
当部署一个云原生AI集群之后,集群管理员需要对集群资源进行划分,并从多个维度查看集群资源的使用情况,以便及时做出调整,使集群达到最佳的利用率。本文介绍云原生AI集群的基本运维操作,包括安装AI套件、查看资源大盘、管理用户和配额。
背景信息
当部署一个云原生AI集群之后,集群管理员需要对集群资源进行划分,管理多个项目组,并可以从多个维度查看集群资源的使用情况,以便及时作出调整,使集群达到最佳的利用率。
当集群中有多个用户时,为了保障用户有足够的资源使用,管理员会将集群的资源固定分配给不同的用户。传统的方法是通过Kubernetes原生的ResourceQuota方式进行固定资源的分配。但由于小组之间资源忙闲不一,为了集群整体利用率达到最高,需要在确保用户的资源分配的基础上通过资源共享的方式来提升整体资源的利用率。
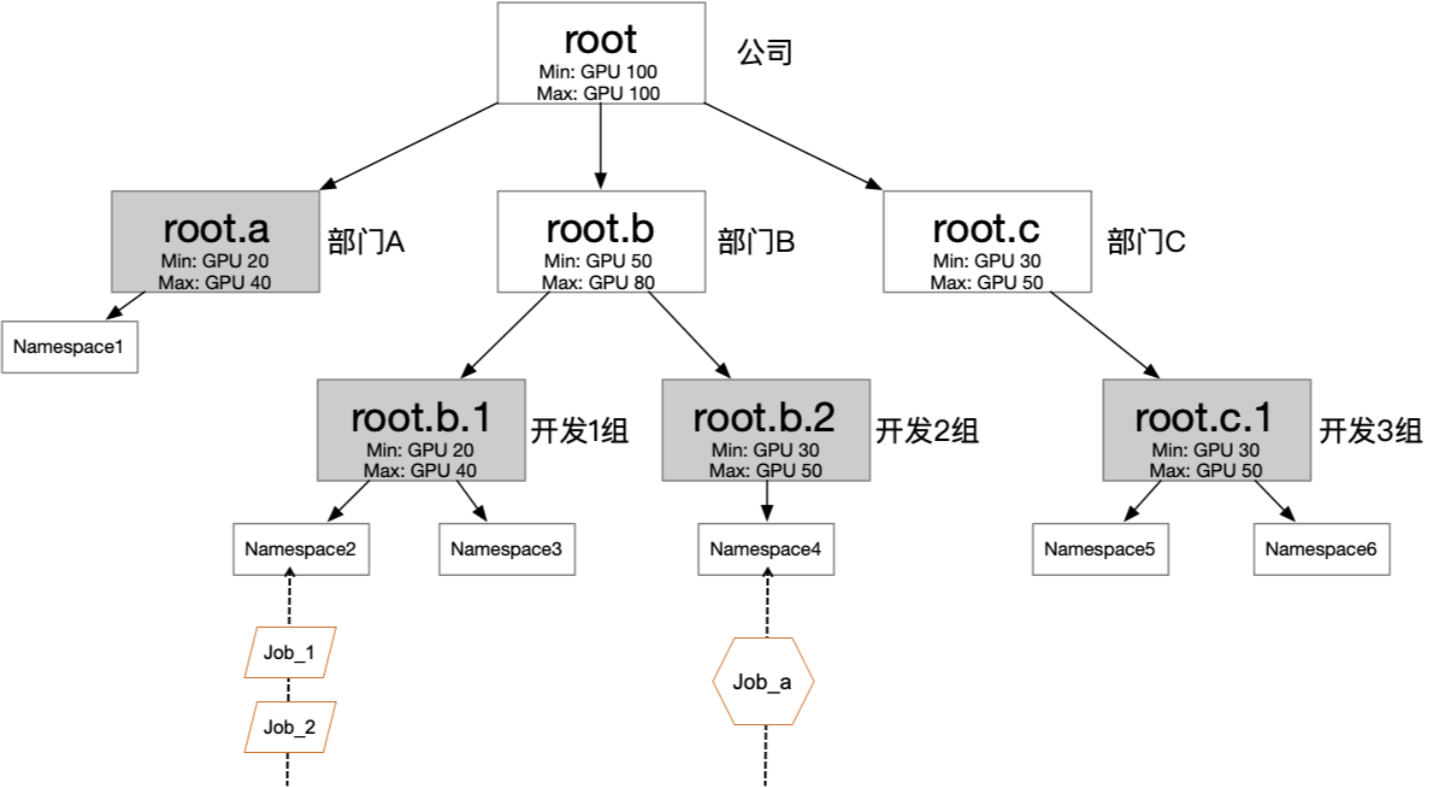
以下图的公司组织结构为例,您可以根据具体情况,配置多个层级的弹性配额。图中每个叶子节点,可对应一个用户组,通过给用户组中的用户分配不同的namespace和role,可以将权限管理和配额管理分开。既可以在组间共享资源,又可以在组内实现隔离。
前提条件
已创建ACK Pro版集群,且在组件配置页面,需要选中监控插件和日志服务。具体操作,请参见创建ACK Pro版集群。
ACK Pro版集群的Kubernetes版本不低于1.18。
目标任务
本指南将指导您完成以下目标任务:
安装云原生AI套件。
查看资源大盘。
以组为单位分配集群配额。
管理用户和用户组。
利用集群空闲资源,提交超出至少可用资源的工作负载。
限制用户使用的最大资源配额。
保证用户随时可用的资源配额。
步骤一:安装云原生AI套件
云原生AI套件作为一款插件化的工具集,包括任务弹性、数据加速、AI任务调度、AI任务生命周期管理、集群运维控制台、端到端研发控制台等组件。您可以根据实际需要自由选择安装。
部署云原生AI套件
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在云原生AI套件页面,单击一键部署。
在一键部署云原生AI套件页面,根据需要选中相应的组件后,单击页面下方的部署云原生AI套件,开始检查环境和依赖项,检查通过后,自动部署选择的组件。
说明交互方式下的Arena命名行(必选)为默认必选组件。
选中云原生AI运维控制台时,会弹出提示话框。具体操作,请参见步骤1。
组件安装成功后,在组件列表页面:
您能看到当前集群中已经安装的组件名称、版本等信息,并能对组件进行部署、卸载操作。
如果已安装的组件有新版本的话,还可以对组件进行升级操作。
安装了云原生AI运维控制台组件(ack-ai-dashboard)后,您可在页面左上方看到运维控制台访问地址,通过该地址可以访问运维控制台页面。
安装配置云原生AI运维控制台
阿里云提供的AI控制台(包括开发控制台、运维控制台)于2025年01月22日起以白名单功能的形式开放。如果您在白名单开放前已部署开发控制台或运维控制台,您的使用将不会受到影响。未加入白名单的用户,可以从开源社区安装配置AI套件控制台。关于开源配置的详细操作,请参见开源AI控制台。
