迁移Azure Databricks Delta Lake表数据
本文介绍如何通过PySpark方式将Azure Databricks的Delta Lake表数据迁移至云原生数据仓库 AnalyticDB MySQL 版。
方案优势
在数据迁移过程中,通常需要将少量数据导入至目标数据源,以验证基本流程是否符合预期。Delta Lake表与其他数据湖表格式不同,其采用了“一份数据,两份元数据”的设计模式。您可以通过本教程提供的方案,使用PySpark方式将Azure Databricks的Delta Lake表数据迁移至AnalyticDB for MySQL。
该方案具有以下优势:
AnalyticDB for MySQL Spark可以直接与Azure存储账户进行集成,无需经过Databricks的JDBC端点,从而实现更优的吞吐性能。
整个数据读取过程与Databricks Unity Catalog API之间呈现松耦合关系,您只需获取Delta Lake表的存储路径即可进行数据迁移。这种模式具有更高的灵活性。数据同步代码可以方便地复用于其他云生态中的Databricks表数据迁移。
在整个数据同步过程中,您只需定义Databricks的Schema或表名称,即可自动完成Databricks的Schema和表向AnalyticDB for MySQL的迁移。借助该脚本工具,可以轻松灵活地将更多数据迁移至AnalyticDB for MySQL。
前提条件
AnalyticDB for MySQL集群的产品系列为企业版、基础版或湖仓版。
若您没有符合上述条件的集群,可以登录云原生数据仓库AnalyticDB MySQL控制台创建企业版或基础版集群。
已创建数据库账号。
如果是通过阿里云账号访问,只需创建高权限账号。
如果是通过RAM用户访问,需要创建高权限账号和普通账号并且将RAM用户绑定到普通账号上。
AnalyticDB for MySQL集群与OSS存储空间位于相同地域。
准备工作
下载AnalyticDB for MySQL Spark访问Azure storage account依赖的Jar包,并将其上传至OSS中。
