基于Notebook+PySpark+Lance实现高效图文混存
本文介绍如何采用Notebook与PySpark对存储在OSS中的多模态数据进行预处理,以满足构建VLM模型(Vision-Language Model,视觉语言模型)或MLLM模型(Multimodal Large Language Model,多模态大语言模型)所需的数据要求。
背景信息
在大模型的发展进程中,多模态能力的构建与多模态训练数据的应用是至关重要的技术方向。在多模态场景下,图文混存是一种较为常见的存储方式,一般通过分布式计算框架(如Spark)执行相关计算任务。通过合理且高效的训练数据方案,可以确保模型在多样化的多模态数据上进行有效学习,从而提升模型的泛化能力和性能表现。
方案优势
基于DMS Notebook+ADB Spark丰富的生态库,可以快速开发、调试任务。
多模态数据统一存储为Lance格式,并在数据湖中进行统一管理(包括生命周期、权限等方面)。
基于Lance格式提供高性能的点查能力,使得模型训练和数据预处理场景更加高效。在演示场景中,Lance格式的性能相较于Parquet格式提升约3~4倍。
Lance Format将图像与数据混合存储有以下优势:
数据的完整性与一致性:图片及其关联数据(如元信息、标注等)存储在同一文件中,避免因文件分散而导致丢失或匹配错误,便于整体管理和迁移。
读取效率提升:无需同时读取多个文件,减少了IO操作和路径查找所需的时间。适用于批量处理大量图像与数据的场景,例如机器学习数据集。
简化数据管理:单一文件即可涵盖所有相关信息,无需维护复杂的文件索引或目录结构,从而降低管理成本,适用于协作场景。
兼容性与可移植性:采用单一文件格式,有助于在不同系统或平台之间进行传输,从而避免因依赖外部路径而引发的兼容性问题。
安全与权限控制:可以对整个文件进行统一加密或权限设置,以防止图像和数据的拆分与篡改,从而提升数据的安全性。
方案流程

准备工作
部署资源
AnalyticDB for MySQL集群的产品系列为企业版、基础版或湖仓版。
创建数据库账号。
如果是通过阿里云账号访问,只需创建高权限账号。
如果是通过RAM用户访问,需要创建高权限账号和普通账号、授予普通账号相应的库表权限并将RAM用户绑定到普通账号上。
已配置Spark应用的日志存储地址。
登录云原生数据仓库AnalyticDB MySQL控制台,在页面,单击日志配置,选择默认路径或自定义存储路径。自定义存储路径时不能将日志保存在OSS的根目录下,请确保该路径中至少包含一层文件夹。
如果您需要使用RAM用户登录控制台进行Spark作业开发,需要完成为RAM用户授权。
准备示例数据及Jar包
随机选择三张图片,将图片命名为
image1.jpg、image2.jpg、image3.jpg并将其上传至OSS中。准备
testdata.json文件,并将其上传至OSS中。[ { "docid": "doc_001", "text": "This is a prompt for image processing.", "image_id1": "image1", "image_id2": "image2" }, { "docid": "doc_002", "text": "Another prompt with image references.", "image_id1": "image3", "image_id2": "image1" }, { "docid": "doc_003", "text": "Interesting dialogue about images.", "image_id1": "image2", "image_id2": "image1", "image_id3": "image3" } ]下载lance-spark-bundle-3.5_2.12-0.0.1.jar包,并将其上传至OSS中。
操作步骤
步骤一:进入Notebook开发页面
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。

步骤二:创建Notebook文件
创建Spark集群。
单击
 按钮,进入资源管理页面,单击计算集群。
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:

参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
目前支持选择如下镜像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
依赖的Jars
Jar包的OSS存储路径。此处需要填写准备工作中下载的Jar包所属的OSS路径。
oss://testBucketName/adb/lance-spark-bundle-3.5_2.12-0.0.1.jar
创建并启动Notebook会话。
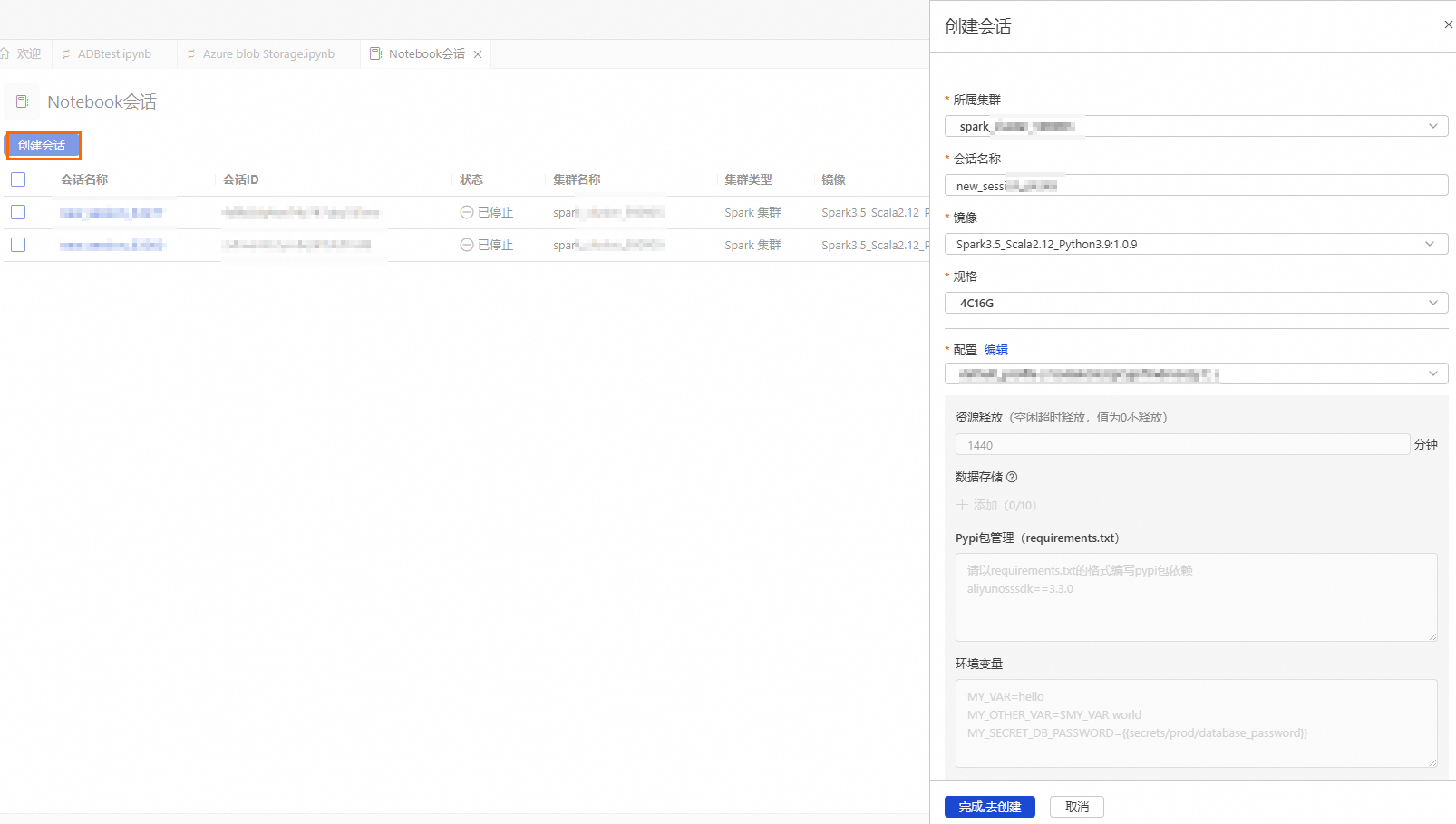
参数
说明
示例值
所属集群
选择步骤b创建的Spark集群。
spark_test
会话名称
您可自定义会话名称。
new_session
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9
Spark3.3_Scala2.12_Python3.9:1.0.9
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
Driver的资源规格。
1核4 GB
2核8 GB
4核16 GB
8核32 GB
16核64 GB
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
deault_profile
单击
 按钮,然后单击。
按钮,然后单击。
步骤三:将图片与文本数据导入Lance
将Cell的语言类型设置为Python,执行以下代码,下载Python依赖。
