
为了提高训练任务的灵活性、稳定性和效率,建议使用云原生AI套件中的弹性训练功能。对于短时运行的任务和容错率高的无状态应用,可以在ACK中使用ACS BestEffort容器算力来降低成本。结合弹性训练SDK Kubeai,可以有效监控和快速响应实例状态。当资源紧张时,系统会立即通知应用层采取措施。BestEffort实例不保证具体资源量,适合对延迟和性能要求较低的应用,如可弹性伸缩的Web服务、图像渲染、音视频转码、大数据分析和大规模并行计算等。
安装elastic-job-supervisor
安装elastic-job-supervisor是为了管理和调度分布式任务,确保在分布式环境下任务能够被高效、准确地执行。在云原生AI套件页面中,确认ack-arena组件的安装版本不低于0.13.1,并确认安装包中的elastic-job-supervisor已启用(默认设置即为启用)。随后在arena-system命名空间下检查elastic-job-supervisor的Pod状态。若这些Pod运行无异常,则表明组件安装成功。
安装
ack-arena组件。elastic-job-supervisor已包含在ack-arena组件中,您只需在云原生AI套件界面安装ack-arena组件即可。
检查
elastic-job-supervisor是否运行正常。确保
elastic-job-supervisor的enable为true(默认不修改即为true)。且确保ack-arena的安装版本大于等于0.13.1,单击查看以下图中的基本信息即可。
确保
elastic-job-supervisor的Pod处于Running状态。
使用说明
为Pod节点添加标签。
对于带
best-effort标签的Pod,其特点是没有设置任何资源请求(requests)或限制(limits),使用ACK中ACS BestEffort Pod可降低计算资源的使用成本,也意味着它们在使用集群资源时会有较大扰动,且可能被抢占和驱逐,适合那些对延迟和性能要求相对宽松的应用场景。您可以参考以下代码示例,为Pod添加一个特定标签,以标识其为BestEffort类型的Pod。如果您想要了解更多信息,请参见BestEffort算力质量概述。alibabacloud.com/compute-qos: best-effort为Pod节点添加注解。
ACS BestEffort的Pod回收感知机制用于在节点资源紧张时,优先保证有资源请求的Pod,通过驱逐无资源保障的ACS BestEffort Pod来释放资源。在ACK中,BestEffort类型的ACS实例Pod需要接入
elastic-job-supervisor才能实现回收感知功能。您需要在Pod的Annotation添加如下的注解,表明该Pod的生命周期可以被elastic-job-supervisor管理。job-supervisor.kube-ai.io/managed-by-job-supervisor: "true"业务代码集成感知实例回收信号。
如果您需要在业务代码中添加感知实例回收信号,您可以参考以下代码示例来实现该功能。
操作步骤
本文使用Arena工具在ACK集群上提交了一个基于Horovod的弹性深度学习训练任务,并配置了抢占式实例以优化成本。该任务设置了8个初始Worker,最小Worker数为1,最大Worker数可达128,实现基于抢占式实例的弹性训练。
执行以下命令,使用pip下载kubeai的依赖库。
pip install kubeai获取示例代码与数据集进行实践测试。
如下所示,在使用kubeai弹性训练组件(Job-Supervisor)时,为实现基于抢占式实例释放信号进行通知的Checkpoint机制,您还需要对原有训练脚本做出适应性修改。
import kubeai.elastic as kubeai if __name__ == '__main__': args = parser.parse_args() args.cuda = not args.no_cuda and torch.cuda.is_available() logging.info(f"start training job {args.name}") allreduce_batch_size = args.batch_size * args.batches_per_allreduce # 通过hvd.init()初始化Horovod分布式训练环境。 hvd.init() # 通过kubeai.init()初始化与kubeai弹性训练组件的连接,以便能够接收抢占式实例释放的信号。 kubeai.init() ... # 2) 恢复检查点。 if args.skip_restore == False and hvd.rank() == 0: for try_epoch in range(args.epochs, 0, -1): # 从能找到的最新的check开始进行训练 if os.path.exists(args.checkpoint_format.format(epoch=try_epoch)): resume_from_epoch = try_epoch break if resume_from_epoch > 0: logging.info("load checkpoint") filepath = args.checkpoint_format.format(epoch=resume_from_epoch) checkpoint = torch.load(filepath) model.load_state_dict(checkpoint['model']) # model optimizer.load_state_dict(checkpoint['optimizer']) # optimizer train_sampler.load_state_dict(checkpoint['sampler']) # sampler def train(state): ... with tqdm(total=len(train_loader), desc='Train Epoch #{}'.format(epoch + 1), disable=not verbose) as t: for idx, (data, target) in enumerate(train_loader): ... # 3)在训练每个批次数据之前,调用kubeai.check_alive()来检测当前训练任务是否还在运行(即实例是否已被抢占)。如果返回值为False,表示实例可能已被释放,此时触发保存当前训练状态(checkpoint),并退出程序(sys.exit(-1))。 