在云原生AI套件部署页面的交互方式区域,选中示例控制台,弹出提示对话框。
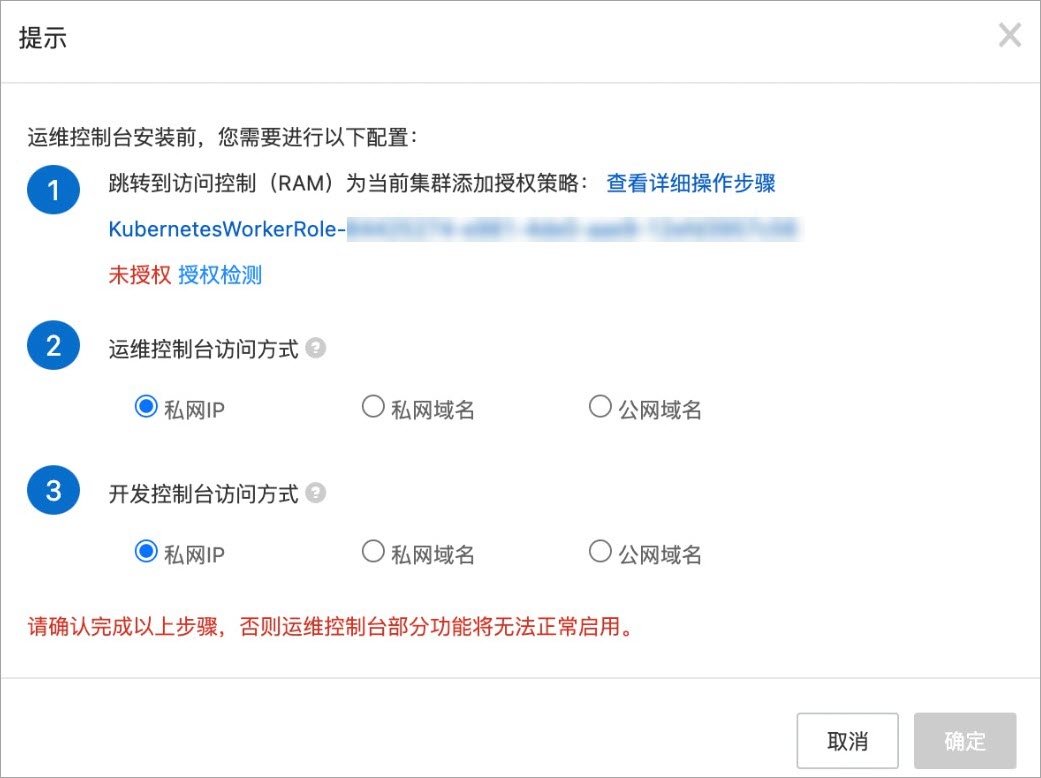
创建自定义权限策略并对RAM角色进行授权。
创建自定义权限策略。
登录RAM控制台,在左侧导航栏选择权限管理>权限策略。
单击创建权限策略。
单击脚本编辑页签。添加以下策略信息,单击确定,在名称文本框中输入自定义权限策略的名称,格式需设置为
k8sWorkerRolePolicy-{ClusterID},名称设置完成后单击确定即可。{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "cs:*", "log:GetProject", "log:GetLogStore", "log:GetConfig", "log:GetMachineGroup", "log:GetAppliedMachineGroups", "log:GetAppliedConfigs", "log:GetIndex", "log:GetSavedSearch", "log:GetDashboard", "log:GetJob", "ecs:DescribeInstances", "ecs:DescribeSpotPriceHistory", "ecs:DescribePrice", "eci:DescribeContainerGroups", "eci:DescribeContainerGroupPrice", "log:GetLogStoreLogs", "ims:CreateApplication", "ims:UpdateApplication", "ims:GetApplication", "ims:ListApplications", "ims:DeleteApplication", "ims:CreateAppSecret", "ims:GetAppSecret", "ims:ListAppSecretIds", "ims:ListUsers" ], "Resource": "*" } ] }
对目标容器集群的RAM角色授权。
登录RAM控制台,在左侧导航栏选择身份管理>角色。
在文本框中输入目标角色名称,格式为
KubernetesWorkerRole-{ClusterID}。单击目标角色名称后操作列的新增授权。在权限策略区域,在文本框中输入之前创建的自定义权限策略名称,格式为
k8sWorkerRolePolicy-{ClusterID}。选中策略名称后,单击确认新增授权。
返回容器服务ACK控制台的提示对话框,单击授权检测。如果授权成功,授权状态显示为已授权,且确定按钮可用。请执行步骤3。
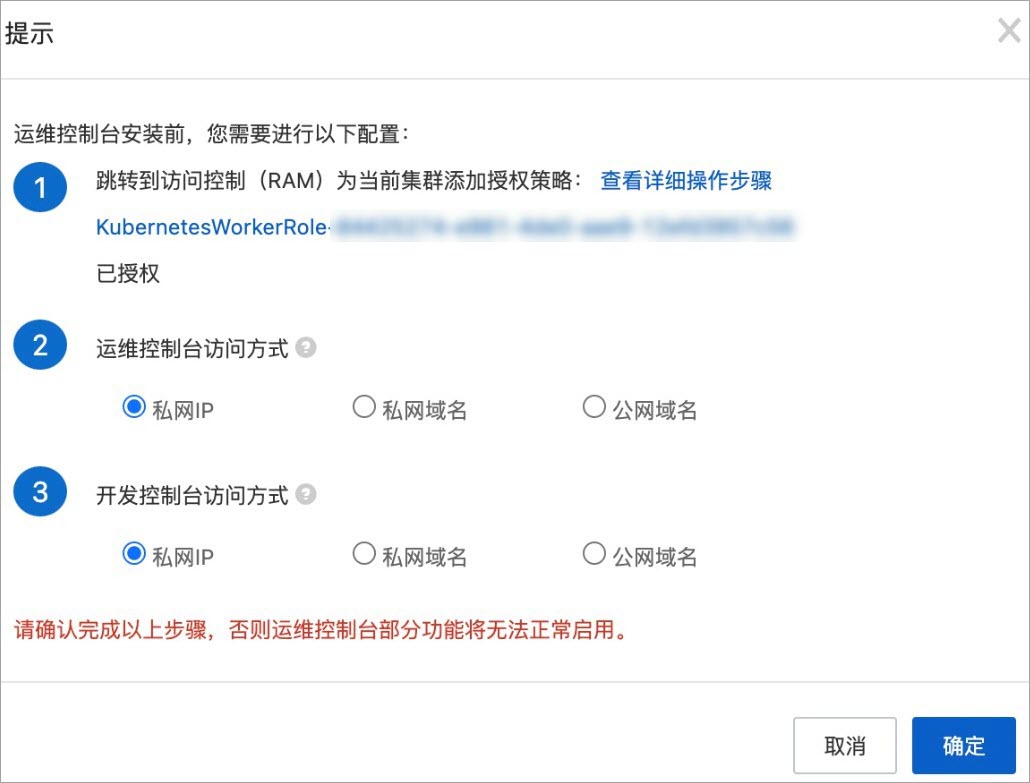
选择控制台数据存储方式。
本文以选择集群内置MySQL为例进行说明,实际使用时可替换为阿里云RDS。详细说明,请参见安装配置云原生AI控制台。
单击部署云原生AI套件。
待运维控制台处于Ready状态后,即可正常使用。