下载链接jetty-util-ajax-9.4.51.v20230217.jar、jetty-server-9.4.51.v20230217.jar、jetty-io-9.4.51.v20230217.jar、jetty-util-9.4.51.v20230217.jar、azure-storage-8.6.0.jar、hadoop-azure-3.3.0.jar和hadoop-azure-datalake-3.3.0.jar。
创建Notebook工作空间。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。

创建Spark集群。
单击
 按钮,进入资源管理页面,单击计算集群。
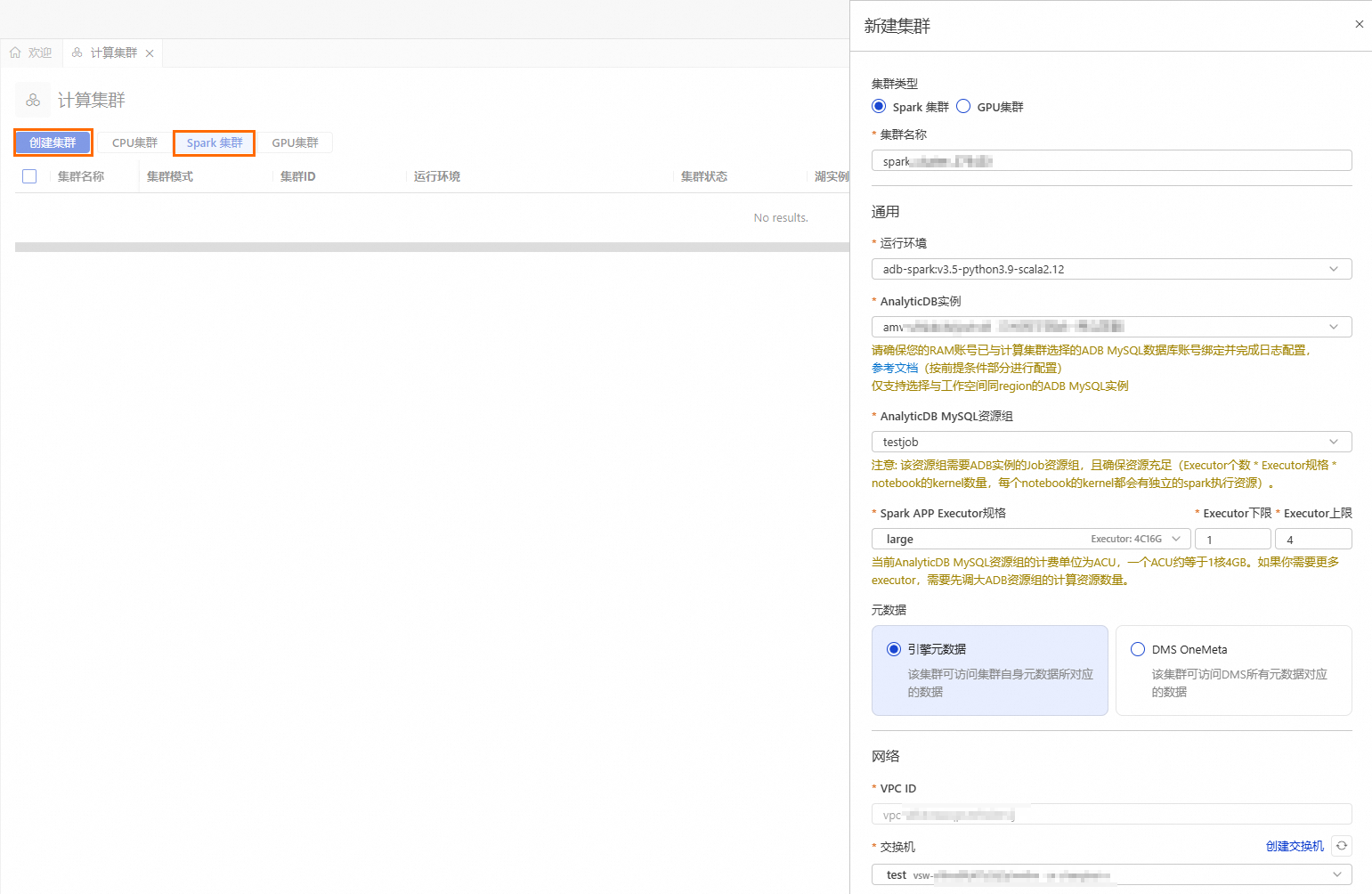
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:
参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
目前支持选择如下镜像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
创建并启动Notebook会话时,首次启动需要等待大约5分钟。
单击
按钮,进入资源管理页面,单击Notebook会话。单击创建会话,并配置如下参数:
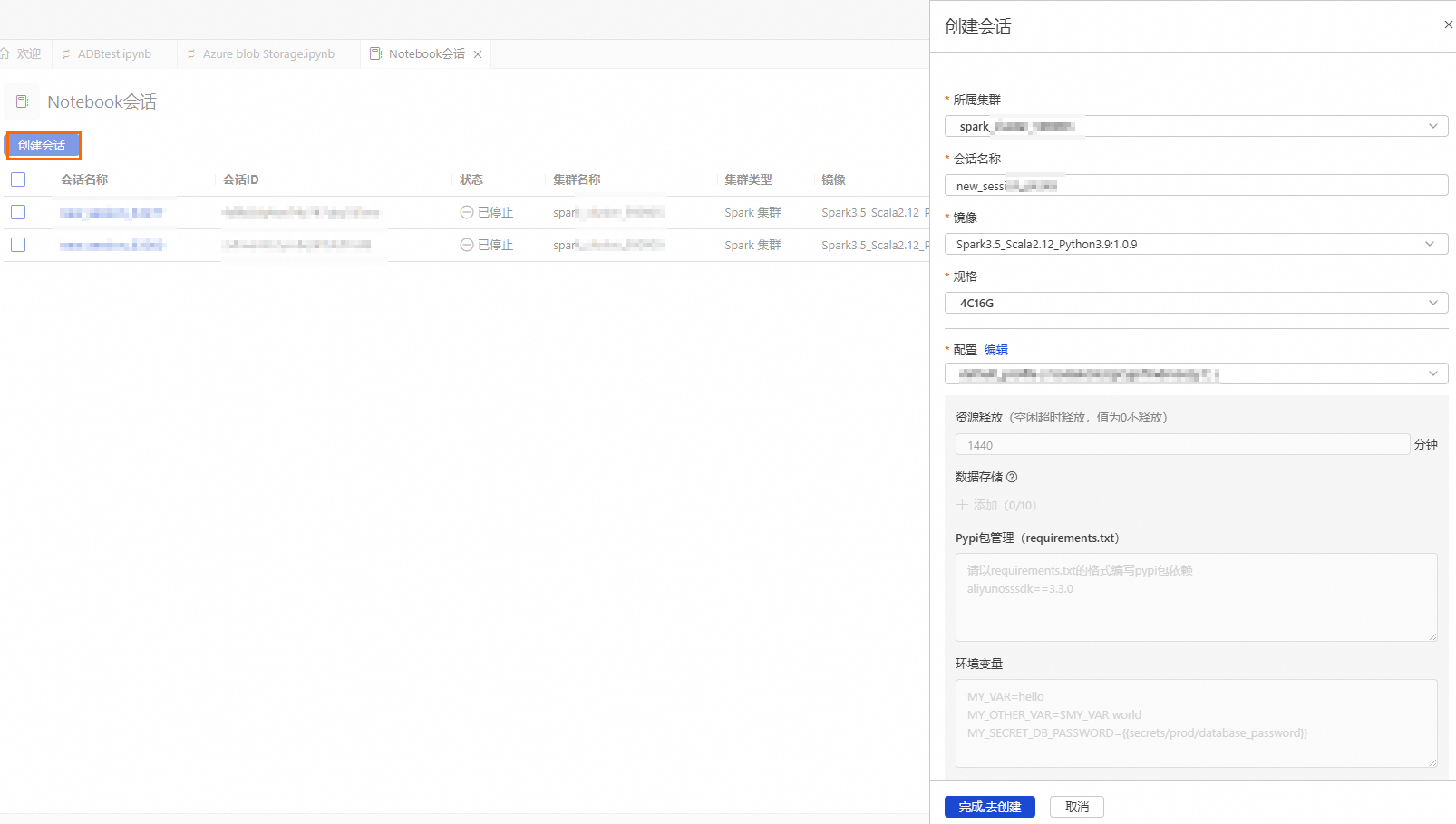
参数说明:
参数
说明
示例值
所属集群
选择步骤4创建的Spark集群。
spark_test
会话名称
您可自定义会话名称。
new_session
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9(推荐)
Spark3.3_Scala2.12_Python3.9:1.0.9
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
kernel的资源规格。
1核4 GB
2核8 GB
4核16 GB
8核32 GB
16核64 GB
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
default_profile
