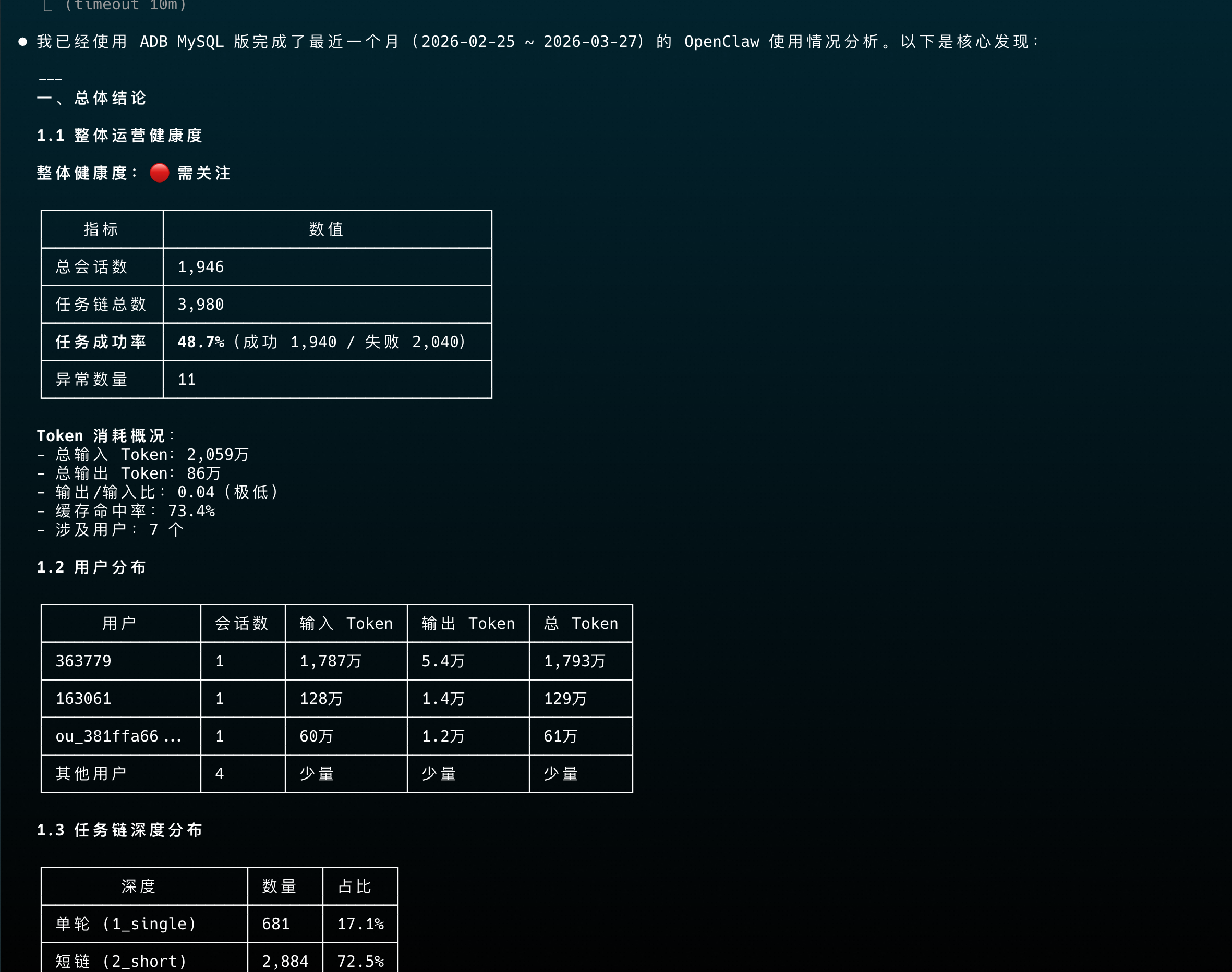
通过 Skill 插件实现OpenClaw日志分析
alibabacloud-adb-openclaw-insight 是一个专为 OpenClaw 会话数据设计的三层自动化分析SKILL。通过连接到AnalyticDB for MySQL数据库,对存储的会话日志进行深度挖掘,自动生成从运营效率、用户行为到组织认知等多个维度的结构化分析结果和叙事性报告,帮助您全面洞察 Agent 的使用情况。
功能详解:三层自动化分析
L1 - 运营层分析 (无需 LLM)
此层分析完全基于 SQL 统计,无需依赖大语言模型,专注于量化的运营指标。
分析用例 | 功能说明 | 场景示例 |
L1-1 Token 效率分析 | 统计各用户/模型的输入输出 Token 消耗、缓存命中率及平均每会话成本。 | 通过效率分析,可以了解用户Token的使用情况。 |
L1-2 会话深度分析 | 分析每个任务链(Task Chain)的平均对话轮次,识别深度交互的会话。 | 通过深度分析,可以了解每个用户的任务执行复杂度。比如,B用户某个任务对话执行步骤最多,任务复杂度最高。 |
L1-3 工具链分析 | 统计工具(Tool)的使用频率及组合模式,发现最常用的工具序列。 | 通过工具链分析,可以发现比如exec工具执行次数最多,了解到Agent执行脚本较多。 |
L1-4 高成本会话识别 | 定位 Token 消耗或费用异常高的会话,快速发现成本热点。 | 通过高成本会话分析,可以发现A用户某会话Token消耗占据了50%以上的Token。 |
L1-5 异常检测 | 基于 Z-Score 算法,对 Token 消耗和响应时间进行统计学上的异常标记。 | 通过异常检测,可以发现某任务一直在重试,消耗了大量Token,做了很多无用功。 |
L2 - 行为层分析 (需要 LLM)
此层分析借助大语言模型(LLM)的能力,对用户行为和任务过程进行深度的定性与定量分析。
分析用例 | 功能说明 | 场景示例 |
L2-1 意图分类 | 将用户的提问归类为编码、调试、问答、数据分析等具体意图。 | 通过意图分类结果,如果发现编码场景用户数最多,聊天场景用户数最少,说明大部分人都在开发。 |
L2-2 任务复杂度评估 | 综合对话轮次、工具使用次数和 Token 量,为每个任务链评定复杂度等级(1-5级)。 | 通过任务复杂度评估,可以看到Task Chain按照执行复杂度排序的列表。 |
L2-3 任务成功率估算 | 基于对话的最终结果,推断每个任务链是否成功完成目标。 | 通过任务成功率估算,可以了解到比如大部分Task Chain都是成功的,只有少数是失败,可以找出失败的原因。 |
L2-4 Prompt 质量评分 | 对用户输入的 Prompt 质量进行打分,识别可优化的低质量输入模式。 | 通过质量评分,可以找出Prompt质量高的用户,进行推广学习。 |
L2-5 主题聚类 | 对所有会话的主题进行聚类,发现用户最关注的热点领域。 | 通过主题聚类结果可以发现大家都在关注的AI 信息。 |
L2-6 重试行为检测 | 检测用户在同一会话内多次重试或追问的行为模式。 | 通过重试行为检测,可以发现某类型任务,Agent的执行能力最弱,可以提供给模型Provider优化模型。 |
L2-7 思考深度分析 | 分析助手的 Thinking 轮次与深度,评估推理复杂度。 | 通过思考深度分析,可以发现某种任务类型,模型思考最多,说明任务复杂度比较高。 |
L2-8 用户成熟度追踪 | 基于历史交互习惯,将用户分级(初级 / 中级 / 高级)。 | 通过用户成熟度追踪,可以发现大家使用AI的能力都在什么水平。 |
