
通过导入工具导入至数仓版
本文介绍如何使用云原生数据仓库 AnalyticDB MySQL 版导入工具将本地数据导入至AnalyticDB for MySQL数仓版集群。
功能介绍
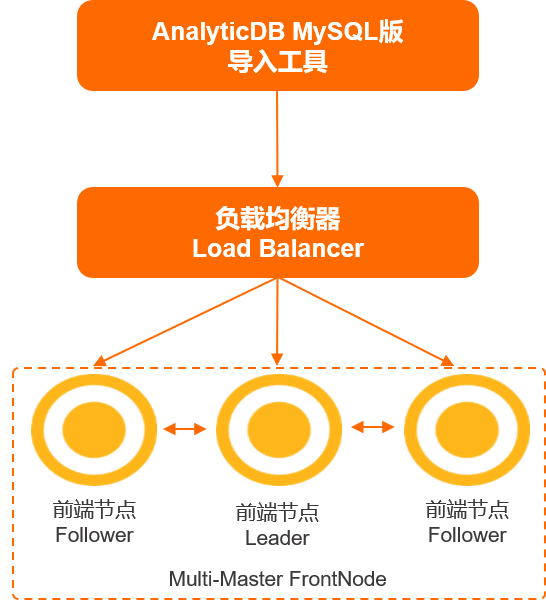
工作原理
AnalyticDB for MySQL导入工具通过JDBC协议接入负载均衡器(Load Balancer),负载均衡器下可连接多个前端节点(FrontNode),前端节点主要负责MySQL协议解析、SQL解析、数据写入、查询调度等,数据经由前端节点转发给存储节点进行导入。
功能特点
相较于MySQL Load Data工具,AnalyticDB for MySQL导入工具有如下特点:
支持通过配置
batchSize、并发数等来控制导入速度,实现以最大化的吞吐量进行数据导入。参数配置详情,请参见步骤三:脚本准备。支持单个文件、多个文件或文件夹的导入,无需启动多个MySQL Load Data进程并行导入。
能够利用并行、Batch、池化、流水线执行(读写非串行)、GC-less programming、大块文件顺序IO读等技术实现更佳的导入性能,导入工具如果配置合理,可以最大化AnalyticDB for MySQL集群的写入吞吐(Throughput)。
导入流程介绍
步骤 | 说明 |
下载AnalyticDB for MySQL导入工具并完成解压和安装。 | |
准备需要导入的源数据。 | |
修改导入脚本模板中的参数,准备数据导入脚本。 | |
执行导入脚本将本地数据导入至AnalyticDB for MySQL集群。 |
步骤一:下载并解压导入工具
执行以下命令,新建一个目录(本文示例中为/u01/loadata)。
mkdir -p /u01/loadata执行以下命令,进入目录。
cd /u01/loadata执行以下命令,下载导入工具。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20220811/gpvn/adb-import-tool.tar.gz执行以下命令,解压导入工具。
tar zxvf adb-import-tool.tar.gz解压后将会产生如下文件:
adb-import.sh.template adb-import.sh.template.md5 adb-import-tool.jar adb-import-tool.jar.md5说明您可以通过执行
java -version命令来确认是否已安装Java,以及Java版本是否为1.8或以上。
步骤二:导入数据准备
您还可以使用Linux的split命令对大文件进行切分(建议切分后的文件大小为1 GB~2 GB),文件切分后会形成更多的分片,更利于AnalyticDB for MySQL导入工具执行并行导入,从而提升导入速度,缩短导入时间。
例如,您可以将一个128 GB的文件filename.txt均匀地切分为64份,每个文件2 GB,那么AnalyticDB for MySQL导入工具将会以64的并行度来读取文件。切分命令如下:
split -l$((`wc -l < filename.txt`/64 + 1)) filename.txt filename.txt.split -da 2;确认需要导入的文件或文件夹的绝对路径。
确认导入文件的行分隔符和列分隔符。更多关于分隔符的说明,请参见步骤三:脚本准备。
确认导入文件的列顺序必须与建表DDL定义顺序一致,可以在数据库中执行SHOW CREATE TABLE确保列顺序。列数必须大于1。
例如,可以使用如下命令定义表结构:
CREATE TABLE `product_info` ( `id` bigint NOT NULL, `name` varchar, `price` decimal(15, 2) NOT NULL ) DISTRIBUTED BY HASH(`id`) INDEX_ALL='Y';合法文件内容如下:
1|tv|1000.0 2|computer|2000.0 3|cup|15.8导入工具兼容最后一列包含多余分隔符的情况。
例如
1|abc|3.0和1|abc|3.0|都是合法的。说明对于空字符串,导入工具默认按照null处理,例如导入的文件为
4||5.0,则name列会插入null值,而不是字符串''。如果列中存在自增列,文件中无需特殊体现,导入工具可以兼容。
步骤三:脚本准备
adb-import.sh.template是一个模板脚本,支持自定义脚本名称,例如要导入的表名为product_info,您可以将脚本命名为adb-import-product_info.sh。您可以复制一份模板脚本,并根据数据导入场景编辑导入脚本参数。
# 脚本中的参数说明 #
#-------------------------------- #
# 下面是必填参数
# -------------------------------- #
####################################
# java命令路径
# 注:如果在控制台下可直接执行java命令,则无需设置。
####################################
java_cmd=java
####################################
# 导入程序jar包地址
# 如果在脚本所在目录执行,则无需设置,否则需要设置绝对路径。
####################################
jar_path=adb-import-tool.jar
####################################
# 配置数据库连接参数
# 注:确保database已经在ADB中创建
# 如果encryptPassword=true需要填写base64加密后的密码。
####################################
host=host
port=3306
user=adbuser
password=pwd
database=dbname
encryptPassword=false
####################################
# 导入表名
####################################
tableName=please_set_table_name
####################################
# 导入的文件或文件夹的绝对路径,支持:
# 1)单个文件或单个文件夹
# 或者
# 2)同时导入多个文件,多个文件的路径间用英文逗号(,)分隔。
####################################
dataPath=please_set_data_file_path_or_dir_path
####################################
