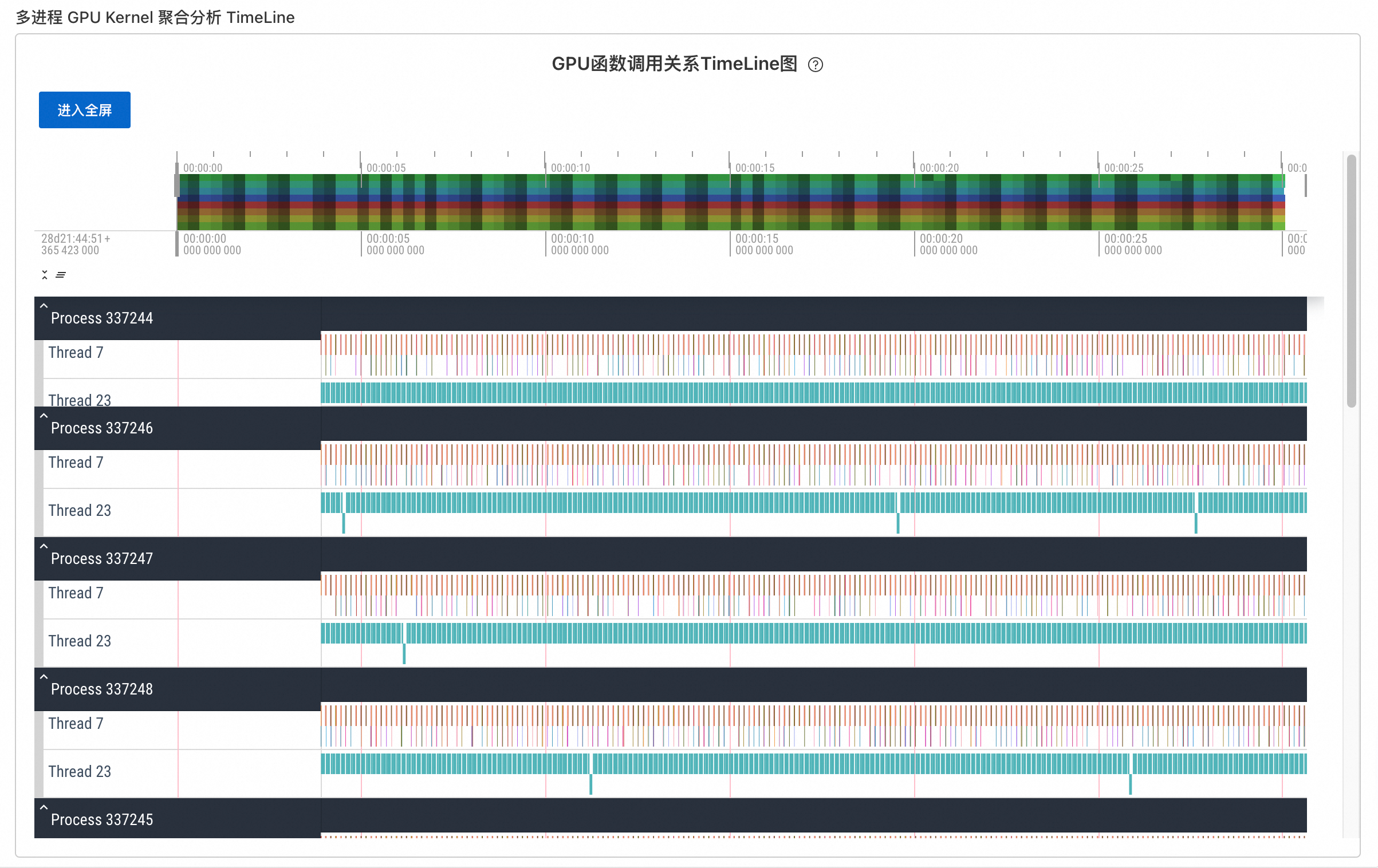
多进程聚合分析进程基础信息概览页面展示采集的进程列表表格,包含进程ID、GPU ID、进程名、设备名、显存总量/MiB、显存占用等列,每行提供跳转单进程报告按钮可查看对应进程的详细分析。
数据分析总览