初始化数据集(可选)
管理员可按照算法开发人员的需求,创建和加速数据集。这里演示如何通过运维控制台或命令行创建数据集。
fashion-mnist数据集
管理员通过kubectl命令行在可以访问集群的机器上,新建OSS类型的PV和PVC。
根据以下命令创建命名空间namespace: demo-ns。
kubectl create ns demo-ns根据YAML示例新建fashion-mnist.yaml。
apiVersion: v1 kind: PersistentVolume metadata: name: fashion-demo-pv spec: accessModes: - ReadWriteMany capacity: storage: 10Gi csi: driver: ossplugin.csi.alibabacloud.com volumeAttributes: bucket: fashion-mnist otherOpts: "-o max_stat_cache_size=0 -o allow_other" url: oss-cn-beijing.aliyuncs.com akId: "AKID" akSecret: "AKSECRET" volumeHandle: fashion-demo-pv persistentVolumeReclaimPolicy: Retain storageClassName: oss volumeMode: Filesystem --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: fashion-demo-pvc namespace: demo-ns spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: fashion-demo-pv storageClassName: oss volumeMode: Filesystem volumeName: fashion-demo-pv配置项
说明
name: fashion-demo-pv
设定PV持久卷的名称。与PVC持久卷声明name: fashion-demo-pvc对应。
storage: 10Gi
设定该PV的存储容量为10GiB。
bucket: fashion-mnist
设定OSS bucket的名称。
url: oss-cn-beijing.aliyuncs.com
设定您OSS服务的endpoint,示例中指的是阿里云北京区域的OSS服务地址。
akId: "AKID"
akSecret: "AKSECRET"
分别用来设定阿里云的AccessKey ID和Access Key Secret,用于认证和授权访问OSS资源。
namespace: demo-ns
设定命名空间的名称。
执行以下命令创建PV和PVC。
kubectl create -f fashion-mnist.yaml查看确认PV和PVC状态。
执行以下命令,确认PV状态。
