操作系统健康度通过关键监控指标,整体反映一个集群、节点或容器的健康状态。在掌握整体健康状况的基础上,进一步分析影响系统健康的因素。本文将介绍操作系统控制台健康页面的使用及说明。
使用限制
地域限制
本功能目前仅支持中国内地与中国香港。
操作系统限制
架构
操作系统
x86架构
Rocky Linux 9.5
Rocky Linux 9.1
Ubuntu 20.04
Alibaba Cloud Linux 3 容器优化版
Rocky Linux 8.8
Ubuntu 22.04
Alibaba Cloud Linux 3 Pro
Alibaba Cloud Linux 2/3
CentOS 7.6及更高版本,或CentOS 8
Anolis OS 7/8
Ubuntu 24.04
ARM架构
Alibaba Cloud Linux 3 Pro
Alibaba Cloud Linux 3
前提条件
查看SysOM集群/节点健康度
健康度通过运用异常检测算法对异常项所包含的指标进行综合计算,从而得出相应的分数。如果用户认为当前检查项报告的异常与当前业务场景不符,可以通过异常项反馈按钮调整该检查项的异常检测算法的敏感度。
系统概览
在系统概览页面,以下面板展示了集群(当前主账号)的实时健康分及资源数据。

集群健康分
展示当前集群的实时健康得分,健康分等级可分为:
健康:代表集群中的实例/实例的系统处于健康状态,该等级表明集群中可能存在健康或亚健康状态实例,对应实例存在关注级别异常事件,基本对业务无影响。
亚健康:代表集群中的实例/实例的系统处于相对健康状态,该等级表明集群存在亚健康或不健康实例,对应实例存在关注/告警级别异常事件,需要及时处理相关异常,并持续关注健康分的趋势。对业务有轻微影响。
不健康:代表集群中的实例/实例的系统处于不健康状态,该等级表明集群存在不健康或严重不健康实例,对应实例存在告警/危险级别异常事件,需要立即处理相关异常,对业务的影响可感知。
严重不健康:代表集群中的实例/实例的系统处于非常不健康状态,该等级表明集群存在较多严重不健康实例,对应实例存在较多告警/危险级别异常事件,需要立即处理相关异常,可能会给业务带来严重的影响。
集群健康指标
展示集群四种类型指标得分,用户可以通过该面板数据定位到系统中哪种类型指标影响集群健康分,指标分类如下:
饱和度:饱和度用来衡量操作系统的承载能力,一般是操作系统相关资源的使用率。如常见的内存使用率,CPU使用率、磁盘使用率等。
延迟:代表操作系统处理某个请求(任务调度、内存申请、IO、网络)所需要的时间。
负载:当前系统的数据流入流出的数据统计,用来衡量服务的承载能力,不同系统的流量有不同的含义,对于操作系统来说,流量可以指网络、IO流量等。
错误:当前操作系统发生错误请求或者发送错误事件的数量,通常为计数值(例如系统发生OOM的次数、系统发生丢包事件的次数、系统发生夯机事件次数等)。
节点数量面板
当前集群中,处于被纳管且处于运行状态的节点数量(显示一小时数据)。
集群资源总览
当前集群中关键资源的使用情况:
CPU:集群CPU使用情况。
内存:集群内存使用情况。
磁盘:集群根文件系统使用情况。
网络:集群中所有网络上行及下行速率之和。
历史健康详情
通过时间选择器选择对应的时间,历史健康详情框中展示集群历史(过往某段时间)的健康及异常情况。

异常事件分析
异常事件分析面板展示了所有影响集群/实例健康状况的异常检查项。

通过选择框可以筛选出对应等级的异常事件,异常级别说明如下。
关注:当某些监控指标或系统行为指标达到一个可疑的状态,这可能意味着系统存在潜在风险,建议运维人员密切关注这些指标的变化,以便在情况恶化之前采取措施。常见的例子包括CPU使用率接近阈值、内存使用增加趋势等。
警告:当监控指标越过设定的告警阈值,表明可能对系统中业务的正常运行造成影响。此时,运维人员应及时查看并处理相关问题。
危险:当检查项表现出绝对的异常或故障迹象,可能会直接影响到系统的可用性和业务连续性。此时,运维人员需要立即介入,调查并解决存在的问题。
通过实例ID选择框,可以筛选出对应实例的异常事件。
诊断状态
暂无诊断:当前异常项暂无诊断。处于暂无诊断的原因可能如下。
当前异常项暂无对应的诊断支持。
自动诊断处于冷却中。
异常事件结束时间早于当前查看页时间(异常项已结束)。
诊断中:当前异常项正在进行诊断。
诊断完成:当前异常项已完成诊断。通过操作列表中单击查看诊断报告按钮查看报告。
诊断失败:诊断调用失败。常见原因是节点当前时间内同时发起了多个诊断请求。
异常项反馈
用户可以通过反馈机制来调整异常检测算法,从而优化异常项的敏感度。以连续报出节点IO流量检测异常为例。如果认为当前的异常事件上报为误报,用户可以单击其中一个异常项操作中的反馈按钮,并选择相应的生效范围及敏感度调节选项。
若选择仅在当前节点生效,则敏感度设置将适用于当前实例的节点IO流检测。
若选择一键配置集群内所有节点,则敏感度设置将适用于当前集群所有节点的IO流量检测。

