
随着生成式AI等技术在各行业的普及和深化,GPU已成为企业关键的战略性算力资源。然而,许多组织面临着一个严峻的挑战:其GPU运维能力与庞大的算力投资规模之间存在显著差距。本文旨在系统性地分析当前GPU训练与推理场景下的核心运维瓶颈,并提出一套以数据驱动为核心的最佳实践框架。该框架旨在帮助企业从被动的、事件驱动的响应模式,转变为主动的、以优化为目标的管理范式,从而显著提升GPU利用效率,缩短故障恢复时间(MTTR),并最大化算力投资回报率(ROI)。
一、 现状与挑战:GPU算力价值释放的核心瓶颈
GPU算力的高昂成本与运维成熟度之间的不匹配,已成为制约AI场景效率和产出的主要瓶颈。这一矛盾具体体现在以下三个关键的运维痛点上:
硬件生态封闭,缺乏跨厂商兼容性
问题描述:主流性能分析与计算工具(如 NVIDIA CUDA、AMD ROCm、Intel IGCL)深度绑定特定厂商的硬件架构与软件栈,在异构或多厂商环境中难以统一使用。
业务影响:不同生态在接口、参数、数据类型等方面互不兼容,显著抬高学习和使用门槛,阻碍通用工具链建设与模型跨平台部署。
故障诊断复杂,采集机制侵入性强
问题描述:在分布式训练等大规模场景中,错误(如 CUDA error)可能源于硬件故障、驱动/固件不兼容、通信库(如 NCCL)异常或应用代码缺陷,缺乏确定性归因路径。现有工具普遍要求修改源码、重新编译并重启进程才能启用分析功能,无法动态开启/关闭性能采集。
业务影响:依赖人工经验试错排查,平均修复时间(MTTR)长;算力资源长时间闲置,严重拖慢关键模型的研发与迭代节奏。
依赖链复杂,版本敏感,资源开销不可控