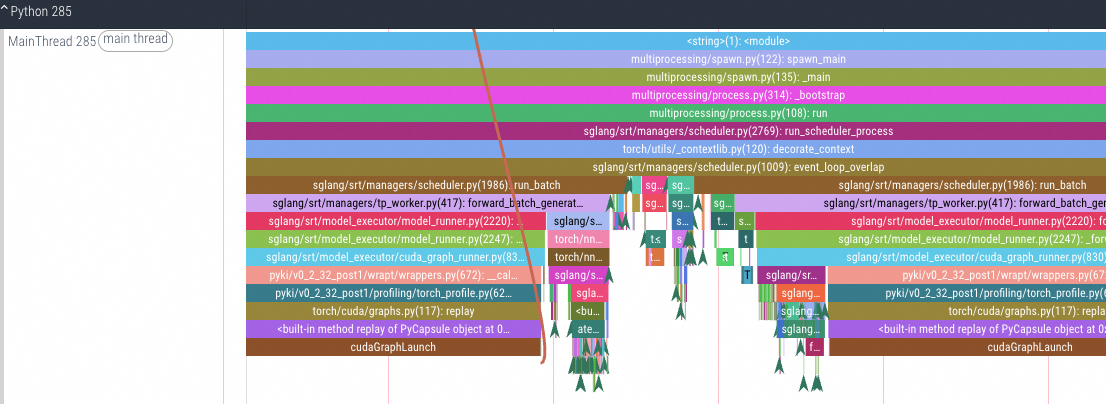
GPU CUDA核函数的细节分析
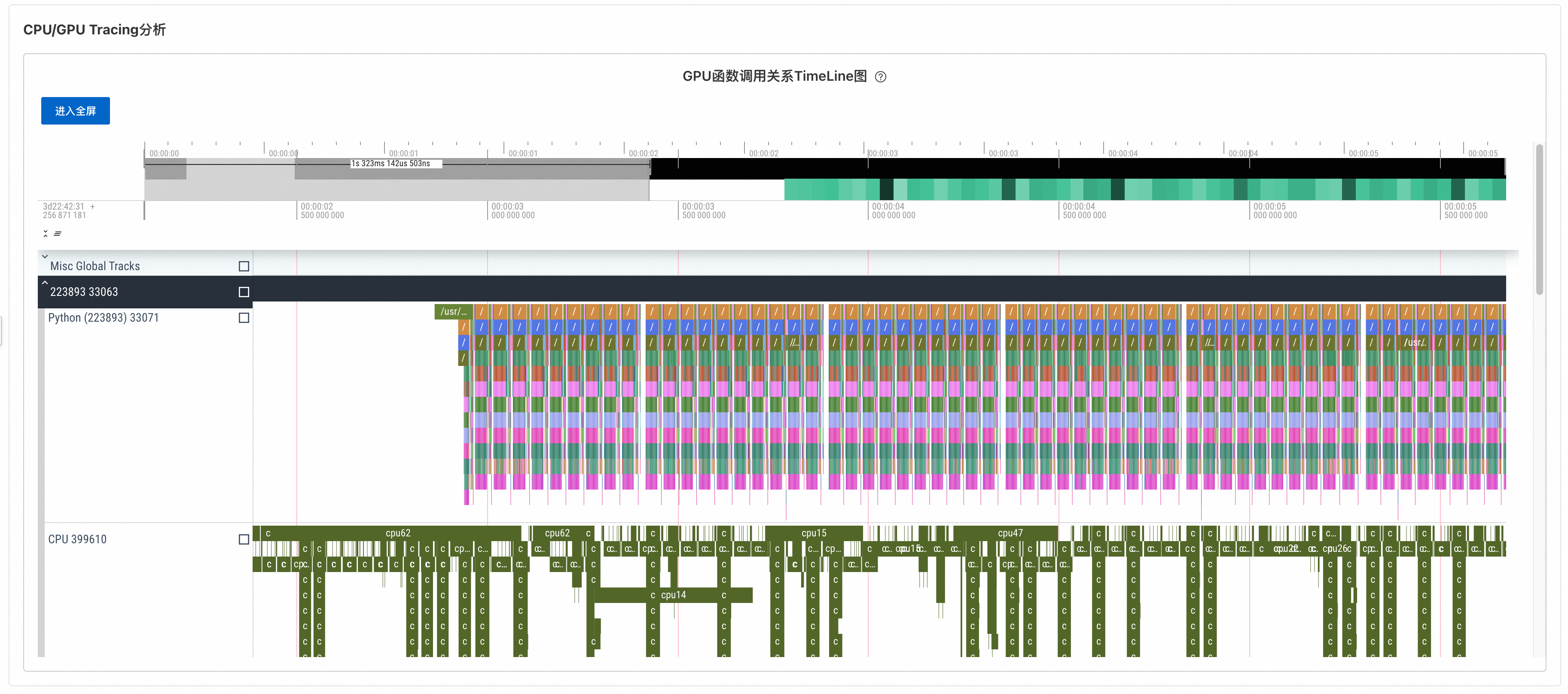
CPU/GPU Tracing分析
步骤三:结果分析
可参见AI Profiling性能分析示例对结果进行分析。