
小查询并发优化
本文介绍 AnalyticDB for MySQLAuto-Scaling 资源组中的小查询并发优化机制。该机制旨在降低小查询的端到端延迟,减少资源占用,从而提升集群的整体吞吐能力与资源利用率。所有优化均由系统自动识别并生效,您无需修改 SQL 或进行任何配置。
背景信息
Auto-Scaling 资源组默认采用资源隔离与分布式执行机制:查询执行前按需申请资源配额,执行时拆分为多个 Stage 通过多节点协同完成计算,以此保证执行稳定性与性能。然而对于小查询而言,默认机制收益有限,反而会引入额外负担:
资源利用率低:小查询实际计算消耗远低于资源配额的最小分配单元。
固定开销占比过高:资源申请流程与分布式调度带来的固定开销可能超过查询本身的计算消耗。
为此,Auto-Scaling 资源组会自动识别此类查询,为其提供轻量级的执行路径,在确保集群稳定性的前提下显著降低延迟并提升吞吐。识别为小查询后,系统从以下三个维度进行专项优化:
单机执行计划:消除分布式调度开销以及节点间 Shuffle 开销。
独立执行队列与调度:小查询进入专属队列,与常规查询完全分离,无需经过资源评估与申请流程。
自适应限流:动态控制小查询并发水位,在防止资源争抢的同时最大化并发能力。
适用场景
小查询的核心特征是源头扫描数据量极小,常见于以下场景:
主键/唯一键点查:通过高选择性过滤条件精确定位少量行,如按用户 ID、订单 ID 查询明细。
TopN 查询:对有序数据取前 N 条,配合索引或分区裁剪后实际扫描量极少。
小表关联:关联表本身数据量很小,Join 后的中间结果集同样极小。
聚合维度查询:基于高选择性条件过滤后再聚合,如查询某个用户近 N 天的消费统计。
系统通过一组内部规则来判断是否对某个查询启用优化,综合考量以下因素:
优化器预估扫描量
查询结构复杂度
SQL Pattern 历史执行统计信息(包括执行时间、峰值内存等)
系统优先保证小查询识别准确率,在此基础上持续提升召回率。模型随每次查询执行持续学习并做自我修正,当查询特征发生显著变化(如数据量大幅增减)时,模型能够快速感知并及时响应。
您也可以通过 Hint配置query_profile=short 强制查询走小查询优化路径,并通过 Persist Plan持久化配置。但此方式存在风险,不建议手动配置。
单机执行计划
优化原理
大多数场景下分布式执行能带来更高的性能,查询被拆分为多个 Stage 在多个节点间通过 Shuffle 交换数据。但分布式执行也额外带来:
网络与序列化开销:节点间数据传输涉及序列化、反序列化以及网络 RPC 调用。
调度协调成本:多节点协同需要 Coordinator 做任务分发、状态收集,增加端到端延迟。
节点长尾风险:任一节点异常都会影响整体进度,受“木桶效应”制约。
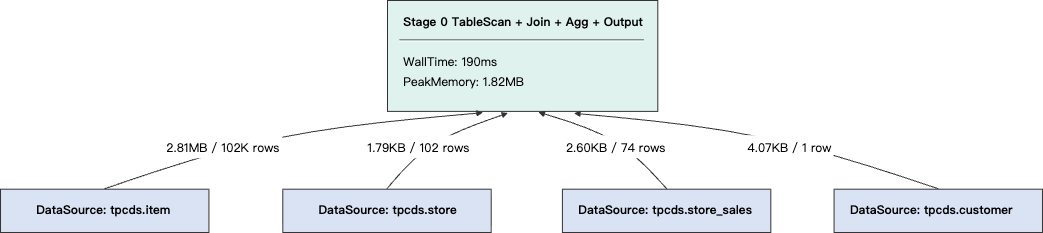
对于小查询而言,处理的数据量极小,并行计算收益有限,上述开销反而可能远超实际计算耗时。为此,系统在识别到小查询后,会将执行计划收敛为单机计划,在单个节点上完成所有计算,从根本上消除分布式开销。
典型示例
以下查询涉及多表 Join 与多维度聚合,但由于过滤条件极具选择性,实际扫描数据量极小,是单机执行的典型受益场景。
SELECT
s.s_store_name,
CAST(COALESCE(SUM(CASE WHEN i.i_current_price > 100 THEN 1 ELSE 0 END), 0) AS BIGINT) AS dx_expensive_items_cnt,
CAST(COALESCE(MIN(CASE WHEN i.i_current_price > 100 THEN DATEDIFF(CURRENT_DATE, ss.ss_sold_date_sk) END), -99) AS BIGINT) AS dx_expensive_items_diff_days_min,