TOP 10节点健康列表
TOP 10节点健康列表面板展示了集群中按照健康评分从低到高排序的最低评分的10个实例信息。单击操作列的节点操作健康,将跳转至相应实例的健康度页面。

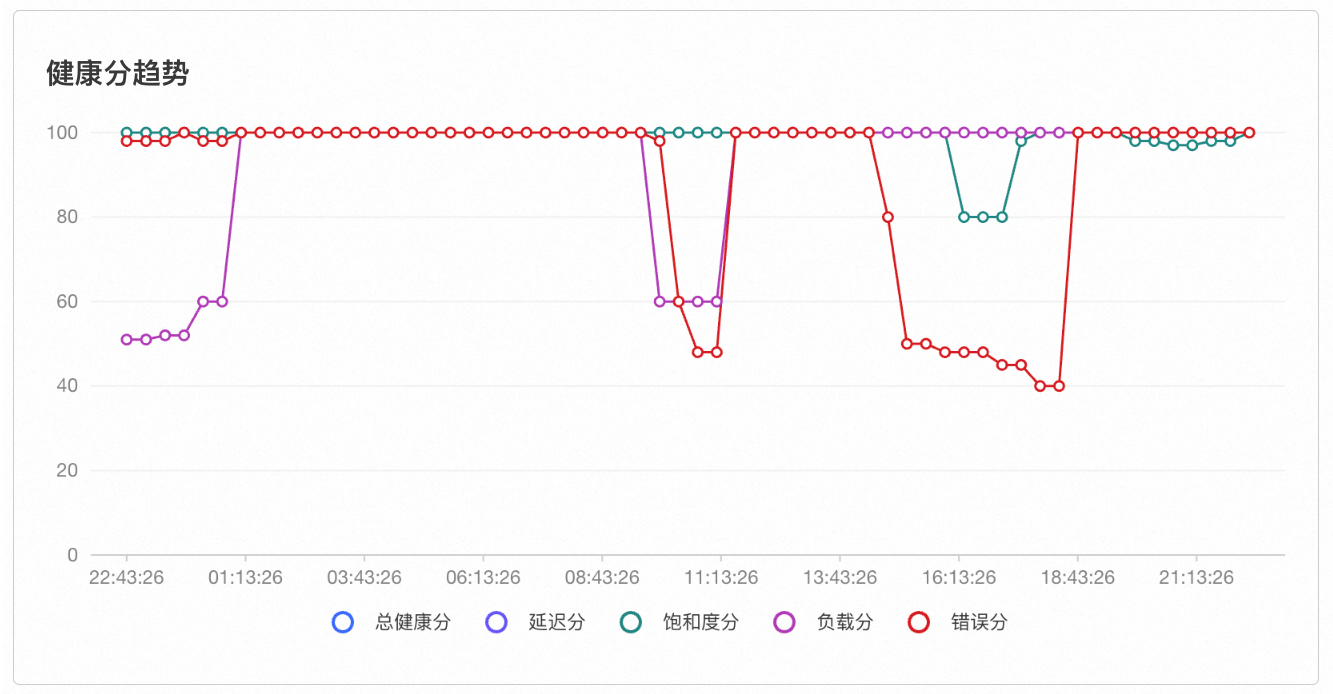
健康分趋势
通过时间选择器显示的时间区间,可以查看总体健康分及四种类型指标健康分的历史情况,从而有效定位集群中历史发生的健康问题。
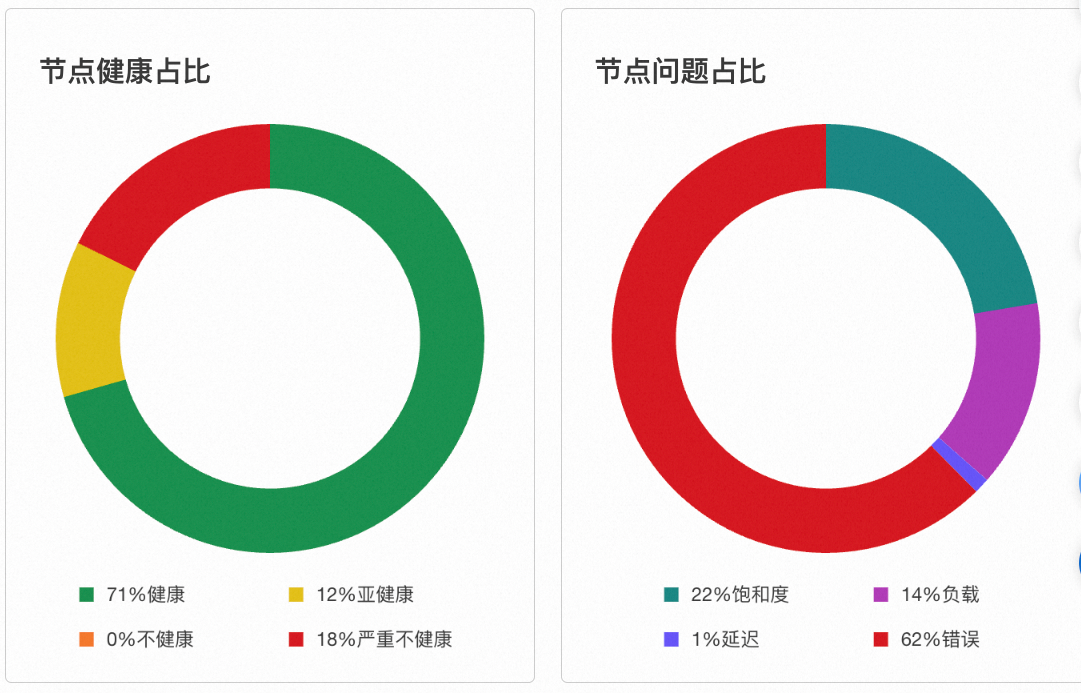
节点健康占比与节点问题占比
节点健康占比通过饼图展示所有节点在各健康等级中的占比,具体分为四个等级。
健康:健康分≥90
亚健康:80≤健康分<90
不健康:60≤健康分<80
严重不健康:健康分<60
节点问题占比通过图形展示各类问题的比例,具体包括饱和度、延迟、负载和错误四个类别。
节点健康页
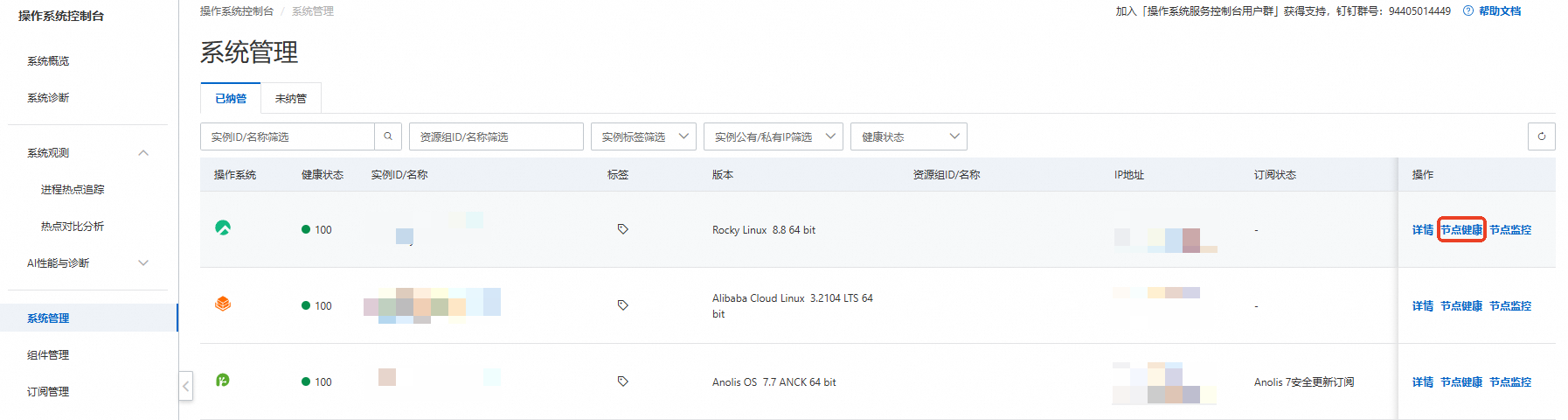
节点健康页面入口
访问操作系统控制台。
在左侧导航栏,单击系统管理。
选择已纳管,输入目标实例ID/名称,或通过条件筛选实例,单击操作列的节点健康。
节点健康页面说明

