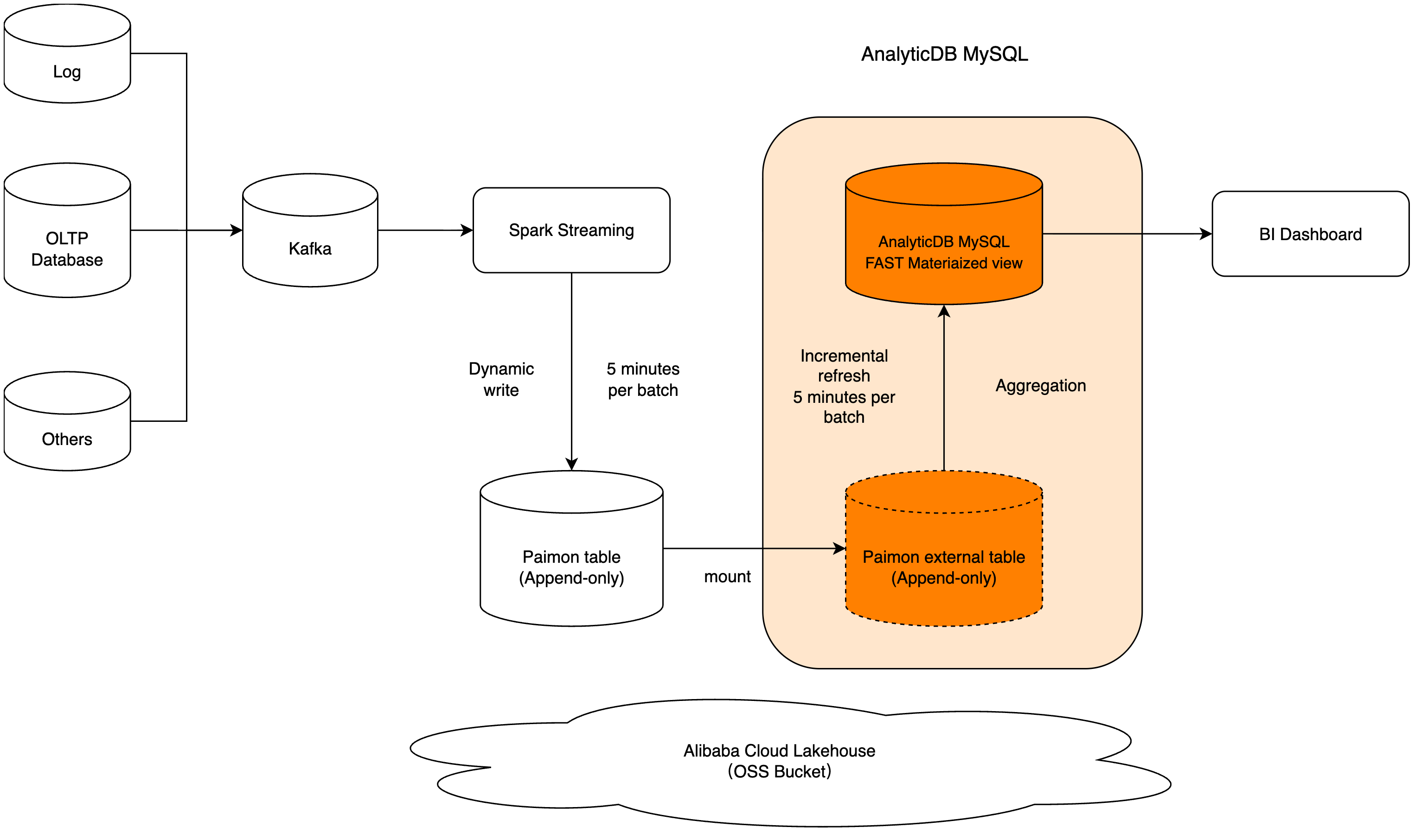
物化视图加速Paimon数据湖分析
AnalyticDB MySQL可以通过物化视图直接分析存储在OSS上的Paimon数据湖表。
背景与挑战
云原生数据仓库 AnalyticDB MySQL 版支持直接分析存储在 OSS 上的 Paimon 数据湖表,无需数据导入。然而,在实际业务中,高频访问的高价值数据集(如广告点击、用户行为日志)常以 Paimon 表形式存于数据湖。若每次查询都直接扫描原始 Paimon 文件,性能难以满足交互式分析需求。传统做法与弊端:
用 Spark 预处理数据 → 生成 Parquet → 导入 MPP 数仓
架构复杂、延迟高、运维成本大
本文提供一种更高效的方案:在 AnalyticDB for MySQL中构建增量物化视图(Incremental Materialized View),实现:
零数据迁移:直接基于 Paimon 表创建物化视图。
自动增量刷新:仅处理新增/变更数据,降低计算开销。
查询加速:物化视图基于列存引擎(XUANWU_V2),查询性能远超直接访问 Paimon。
前提条件
集群的内核需为3.2.6及以上版本。版本升级请联系阿里云服务支持处理(钉钉账号:
x5v_rm8wqzuqf)。说明请在云原生数据仓库AnalyticDB MySQL控制台集群信息页面的配置信息区域,查看和升级内核版本。
OSS bucket与集群位于同一地域。
构建Paimon数据湖表
步骤一:使用SparkSQL创建Paimon表
仅 Paimon的append only(无主键)表能构建增量物化视图。
如已有Paimon表,必须是使用
filesystem或Hive catalog管理元数据。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
左侧导航栏选择,创建Spark引擎的Interactive类型资源组。
新增以下Spark配置,将
spark.sql.catalog.paimon.warehouse替换为实际OSS路径,路径需与后续外表配置一致。spark.sql.catalog.paimon org.apache.paimon.spark.SparkCatalog; spark.sql.catalog.paimon.warehouse oss://your-bucket/paimon-warehouse; spark.sql.extensions org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions;创建完成后,在左侧导航栏选择,在SQLConsole中,选择Spark和上一步创建的Interactive类型资源组。
-- 创建数据库与表 USE paimon.default; CREATE DATABASE IF NOT EXISTS paimon_db; USE paimon_db; DROP TABLE IF EXISTS user_event_log; CREATE TABLE user_event_log ( day STRING, hour STRING, event_time STRING, city STRING, account_id STRING, ad_id STRING, event_count INT, event_name STRING ) USING paimon PARTITIONED BY (day, hour) TBLPROPERTIES ( 'execution.checkpointing.timeout' = '60 min', 'file.compression' = 'ZSTD', 'file.format' = 'Parquet', 'num-sorted-run.stop-trigger' = '2147483647', 'snapshot.time-retained' = '2 h', 'sort-spill-threshold' = '10', 'spill-compression' = 'ZSTD', 'write-buffer-size' = '1536 mb', 'write-buffer-spillable' = 'true' );重要创建后需要在OSS文件中查看,会出现对应的
.db文件。
步骤二:模拟数据持续写入
创建一个
.py脚本文件。根据实际路径修改