CAST(COALESCE(COUNT(DISTINCT CASE WHEN i.i_current_price > 100 THEN i.i_category END), 0) AS BIGINT) AS dx_expensive_items_categories,
CAST(COALESCE(SUM(CASE WHEN i.i_current_price > 100 AND DATEDIFF(CURRENT_DATE, ss.ss_sold_date_sk) < 14 THEN ss.ss_sales_price ELSE 0 END), 0) AS BIGINT) AS dx_expensive_items_14d_cnt,
CAST(COALESCE(SUM(CASE WHEN i.i_current_price > 100 AND DATEDIFF(CURRENT_DATE, ss.ss_sold_date_sk) < 30 THEN ss.ss_sales_price ELSE 0 END), 0) AS BIGINT) AS dx_expensive_items_30d_cnt,
CAST(COALESCE(SUM(CASE WHEN i.i_current_price > 100 AND DATEDIFF(CURRENT_DATE, ss.ss_sold_date_sk) < 60 THEN ss.ss_sales_price ELSE 0 END), 0) AS BIGINT) AS dx_expensive_items_60d_cnt,
CAST(COALESCE(SUM(CASE WHEN i.i_current_price > 100 AND DATEDIFF(CURRENT_DATE, ss.ss_sold_date_sk) < 90 THEN ss.ss_sales_price ELSE 0 END), 0) AS BIGINT) AS dx_expensive_items_90d_cnt,
c.c_customer_sk AS dx_expensive_group_rptid
FROM store_sales ss
JOIN item i ON ss.ss_item_sk = i.i_item_sk
JOIN customer c ON ss.ss_customer_sk = c.c_customer_sk
JOIN store s ON ss.ss_store_sk = s.s_store_sk
WHERE c.c_customer_sk = 10001
GROUP BY
s.s_store_name,
c.c_customer_sk
LIMIT 1;优化前:查询被切分为 6 个 Stage 分布式执行。
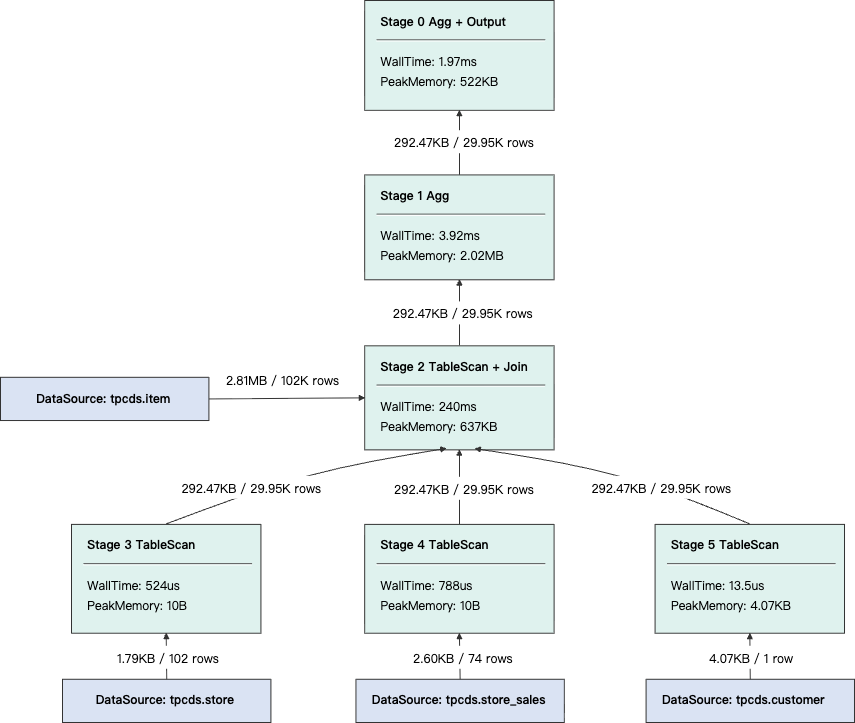
优化后:仅包含 1 个 Stage 单机执行,无数据 Shuffle。
实测效果
基于 96 ACU 集群规格,在不同并发下对比开关单机执行计划的性能表现:
并发数 | 指标 | 关闭单机计划 | 开启单机计划 | 收益 |
20 | 查询平均 RT(ms) | 137 | 116 | 15.17% |
QPS | 145 | 171 | 17.89% | |
CPU 消耗 P95 | 89% | 59% | 33.7% | |
50 | 查询平均 RT(ms) | 330 | 228 | 30.98% |
QPS | 150 | 218 | 44.9% | |
CPU 消耗 P95 | 93% | 76% | 18.27% | |
100 | 查询平均 RT(ms) | 708 | 464 | 34.47% |
QPS | 140 | 214 | 52.56% | |
CPU 消耗 P95 | 94% | 86% | 8.51% | |