问题描述:目前常用的高层分析工具(如 PyTorch Profiler)对 Python 解释器、PyTorch 运行时等依赖版本高度敏感,微小版本差异即可导致功能异常或数据失真。同时,高频事件采集或大规模 trace 数据易使工具自身成为性能瓶颈,干扰甚至扭曲原始程序行为。
业务影响:环境配置维护成本高,工具稳定性差;分析结果可信度低,反而增加排查难度。
缺少应用层上下文信息,定界能力弱
问题描述:现有监控多聚焦于硬件利用率等宏观指标,缺乏与应用逻辑的关联。当问题发生在代码层面时,运维无法获知:当前执行的 Python 函数、触发异常的具体算子(Operator)、算子输入参数等关键上下文。
业务影响:问题定位停留在表象猜测,缺乏有效定界依据,难以触及根本原因。
监控数据孤岛化,缺乏端到端关联
问题描述:监控数据分散于多个技术栈——硬件层(如 DCGM)、系统层(CPU/内存/网络)、应用层(框架 Profiler、日志)——彼此孤立,无法建立“硬件状态 ↔ 系统行为 ↔ 应用逻辑”之间的因果链条。
业务影响:难以实现端到端性能分析与根因定位,整体可观测性薄弱,制约 AI 系统的可运维性与可靠性。
二、 最佳实践:构建数据驱动的GPU运维框架
为解决上述挑战,企业需要主动式发现问题,并提高整体运维效率。该框架建立在以下三大核心实践之上:
实践一:构建AI场景全链路可观测体系
这是实现精细化运维的数据基石。一个有效的可观测性体系必须能够统一采集并关联以下几个层面的数据:
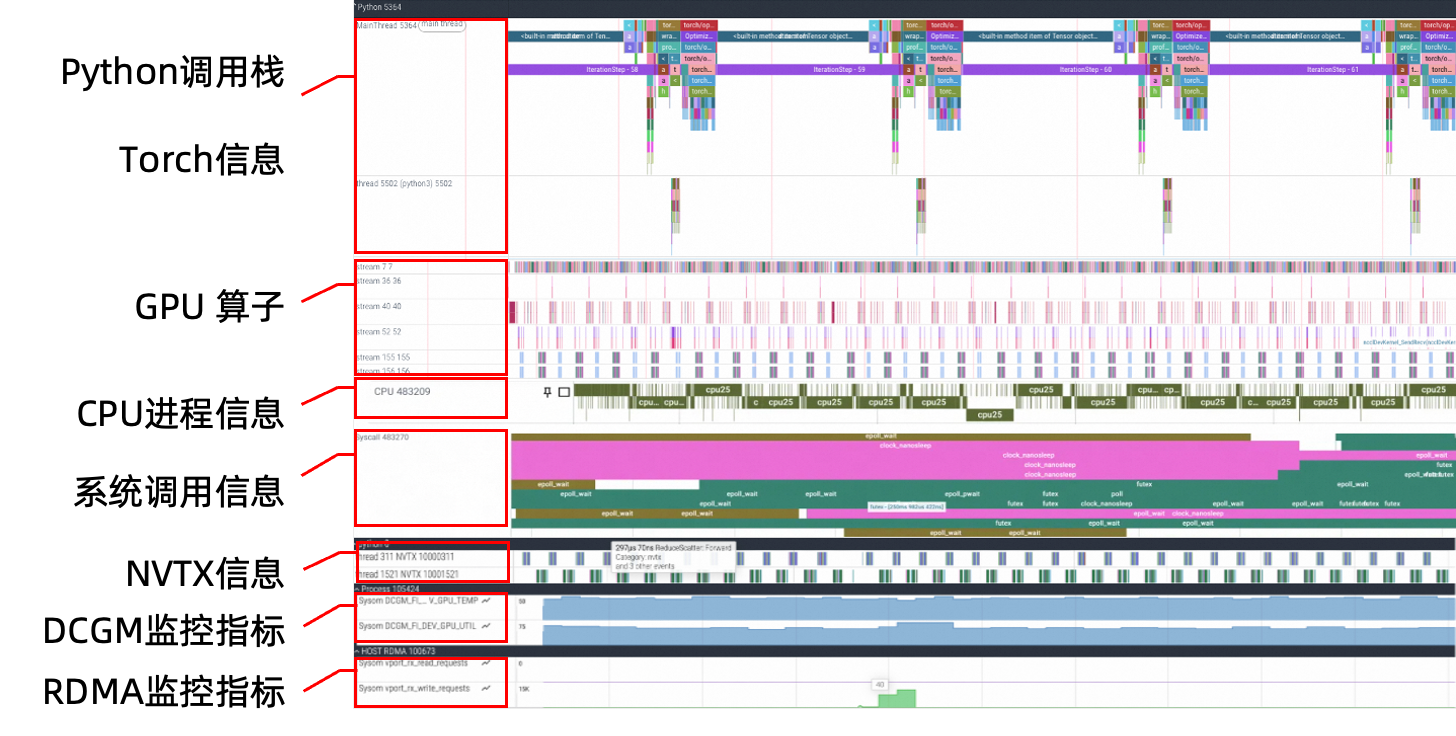