kubectl get pv fashion-demo-pv -ndemo-ns预期输出:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE fashion-demo-pv 10Gi RWX Retain Bound demo-ns/fashion-demo-pvc oss 8h执行以下命令,确认PVC状态。
kubectl get pvc fashion-demo-pvc -ndemo-ns预期输出:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE fashion-demo-pvc Bound fashion-demo-pv 10Gi RWX oss 8h
创建加速数据集
管理员可通过AI运维控制台加速目标数据集。本示例介绍如何对demo-ns命名空间下的fashion-demo-pvc数据集进行加速。
- 使用管理员账号访问AI运维控制台。
- 在AI运维控制台左侧导航栏中,选择。
在数据集列表页面,单击目标数据集右侧操作列的一键加速。
加速后的数据集如下图所示:

步骤二:查看资源大盘
云原生AI套件中的运维控制台,提供了集群资源大盘,可多维度查看集群实时使用情况,方便调优集群资源分配,优化集群资源使用率。
阿里云提供的AI控制台(包括开发控制台、运维控制台)于2025年01月22日起以白名单功能的形式开放。如果您在白名单开放前已部署开发控制台或运维控制台,您的使用将不会受到影响。未加入白名单的用户,可以从开源社区安装配置AI套件控制台。关于开源配置的详细操作,请参见开源AI控制台。
集群监控大盘
打开云原生AI运维控制台后,默认进入的是集群监控大盘页面。集群监控大盘可供您查看以下指标:
GPU Summary Of Cluster:展示集群中总的GPU节点数、已分配的GPU节点数、不健康的GPU节点数。
Total GPU Nodes:集群中总的GPU节点数。
Unhealthy GPU Nodes:不健康的GPU节点数。
GPU Memory(Used/Total):集群已使用GPU显存与总的GPU显存的百分比。
GPU Memory(Allocated/Total):集群已分配GPU显存与总的GPU显存百分比。
GPU Utilization:集群GPU的平均利用率。
GPUs(Allocated/Total):集群已分配GPU卡的个数与总的GPU卡数的百分比。
Training Job Summary Of Cluster:集群中各种状态(Running、Pending、Succeeded、Failed)的训练任务数。
节点监控大盘
在集群监控大盘页面,单击右上角的Nodes,进入节点监控大盘。节点监控大盘可供您查看以下指标:
GPU Node Details:以表格的形式展示集群节点的相关信息,包括:节点名称(Name)、节点在集群中的IP(IP)、节点在集群中的角色(Role)、节点的状态(Status)、GPU模式:独占或共享(GPU Mode)、节点拥有GPU卡的个数(Total GPUs)、节点拥有的总GPU显存(Total GPU Memory)、节点已分配GPU卡数(Allocated GPUs)、节点已分配GPU显存(Allocated GPU Memory)、节点已使用GPU显存(Used GPU Memory)、节点GPU平均使用率(GPU Utilization)。