200 | 查询平均 RT(ms) | 1559 | 967 | 37.94% |
QPS | 128 | 205 | 60.46% | |
CPU 消耗 P95 | 95% | 87% | 8.42% |
独立执行队列与调度
Auto-Scaling 资源组中的常规查询均采用严格的资源隔离机制:查询执行前按需申请资源配额,当资源组没有空闲配额时后续查询需排队等待。对于小查询而言,排队等待的时间不可忽略,固定的资源配额也限制了集群的整体并发能力。
为此,小查询优化引入了独立的执行队列与调度链路。识别为小查询的任务无需经过资源评估与申请流程,直接进入专属队列,由系统将其分发至合适的节点执行,充分利用集群的资源空隙。
系统综合考量各候选节点的实时状态,动态选择最优执行节点。主要调度策略包括:
健康节点过滤:排除资源水位过高或状态异常(如近期发生过 Full GC)的节点,确保查询只被调度到稳定可用的节点。
多维负载评估:综合物理资源水位(CPU、内存、网络)、资源配额使用情况及业务负载指标对节点进行评估,同时引入热点惩罚,避免查询过度集中于同一节点。
智能路由探索:在高优节点中引入适度随机性,有效缓解监控指标更新延迟带来的调度偏差。
最小并发保障:内置兜底调度机制,极端场景下仍可保障最低并发水位的小查询立即执行。
通过这种轻量级的调度方式,小查询可以灵活利用集群中的碎片化资源,无需等待资源配额即可快速执行,在显著提升资源利用率的同时,有效保障了高并发场景下的整体吞吐能力。
自适应限流
原理
独立执行队列让小查询绕开了常规的资源配额管控,但若不加以控制,大量小查询同时涌入同一节点可能造成资源争抢,甚至导致节点过载。
为此,系统在 Coordinator 侧为每个计算节点维护一套轻量的资源配额机制,专门用于管控小查询的执行负载。每条小查询在调度前需先向目标节点申请配额,若当前所有节点均无空闲配额,调度请求将短暂等待后重试,同时 Executor Control Service 会基于查询队列深度做扩缩容决策。更多信息,请参见Auto-Scaling弹性策略。
每个节点的配额上限并非固定不变,系统基于节点当前的查询延迟与吞吐水平动态调整:
异常熔断保护:节点过载或持续异常时触发熔断,降低配额上限并暂停调度,恢复后重新接入。
慢节点自动降级:节点响应延迟显著高于集群平均水平时,降低配额上限并将流量调度至健康节点。
稳态探测:稳定节点试探性提升配额上限,在确保执行性能不劣化的前提下最大化资源利用。
弹性收缩:流量降低时自动收缩配额至安全水位,避免突发流量导致节点瞬间过载。
配额上限的调节范围有明确的上下边界,防止在极端情况下过度收紧或放开。整个过程完全自动,无需人工干预,每次调节后会有一段冷静期。
实测效果
基于 96 ACU 规格,关闭单机执行计划策略以充分模拟资源争抢场景,测试SQL如单机执行计划章节所示,在不同并发下对比开关自适应限流的集群性能表现:
无限流:性能呈先升后降趋势,高并发引发节点过载,导致延迟飙升且吞吐量断崖式下跌。
自适应限流:性能持续上升并企稳,通过动态调控成功抵御压力,在高负载下仍保持高吞吐,端到端延迟线性增长主要是排队带来的额外开销。
并发数 | 指标 | 无限流 | 自适应限流 | 收益 |
20 | 查询平均 RT(ms) | 140 | 111 | 20.93% |
QPS | 141 | 179 | 26.45% | |
50 | 查询平均 RT(ms) | 303 | 214 | 29.38% |
QPS | 164 | 232 | 41.55% | |
100 | 查询平均 RT(ms) | 1029 | 426 | 58.59% |
QPS | 96 | 233 | 141.75% | |
200 | 查询平均 RT(ms) | 2897 | 848 | 70.72% |
QPS | 67 | 235 | 248.32% |