
使用执行计划分析查询
AnalyticDB MySQL版的SQL诊断功能支持以树形图的形式展现SQL查询的执行计划。执行计划树分为两层:第一层是Stage层,第二层是算子(Operator)层。本文介绍如何使用Stage层和算子层执行计划树来分析查询。
Stage层执行计划树
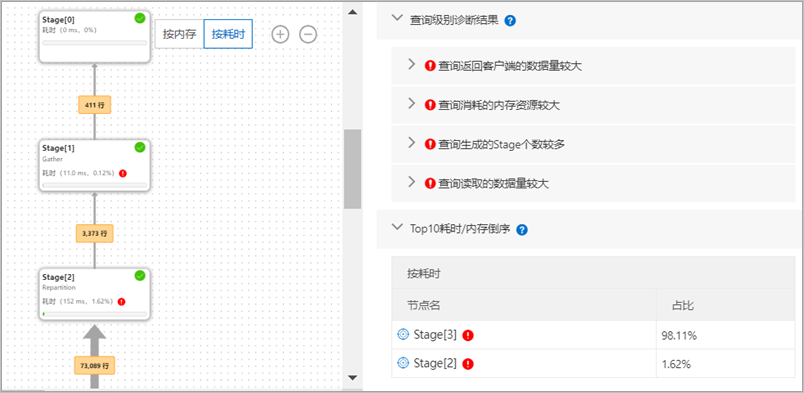
Stage层执行计划树由多个Stage节点组成,数据流向自下而上,先由具有扫描算子的Stage进行数据扫描,再经过中间Stage节点的层层处理后,再由最上层的根节点将查询结果返回客户端。
Stage层执行计划树中主要包含如下信息:
基本信息
图中的每个矩形框代表一个Stage,框里会包含Stage ID、数据输出类型、耗时或内存(选择按内存排序时展示)等信息。
说明当Stage层执行计划树上出现红色警示号,表示该Stage被诊断出存在可优化点。
数据输出行数
两个相邻Stage间连线上的数字表示上游Stage向下游Stage输出的数据行数。数据输出行数越多,Stage间的连线越粗。
数据输出方法
表示在两个相邻的Stage间,上游向下游Stage传输数据时所用的方法。AnalyticDB MySQL版支持以下数据输出方法。
数据输出方法
说明
Broadcast
表示上游Stage中每个计算节点的数据都会复制到所有下游Stage的计算节点。
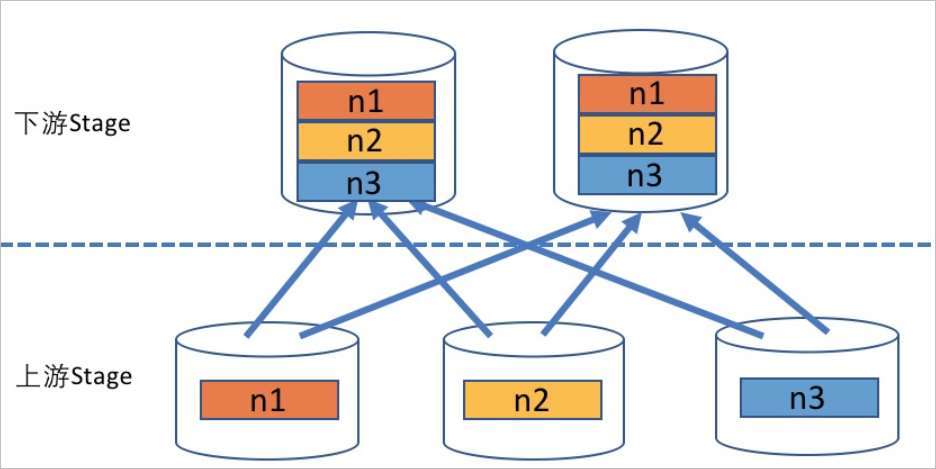
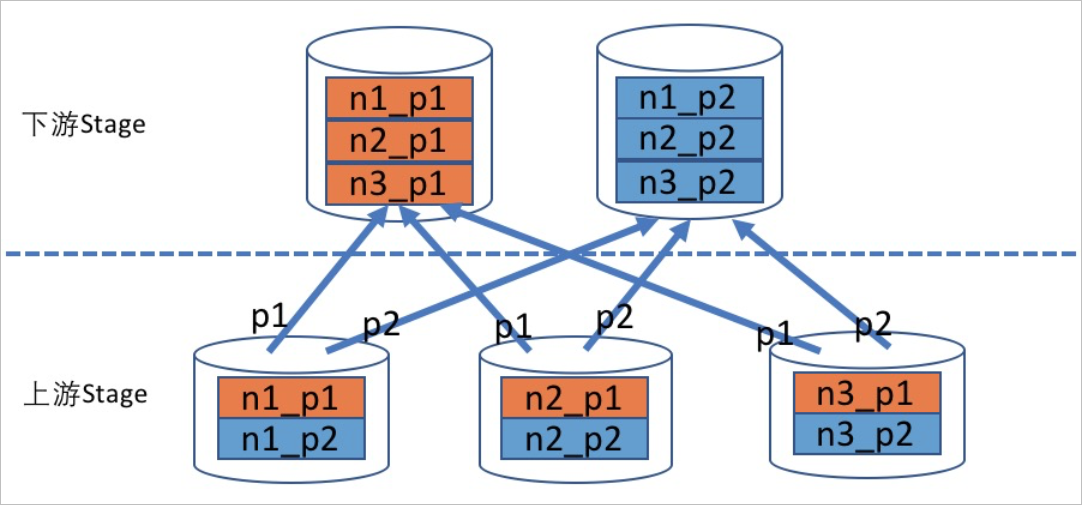
Repartition
表示上游Stage中每个节点的数据会按照固定的规则切分后,再分发到下游Stage的指定计算节点。
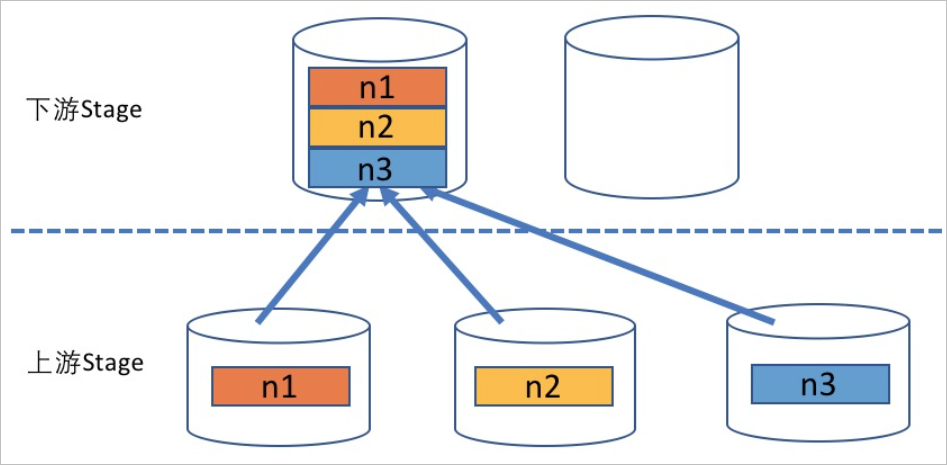
Gather