应用层:深入代码执行层面,获取Python函数调用栈、Torch信息、NVTX标签等性能数据。
系统层:与AI任务伴生的CPU利用率、内存使用、磁盘I/O、网络吞吐量与延迟、中断和上下文切换等。
GPU层:采集 GPU 算子耗时、数据加载管道状态、以及分布式通信原语(All-Reduce)、RDMA数据传输、基于DCGM采集的GPU利用率、显存占用与带宽、功耗、温度等。
实践二:实施无侵入式的性能剖析
为降低运维工具对业务开发的影响并提高其接受度,性能数据的采集应采用无侵入式技术。这意味着分析工具应能动态注入到正在运行的AI任务进程上,而无需开发人员修改或重新编译业务代码。这种“即插即用”的能力,确保了性能分析可以在生产环境或准生产环境中安全、便捷地进行,从而获取最真实的性能数据。
实践三:集成自动化的根因分析(RCA)与诊断能力
原始数据本身价值有限,真正的核心在于从中自动提炼洞察。一个成熟的运维框架应具备自动化的诊断引擎,能够:
生成综合诊断报告:将多层数据关联分析后,以结构化、可视化的方式呈现,而非简单罗列指标。
自动识别瓶颈类型:明确指出当前任务的主要瓶颈是
Data-Bound(数据瓶颈)、CPU-Bound(计算瓶颈)还是GPU-Bound(GPU计算瓶颈)。精准定位问题源头:将性能问题下钻到具体的代码函数、耗时最长的Top-K算子,或特定的系统资源争抢上。
提供可执行的优化建议:基于诊断结果,给出明确的优化方向,例如“建议增加数据加载器的worker数量”或“建议优化某某算子的实现”。
三、 解决方案:阿里云AI Profiling
阿里云AI Profiling解决方案是将上述框架付诸实践的典型案例。它为企业提供了一套完整的、用于GPU训练和推理场景的性能分析与诊断工具。