操作步骤
配置公网环境。
公网NAT网关需要与AnalyticDB for MySQL实例为同一个地域。
- 重要
推荐按交换机粒度创建SNAT条目。为保证成功读取并导入Azure Blob Storage数据,创建SNAT条目时指定的交换机需要与创建Spark集群的交换机一致。
下载示例文件DirectlyReadDatabricksDeltaTable_V01.ipynb。
DirectlyReadDatabricksDeltaTable_V01.ipynb脚本文件包括如下流程:
安装与Azure Databricks存储访问相关的Python依赖。
初始化解析Deltalake文件路径以及测试Azure访问的网络连接性。
定义访问Azure Databricks及AnalyticDB for MySQL的相关身份凭证信息。
启动Spark应用程序。
自动创建同名的数据库,并将Azure Databricks表读取为DataFrame,然后将DataFrame中的数据保存到AnalyticDB for MySQL中,创建同名的Delta Lake表。
上传
DirectlyReadDatabricksDeltaTable_V01.ipynb文件至default(默认库)文件夹。进入DMS Notebook,单击左侧导航栏
 按钮,进入资源管理器页面。
按钮,进入资源管理器页面。鼠标悬浮在default(默认库)上右击,然后单击上传文件,选择步骤2下载的示例文件。

执行
DirectlyReadDatabricksDeltaTable_V01.ipynb文件,迁移Azure Databricks数据。打开
DirectlyReadDatabricksDeltaTable_V01.ipynb文件,将第3个Cell中的参数取值替换为实际值。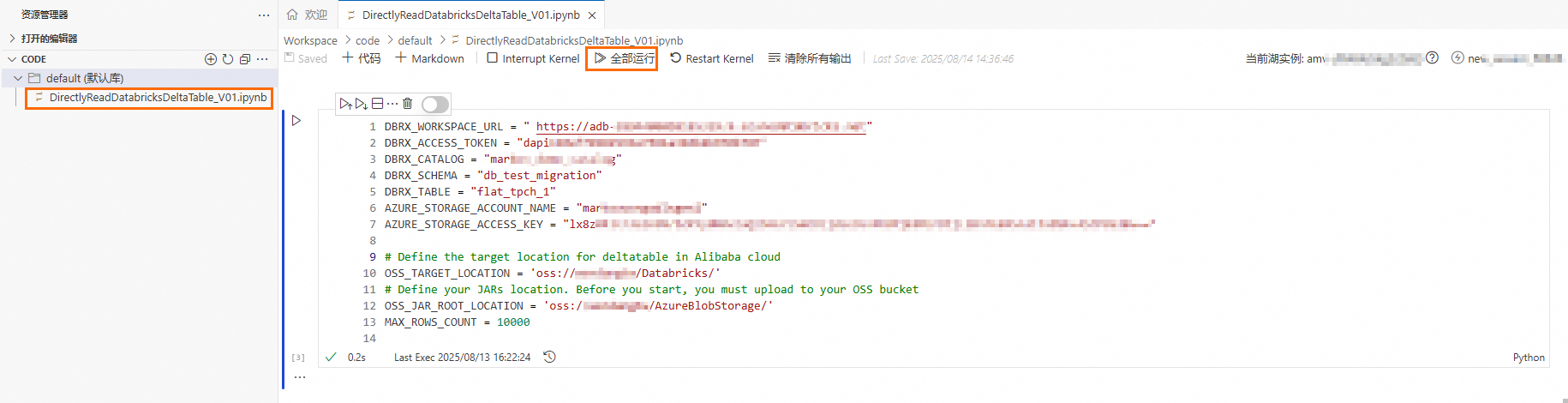
参数说明:
参数
说明
示例值
DBRX_WORKSPACE_URL
Azure Databricks的工作区 URL,格式为
https://adb-28****.9.azuredatabricks.net。获取方法,请参见Workspace URL。https://adb-28****.9.azuredatabricks.net