表示上游Stage中每个节点的数据会集中到下游Stage中某一个特定的计算节点。
查看内存使用率或执行耗时Top 10的Stage详情
执行计划树右侧的Top10耗时/内存倒序页签下,会展示执行耗时占总查询耗时比例最大,或使用内存占总查询使用内存比例最大的前10个Stage的ID和对应的比例。
说明默认按耗时排序,您也可以选择执行计划树右上角的按内存排序。
Top10耗时/内存倒序页签下不会显示内存使用量或执行耗时占比小于1%的Stage数据。
由于统计方式的差异,可能存在一个查询中的所有Stage耗时或内存的百分比之和不等于100%的情况。
诊断结果
单击执行计划树中某个Stage(如Stage[1]),即可在右侧查看对应Stage的诊断结果详情,包括如下两类诊断:
Stage诊断:这类诊断结果包含了对目标Stage诊断结果的详细说明,包括诊断出的问题(如存在较大的数据量被广播或数据倾斜)以及对应的调优方案。
算子诊断:这类诊断仅展示当前Stage中有问题的算子名称以及对应问题的概述,详细的说明和调优方案需要到算子执行计划树中才能看到。更多详情,请参见算子层计划执行树。
关于Stage的诊断结果的说明,请参见Stage级别诊断结果。
统计信息
诊断结果下方展示了目标Stage中各项指标的统计信息。
指标项
说明
峰值内存
目标Stage的峰值内存消耗量。系统会根据实际内存消耗量选择Bytes、KB、MB、GB或TB为单位。
累积耗时
目标Stage内存中所有算子多节点多线程执行时耗时的累加,系统会根据实际耗时选择ms、s、m或h为单位。
说明该累积耗时不能和当前查询的总耗时进行比较。
输出行数
目标Stage输出的行数。
输出大小
目标Stage输出的数据量。系统会根据实际数据量选择Bytes、KB、MB、GB或TB为单位。
输入行数
目标Stage输入的行数。
输入大小