GPU Duty Cycle:每个节点的每个GPU的使用率。
GPU Memory Usage:每个节点的每个GPU的显存使用量。
GPU Memory Usage Percentage:每个节点的每个GPU的显存使用百分比。
Allocated GPUs Per Node:每个节点已分配的GPU卡数。
GPU Number Per Node:每个节点的总GPU卡数。
Total GPU Memory Per Node:每个节点的总GPU显存。
训练任务监控大盘
在节点监控大盘页面,单击右上角TrainingJobs,进入训练任务的监控大盘。训练任务监控大盘可供您查看以下指标:
Training Jobs:通过表格的形式展示各个训练任务的情况,包括:训练任务所在命名空间(Namespace)、训练任务名称(Job Name)、训练任务类型(Job Type)、训练任务状态(Job Status)、训练任务持续时间(Duration)、训练任务请求GPU卡数(Request GPUs)、训练任务请求的GPU显存(Allocated GPU Memory)、训练任务当前使用的GPU显存(Used GPU Memory)、训练任务的GPU平均利用率(GPU Utilization)。
Job Instance Used GPU Memory:训练任务中的各个实例的已使用GPU显存。
Job Instance Used GPU Memory Percentage:训练任务中各个实例使用GPU显存的百分比。
Job Instance GPU Duty Cycle:训练任务中各个实例的GPU利用率。
资源配额监控大盘
在训练任务监控大盘页面,单击右上角的Quota,进入资源配额监控大盘。资源配额监控大盘可供您查看以下指标:Quota(cpu)、Quota(memory)、Quota(nvidia.com/gpu)、Quota(aliyun.com/gpu-mem)、Quota(aliyun.com/gpu)。每一个指标都以表格的形式展示以下资源配额的相关信息:
Elastic Quota Name:资源配额的名称。
Namespace:资源所属的Namespace。
Resource Name:资源类型的名称。
Max Quota:您在某个Namespace下某种资源所使用的上限。
Min Quota:当整个集群资源紧张时,您在某个Namespace下可以使用的保障资源。
Used Quota: 您在某个Namespace下,某种资源的已使用值。
步骤三:管理用户和配额
云原生AI套件通过用户(User)、用户组(UserGroup)、配额树(QuotaTree)/配额节点(QuotaNode)、K8s Namespace等实体来管理用户和配额。这些概念的关联关系,如下图所示。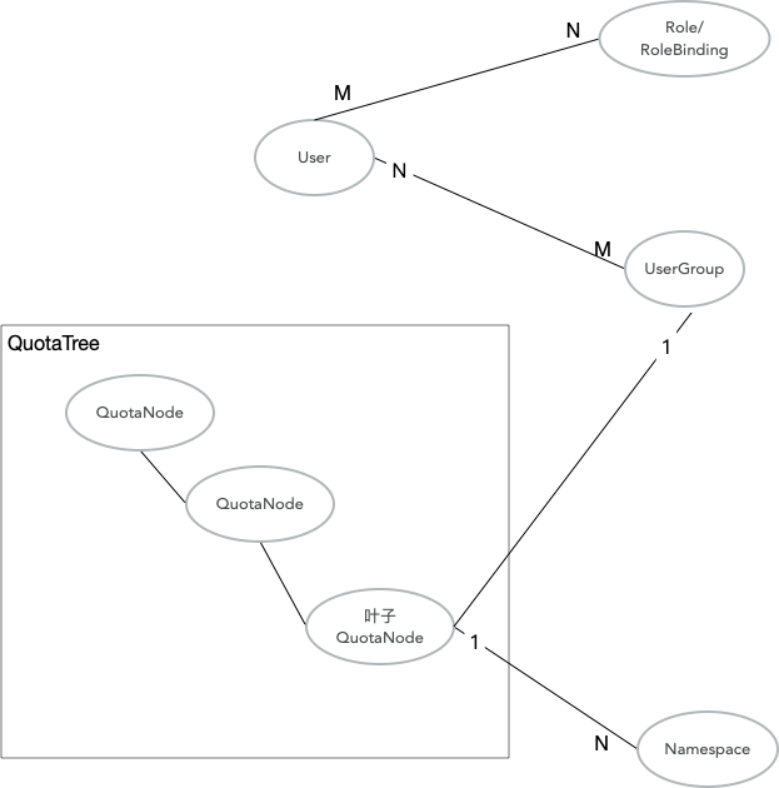
