
多活容灾MSHA(Multi-Site High Availability)是在阿里巴巴电商业务环境演进出来的多活容灾商业化产品,是应用高可用服务AHAS的核心模块,为客户提供容灾架构建设能力。横向支持容灾架构的上线、运维、演练、切流,升级到下线。纵向支持业务流量的全链路管理,从流量接入到服务化调用再到异步化消息,最终完成数据落库。
什么是多活
多活是指分布在多个站点同时对外提供服务。与传统的灾备的最主要区别就是多活里的所有站点同时对外提供服务,不仅解决了容灾本身问题,还提升了业务连续性,实现了容量的扩展。
多活容灾解决的问题
灾备容灾建立在数据级容灾的基础上,常用的实现方式是在备机房构建一套相同的应用系统,灾难发生时会在约定时间范围内恢复运行,尽可能减少灾难带来的损失。实际的灾备系统落地效果,存在以下几个问题:
灾备中心平时不提供服务,关键时刻无法确定切换到灾备中心是否可以切换成功;
灾备中心平时不提供服务,整个灾备资源处于闲置状态,成本浪费比较严重;
灾备中心平时不提供服务,所以平时提供服务的数据中心还停留在单地域,当业务体量大到一定程度时,这种模式无法解决单地域资源瓶颈的问题;
为了应对传统灾备容灾的问题,我们需要实践多活容灾,整体上能获得以下架构优势:
分钟级RTO:恢复时间快,阿里内部生产级别恢复时间平均在 30s 以内,外部客户生产系统恢复时间平均在 1 分钟。
资源充分利用:资源不存在闲置的问题,多机房多资源充分利用,避免资源浪费。
切换成功率高:依托于成熟的多活技术架构和可视化运维平台,相较于现有容灾架构,切换成功率高, 阿里内部年切流数千次的成功率高达 99.9%以上。
流量精准控制:多活容灾支持流量自顶到底封闭,依托精准引流能力将特定业务流量打入对应机房,企业可基于此优势能力孵化全域灰度、重点流量保障等特性。
容灾系统评价指标
容灾系统主要为了在灾难发生时业务不发生中断,那么当灾难发生时,用户最关心的是什么呢?以下是国际通用的容灾系统的评审标准Share 78,可以作为广大用户衡量和选择容灾解决方案的指标。以下是备份/恢复的范围:
灾难恢复计划的状态
在应用中心与备份中心之间的距离
应用中心与备份中心之间是如何相互连接的
数据是怎样在两个中心之间传送的
有多少数据被丢失
怎样保证更新的数据在备份中心被更新
备份中心可以开始备份工作的能力
因此,容灾系统的设计,主要也是围绕这几个用户需求。由于用户投入资金的数量限制,想用少的资金达到第6级容灾级别显然是有难度的,我们设计出的系统也只能是在现有的条件下尽量减少故障历时,尽量多的恢复数据,这也是衡量我们所设计出来的容灾系统质量的指标。实际的容灾系统设计过程中,我们重点关注的是RTO和RPO两个指标。
RPO(Recovery Point Objective)
即数据恢复点目标,以时间为单位,即在灾难发生时,系统和数据必须恢复的时间点要求。RPO标志系统能够容忍的最大数据丢失量。系统容忍丢失的数据量越小,RPO的值越小。
RTO(Recovery Time Objective)
即恢复时间目标,以时间为单位,即在灾难发生后,信息系统或业务功能从停止到必须恢复的时间要求。RTO标志系统能够容忍的服务停止的最长时间。系统服务的紧迫性要求越高,RTO的值越小。
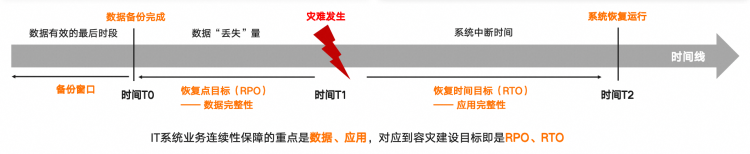