if kubeai.check_alive() == False : save_checkpoint(state.epoch) sys.exit(-1) def validate(epoch): ... with tqdm(total=len(val_loader), desc='Validate Epoch #{}'.format(epoch + 1), disable=not verbose) as t: with torch.no_grad(): for data, target in val_loader: # 4) 验证每个批次数据之前检测当前训练任务是否还在运行。当检测到实例被抢占时,保存当前训练状态并退出程序。 if kubeai.check_alive() == False : save_checkpoint(state.epoch) sys.exit(-1)对于以上的更改,在每个训练和评估的步骤结束后判断是否需要进行Checkpoint,并在获取到释放信号的最近一个步骤后进行Checkpoint。由于收到信号后会有5分钟的回收缓冲时间,所以在每个训练Step+Checkpoint的时间控制在5分钟之内即可保证模型训练结果的及时保存。
执行以下命令,使用Arena在集群中提交该弹性训练任务。
arena submit etjob \ --loglevel=debug \ --spot-instance \ --max-wait-time=600 \ --job-restart-policy=OnFailure \ --job-backoff-limit=3 \ --worker-restart-policy=Always \ --launcher-selector=instance_type=spot-launcher \ --toleration=all \ --namespace=default \ --name=fine-tuning-elastic \ --gpus=1 \ --memory=16Gi \ --cpu=4 \ --workers=8 \ --max-workers=128 \ --min-workers=1 \ --image=registry.cn-beijing.aliyuncs.com/acs/bert-elastic-demo:v1.5 \ "horovodrun --log-level DEBUG --verbose -np \$((\${workers}*\${gpus})) --min-np \$((\${minWorkers}*\${gpus})) --max-np \$((\${maxWorkers}*\${gpus})) --host-discovery-script /etc/edl/discover_hosts.sh python /examples/elastic/pytorch/train_bert.py --epochs=5 --model=bert --batch-size 32 --log-dir /opt"以上代码指定了抢占式实例上运行的Worker数量以及最大等待时间。
最大等待时间为600秒:表示即使抢占式实例有可能因市场价格变化等原因被云服务提供商随时回收,系统仍会尽可能保持至少1个Worker运行,并且当Worker未能及时响应时,最多等待600秒。
最小Worker数为1:表示即使在资源紧张、抢占式实例可能被回收的情况下,也能保证至少有一个Worker维持训练,以防止任务完全终止。
最大Worker数设置为128:表示当资源充足且价格合适时,系统会自动增加Worker数量,充分利用集群资源加速训练进程。这种弹性伸缩机制使得训练任务能在成本与效率之间取得良好平衡,既保证了训练任务的稳定性,又降低了计算资源的成本。
预期输出:
trainingjob.kai.alibabacloud.com/fine-tuning-elastic created secret/fine-tuning-elastic created trainingjob.kai.alibabacloud.com/fine-tuning-elastic created INFO[0003] The Job fine-tuning-elastic has been submitted successfully INFO[0003] You can run `arena get fine-tuning-elastic --type etjob -n default` to check the job status执行以下命令,检查已提交任务的状态。
kubectl get pod -n default预期输出:
NAME READY STATUS RESTARTS AGE fine-tuning-elastic-launcher 1/1 Running 0 44s fine-tuning-elastic-worker-0 1/1 Running 0 46s fine-tuning-elastic-worker-1 1/1 Running 0 3m47s fine-tuning-elastic-worker-2 1/1 Running 0 3m47s fine-tuning-elastic-worker-3 1/1 Running 0 3m47s fine-tuning-elastic-worker-4 1/1 Running 0 3m47s fine-tuning-elastic-worker-5 1/1 Running 0 3m47s fine-tuning-elastic-worker-6 1/1 Running 0 46s fine-tuning-elastic-worker-7 1/1 Running 0 46s输出结果表明,每个Pod中的容器都已经准备就绪并且正在运行,没有出现异常情况。
如果此时有部分抢占式实例被回收,那么对应这些节点上的Worker也会被回收。当Launcher检测到有Worker连接失败,Launcher会将失败的Worker添加进BlackList中,并使用剩余存活的Worker来建立新的通信环境继续训练。如下图所示:
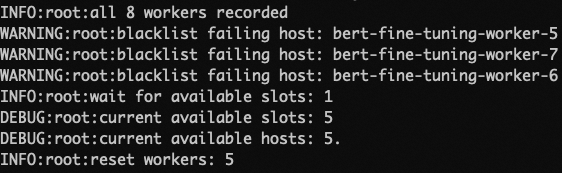
当回收后的Worker数量小于设定的最小Worker数目时,每个Worker会收到即将被回收的信号,在收到信号后Rank为0的Worker会执行保存Checkpoint的操作以保存训练的成果。如下图所示:
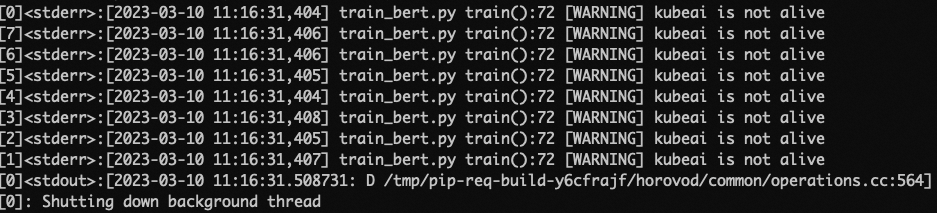
至此,该任务会被挂起,以等待资源重新满足时从保存的Checkpoint处恢复再次运行。
如果您想要了解更多详细操作信息,请参见基于抢占式实例的弹性训练。