目标Stage输入的数据量。系统会根据实际数据量选择Bytes、KB、MB、GB或TB为单位。
扫描行数
目标Stage扫描的行数。
说明仅当目标Stage中存在数据扫描算子时支持该参数。
扫描量
目标Stage扫描的数据量。系统会根据实际数据量选择Bytes、KB、MB、GB或TB为单位。
说明仅当目标Stage中存在数据扫描算子时支持该参数。
算子层计划执行树
算子层执行计划由多个算子组成,图中的每个矩形框代表一个算子,数据流向自下而上,扫描数据过程或接收网络数据由最上游的算子(TableScan和RemoteSource)完成,扫描到的数据和接收到的网络数据经过中间算子层层处理后,再由最上层的根节点算子(StageOutput或Output)将数据输出到下游Stage或将查询结果返回给客户端。
您可以将鼠标移动到目标Stage上,在弹出的信息框中单击查看Stage计划,即可进入对应Stage的计划详情页来查看算子层计划执行树。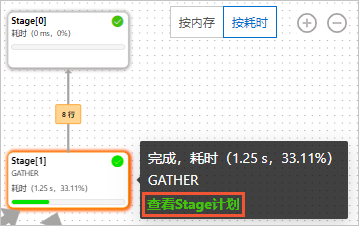
算子层执行计划树中包含如下信息: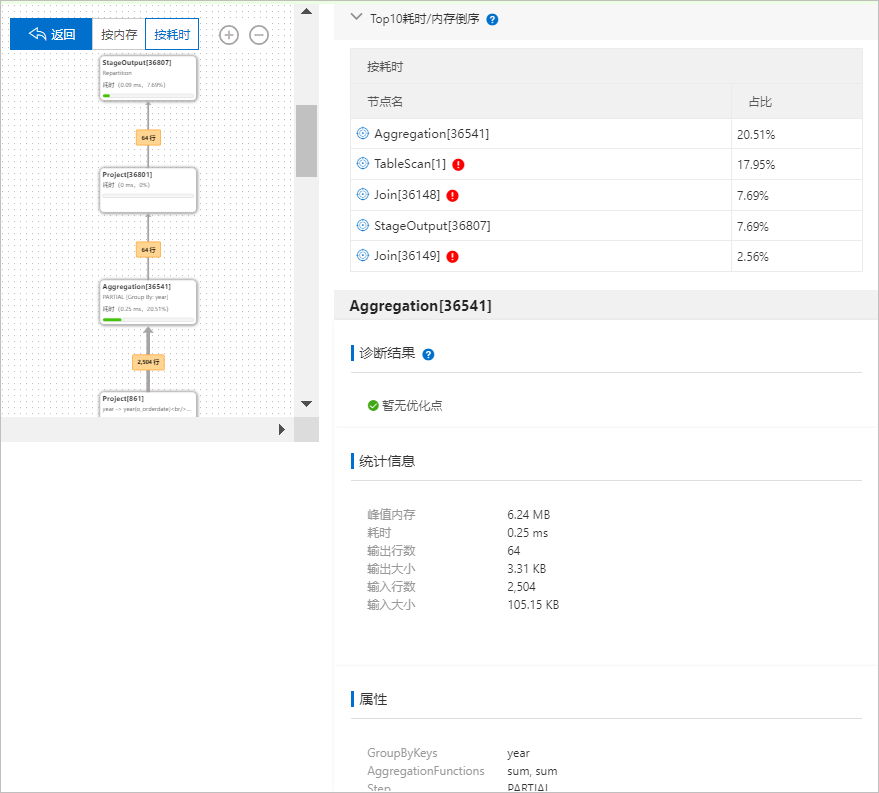
当算子层执行计划树上出现红色警示号,表示该算子被诊断出存在可优化点。
基本信息
图中的每个矩形框代表一个算子,框里会包含算子名称及ID、算子属性(如Join算子的Join条件、算法等)、耗时或内存(选择按内存排序时展示)等信息。
数据输出行数
两个相邻算子间连线上的数字表示上游算子向下游算子输出的数据行数。数据输出行数越多,算子间的连线越粗。
查看内存使用率或执行耗时Top 10的算子详情
执行计划树右侧的Top10耗时/内存倒序页签下,会展示执行耗时占总查询耗时比例最大,或使用内存占总查询使用内存比例最大的前10个算子的ID和对应的比例。
