AI Profiling是一种用于实现AI应用程序全生命周期性能观测、诊断与优化的高级分析工具。通过深入追踪AI模型在训练及推理阶段的跨层软件栈调用轨迹(涵盖Python栈、Torch层、显存、CudaRuntime、GPU核函数),结合细粒度的算子级性能指标(如FLOPs、计算/通信/显存/空闲时间占比等)及资源消耗数据,为开发者和运维团队提供端到端的解决方案。
使用限制
当前功能白名单开放,若需试用请联系人工客服。
地域限制
本功能目前仅支持中国内地与中国香港。
操作系统限制
架构
操作系统
x86
Alibaba Cloud Linux 3
Alibaba Cloud Linux 2
Ubuntu22.04
Ubuntu24.04
其他限制
重要AI Profiling需要占用目标进程的内存和CPU资源,具体资源占用与采集时间与迭代数有关,若目标进程资源小于0.5G每秒/每迭代,则放弃采集。
需要先纳管机器才能执行AI Profiling
支持显卡类型:GPU(A卡、L卡、T卡)。
支持虚拟环境中运行AI作业或容器(ACK/自建k8s)中运行AI作业,当使用容器时,作业容器不能挂载主机的
/proc目录。不建议直接在主机Python环境运行AI作业,其他场景支持请提交工单。仅支持Python进程观测,且进程需要占用GPU,Python版本范围3.9~3.12。
进程必须使用了torch库,torch版本范围2.4~2.7。