warehouse配置,以及spark.sql中插入语句的库表名。# 每分钟写入1w条数据 from pyspark.sql import SparkSession from pyspark.sql.functions import ( col, lit, rand, round, concat, when, array, current_timestamp, date_format, current_date, expr, floor ) import datetime import time # 初始化 SparkSession spark = SparkSession.builder \ .appName("Generate Mock Data for paimon_base_table") \ .config("spark.adb.version", "3.5") \ .config("spark.sql.extensions", "org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions") \ .config("spark.sql.catalog.paimon", "org.apache.paimon.spark.SparkCatalog") \ .config("spark.sql.catalog.paimon.warehouse", "oss://your-bucket/paimon-warehouse") \ .getOrCreate() # 10次数据写入,每次写入1w行 for i in range(10): print(f"开始第 {i + 1} 次数据写入") time_offset_expr = expr("current_timestamp() - interval 1 minutes") # 构造随机数据的 DataFrame # range(0, 10000)表示生成1w行 mock_data = spark.range(0, 10000).select( lit(date_format(current_date(), "yyyy-MM-dd")).alias("day"), lit(date_format(current_timestamp(), "HH")).alias("hour"), time_offset_expr.alias("event_time"), array(lit("HZ"), lit("SH"))[floor(rand() * 2)].alias("city"), concat(lit("acct_"), floor(rand() * 25)).alias("account_id"), concat(lit("ad_"), floor(rand() * 25)).alias("ad_id"), floor(rand() * 1000).alias("event_count"), lit(400 + floor(rand() * 101)).alias("event_name") ) # 注册临时表 mock_data.createOrReplaceTempView("temp_mock_data") # 执行插入操作 spark.sql("INSERT INTO paimon.paimon_db.user_event_log SELECT * FROM temp_mock_data") time.sleep(60)可以使用notebook运行上面的脚本代码。如果使用Spark Jar开发提交该脚本,请继续以下步骤的操作。
将脚本上传至OSS,详情请参见简单上传。
从Maven仓库中下载 paimon-spark JAR包,上传至OSS。
在左侧导航栏选择,选择Spark引擎的Job类型资源组,Batch模式运行以下作业。
根据实际情况替换对应的
file和jars的路径地址。{ "name": "Spark Python Test", "file": "oss://your-bucket/paimon-warehouse/write_auto.py", "jars": ["oss://your-bucket/paimon-warehouse/paimon-spark-3.5-1.1.0.jar"], "conf": { "spark.driver.resourceSpec": "large", "spark.executor.instances": 2, "spark.executor.resourceSpec": "large", "spark.adb.version": "3.5" } }运行脚本写入数据需要一定时间,可以继续进行下面的步骤。