!pip install pyarrow==19.0.1 !pip install pylance==0.23.2 !pip install oss2==2.19.1 !pip install pandas==2.2.3 !pip install torch==2.7.0 !pip install torchvision==0.22.0 !pip install pillow==11.2.1将Cell的语言类型设置为Python,替换以下代码中的相关配置参数并执行,将图片数据导入Lance。
import os import oss2 import pandas as pd import pyarrow as pa import lance # Bucket名称 bucket_name = 'testBucketName' # Bucket的Endpoint endpoint = 'oss-cn-hangzhou-internal.aliyuncs.com' # 阿里云账号或者具备OSS访问权限的RAM用户的AccessKey ID和AccessKey Secret auth = oss2.Auth('AK', 'SK') bucket = oss2.Bucket(auth, endpoint, bucket_name) # 图片数据存放的目录前缀 prefix = 'lanceData/' storage_options = { # Bucket所属地域 "region": "cn-hangzhou", # Bucket的Endpoint "endpoint": "https://testBucketName.oss-cn-hangzhou-internal.aliyuncs.com", # 阿里云账号或者具备OSS访问权限的RAM用户的AccessKey ID和AccessKey Secret "access_key_id": "ak", "secret_access_key": "sk", "virtual_hosted_style_request": "True" } data = [] for obj in oss2.ObjectIterator(bucket, prefix=prefix): if obj.key.endswith(('.png', '.jpg', '.jpeg')): image_id = os.path.splitext(os.path.basename(obj.key))[0] img_binary = bucket.get_object(obj.key).read() data.append({'image_id': image_id, 'image_data': img_binary}) df = pd.DataFrame(data) schema = pa.schema([pa.field("image_id", pa.string()), pa.field("image_data", pa.binary())]) table = pa.Table.from_pandas(df, schema=schema) # 图片Lance数据存放的OSS路径,协议需为s3 uri = "s3://testBucketName/lance_data/lance_image_dataset.lance" lance.write_dataset(table, uri, storage_options=storage_options) ds = lance.dataset(uri, storage_options=storage_options)将Cell的语言类型设置为Python,替换以下代码中的相关配置参数并执行,将文本数据导入Lance。
import pandas as pd import pyarrow as pa import lance import fsspec import json import oss2 import json storage_options = { # Bucket所属地域 "region": "cn-hangzhou", # Bucket的Endpoint "endpoint": "https://testBucketName.oss-cn-hangzhou-internal.aliyuncs.com", # 阿里云账号或者具备OSS访问权限的RAM用户的AccessKey ID和AccessKey Secret "access_key_id": "AK", "secret_access_key": "SK", "virtual_hosted_style_request": "True" } # 初始化认证信息 auth = oss2.Auth('AK', 'SK') bucket = oss2.Bucket( auth, 'https://oss-cn-hangzhou-internal.aliyuncs.com', 'testBucketName' # Bucket名称 ) # 取文件内容 obj = bucket.get_object('Lance/data/testdata.json') text_data = json.load(obj) # 2. 构造DataFrame并后续数据处理 schema = pa.schema([ pa.field("docid", pa.string()), pa.field("text", pa.string()), pa.field("image_id1", pa.string()), pa.field("image_id2", pa.string()), pa.field("image_id3", pa.string()) ]) df = pd.DataFrame(text_data) table = pa.Table.from_pandas(df, schema=schema) # 文本Lance数据存放的OSS路径,协议需为s3 uri = "s3://testBucketName/Lance/lance_text_dataset.lance" lance.write_dataset(table, uri, storage_options=storage_options) ds = lance.dataset(uri, storage_options=storage_options) print(ds.to_table().to_pandas())