CUDA版本范围12.0~12.8,不含12.7 版本。
若AI作业默认使用nsys,则无法采集GPU Kernel的数据。
目标进程的Python解释器必须已安装pip。
已验证环境:
Alinux2 + (conda)python 3.11.13 + pip 25.1.1 + NVIDIA A10 + CUDA Version: 12.4 + 4.19.91-28.2.al7.x86_64
Alinux3 + (conda) python 3.10.18 + pip 25.1 + Tesla T4 + CUDA Version: 12.4 + 5.10.134-19.1.al8.x86_64
Alinux3 + (conda) python 3.9.23 + pip 21.2.4 + Tesla T4 + CUDA Version: 12.4 + 5.10.134-19.1.al8.x86_64
Ubuntu24.04 + (conda)python 3.12.1 + pip 22.0.4 + NVIDIA A10 + CUDA Version: 12.8 + 6.8.0-63-generic
Ubuntu22.04 + (conda)python 3.12.11 + pip 22.0.4 + Tesla P4 + CUDA Version: 12.8 + 5.15.0-142-generic
Ubuntu 22.04.3 LTS + python 3.10.12 + NVIDIA A10 + CUDA Version: 12.2 + 5.10.134-18.al8.x86_64(ACK容器)
数据丰富度介绍
指标名
含义与注意事项
支持环境
示例
默认指标采集
默认开启:
GPU Kernel
Torch
Python Stack
GPU Kernel、Torch、Python Stack的并集
GPU Kernel
GPU算子信息
支持硬件:Nvidia、AMD
cuda版本:12.0 ~ 12.8

Torch
Torch层面信息
支持硬件:Nvidia、AMD
Torch版本:>=2.1.0
Python版本:3.9 ~ 3.12
python解释器直接安装pip
Python Stack
Python栈信息
支持硬件:Nvidia、AMD
Python版本:3.9 ~ 3.12
python解释器直接安装pip
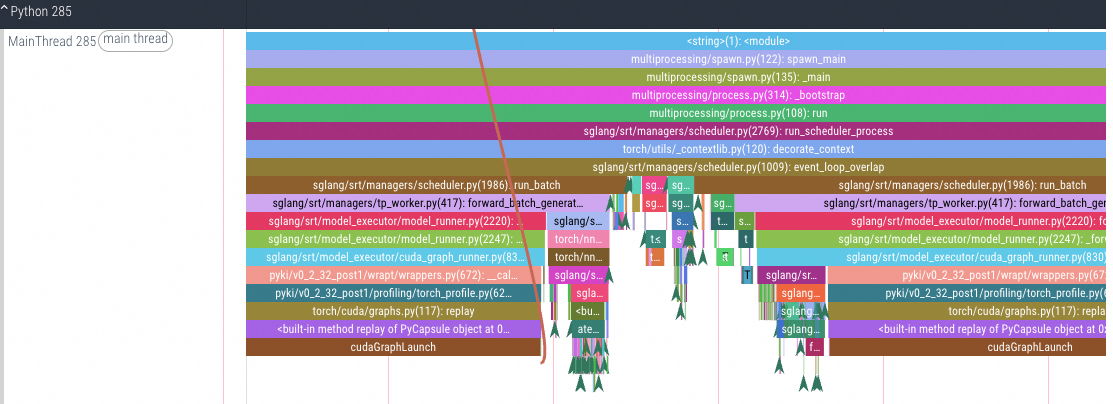
Profile Memory
Torch显存信息
注意:不支持TensorRT任务,TensorRT任务开启后会导致采集Torch指标采集失败
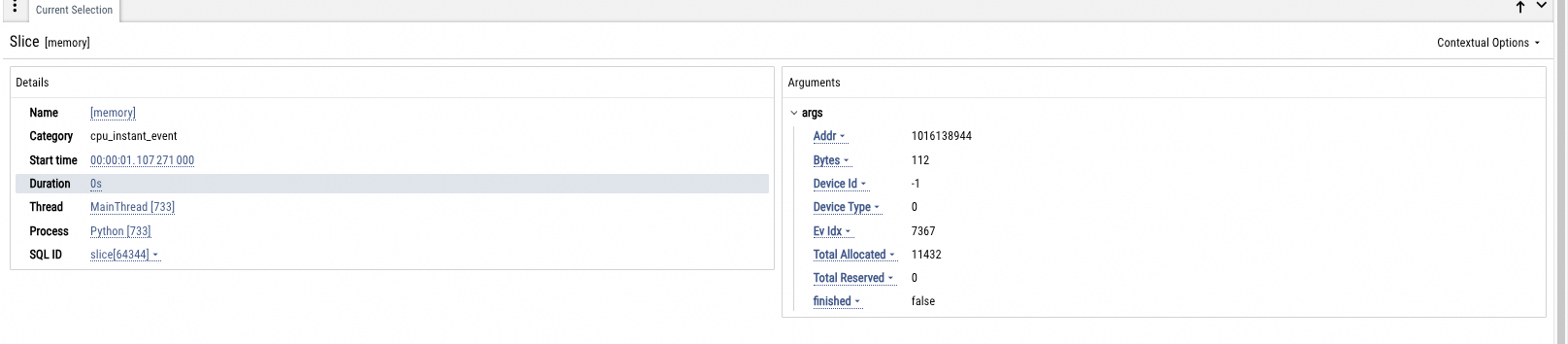
GPU显存快照
采集GPU显存分配、碎片、分配栈等情况