配额树是配置多层级约束的资源,供Capacity Scheduling Plugin使用。可以确保用户资源分配的基础上通过资源共享的方式来提升集群的整体资源利用率。
云原生AI套件的用户一一对应一个K8s ServiceAccount,是提交任务和登录控制台的凭证。用户根据用户类型确定权限,其中admin负责运维集群,可登录运维控制台;researcher负责提交任务,使用集群资源,可登录开发控制台;admin包含researcher的所有权限。
用户组是资源分配中的最小单位,并与QuotaTree的叶子节点一一对应。用户必须关联用户组,才能使用与之关联的配额资源。
本步骤将介绍如何通过配额树来配置多层级的配额约束、通过用户组来分配配额给组用户以及通过提交简单的任务,演示CPU资源的弹性借还。
添加配额节点,并限定资源使用额度
配额是通过设置各资源的Min/Max来配置额度,其中Min表示有保障的资源数量(Guaranteed Resource),Max表示最大可用的资源数。把namespace挂载在配额树的叶子节点,就意味着namespace受根节点到当前叶子节点路径上的所有约束。
如果namespace不存在,需要提前手动创建namespace。如果namespace已存在,需要保证namespace下没有Running的Pod。
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4创建配额节点,并关联namespace。
创建用户和用户组
用户和用户组是多对多的关系,一个用户可以属于多个用户组,一个用户组也可以有多个用户。您可以通过用户关联用户组,也可以通过用户组关联用户。通过配额树和用户组,可以方便地根据实际项目组划分资源,分配权限。
创建用户。具体操作请参见为新增用户生成KubeConfig和登录Token。
创建用户组。具体操作请参见新增用户组。
Capacity调度功能演示
本演示将通过创建CPU Pod,演示Capacity调度功能如何借用和抢占资源,从而保证每个配额节点的Min和Max约束。演示的设计流程如下所示:
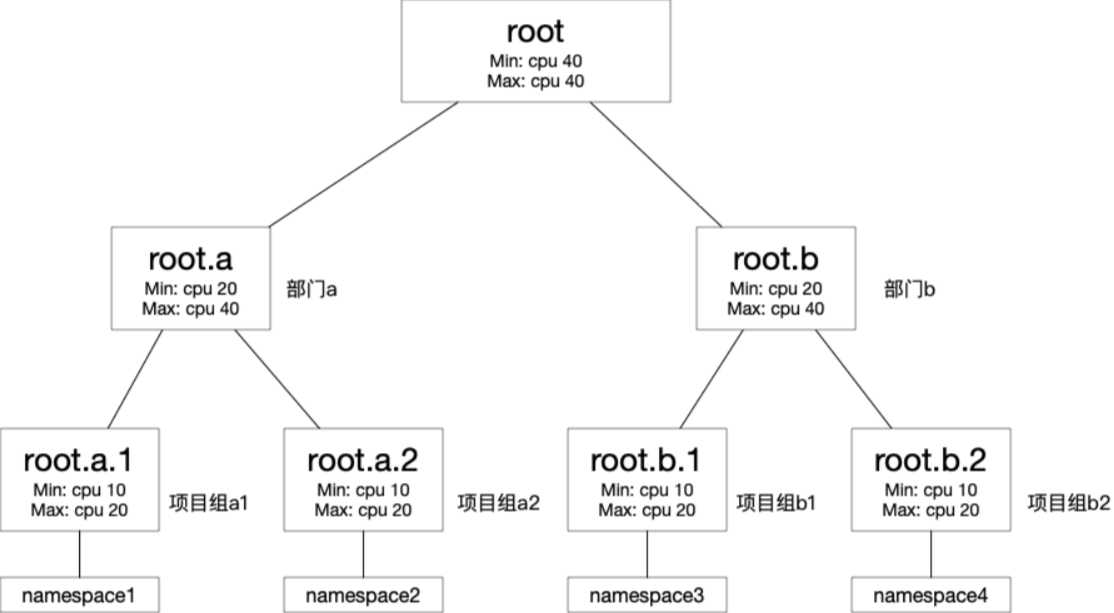
通过配置root节点的Min和Max均为40,使得配额树整体拥有40核CPU的资源。
使root.a和root.b均分CPU资源,各保障有20核,最大可利用40核。
root.a.1、root.a.2及root.b.1、root.b.2,各保障10核,最大可利用20核。
通过提交一个5副本的任务(5副本 x 5核/副本=25核)到namespace1,预期可成功运行4个副本(4副本 x 5核/副本=20核),即root.a.1的Max(最大可用配额)。
通过提交一个5副本的任务(5副本 x 5核/副本=25核)到namespace2,预期可成功运行4个副本(4副本 x 5核/副本=20核),即root.a.2的Max(最大可用配额)。