以上面板展示了所选实例的实时监控分及资源数据。
节点健康分
展示所选实例的实时健康得分,健康分等级可分为:
健康:代表实例的系统/实例中的Pod处于健康状态,该等级表明集群中可能存在健康或亚健康状态实例,对应实例存在关注级别异常事件,基本对业务无影响。
亚健康:代表实例的系统/实例中的Pod处于相对健康状态,该等级表明当前实例存在需要关注的异常项、存在亚健康或不健康Pod,对业务有轻微影响。
不健康:代表节点的系统/节点中的Pod处于不健康状态,该等级表明当前实例存在告警级别的异常项或存在不健康或严重不健康Pod,需要立即处理相关异常,对业务的影响可感知。
严重不健康:代表节点的系统/节点中的Pod处于非常不健康状态,该等级表明当前实例存在危险级别的异常项或存在严重不健康Pod,需要立即处理相关异常,可能会给业务带来严重的影响。
节点健康指标
展示所选实例四种类型指标得分,用户可以通过该面板数据定位到系统中哪种类型指标影响集群健康分,指标分类如下:
饱和度:饱和度用来衡量操作系统的承载能力,一般是操作系统相关资源的使用率。如常见的内存使用率,CPU使用率、磁盘使用率等。
延迟:代表操作系统处理某个请求(任务调度、内存申请、IO、网络)所需要的时间。
负载:当前系统的数据流入流出的数据统计,用来衡量服务的承载能力,不同系统的流量有不同的含义,对于操作系统来说,流量可以指网络、IO流量等。
错误:当前操作系统发生错误请求或者发送错误事件的数量,通常为计数值(例如系统发生OOM的次数、系统发生丢包事件的次数、系统发生夯机事件次数等)。
Pod数量面板
当前实例中部署的处于运行状态的Pod数量。
节点资源总览
CPU:节点CPU使用情况。
内存:节点内存使用情况。
磁盘:节点根文件系统使用情况。
网络:节点中所有网络上行及下行速率之和。
历史健康详情
节点异常事件分析