# 导入并行度
# 注:越大的并行度越有利于发挥ADB的性能
# 建议值>=16,<=96。
####################################
concurrency=64
####################################
# 导入写入VALUES的数量
# 注:越大的批次越有利于发挥ADB的性能
# 但也要结合单行的长度,不宜过大
# 建议值>=1024,<=4096。
####################################
batchSize=4096
####################################
# 导入文件编码,UTF-8或者GBK。
####################################
encoding=UTF-8
####################################
# 行分隔符
# 支持使用可见符(例如"\\n")和不可见符作为分隔符。
# 如需使用不可见符作为分隔符,需使用16进制来表示。
* 例如\x0d\x06\x08\x0a需使用十六进制表示为"hex0d06080a"。
####################################
lineSeparator="\\n"
####################################
# 列分隔符
# 支持使用可见符(例如"\\|")或不可见符作为分隔符。
# 如需使用不可见符作为分隔符,需使用16进制来表示。
# 例如\x07\x07需使用十六进制表示为"hex0707"。
####################################
delimiter="\\|"
# -------------------------------- #
# 下面是选填参数
# -------------------------------- #
####################################
# jvm参数
####################################
jvmopts="-Xmx12G -Xms12G"
####################################
# 当dataFile是一个文件夹时,
# 并行读取文件的数量。
####################################
maxConcurrentNumOfFilesToImport=64
####################################
# 选填,默认值:false,空字符串会变成null;
# 若设置为true,则空字符串会变成''。
# 建议设置为默认值false。
####################################
nullAsQuotes=false
####################################
# 每个文件导入完毕后是否打印目标表实际行数。
# 选填,默认值:false。
####################################
printRowCount=false
####################################
# SQL执行失败时候会打印SQL,
# 设置错误SQL的打印截断长度。
# 选填,默认值:1000。
####################################
failureSqlPrintLengthLimit=1000
####################################
# 导入数据时是否不执行INSERT,仅打印INSERT SQL命令。
# 选填,默认false。
####################################
disableInsertOnlyPrintSql=false
####################################
# 跳过表头。选填,默认false。
####################################
skipHeader=false
####################################
# INSERT SQL的缓冲数量。
# 便于发送给ADB的时候做到
# IO和计算分离,提高客户端性能。
####################################
windowSize=128
####################################
# 是否转义列中的\以及'符号。选填,默认true,表示需要转义。
# 转义对于客户端有一定字符串解析造成的性能损失,
# 特殊情况下保证没有转义字符的情况下,可以置false。
####################################
escapeSlashAndSingleQuote=true
####################################
# 导入数据遇到错误,是否忽略失败的批次。
####################################
ignoreErrors=false
####################################
# 导入数据遇到错误,是否打印出错的SQL。
####################################
printErrorSql=true
####################################
# 当导入数据遇到错误,且printErrorSql=true时,
# 是否打印出错的栈信息。
####################################
printErrorStackTrace=true步骤四:执行导入
执行如下命令导入脚本:
sh adb-import-product_info.sh;若打印出如下日志表示执行正常:
[2021-03-13 17:50:24.730] add consumer consumer-01导入期间,导入工具不会进行过多的日志滚动,您可以查询数据库获取导入进度,例如查询目标表的总行数,命令如下:
mysql > select count(*) from dbname.product_info;说明数据导入期间若执行SQL出错,导入工具会立即停止导入,并打印出错误SQL的详细信息。此时导入的数据是不完整的,可通过执行
TRUNCATE TABLE table_name清空表后重新导入;或者执行DROP TABLE table_name删除表后再新建表来重新导入。导入结束后会打印每个文件的读取行数、耗时,以及总体的耗时,最后会提示是否全部执行成功。 如果全部执行成功,则打印
all import finished successfully,否则打印all import finished with ERROR!。详细的导入行数,请查询数据库进行校验。
常见问题
Q:如何查验客户端或其所在服务器负载是否存在瓶颈?