基于Paimon表构建物化视图
AnalyticDB for MySQL需通过外部表映射 Paimon 数据。
创建外部数据库
在左侧导航栏选择,在SQLConsole中,选择XIHE引擎的Interactive类型资源组。
外部数据库名必须与 Spark 中创建的库名一致(如 paimon_db)。
location路径格式为:oss://<bucket>/<warehouse>/<db_name>.db/。
CREATE EXTERNAL DATABASE IF NOT EXISTS paimon_db WITH DBPROPERTIES ( catalog = 'paimon', adb.paimon.warehouse = 'oss://your-bucket/paimon-warehouse/', location = 'oss://your-bucket/paimon-warehouse/paimon_db.db/' );创建外部表
USE paimon_db; -- 创建外表 DROP TABLE IF EXISTS user_event_log; CREATE TABLE user_event_log ( `day` STRING, `hour` STRING, event_time STRING, city STRING, account_id STRING, ad_id STRING, event_count INT, event_name STRING ) STORED AS paimon LOCATION 'oss://your-bucket/paimon-warehouse/paimon_db.db/user_event_log/';验证查询一致性
本文提供了三种常见的查询场景,可以验证Query语义一致的情况,查询结果一致,且性能更优。
注意查询条件变更,脚本生成数据的日期是运行当日的本地时间。
单表聚合查询
SELECT coalesce(`day`, '') AS `day`, coalesce(account_id, '') AS account_id, coalesce(event_time, '') AS event_time, coalesce(city, '') AS city, coalesce(ad_id, '') AS ad_id, SUM(CASE WHEN event_name = '401' THEN event_count ELSE 0 END) AS count_401, SUM(CASE WHEN event_name = '402' THEN event_count ELSE 0 END) AS count_402, SUM(CASE WHEN event_name = '403' THEN event_count ELSE 0 END) AS count_403, SUM(CASE WHEN event_name = '404' THEN event_count ELSE 0 END) AS count_404, SUM(CASE WHEN event_name = '405' THEN event_count ELSE 0 END) AS count_405, SUM(CASE WHEN event_name = '406' THEN event_count ELSE 0 END) AS count_406, SUM(CASE WHEN event_name = '407' THEN event_count ELSE 0 END) AS count_407, SUM(CASE WHEN event_name = '408' THEN event_count ELSE 0 END) AS count_408, SUM(CASE WHEN event_name = '409' THEN event_count ELSE 0 END) AS count_409, SUM(CASE WHEN event_name = '410' THEN event_count ELSE 0 END) AS count_410 FROM user_event_log WHERE day='2025-10-30' GROUP BY 1,2,3,4,5 LIMIT 1000;Top N排序查询