步骤四:将图片与文本数据混合存储
将Cell的语言类型设置为Python,替换以下代码中的相关配置参数并执行,将图片与文本数据关联整合,存储为同时包含图片与文本的综合数据集。
from pyspark.sql.dataframe import DataFrame from pyspark.sql import SparkSession, DataFrame from pyspark.sql import functions as F from pyspark.sql.types import StringType import lance import json storage_options = { # Bucket所属地域 "region": "cn-hangzhou", # Bucket的Endpoint "endpoint": "https://testBucketName.oss-cn-hangzhou-internal.aliyuncs.com", # 阿里云账号或者具备OSS访问权限的RAM用户的AccessKey ID和AccessKey Secret "access_key_id": "ak", "secret_access_key": "sk", "virtual_hosted_style_request": "True" } class VisionDataProcessor: def __init__(self, app_name="Lance Vision Data Join and Format Example"): self.spark = SparkSession.builder.config("spark.driver.memory", "32g") \ .config("spark.sql.catalog.lance","com.lancedb.lance.spark.LanceCatalog") \ .config("spark.sql.catalog.lance.aws_region","cn-hangzhou") \ # Bucket的Endpoint .config("spark.sql.catalog.lance.aws_endpoint","https://testBucketName.oss-cn-hangzhou-internal.aliyuncs.com") \ # 阿里云账号或者具备OSS访问权限的RAM用户的AccessKey ID和AccessKey Secret .config("spark.sql.catalog.lance.access_key_id","ak") \ .config("spark.sql.catalog.lance.secret_access_key","sk") \ .config("spark.sql.catalog.lance.virtual_hosted_style_request","True") \ .config("spark.driver.cores", "8").config("spark.rpc.message.maxSize","1024").appName(app_name).getOrCreate() def get_lance_dataset(self, uri) -> DataFrame: # 读取 Lance 数据集 data = spark.read \ .format("lance") \ .load(uri) return data def join_vision_data(self) -> DataFrame: # 图片Lance数据和文本Lance数据存放的OSS路径,协议需为s3 df_text = self.get_lance_dataset(uri='s3://testBucketName/lance_data/lance_text_dataset.lance') df_image = self.get_lance_dataset('s3://testBucketName/lance_data/lance_image_dataset.lance') df_text = df_text.join( df_image.select(F.col("image_id").alias("image_id1"), F.col("image_data")), on="image_id1", how="left" ).withColumnRenamed("image_data", "image1_byte") df_text = df_text.join( df_image.select(F.col("image_id").alias("image_id2"), F.col("image_data")), on="image_id2", how="left" ).withColumnRenamed("image_data", "image2_byte") df_text = df_text.join( df_image.select(F.col("image_id").alias("image_id3"), F.col("image_data")), on="image_id3", how="left" ).withColumnRenamed("image_data", "image3_byte") vision_df = df_text.select( "docid", "text", F.col("image1_byte").alias("image1"), F.col("image2_byte").alias("image2"), F.col("image3_byte").alias("image3") ) return vision_df def format_to_training_data(self, df: DataFrame) -> DataFrame: def format_prompt(text, image1, image2, image3): images = [image.hex() for image in (image1, image2, image3) if image] alpaca_format = {"instruction": text, "input": images, "output": ""} return json.dumps(alpaca_format) format_prompt_udf = F.udf(format_prompt, StringType()) result_str = df.withColumn("formatted_prompt", format_prompt_udf("text", "image1", "image2", "image3")) return result_str def process_and_save(self, json_output_path="training_data.json"): vision_df = self.join_vision_data() formatted_df = self.format_to_training_data(vision_df) formatted_df.show(truncate=True) # 保存为JSON文件 formatted_prompts = [row.formatted_prompt for row in formatted_df.collect()] with open(json_output_path, "w") as f: json.dump(formatted_prompts, f, indent=2)将Cell的语言类型设置为Python,执行以下代码,构造训练数据集。
from torch.utils.data import Dataset, DataLoader from PIL import Image import torch from torchvision import transforms import io import json class VLMDataset(Dataset): """ Custom dataset for VLM training. """ def __init__(self, df, transform=None): """ Initialize the dataset. """ self.rows = df.select("formatted_prompt").collect() self.transform = transform or transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor() ]) def __len__(self): """ Get the total number of samples in the dataset. """ return len(self.rows) def __getitem__(self, idx): """ Get a sample from the dataset. """ row = json.loads(self.rows[idx].formatted_prompt) text = row["instruction"] images_data = row["input"] images = [] for image_hex in images_data: img_data = bytes.fromhex(image_hex) try: image = Image.open(io.BytesIO(img_data)) if self.transform: image = self.transform(image) images.append(image) except Exception as e: print(f"Error processing image: {e}") images.append(torch.zeros(3, 224, 224)) # Placeholder for missing images while len(images) < 3: images.append(torch.zeros(3, 224, 224)) return text, torch.stack(images) if __name__ == "__main__": processor = VisionDataProcessor() formatted_df = processor.format_to_training_data(processor.join_vision_data()) dataset = VLMDataset(formatted_df) dataloader = DataLoader(dataset, batch_size=8, shuffle=False) for batch in dataloader: texts, images = batch print('Texts:', texts) print('Images batch shape:', images.shape) processor.spark.stop()执行结果如下:
构造了一个3*3*3*224*224(批次*图片数量*图片大小[RGB,长,宽])的数据集。