支持硬件:Nvidia
Torch版本:>=2.1.0
Python版本:3.9 ~ 3.12
python解释器直接安装pip

RDMA Monitor
RDMA监控信息,默认采集:
vport_rx_write_requests
vport_rx_read_requests
有RDMA网卡
DCGM Monitor
DCGM监控信息,默认采集:
DCGM_FI_DEV_FB_FREE
DCGM_FI_DEV_FB_USED
DCGM_FI_DEV_GPU_UTIL
支持硬件:Nvidia
Tesla驱动
NVTX
自定义的NVTX标记
支持硬件:Nvidia、AMD
Torch版本:>=2.1.0
代码中标记了NVTX
Python版本:3.9 ~ 3.12
python解释器直接安装pip
FLOPS
Torch中的Flops信息
支持硬件:Nvidia、AMD
Torch版本:>=2.1.0
Python版本:3.9 ~ 3.12
python解释器直接安装pip
Record Shapes
Torch中的Record Shapes信息
支持硬件:Nvidia、AMD
Torch版本:>=2.1.0
Python版本:3.9 ~ 3.12
python解释器直接安装pip
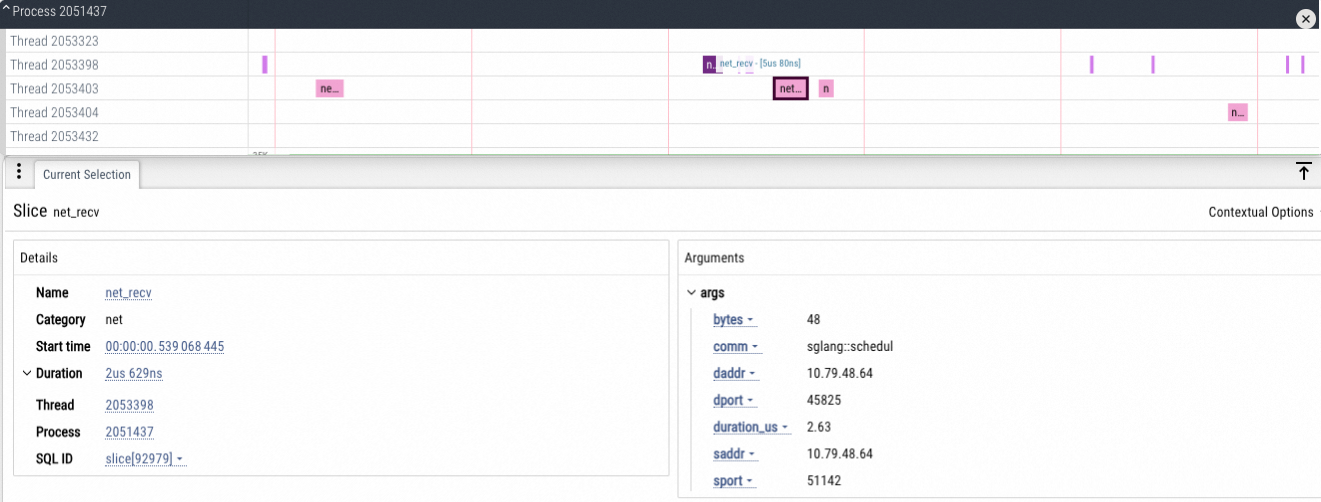
TCP网络指标
TCP发送/接收网络数据包的信息