通过提交一个5副本的任务(5副本 x 5核/副本=25核)到namespace3,预期可成功运行2个副本(2副本 x 5核/副本=10核),即root.b.1的Min(最少可用配额)。这时调度器会综合优先级、可用性以及创建时间等因素,选择root.a下相应的Pod抢占,归还之前抢占的资源。考虑到公平性,root.a.1和root.a.2的pod会分别被抢占一个。这时namespace1和namespace2下分别有3个副本(皆为:3副本 x 5核/副本=15核)
通过提交一个5副本的任务(5副本 x 5核/副本=25核)到namespace4,预期可成功运行2个副本(2副本 x 5核/副本=10核),即root.b.2的Min(最少可用配额)。
具体操作步骤如下所示。
新建namespace及配额树。
执行以下命令,分别创建四个对应的Namespace。
已创建namespace1为例:
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4根据下图,建立配额树。

使用以下YAML文件样例,在namespace1中部署服务,Pod的副本数为5个,每个Pod请求CPU资源量为5核。
如果没有弹性配额,用户最多只能使用10核(cpu.min=10),也就是建立2个副本。但在弹性配额Capacity调度下:
当集群有空闲的40核CPU时,可以创建4个副本(4副本 x 5核/副本=20核)。
最后一个副本因为超出最大资源限制(cpu.max=20),处于Pending状态。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx1 namespace: namespace1 labels: app: nginx1 spec: replicas: 5 selector: matchLabels: app: nginx1 template: metadata: name: nginx1 labels: app: nginx1 spec: containers: - name: nginx1 image: nginx resources: limits: cpu: 5 requests: cpu: 5使用以下YAML文件样例,在namespace2中部署服务,Pod的副本数为5个,每个Pod请求CPU资源量为5核。
如果没有弹性配额,用户最多只能使用10个CPU(cpu.min=10),只能建立2个副本。但在弹性配额Capacity调度下:
在集群资源有20核(40核-namespace1中的20核)空闲,可以创建4个副本(4副本 x 5核/副本=20核)。
最后一个副本因为超出最大资源限制(cpu.max=20),处于Pending状态。
此时集群中namespace1和namespace2中的Pod所占用的资源已经达到了root设置的root.max.cpu=40。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx2 namespace: namespace2 labels: app: nginx2 spec: replicas: 5 selector: matchLabels: app: nginx2 template: metadata: name: nginx2 labels: app: nginx2 spec: containers: - name: nginx2 image: nginx resources: limits: cpu: 5 requests: cpu: 5使用以下YAML文件样例,在namespace3中部署服务,其中Pod的副本数为5,每个Pod请求CPU资源量为5核。