节点异常事件分析面板展示了所有影响实例/Pod健康情况的异常检查项。通过选择框可以筛选出对应等级的异常事件。
若实例中部署有Pod,可以通过POD选择框查看ECS实例中Pod的异常事件,通过Pod名称和NAMESPACE筛选框,可以筛选出对应Pod和NameSpace的异常事件。
通过选择框可以筛选出对应等级的异常事件,异常级别说明如下。
关注:当某些监控指标或系统行为指标达到一个可疑的状态,这可能意味着系统存在潜在风险,建议运维人员密切关注这些指标的变化,以便在情况恶化之前采取措施。常见的例子包括CPU使用率接近阈值、内存使用增加趋势等。
警告:当监控指标越过设定的告警阈值,表明可能对系统中业务的正常运行造成影响。此时,运维人员应及时查看并处理相关问题。
危险:当检查项表现出绝对的异常或故障迹象,可能会直接影响到系统的可用性和业务连续性。此时,运维人员需要立即介入,调查并解决存在的问题。
诊断状态
暂无诊断:当前异常项暂无诊断。处于暂无诊断的原因可能如下。
当前异常项暂无对应的诊断支持。
自动诊断处于冷却中。
异常事件结束时间早于当前查看页时间(异常项已结束)。
诊断中:当前异常项正在进行诊断。
诊断完成:当前异常项已完成诊断。通过操作列表中单击查看诊断报告按钮查看报告。
诊断失败:诊断调用失败。常见原因是节点当前时间内同时发起了多个诊断请求。
异常项反馈
用户可以通过反馈机制来调整异常检测算法,从而优化异常项的敏感度。以连续报出节点IO流量检测异常为例。如果认为当前的异常事件上报为误报,用户可以单击其中一个异常项操作中的反馈按钮,并选择相应的生效范围及敏感度调节选项。
若选择仅在当前节点生效,则敏感度设置将适用于当前实例的节点IO流检测。
若选择一键配置集群内所有节点,则敏感度设置将适用于当前集群所有节点的IO流量检测。

TOP10 POD健康列表
若ECS实例中存在Pod,则TOP10 Pod健康列表面板将显示该ECS实例中按健康分从低到高排序的前10个最低分Pod的信息。
Pod的具体信息。
Pod健康分表示时间选择器选择时间区间中当前Pod的最低分。
镜像表示Pod中容器的镜像(最多只展示5个容器的镜像)状态代表了Pod的当前状态(运行中/离线)。