L3 - 组织层分析 (需要 LLM)
此层分析从更高维度审视跨用户、跨会话的集体行为模式,旨在发现组织层面的知识缺口与改进机会。
分析用例 | 功能说明 | 场景示例 |
L3-1 技术栈热力图 | 统计各种技术栈、编程语言或框架被提及的频率,生成技术热度排行。 | 通过技术栈热力图,可以发现大家关注的技术热点都是什么。 |
L3-2 重复问题检测 | 识别跨会话、跨用户的高频重复问题,这通常反映了知识库或文档的不足。 | 通过重复问题检测,可以发现大家的关注点都是什么,有哪些业务可以完全自动化的。 |
L3-3 Skill 候选分析 | 根据高频出现的任务模式,推荐可被固化为独立 Skill 的潜在场景。 | 通过SKILL候选分析,可以将高频任务沉淀为SKILL,避免每次都要Agent进行复杂处理,减少Token消耗。 |
L3-4 用户画像报告 | 为每位用户汇总其行为特征、技术偏好和使用习惯,生成摘要报告。 | 通过画像报告,可以了解每位用户使用AI的偏好,识别工作复杂度以及问题处理效率。 |
L3-5 最终叙事报告 | 综合 L1/L2/L3 的所有分析结果,自动生成一份完整的 Markdown 格式分析报告。 | 通过报告可以让管理总览全局,了解大家AI的使用成本以及AI的推广程度。 |
每次分析完成后还会自动生成 insight_logic_explanation.md,解释本次各用例的指标计算逻辑,语言与报告主体一致(中文数据 → 中文,英文数据 → 英文)。
注意事项
数据量要求
L1 分析:无数据量下限,但建议至少有1条会话记录以进行有效统计。
L2 分析:建议至少有 50 个任务链,以保证意图分类和主题聚类的结果具有参考价值。
L3 分析:建议至少有 100 个任务链,以确保跨会话的重复问题检测足够准确。
LLM 依赖
L1 分析完全不依赖 LLM。
L2 和 L3 的所有分析用例都必须配置 LLM API,否则将被自动跳过。
单次分析默认最多向 LLM 发送 500 个会话(可在
config.json中调整maxSessionsForLlm)。建议使用支持长上下文窗口(≥ 32K,推荐 128K+)的模型。
数据库 Schema 依赖
Skill 依赖以下三张表。init_db脚本会自动创建或补齐这些表及其字段。表名
用途
openclaw_sessions存储会话的每一条消息(角色、内容、Token 等)。
openclaw_logs存储运行时日志(可选)。
openclaw_analysis_results存储每次分析的结果。
分析默认基于最近2天数据(可通过
--from/--to指定时间窗口),结果仅反映该窗口内情况,不跨窗口累计,且数据保留周期由retentionDays(默认2天)控制,超期数据将自动清理。当前不支持实时流式分析,所有分析均为批量历史数据处理。
L2-5 主题聚类在用户意图分布高度分散时,聚类结果可能粒度较粗。
L3-2 重复问题检测基于语义相似度,需要 LLM 推断,对完全相同的字面问题检测更准确。
安装与配置步骤
自动安装
您可通过 OpenCLaw 对话框一键完成安装:只需输入以下指令并按提示提供相应配置信息即可。如需了解具体执行细节,请参考手动部署页面。
请使用如下命令安装alibabacloud-adb-openclaw-insight SKILL到你的SKILL目录:
git clone https://github.com/aliyun/alibabacloud-adb-mysql-mcp-server
cd alibabacloud-adb-mysql-mcp-server/skill/alibabacloud-adb-openclaw-insight,