RPO针对的是数据丢失,而RTO针对的是服务丢失,RTO和RPO的确定必须在进行风险分析和业务影响分析后根据不同的业务需求确定。好的容灾系统需要尽量满足用户的需求,但是容灾系统的设计往往受多种条件的制约,如可用的技术、现网状况、用户意志、用户业务等,但到目前为止,起决定性的因素,是容灾建设的成本。
容灾架构建设方法
根据对容灾系统建设模型,容灾系统建设过程分为分析、设计和实施三个阶段。
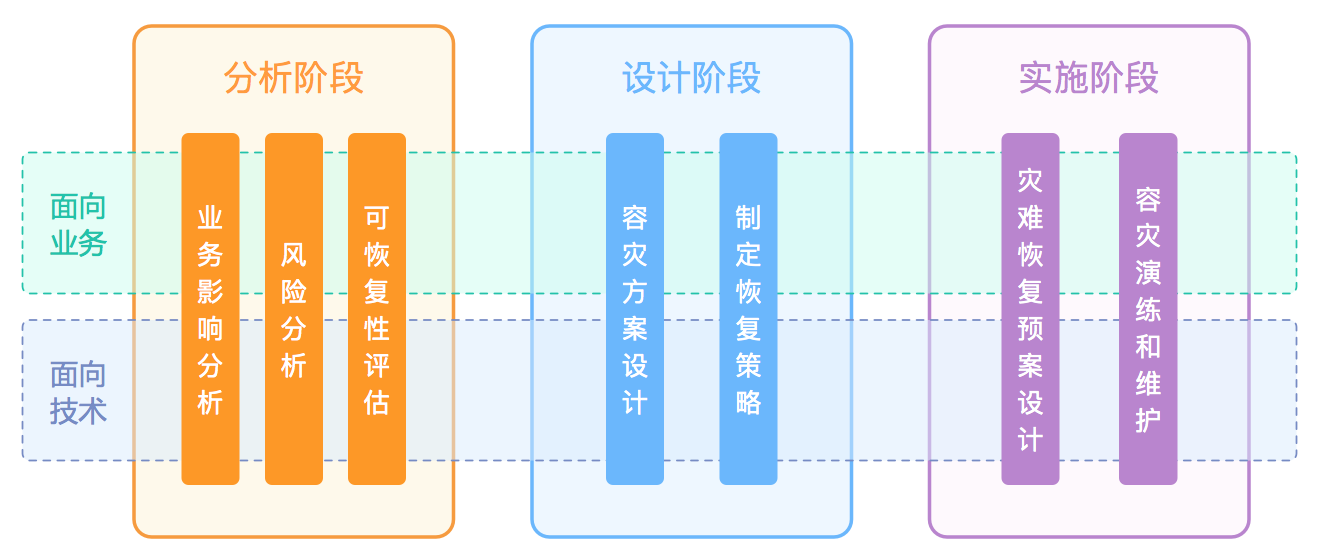
下面分别对各个阶段作出说明:
分析阶段
在取得管理层的正式同意后,获得人员和资源的保证。首先收集业务过程的信息、技术基础架构的支撑环境、灾难类型等方面的内容,然后进行业务影响分析和风险分析,确定由于中断和预期灾难可能造成的影响。分析的结果用以确定业务关键级别、业务恢复时间和可承受的数据损失程度。
设计阶段
在本阶段,结合以上的分析成果,以及企业对容灾的投入规划,制订企业短期、长期范围内的容灾策略和目标,先定义初步的方案。再进一步结合各种因素进行分析,在候选的方案中剔除不合适的方案,将剩余的可用的方案提交给评估组,评估组经过充分详细的评审,选择最合适的容灾方案。通过对业务进行分级,对核心业务和非核心业务建设不同的容灾等级预期,我们建议对关基系统、等保3级等核心系统建设多活,而对一些非核心业务可以建设灾备或仅做数据容灾。
实施阶段
根据选择的容灾方案,整合企业相关资源,确定容灾的体系架构和灾难恢复计划,通过技术手段和服务以达到所要求的容灾目标。任何制订的计划,都必须经过不断的测试和修正,才能满足企业不断发展的需求。同时,通过培训、测试过程,也能够使企业内部人员熟悉自己在容灾流程中所扮演的角色,保证在灾难真正发生的时刻能够有条不紊地执行恢复流程。测试的过程可以分为局部验证和演习两种方式。随着商业需求、新技术的不断升级以及新的内部和外部规则的变化,IT系统也会随之改变。要确保灾难恢复计划的有效性,必须定期检查和修改计划。
容灾架构保鲜
多活容灾旨在给出一套帮助业务应对未来潜在灾难场景下的解决方案。但业务会持续发展,架构也会不断演进,容灾治理始终解决的是发展中问题。因此容灾治理不仅要持续建设更高阶的容灾架构技术,还需要增强“基础设施”、“业务系统”、“保障工具”、“生产制度”和“应急人员”之间的协同。唯有时刻追求能力保鲜,才能立足于日新月异的复杂环境。
容灾演练作为一种管理型技术手段,可以帮助业务度量容灾能力,暴露潜在风险短板。演练按照演练目的可以分为三个类型,即:沙盘推演、模拟演练及实际业务接管演练。业务接管演练还会配合一些生产故障演练,虽然会对线上引入一定影响,但是演练效果往往更加真实。容灾演练一般会经历下面四个阶段的演进:
阶段一,可控的暴露问题
围绕“基础设施”和“业务系统”提前梳理出影响可用率的风险因子,确定风险因子具体影响大小、是否可自愈、是否为跌零因子,此阶段需要通过生产小规模的生产实验来探索和验证。
阶段二,可靠的收敛问题
通过阶段一的验证,已经可以初步得出有效的跌零因子,同时也暴露出一些问题和风险。接下来需要继续坚持把已知的风险进行收敛,并常态保鲜演练。本阶段通常以演练成功率作为驱动指标。
阶段三,可信的量化问题
经过阶段二,“基础设施”和“业务系统”已经初步具备确定性。这时候需要开始关注“保障工具”、“生产制度”、“应急人员”这三个动态因素对整体结果带来的影响。这一阶段可以采用类似攻防对抗、突袭的方式来驱动,逐渐建立度量体系,完成度量指标的梳理和数据化沉淀。
阶段四,可能的挖掘问题
通过阶段三的积累,已经掌握了一定的结构化的数据,此时可以借助智能化的方案,挖掘出一些隐藏的、潜在的弱点和风险。