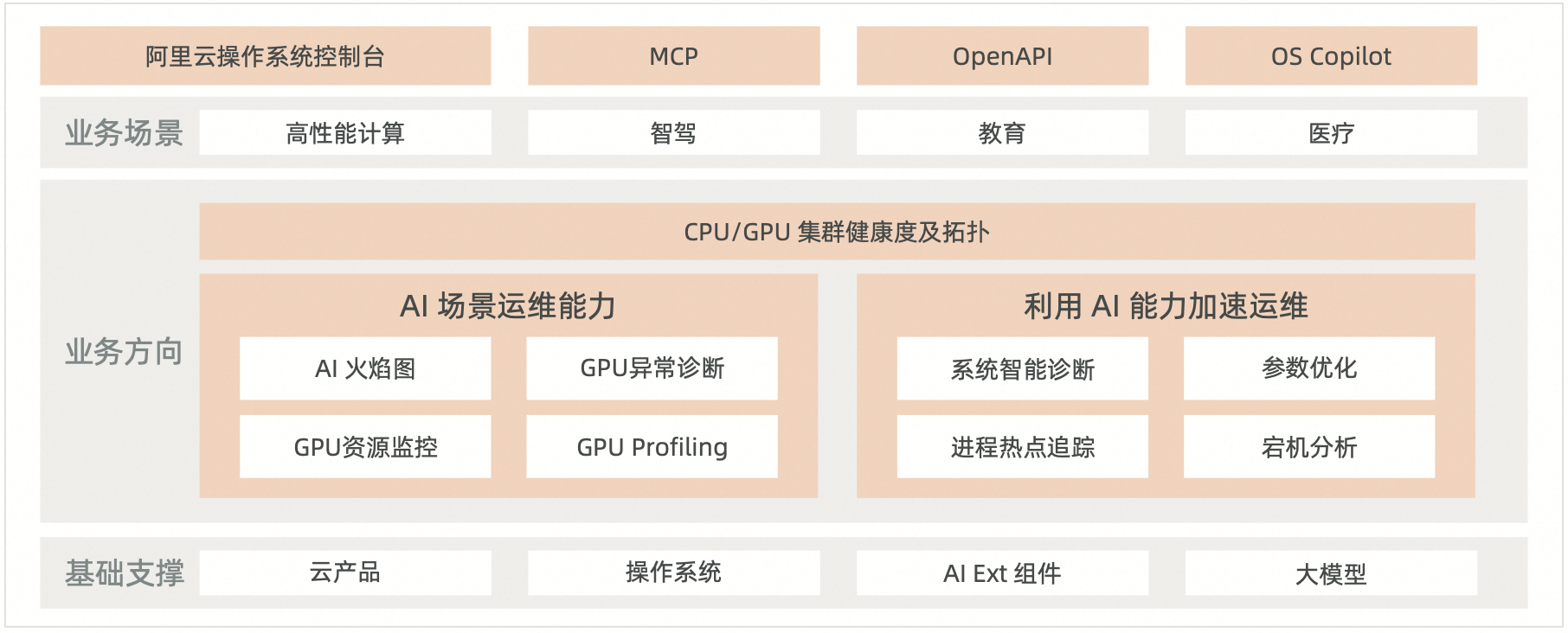
能力对标:
常态化部署的 AI 火焰图、热力图,快速构建 CPU 和 GPU 的全栈分析能力,实现分钟级的问
题发现和定界能力;
无侵入、高可靠的在线 GPU Profiling,结合训练时不同 step 的差分对比分析,帮助快速找
到 GPU Kernel 算子优化的突破点。
框架实现:
端到端可观测性:通过对异构计算、跨设备通信、内存占用等进行全链路Profiling,打通了从硬件到应用的数据壁垒。
无侵入式部署:提供无侵入式代理,支持一键式部署,使算法工程师无需修改代码即可启动深度性能分析。
自动化诊断:可自动生成白屏化的分析报告,提供数据驱动的瓶颈识别与根因分析,将传统的排查模式转变为确定性的诊断流程。

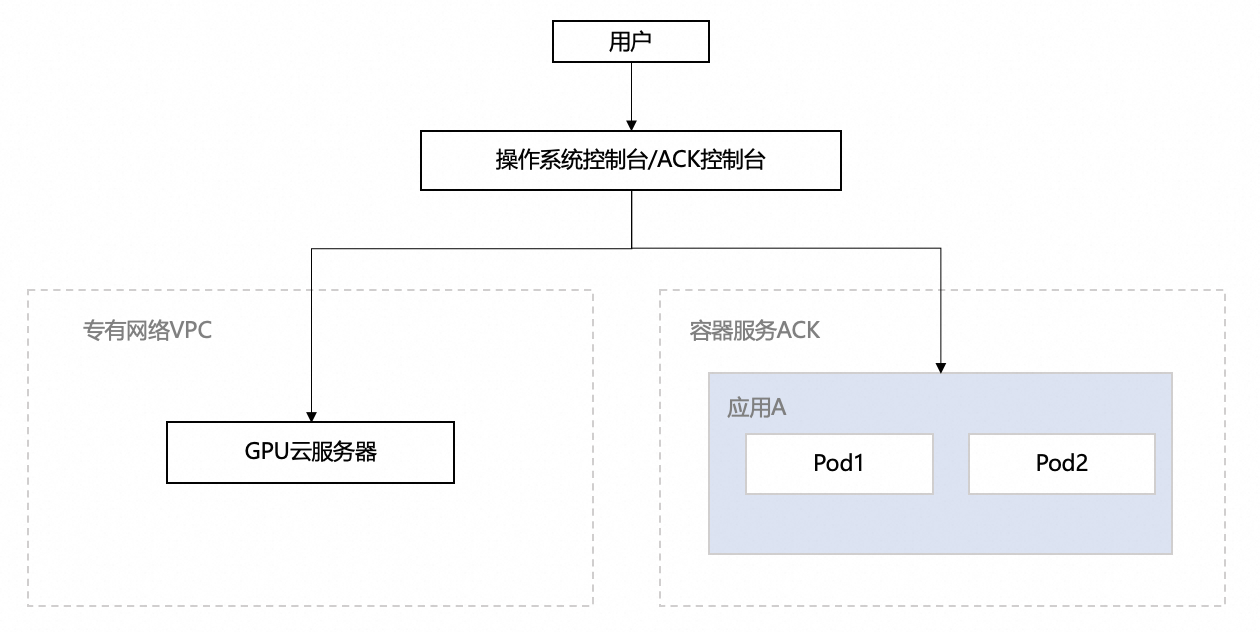
部署架构:该方案可灵活部署于阿里云GPU云服务器(ECS)或容器服务(ACK)之上,通过VPC、安全组等云原生基础设施保障环境的安全与隔离,让用户能快速搭建并使用这一强大的性能分析能力。
四、 结论
在AI技术成为核心竞争力的背景下,GPU基础设施的运维模式必须升级。企业应致力于从依赖个人经验的被动响应模式,转向基于数据和工具的系统化、主动式管理范式。通过构建一个集端到端可观测性、无侵入式剖析和自动化诊断于一体的运维框架,企业不仅能显著降低故障带来的损失,更能持续优化算力使用效率,从而有效提升研发迭代速度、最大化算力投资回报率(ROI),在激烈的技术竞争中获得持续优势。