说明默认按耗时排序,您也可以选择执行计划树右上角的按内存排序。
Top10耗时/内存倒序页签下不会显示内存使用量或执行耗时占比小于1%的算子数据。
由于统计方式的差异,可能存在一个Stage中的所有算子耗时或内存的百分比之和不等于100%的情况。
诊断结果
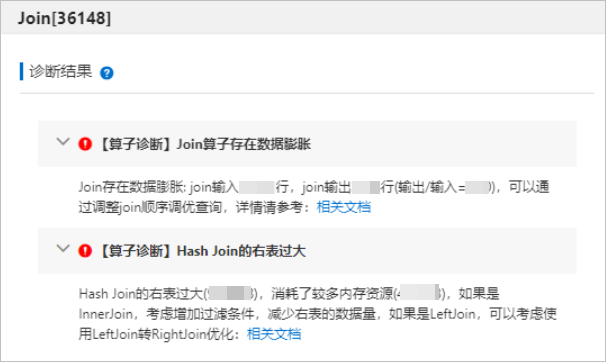
单击执行计划树中某个算子(如Join[36148]),即可在右侧查看对应算子的诊断结果详情,包括诊断出的问题(如存在数据膨胀或Join的右表过大)以及对应的调优方案。更多关于算子诊断的详情,请参见算子级别诊断结果。
统计信息
诊断结果下方展示了目标算子中各项指标的统计信息。
指标项
说明
峰值内存
目标算子的峰值内存消耗量。系统会根据实际内存消耗量选择Bytes、KB、MB、GB或TB为单位。
耗时
目标算子在一定并发度上的平均耗时,系统会根据实际耗时选择ms、s、m或h为单位。
说明该耗时可以和当前查询的耗时进行比较。
输出行数
目标算子输出的行数。
输出大小
目标算子输出的数据量。系统会根据实际数据量选择Bytes、KB、MB、GB或TB为单位。
输入行数
目标算子输入的行数。
输入大小
目标算子输入的数据量。系统会根据实际数据量选择Bytes、KB、MB、GB或TB为单位。
Builder统计信息
包括Builder的类型、峰值内存、耗时、输出输入行数和数据量等信息。主要有如下Builder类型:
HashBuilder:用于构建Hash表来完成Hash Join计算。
SetBuilder:用于构造Set结构来完成Semi Join计算。
NestLoopBuilder:用于完成Nest Loop Join计算。
说明仅Join算子支持该统计指标项。
属性
不同算子的属性信息不同,例如Join算子的属性信息中包括了Join的类型、方式等。更多详情,请参见算子。