SELECT coalesce(`day`, '') AS `day`, coalesce(account_id, '') AS account_id, coalesce(event_time, '') AS event_time, coalesce(city, '') AS city, coalesce(ad_id, '') AS ad_id, SUM(CASE WHEN event_name = '401' THEN event_count ELSE 0 END) AS count_401, SUM(CASE WHEN event_name = '402' THEN event_count ELSE 0 END) AS count_402, SUM(CASE WHEN event_name = '403' THEN event_count ELSE 0 END) AS count_403, SUM(CASE WHEN event_name = '404' THEN event_count ELSE 0 END) AS count_404, SUM(CASE WHEN event_name = '405' THEN event_count ELSE 0 END) AS count_405, SUM(CASE WHEN event_name = '406' THEN event_count ELSE 0 END) AS count_406, SUM(CASE WHEN event_name = '407' THEN event_count ELSE 0 END) AS count_407, SUM(CASE WHEN event_name = '408' THEN event_count ELSE 0 END) AS count_408, SUM(CASE WHEN event_name = '409' THEN event_count ELSE 0 END) AS count_409, SUM(CASE WHEN event_name = '410' THEN event_count ELSE 0 END) AS count_410 FROM user_event_log WHERE day='2025-10-30' GROUP BY 1,2,3,4,5 ORDER BY 1,2,3,4,5 limit 1000000;多filter圈选
SELECT coalesce(`day`, '') AS `day`, coalesce(account_id, '') AS account_id, coalesce(event_time, '') AS event_time, coalesce(city, '') AS city, coalesce(ad_id, '') AS ad_id, SUM(CASE WHEN event_name = '401' THEN event_count ELSE 0 END) AS count_401, SUM(CASE WHEN event_name = '402' THEN event_count ELSE 0 END) AS count_402, SUM(CASE WHEN event_name = '403' THEN event_count ELSE 0 END) AS count_403, SUM(CASE WHEN event_name = '404' THEN event_count ELSE 0 END) AS count_404, SUM(CASE WHEN event_name = '405' THEN event_count ELSE 0 END) AS count_405, SUM(CASE WHEN event_name = '406' THEN event_count ELSE 0 END) AS count_406, SUM(CASE WHEN event_name = '407' THEN event_count ELSE 0 END) AS count_407, SUM(CASE WHEN event_name = '408' THEN event_count ELSE 0 END) AS count_408, SUM(CASE WHEN event_name = '409' THEN event_count ELSE 0 END) AS count_409, SUM(CASE WHEN event_name = '410' THEN event_count ELSE 0 END) AS count_410 FROM user_event_log WHERE day='2025-10-30' and account_id = 'acct_3' and ad_id = 'ad_15' GROUP BY 1,2,3,4,5 ORDER BY 1,2,3,4,5