集群无资源空闲,但是为了保障root.b.1的Min(最少可用配额),需要抢占root.a中的pod归还10核。
调度器会综合考虑root.a下作业的优先级、可用性以及创建时间等因素,选择相应的Pod归还之前抢占的资源(10核)。因此,nginx3得到配额min.cpu=10的资源量后,有2个Pod处于Running状态,其他3个仍处于Pending状态。
root.a被抢占后,namespace1下有2个pod处于Running,3个处于Pending;namespace2下也有2个pod处于Running,3个处于Pending。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx3 namespace: namespace3 labels: app: nginx3 spec: replicas: 5 selector: matchLabels: app: nginx3 template: metadata: name: nginx3 labels: app: nginx3 spec: containers: - name: nginx3 image: nginx resources: limits: cpu: 5 requests: cpu: 5使用以下YAML文件样例,在namespace4中部署服务,其中Pod的副本数为5个,每个Pod请求CPU资源量为5核
这时调度器会综合优先级、可用性以及创建时间等因素,选择root.a下相应的Pod抢占,归还之前抢占的资源。
考虑到公平性,root.a.1和root.a.2的pod会分别被抢占一个。这时,在namespace1下有2个pod*5核/副本=10核。在namespace2下,也有2个pod*5核/副本=10核。这时namespace1和namespace2下分别有2个副本(皆为:2副本 x 5核/副本=10核)。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx4 namespace: namespace4 labels: app: nginx4 spec: replicas: 5 selector: matchLabels: app: nginx4 template: metadata: name: nginx4 labels: app: nginx4 spec: containers: - name: nginx4 image: nginx resources: limits: cpu: 5 requests: cpu: 5
通过以上演示,有效验证了Capacity调度在弹性分配资源中的优势。