下载完成后,请阅读 SKILL.md,安装对应依赖,更新配置文件,并完成数据库初始化。手动部署
步骤一:克隆仓库并准备环境
git clone https://github.com/aliyun/alibabacloud-adb-mysql-mcp-server
cd alibabacloud-adb-mysql-mcp-server/skill/alibabacloud-adb-openclaw-insight步骤二:安装项目依赖
方式一:使用 uv(推荐)
# 安装 uv 包管理器 curl -LsSf https://astral.sh/uv/install.sh | sh # 安装项目依赖 uv pip install -r requirements.txt方式二:使用 pip
pip install -r requirements.txt # 如果找不到 "pip",请尝试: pip3 install -r requirements.txt
步骤三:配置 Skill 连接信息
这是安装过程中唯一需要手动干预的步骤。请在继续之前,收集并确认以下配置信息。
AnalyticDB for MySQL 连接信息
配置项
说明
示例
adb.hostAnalyticDB for MySQL集群的连接地址。
am-xxxxxxxx.ads.aliyuncs.comadb.port数据库端口号。
3306adb.database目标数据库名称。
openclaw_adbadb.username数据库用户名。
your_useradb.password数据库密码。
your_passwordLLM 大模型配置
说明如果用户只需要 L1 运营效率分析,可跳过此部分。
配置项
说明
示例
llm.endpoint大模型 API 的服务地址。
https://dashscope.aliyuncs.com/compatible-mode/v1llm.apiKeyAPI Key。
sk-xxxxxxxxxxllm.model模型名称。
qwen-plusllm.apiTypeAPI 协议类型 (
openai或anthropic)。openai(可选)分析模块开关
配置项
说明
默认值
analysis.enableL1启用 L1 分析。
trueanalysis.enableL2启用 L2 分析 (需要 LLM)。
trueanalysis.enableL3启用 L3 分析 (需要 LLM)。
trueanalysis.analysisWindowDays分析时间窗口(天)
7
步骤四:写入配置文件
根据用户提供的信息,从模板生成 config.json:
cp config.example.json config.json然后将用户提供的值写入 config.json 对应字段。最终文件结构如下:
{
"adb": {
"host": "<用户提供的 host>",
"port": 3306,
"database": "<用户提供的 database>",
"username": "<用户提供的 username>",
"password": "<用户提供的 password>",
"sessionTable": "openclaw_sessions",
"logsTable": "openclaw_logs",
"connectionPoolSize": 5
},
"collection": {
"intervalMinutes": 5,
"batchSize": 100,
"retentionDays": 7,
"enableLogCollection": true,