内核版本>=5.10
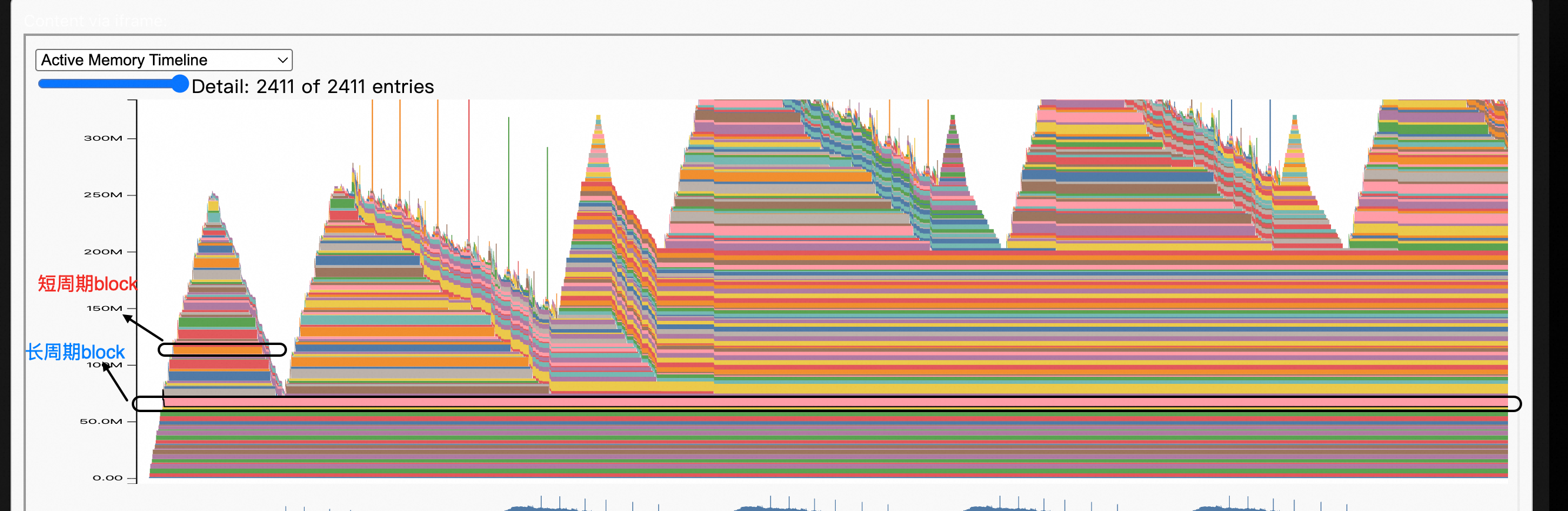


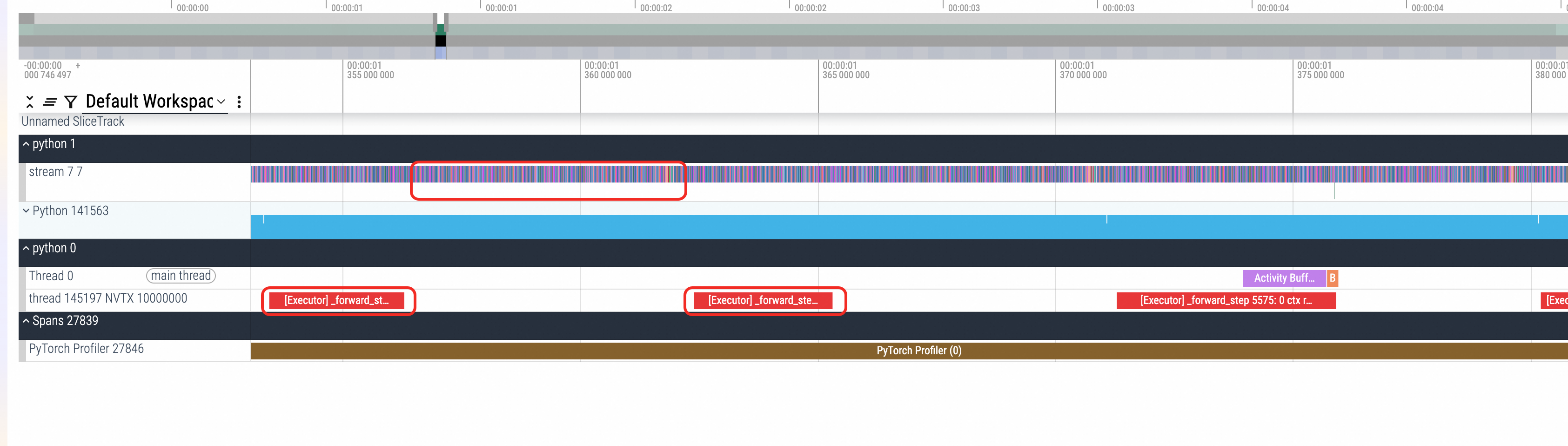
功能优势
零侵入:采用无侵入式Profiling技术,您无需对容器做任何变更。
丰富性:支持按需采集Python调用栈、CPU信息、GPU算子、Torch、显存及FLOPS等指标。同时,RDMA、GPU和CPU监控指标也支持按需采集。
中心端分析:对采集的原始数据自动在中心端进行统计分析,多维度展示作业真实情况。
易用性:全流程实现分钟级自动完成。只需在前端配置实例ID,即可自动触发AI Profiling。采集完成后,数据将自动回传至中心端,分析完成后生成的报告将在前端显示。此外,系统自带TimeLine视图,无需额外将数据拷贝至Chrome Tracing/Perfetto等组件。
稳定性:已在千卡集群中完成部署验证,对AI作业零影响。
多维度采集:支持按时间采集和按迭代采集两种采集维度。同时支持自定义迭代入口以及跳过前n迭代等高级配置。
低开销:采集数据的丰富度可根据需求进行配置,启动采集时系统开销范围为5%~40%。
多进程支持:支持多进程同时采集。
应用场景
本文列举了部分常见的场景,您可以利用该功能进行诊断分析,并根据建议采取相应措施以解决问题。
在您完成AI场景的部署后发生故障。
AI的处理速度不如预期。