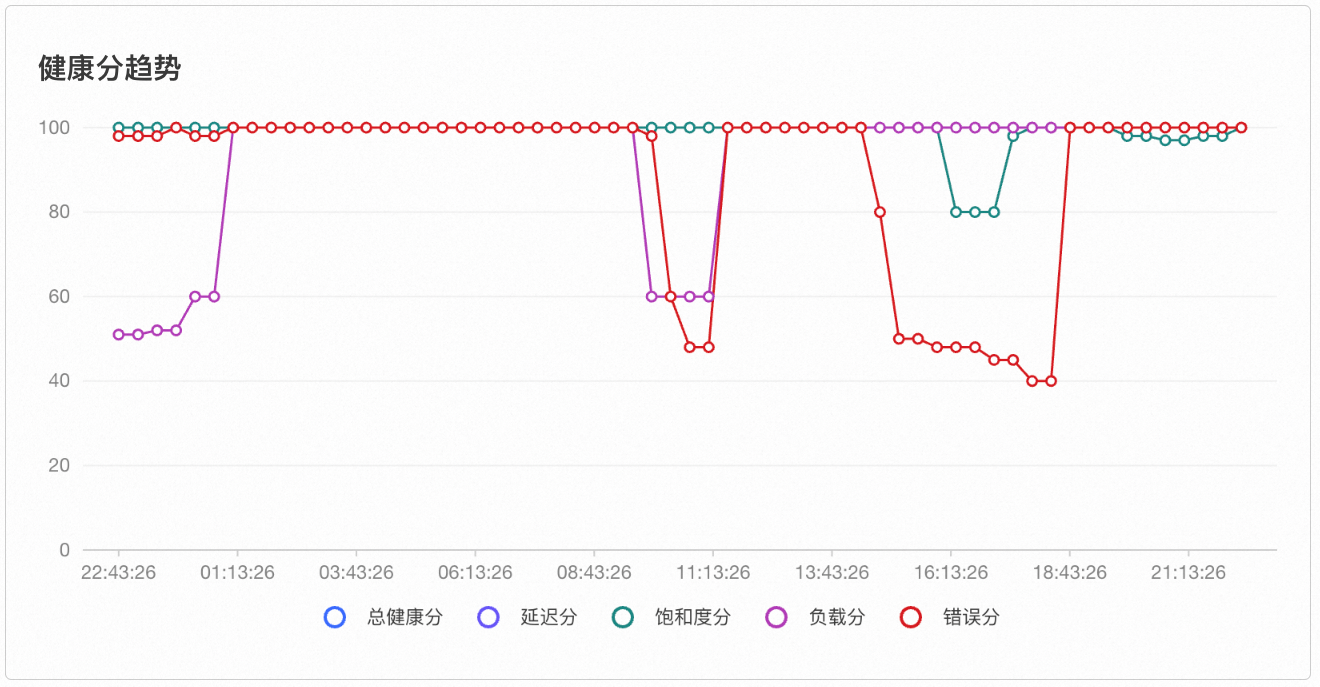
健康分趋势
通过时间选择器显示的时间区间,可以查看总体健康分及四种类型指标健康分的历史情况,从而有效定位实例中历史发生的健康问题。
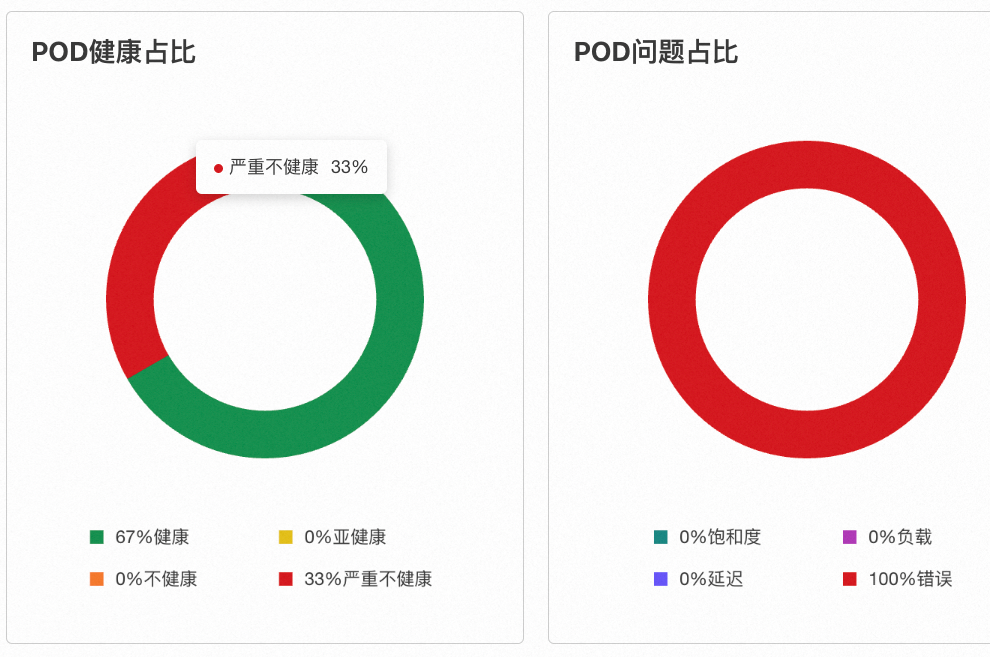
POD健康占比与POD问题占比
POD健康占比通过饼图展示当前ECS实例中所有POD各健康等级的比例,具体分为四个等级。
健康:健康分≥90
亚健康:80≤健康分<90
不健康:60≤健康分<80
严重不健康:健康分<60
POD问题占比利用图来显示各类问题的占比,分别为饱和度、延迟、负载和错误四类。
实践案例
通过四个典型案例展示如何从健康分降低至异常事件,再到诊断问题的发现及其解决方案的全链路运维实例。
内存占用异常分析
健康度设置了节点内存检查和节点内核内存检查两个项目,以监测ECS实例的内存占用情况。以下将通过共享内存占用过高和内核模块内存泄漏两个场景,展示从健康状态降低到异常事件的过程,以及诊断的完整流程。
应用申请大量共享内存或者内核模块存在内核内存泄漏漏洞。
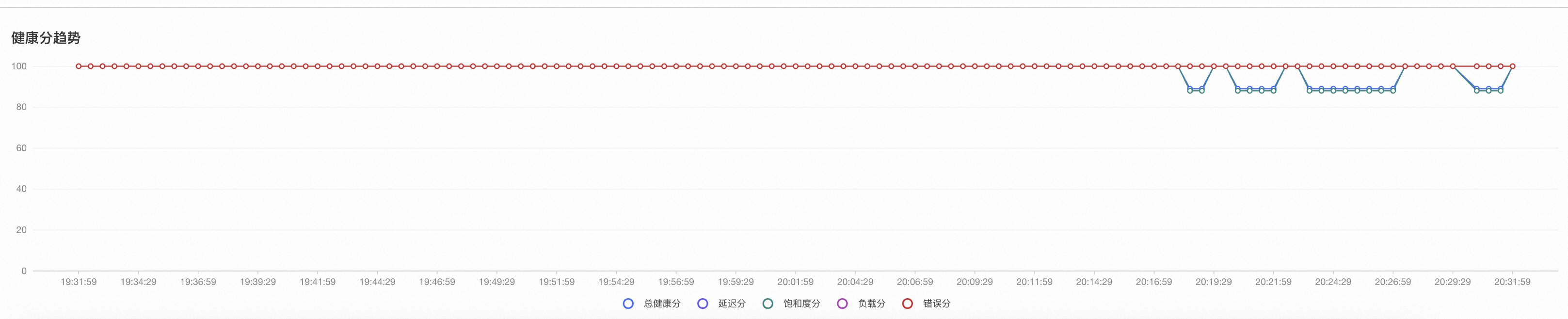
用户可以通过集群/节点的实时健康分或健康分趋势,发现集群/节点的总分及饱和度分已下降至亚健康或不健康状态。如图所示,如果异常情况持续发生且仍在进行中,则可以通过实时健康分面板监测到分数的降低。