DBRX_ACCESS_TOKEN
Azure Databricks的访问令牌,且需确保已具有Catalog或Schema的读取权限。获取方法,请参见Manage personal access token permissions。
dapi****
DBRX_CATALOG
Azure Databricks的Catalog名称。
markov****
DBRX_SCHEMA
Azure Databricks的Schema名称。
db_test_migration
DBRX_TABLE
Azure Databricks的表名称。表类型必须为Delta Lake。
flat_tpch_1
AZURE_STORAGE_ACCOUNT_NAME
Azure Databricks表所在的Azure Data Lake Storage名称。
mark****
AZURE_STORAGE_ACCESS_KEY
Azure Data Lake Storage的Access key。
lx8z****
OSS_TARGET_LOCATION
AnalyticDB for MySQL中Delta Lake表数据的存储路径。
oss://testBucketName/db_test_migration/
OSS_JAR_ROOT_LOCATION
准备工作中下载的访问Azure Databricks依赖的Jar包所在的OSS目录路径。
oss://testBucketName/jars/
MAX_ROWS_COUNT
迁移过程中读取数据的最大行数。默认情况下为10000。如果您希望迁移更大数据量,建议先将EIP带宽调至200 MB以上(导入效率和带宽相关)。
10000
单击全部运行,顺序执行该文件。
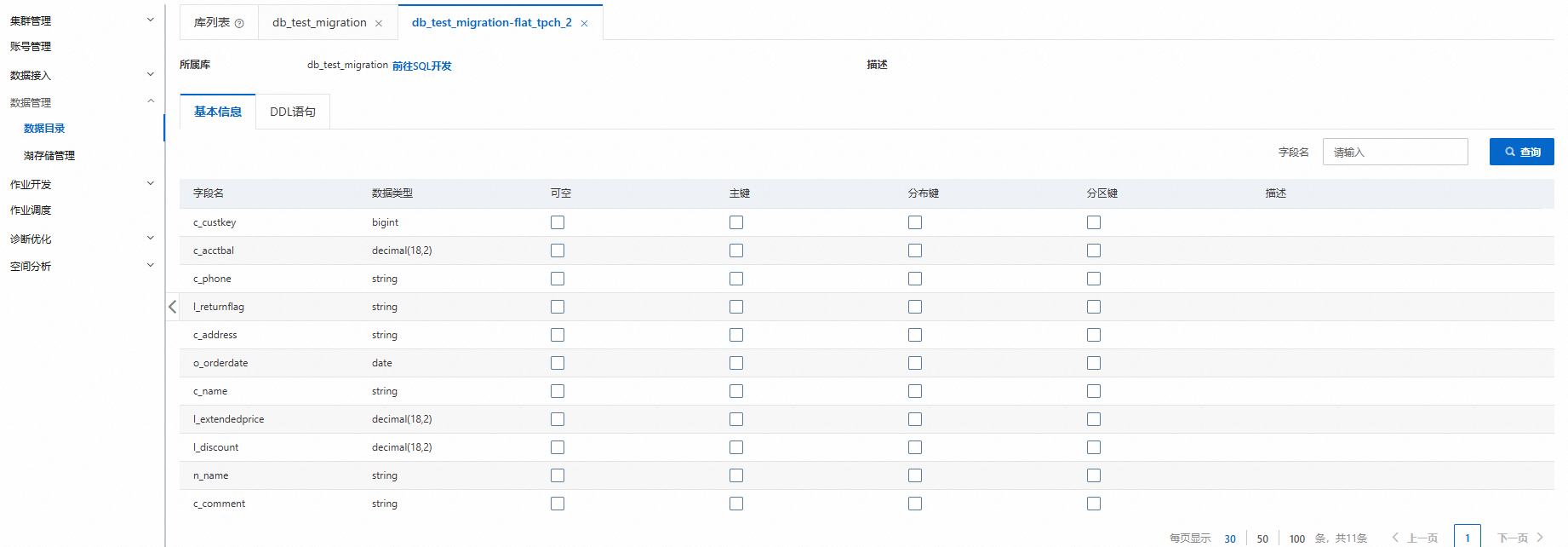
预览目录。
数据迁移完成后,您可以在AnalyticDB for MySQL集群中查看迁移后的数据库和表。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏,单击。
单击目标数据库和表,查看表的详细信息,例如:表类型、表存储数据量、列名等。