检查当前服务器的瓶颈,以确定是否存在某个算子耗时较长。
前提条件
操作步骤
选择或输入条件,单击开始分析。
参数说明
实例ID:选择该账户下已纳管的实例ID,该实例应配备GPU,并且正在执行AI作业。
支持填写AI作业PID或AI作业进程名指定AI作业,可填写多个AI作业PID或AI作业进程名,多个AI作业PID或AI作业进程名之间以
,分隔。如果同时填写了AI作业PID和AI作业进程名,系统将在执行分析时取其并集进行处理。说明可以执行
top命令,在PID列中查看AI作业的进程ID,并在COMMAND列中查看AI作业的进程名。您也可以执行nvidia-smi命令进行查看。
数据丰富度:可根据需求选择GPU算子、Python调用栈、CPU信息、Torch显存及浮点运算次数,支持多重选择。
分析模式:
duration模式
按照时间区间采集,以毫秒为单位,当前支持1000毫秒~5000毫秒的分析。
iteration模式
迭代范围:默认采集0~10个迭代,支持跳过前n个迭代。迭代数指数据采集模块激活时的迭代次数,独立于AI作业的迭代计数。
迭代入口模块:例如:
transformers.trainer。迭代入口函数:
vllm推理场景默认为
LLMEngine.step。训练场景默认为
Optimizerstep。
采集时长:默认为2000毫秒,您可以根据实际业务需求调整分析时长,目前支持的范围为1000毫秒~5000毫秒的分析。