如果是历史某一时段发生的异常,则可以通过健康分趋势观察到某一时段的饱和度以及健康分下降。
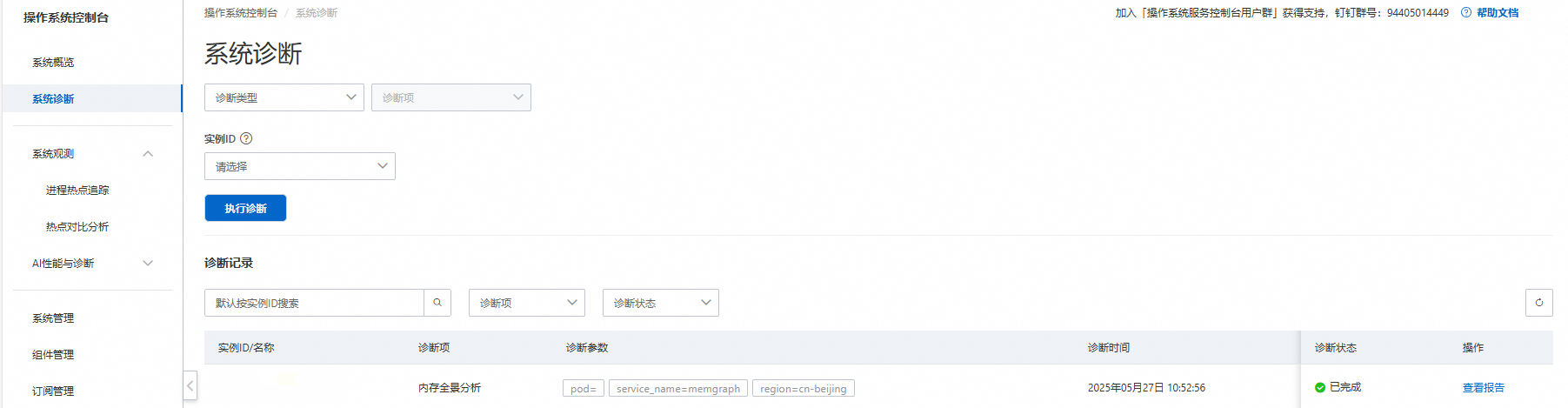
用户从异常事件分析面板中找到对应时间段的异常事件(共享内存高场景时会出现系统内存使用高异常事件;内核内存泄漏场景会同时出现ECS实例内存使用高和ECS实例内核不可回收Slab/可回收Slab/直接页面分配内存使用率高异常事件),点击异常事件操作列的诊断按钮后,跳转至系统诊断页面,并自动选择对应的诊断项以及诊断对应的实例。

OOM夯机预测及分析
健康度设置了实例OOM预测检查项,该检查项结合了ECS实例的内存使用率、CPU使用率、负载、IO Wait等指标对OOM的概率进行计算。同时,该检查项也能够反映实例过去发生的OOM事件。以下将通过已经发生OOM和即将发生OOM的两个场景,展示如何从健康状态下降到异常事件,再到诊断的一站式问题解决。
已发生OOM事件的场景。
由于OOM事件通常是瞬时发生的,因此用户通常难以从集群或节点的实时健康分中识别出因OOM事件引起的分数下降。
如果是历史某一时段发生的OOM异常,则可以通过健康分趋势观察到某一时段的错误分以及健康分下降。

从异常事件分析面板中找到相应时间段的OOM异常事件,单击异常事件操作列中的诊断按钮后,将对该次OOM异常事件进行诊断。诊断完成后,异常项对应的操作列将显示查看诊断报告,点击该选项后即可查看具体的诊断报告。
OOM夯机预测场景。
由于OOM夯机事件通常是短时间内发生的现象,因此用户通常难以通过集群或节点的实时健康分数识别因OOM夯机事件引起的分数下降。
如果某一历史时段发生了OOM夯机事件,则可以通过健康分趋势观察到该时段内错误分和健康分的下降情况。
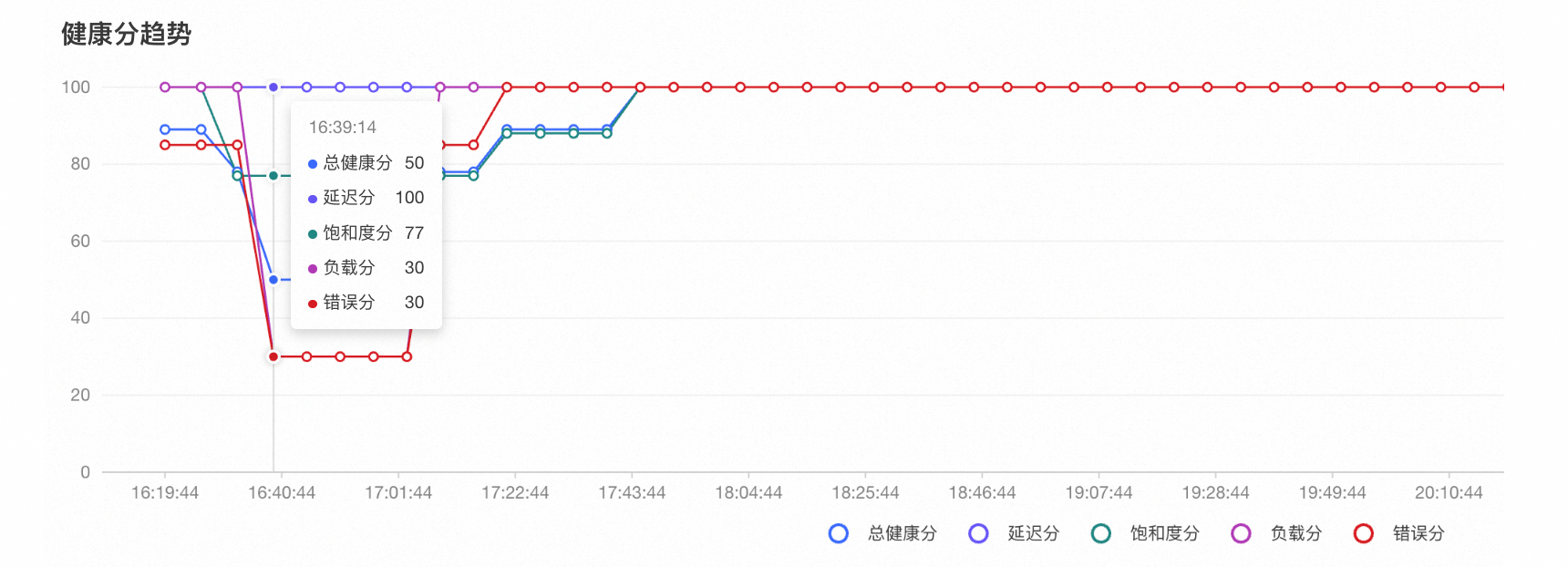
用户在异常事件分析面板中定位到相应时间段的OOM异常事件(可能伴随ECS实例IO流量异常),并且在描述中显示发生了OOM异常事件。单击异常事件操作列中的诊断按钮后,将跳转至系统诊断页面,并自动选择相应的诊断项(内存全景分析)及对应的实例进行诊断。