"enableTokenCollection": true
},
"filters": {
"minLevel": "info",
"includeSubsystems": [ ],
"excludeSubsystems": ["verbose", "trace"]
},
"llm": {
"endpoint": "<用户提供的 endpoint,如未提供则留空>",
"apiKey": "<用户提供的 apiKey,如未提供则留空>",
"model": "<用户提供的 model>",
"apiType": "<用户提供的 apiType>",
"maxConcurrency": 5,
"temperature": 0.1,
"maxTokens": 128000
},
"analysis": {
"enableL1": true,
"enableL2": <用户是否启用 L2>,
"enableL3": <用户是否启用 L3>,
"analysisWindowDays": 7,
"maxSessionsForLlm": 500
}
}
步骤五:初始化数据库
此命令将在AnalyticDB for MySQL版集群中创建或更新所需的表结构。
python -m scripts.init_db
# 如果找不到 "python",请尝试:
python3 -m scripts.init_db运行与验证
启动服务与数据采集
方式一:前台启动
此命令会立即启动服务并在前台运行,适合快速测试。python -m scripts.main # 如果找不到 "python",请尝试: python3 -m scripts.main服务启动后将自动开始采集 OpenClaw 会话日志并按计划执行分析。
方式二:注册为定时任务(生产推荐)
为实现持续自动的数据采集,建议将采集脚本注册为 OpenClaw 的定时任务(Cron Job)。{ "cron": "*/30 * * * * *", "command": "python -m scripts.main collect", "cwd": "/path/to/alibabacloud-adb-mysql-mcp-server/skill/alibabacloud-adb-openclaw-insight" }
手动触发分析
在数据采集运行一段时间后,您可以随时手动触发分析脚本。
# 分析过去 1 天
python -m scripts.analyze_usage --from "$(date -d '1 day ago' '+%Y-%m-%d') 00:00:00" --to "$(date '+%Y-%m-%d') 23:59:59"
# 分析过去 2 天
python -m scripts.analyze_usage --from "$(date -d '2 days ago' '+%Y-%m-%d') 00:00:00" --to "$(date '+%Y-%m-%d') 23:59:59"
验证安装结果
安装并运行服务片刻后,执行以下 SQL 查询来验证数据采集链路是否正常。
SELECT COUNT(*) FROM openclaw_sessions;
SELECT COUNT(*) FROM openclaw_logs;如果两张表的查询结果均大于 0,则表明 Skill 已成功安装并开始采集数据。
分析使用示例
完成 Skill 挂载后,输入相应指令,系统将自动识别并返回结构化分析结果。
命令行界面输入:
/alibabacloud-adb-openclaw-insight 帮我使用ADB分析下最近一个月用户的openclaw的使用情况分析结果