在分析记录区域,单击查看报告。
结果分析说明
分析建议
本次AI作业分析建议,如下图所示。
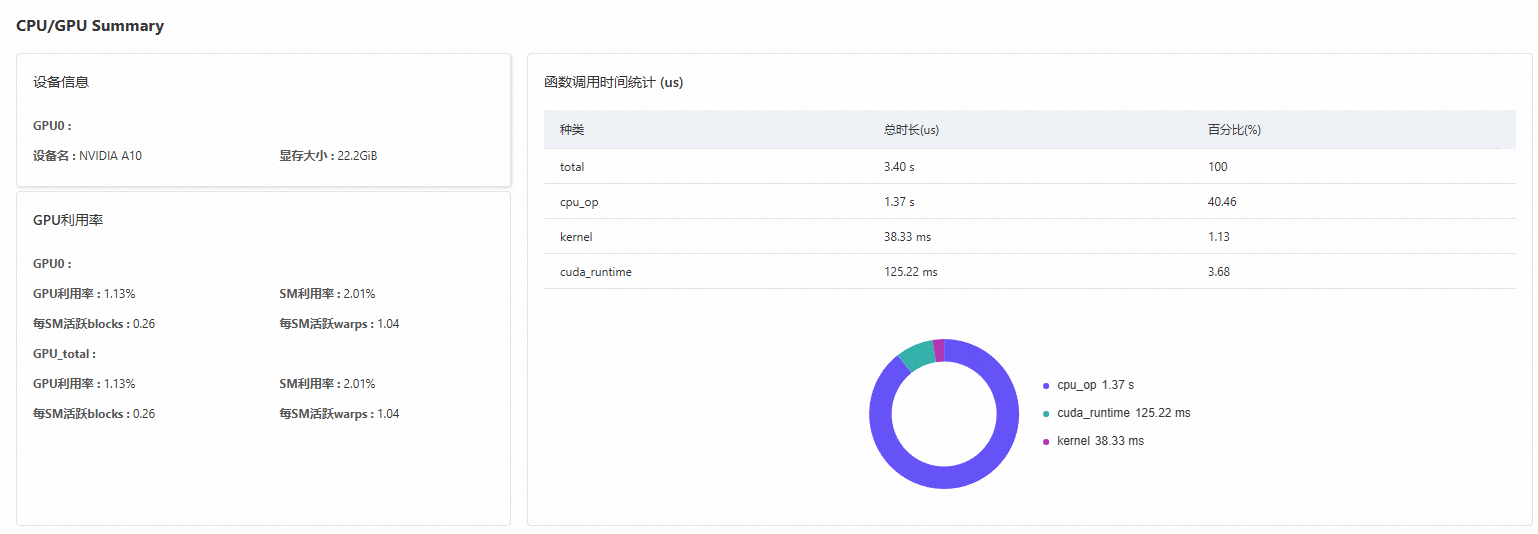
CPU/GPU Summary
设备信息、函数调用时间统计(us)和GPU利用率,如下图所示。
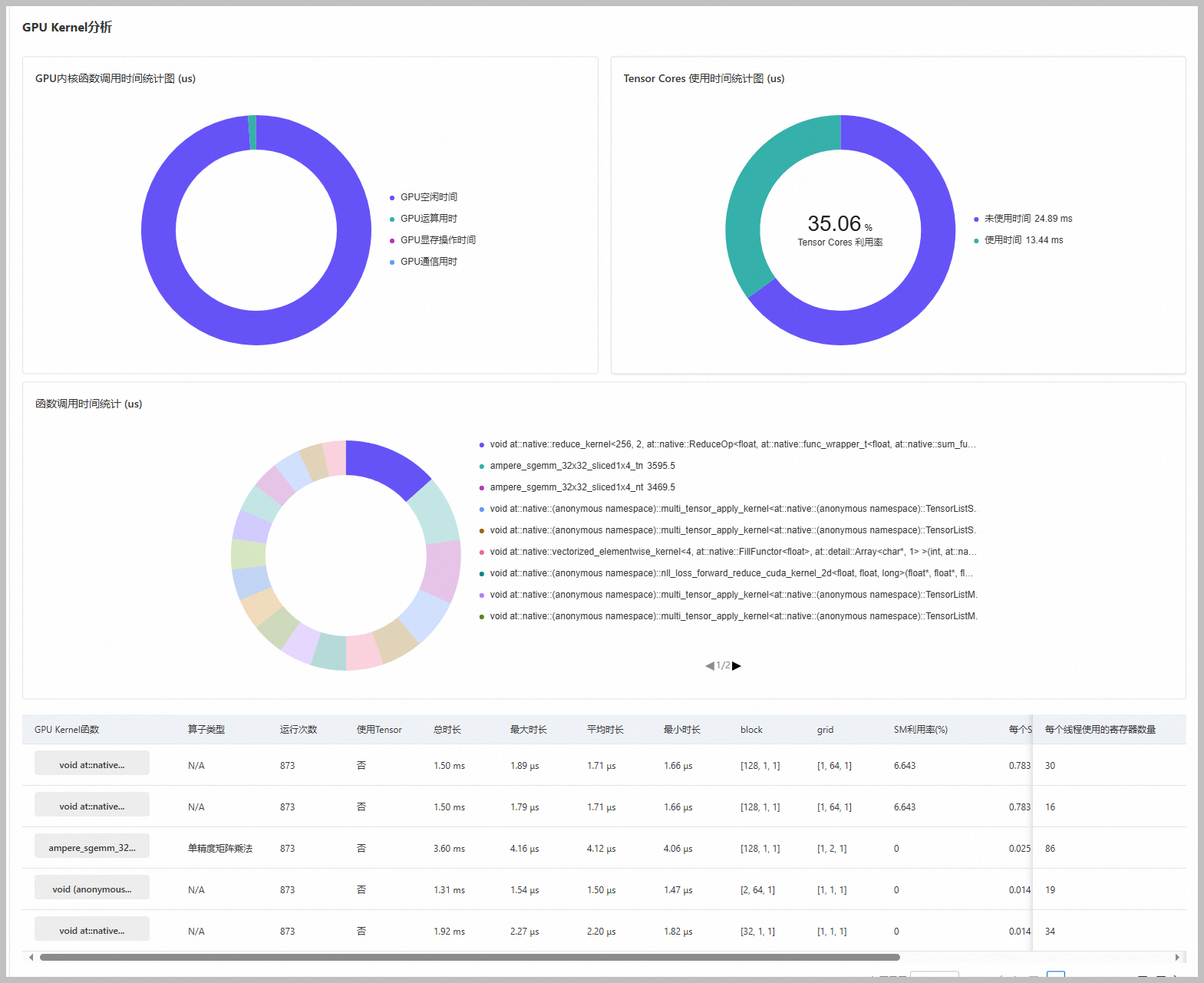
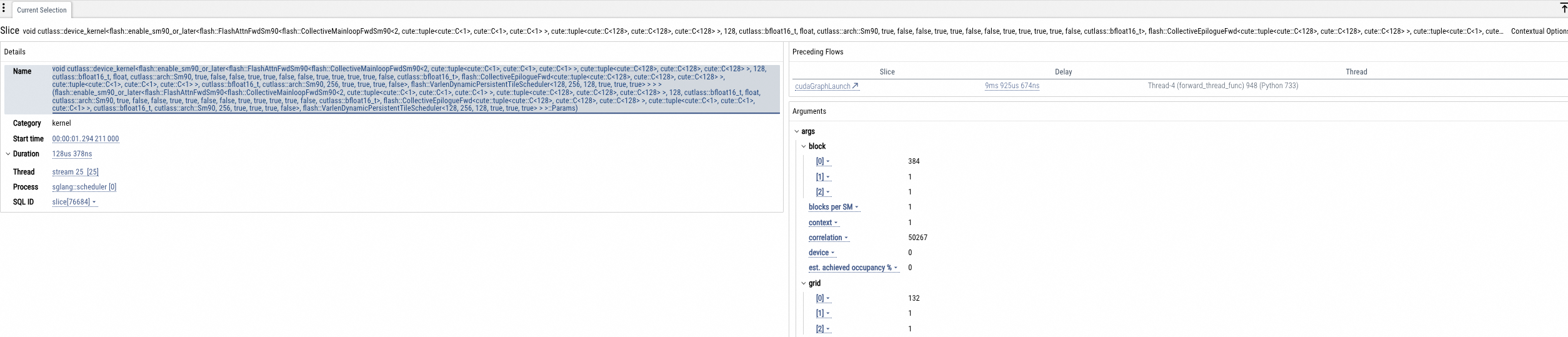
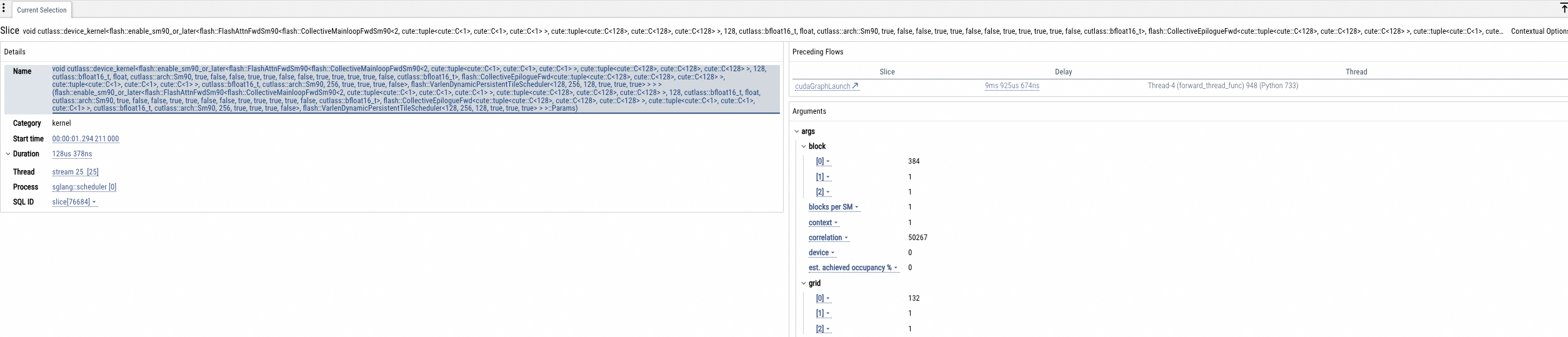
GPU Kernel分析
GPU内核函数调用时间统计图 (us)、Tensor Cores 使用时间统计图 (us)、函数调用时间统计 (us)和GPU Kernel函数信息,如下图所示。
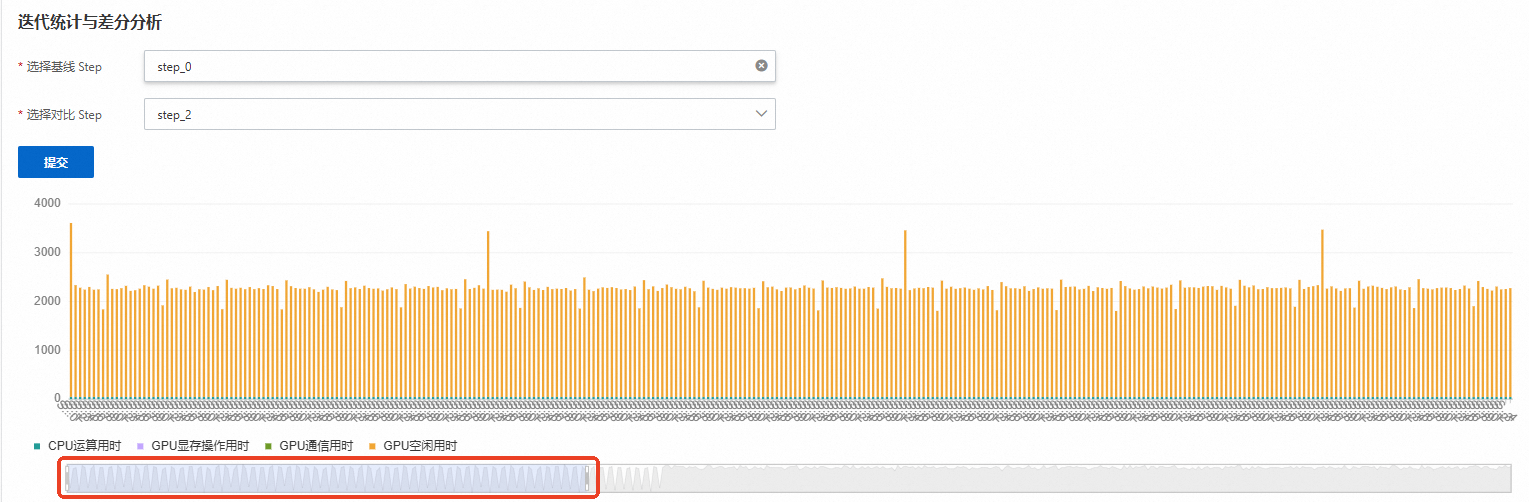
迭代统计与差分分析
AI迭代统计
基于Iteration标记对训练推理过程进行锚定,针对每一个迭代进行单独的统计分析,计算每个迭代的损失值以及计算、存储和通信的耗时。同时,将这些数据汇总为柱状图,以便能够直观地识别出哪个迭代的梯度出现异常,或哪个迭代的通信时间占比异常突出。您可以拖动以下滑轨查看具体迭代次数数据,如下图所示。
训练作业系统默认以Optimizerstep为迭代分界点。
推理作业系统默认以LLMEngine.step函数为分界点。