调度延时抖动
健康度设置了节点调度延时检查项,该检查项会检测节点是否发生调度延时事件。
节点发生调度延时。
用户从集群/节点的实时健康分或健康分趋势中发现集群/节点总分以及延迟分下降至亚健康或不健康状态。如下图所示,如果异常持续发生,且仍然在发生,则可以通过实时健康分面板观察到分数下降。

如果是历史某一时段发生的异常,则可以通过健康分趋势观察到某一时段的延迟分以及健康分下降。
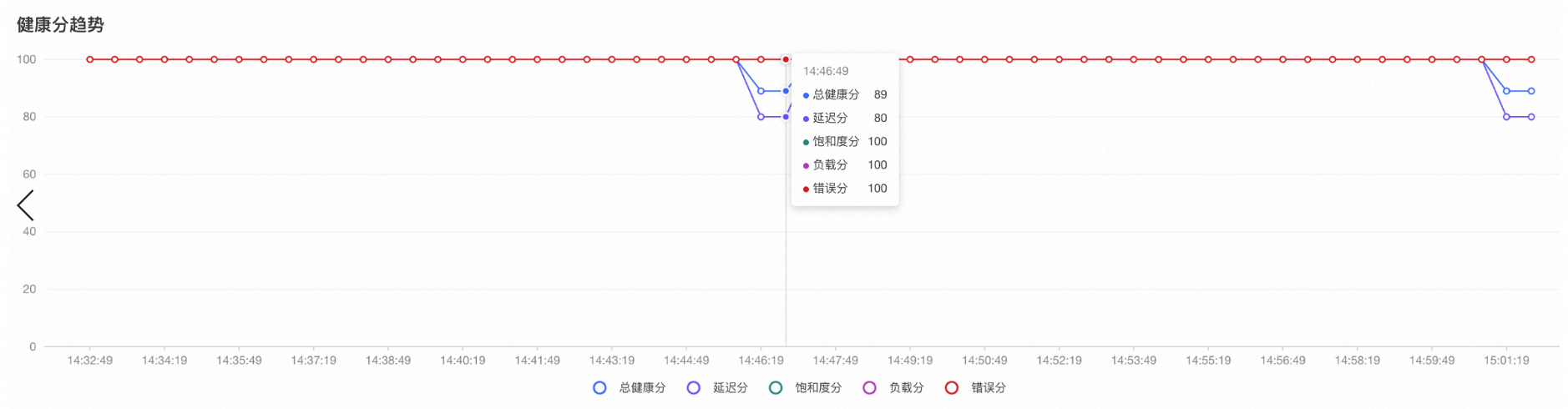
用户从异常事件分析面板中找到对应时间段的ECS实例调度延时事件。

点击诊断后,将会对调度抖动异常事件进行诊断,诊断完成后,异常项对应的操作列将显示查看诊断报告,点击该选项后即可查看具体的诊断报告。
网络丢包分析
用户通过集群/节点的实时健康分或健康分趋势,发现集群/节点的总分及错误分下降至亚健康或不健康状态。如图所示,如果异常现象持续发生且仍在进行中,则可以通过实时健康分面板观察到分数的下降情况。