构建增量物化视图(核心加速方案)
创建资源组。
左侧导航栏选择,新增资源组。
说明需要选择Xihe引擎,使用Interactive类型资源组,规格 256 ACU,用于运行刷新任务。
启用增量刷新能力。
返回SQL开发,选择使用新增的资源组,启用增量刷新。
set adb_config O_MV_IVM_V2_ENABLED = true; set adb_config MV_FAST_REFRESH_PLAN_CACHE_ENABLED=false;创建物化视图
创建原生数据库
create database paimon_mv;在左侧数据库目录刷新后,选择创建好的
paimon_mv库。CREATE MATERIALIZED VIEW paimon_test_view ( PRIMARY KEY ( `day`, account_id, event_time, city, ad_id ) ) INDEX_ALL='N' ENGINE='XUANWU_V2' COMPRESSION='lz4' TABLE_PROPERTIES='{"format":"columnstore"}' -- define your interactive resource group name in MV_PROPERTIES MV_PROPERTIES='{"mv_resource_group":"paimon_refresh"}' -- 表示此物化表会在创建后每五分钟增量刷新一次。 REFRESH FAST NEXT now() + interval 5 minute AS SELECT coalesce(`day`, '') AS `day`, coalesce(account_id, '') AS account_id, coalesce(event_time, '') AS event_time, coalesce(city, '') AS city, coalesce(ad_id, '') AS ad_id, SUM(CASE WHEN event_name = '401' THEN event_count ELSE 0 END) AS count_401, SUM(CASE WHEN event_name = '402' THEN event_count ELSE 0 END) AS count_402, SUM(CASE WHEN event_name = '403' THEN event_count ELSE 0 END) AS count_403, SUM(CASE WHEN event_name = '404' THEN event_count ELSE 0 END) AS count_404, SUM(CASE WHEN event_name = '405' THEN event_count ELSE 0 END) AS count_405, SUM(CASE WHEN event_name = '406' THEN event_count ELSE 0 END) AS count_406, SUM(CASE WHEN event_name = '407' THEN event_count ELSE 0 END) AS count_407, SUM(CASE WHEN event_name = '408' THEN event_count ELSE 0 END) AS count_408, SUM(CASE WHEN event_name = '409' THEN event_count ELSE 0 END) AS count_409, SUM(CASE WHEN event_name = '410' THEN event_count ELSE 0 END) AS count_410 FROM paimon_db.user_event_log GROUP BY 1,2,3,4,5;
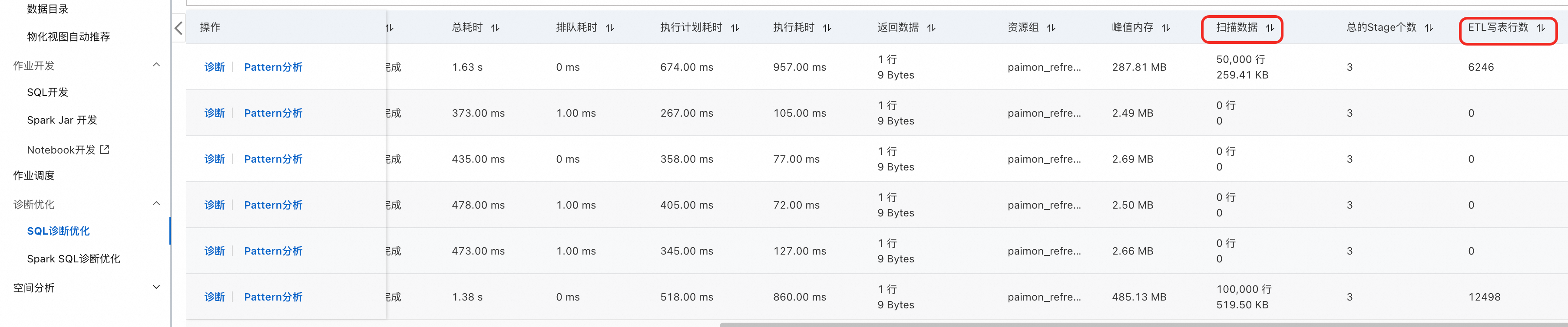
监控物化视图刷新状态。
-- 获取最新刷新任务的 process_id SELECT process_id FROM INFORMATION_SCHEMA.mv_auto_refresh_jobs WHERE mv_name = 'user_event_mv' AND mv_schema = 'paimon_mv' ORDER BY job_id DESC LIMIT 1;将
process_id输入控制台 SQL 诊断优化页面,可查看扫描数据,ETL写表行数,以此判断增量物化视图的刷新吞吐。