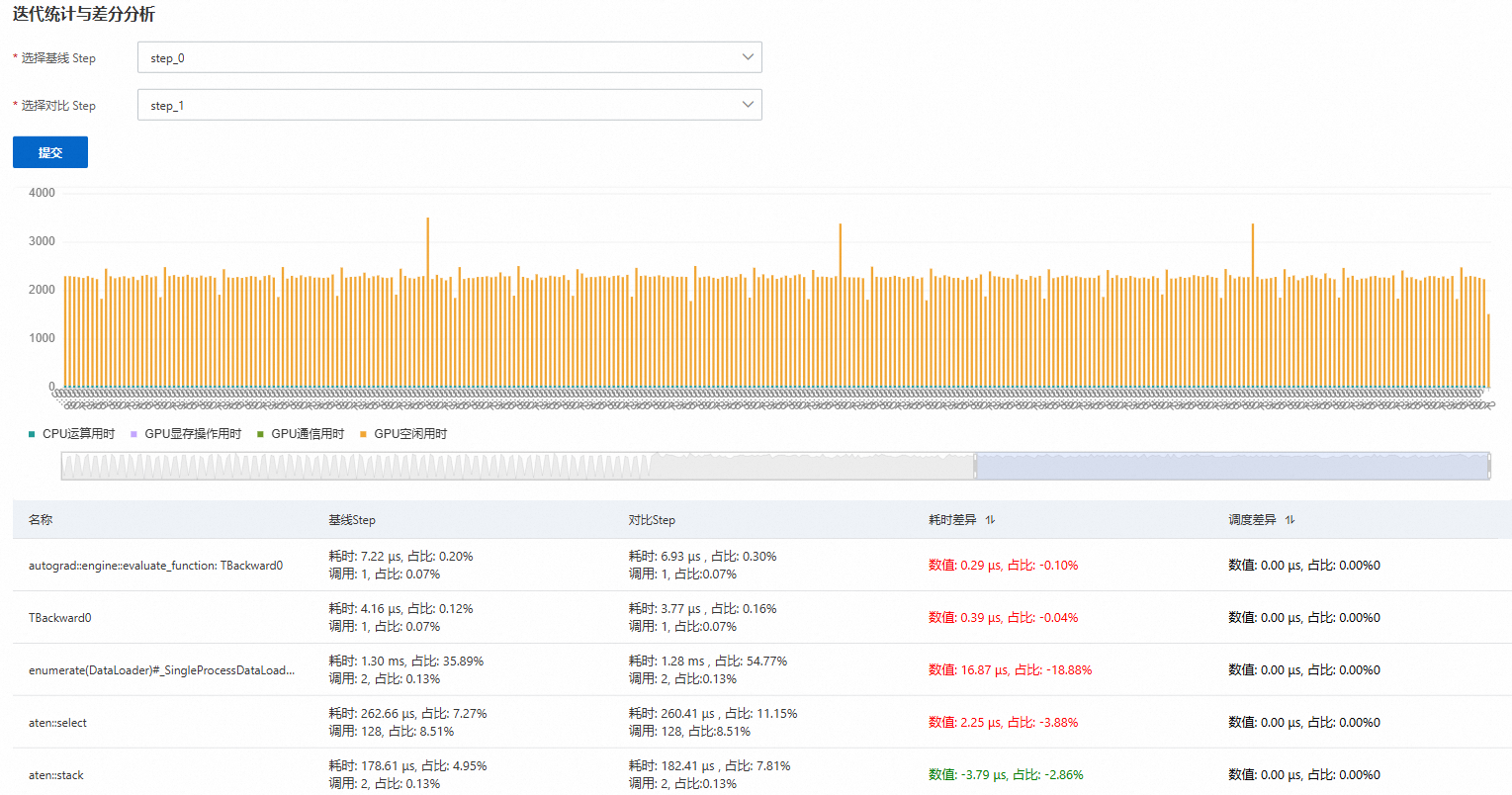
AI差分分析
AI Profiling采集的TimeLine数据非常复杂且数据量巨大(达到GB级),这使得分析工作变得困难。在性能对比或异常分析的场景中,传统方式难以快速识别出两份数据的差异点。通过AI差分分析对比异常迭代与正常迭代的核函数耗时及调度差异,精准定位跨迭代间性能差异的根源函数,实现训练瓶颈的快速定位与优化决策。
选择基线Step和对比Step后,单击提交。例如,选择基线Step为正常迭代,选择对比Step为异常迭代进行对比,如下图所示。
参数
说明
名称
根源函数。
基线Step
正常/异常迭代的耗时、占比,以及调用次数和占比。
对比Step
耗时差异
基线Step与对比Step耗时和占比的差异。
调度差异
基线Step与对比Step调用次数和占比的差异。
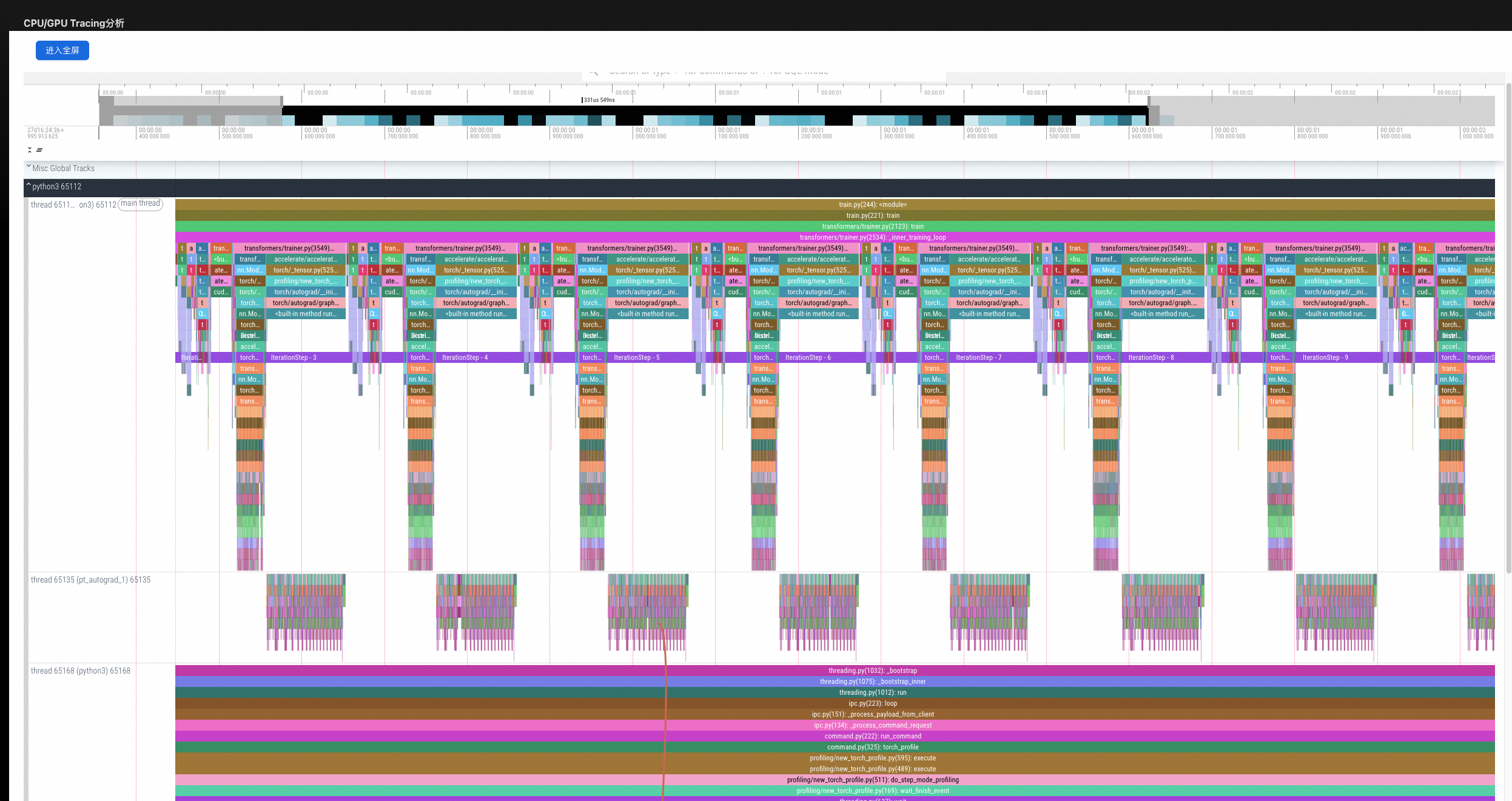
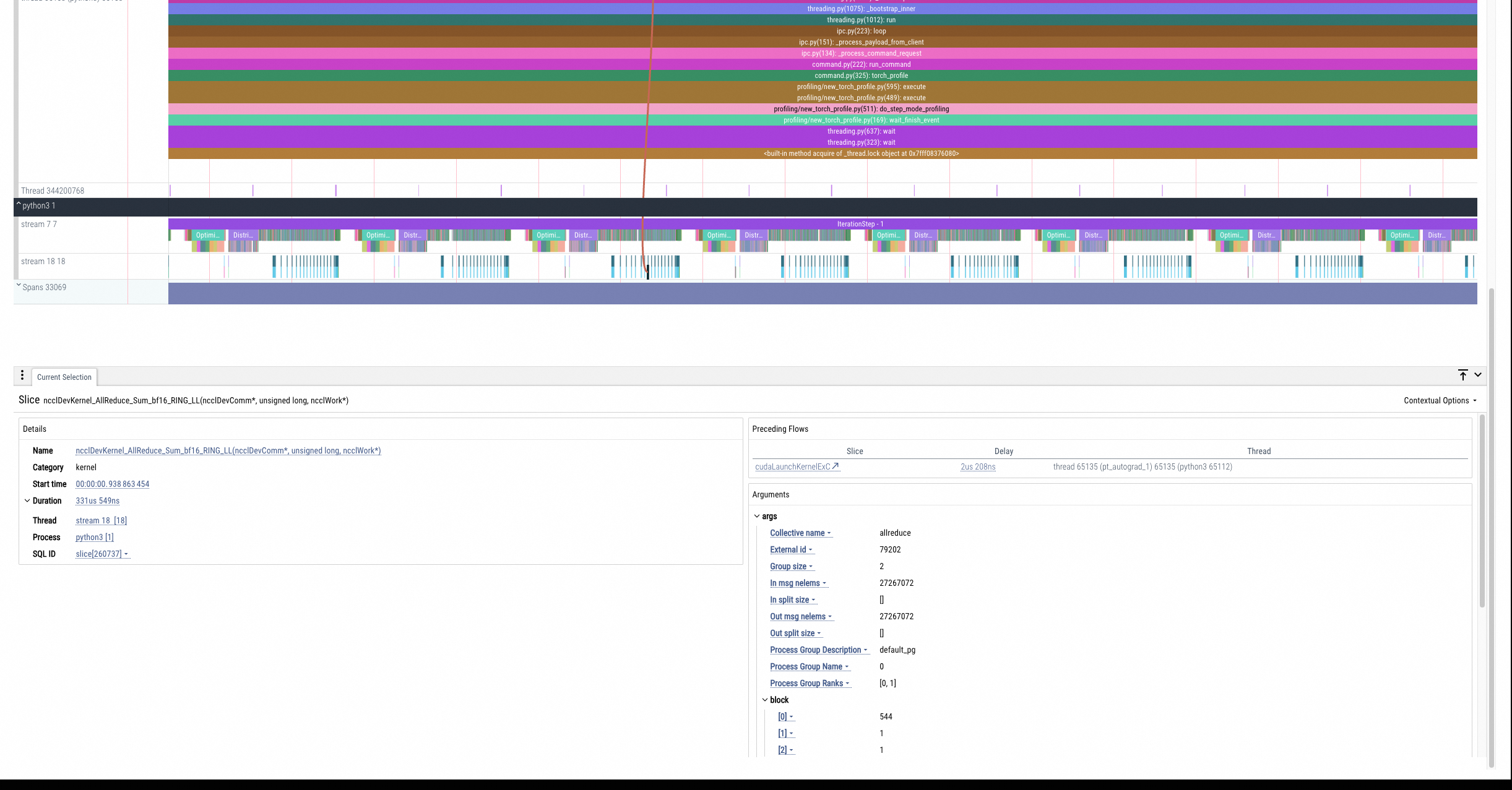
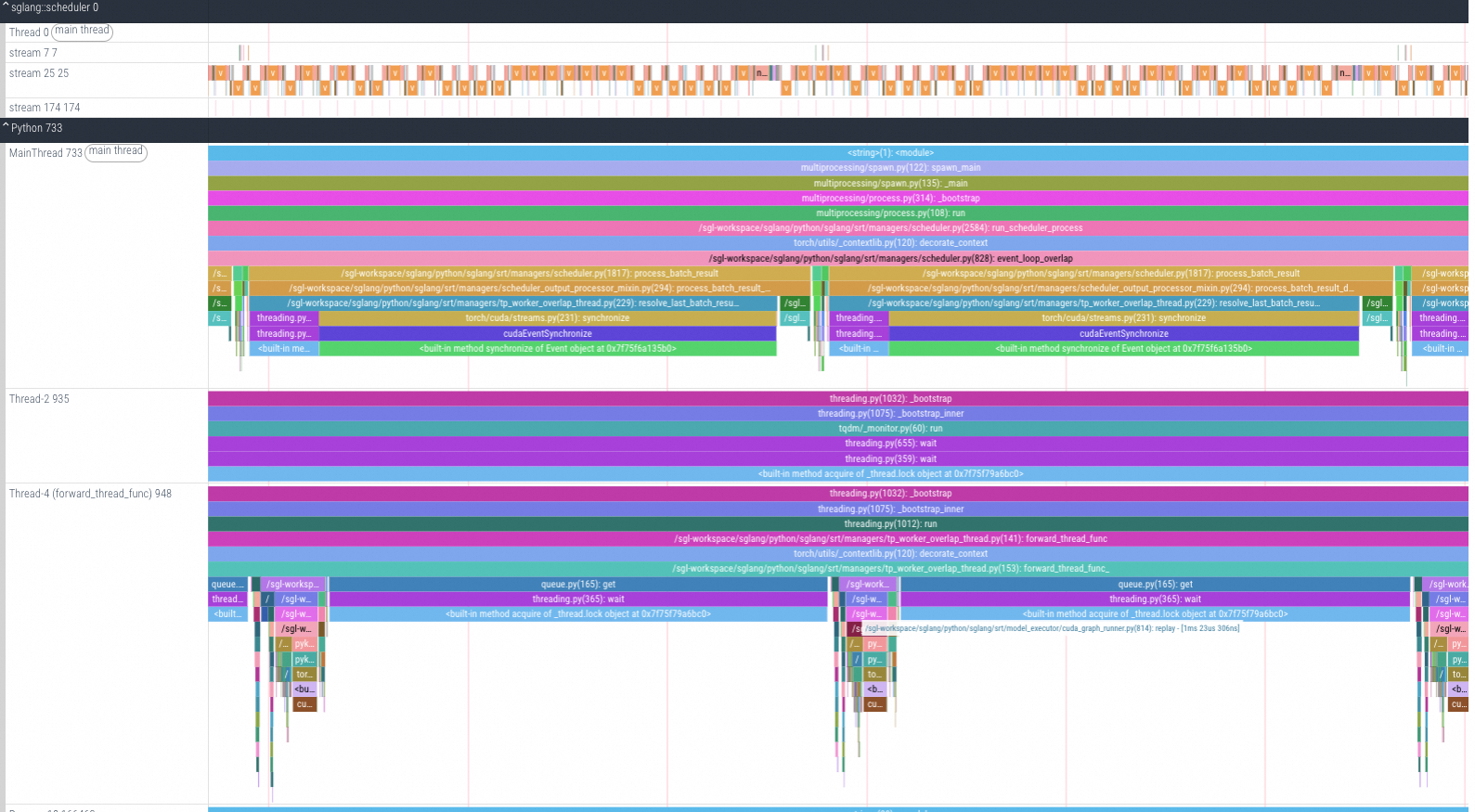
CPU/GPU Tracing分析
无需再打开Chrome Tracing/Perfetto。采集数据类型可按需配置,支持Python调用栈、CPU信息、GPU算子、Torch、显存、FLOPS。