如果是历史某一时段发生的异常,则可以通过健康分趋势观察到某一时段的错误分以及健康分下降。
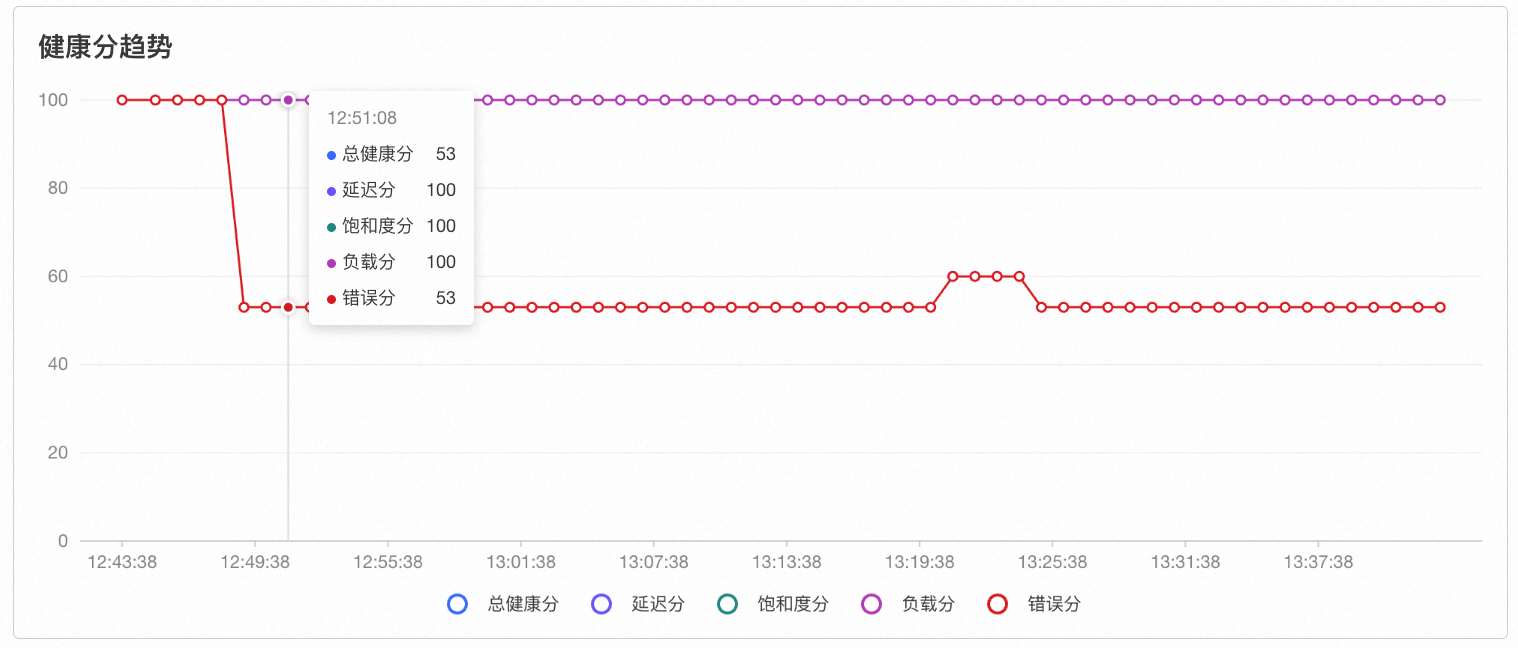
从异常事件分析面板中找到对应时间段的ECS实例网络丢包异常事件。

点击诊断后,将会对此次网络丢包异常事件进行诊断。诊断完成后,异常项对应的操作列将显示查看诊断报告,点击该选项后即可查看具体的诊断报告。
系统高负载分析
系统负载是衡量当前系统负载及压力状况的关键指标,其定义为在一段时间内CPU正在处理和等待处理的进程总数。由于系统的复杂性,导致高负载的原因多种多样。可以通过监测系统的一分钟平均负载来识别异常,并利用系统负载诊断提供高负载原因分析及相应的修复建议。
节点因错误的CPU绑核、网络、IO等内核资源竞争而导致系统负载指标出现抖动。
用户从集群/节点的实时健康分或健康分趋势中发现集群/节点总分以及错误分下降。如图所示,如果异常现象持续发生且仍在进行中,则可以通过实时健康分面板观察到分数的下降情况。

如果异常发生在历史某一时间段内,可以通过健康分趋势观察该时间段内的错误分以及健康分的下降情况,如下图所示。

从异常事件分析面板中找到对应时间段的节点负载高异常事件。
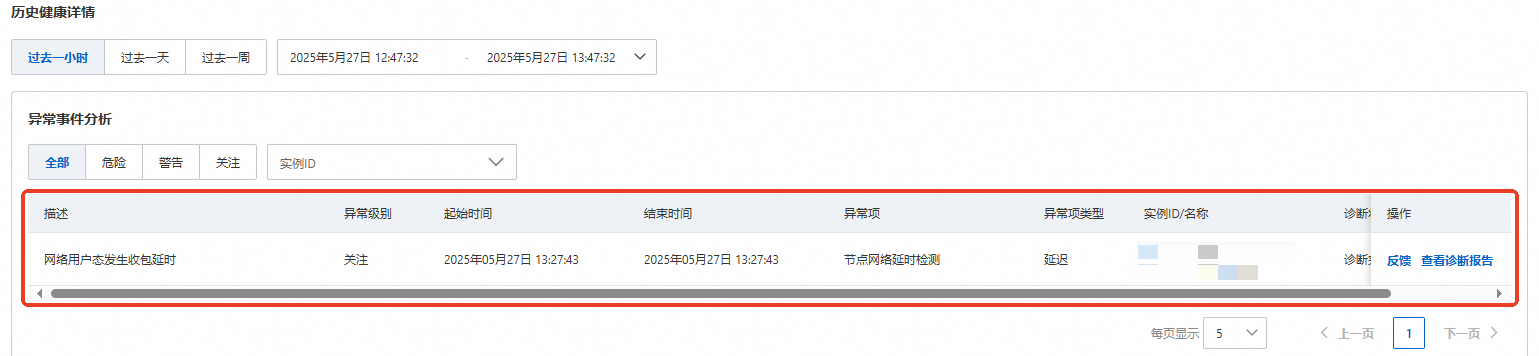
点击诊断后,将会对此次网络丢包异常事件进行诊断。诊断完成后,异常项对应的操作列将显示查看诊断报告,点击该选项后即可查看具体的诊断报告。