A:若客户端存在瓶颈,将无法最大化压测数据库,此时您可以通过查看以下常用命令来查验客户端自身以及所在服务器负载是否存在瓶颈。
命令
说明
top
查看CPU使用率。
free
查看内存占用。
vmstat 1 1000
查看综合负载。
dstat -all --disk-util或iostat 1 1000
查看磁盘的读带宽和使用率。
jstat -gc <pid> 1000
查看导入工具Java进程的垃圾回收(Garbage Collection,简称GC)详情,如果GC频繁,可以尝试适当扩大JVM参数
jvmopts中的堆内存大小,例如将其扩大到-Xmx16G -Xms16G。Q:如何将导入脚本参数化?
A:如果确保导入文件的行列分隔符一致,可修改导入脚本中的
tableName和dataPath参数,通过传入不同的表名和文件路径参数,实现一个脚本导入多个表的需求。示例如下:
tableName=$1 dataPath=$2使用参数化的方式执行导入。
# sh adb-import.sh table_name001 /path/table_001 # sh adb-import.sh table_name002 /path/table_002 # sh adb-import.sh table_name003 /path/table_003Q:如何将导入程序放在后台运行?
A:您可以执行如下命令在后台运行导入程序:
# nohup sh adb-import.sh &导入程序在后台开始运行后,您可以执行以下命令查看检查日志,如果打印异常信息栈则说明导入存在错误,需要根据异常信息进行问题排查。命令如下:
# tail -f nohup.out您还可以使用如下命令查看导入进程是否仍正常执行:
# ps -ef|grep importQ:如何忽略导入程序中的错误行?
A:导入程序中的错误行可以分为如下两类:
执行SQL出错。
针对此类错误,您可以通过设置参数
ignoreErrors=true来忽略错误行。此时会在执行结果中打印详细的出错文件、起始行号(因设置了batchSize,错误行会在起始行号后的batchSize行内)以及执行出错的SQL。文件列数不符合预期。
当文件列数不符合预期时,系统会立即停止导入该文件并打印出错误信息,但由于该错误是由于非法文件导致的,因此并不会被忽略,您需要手动排查文件的正确性。此类错误会打印如下错误信息:
[ERROR] 2021-03-22 00:46:40,444 [producer- /test2/data/lineitem.csv.split00.100-41] analyticdb.tool.ImportTool (ImportTool.java:591) -bad line found and stop import! 16, file = /test2/data/tpch100g/lineitem.csv.split00.100, rowCount = 7, current row = 3|123|179698|145|73200.15|0.06|0.00|R|F|1994-02-02|1994-01-04|1994-02- 23|NONE|AIR|ongside of the furiously brave acco|
Q:如何缩小导入失败原因的排查范围?
A:为帮助更快的定位导入失败原因,您可以从如下几个方面来缩小失败原因的排查范围:
当导入失败时,AnalyticDB for MySQL导入工具会打印错误日志以及详细的错误原因,默认会截断SQL语句(最长支持1000个字符),若需要打印更全的SQL信息,您可以使用如下命令将
failureSqlPrintLengthLimit参数扩大至一个合理值(例如1500):printErrorSql=true failureSqlPrintLengthLimit=1500;由于SQL设置了
batchSize,通常是上千行批量执行的SQL,不利于分辨错误行,您可以缩小batchSize参数(例如设置为10)以便于定位错误的行。参数修改命令如下:batchSize=10;如果文件已进行了切分且已知错误的行所在的文件分片,为了复现问题,可通过修改
dataPath参数来导入存在错误行的单个文件,查看错误信息。语句如下:dataPath=/u01/this/is/the/directory/where/product_info/stores/file007;
Q:如何在Windows环境下运行导入程序?
A:Windows环境暂未提供bat批处理脚本,您可以直接使用如下方法调用JAR文件来执行:
usage: java -jar adb-import-tool.jar [-a <arg>] [-b <arg>] [-B <arg>] [-c <arg>] [-D <arg>] [-d <arg>] [-E <arg>] [-f <arg>] [-h <arg>] [-I <arg>] [-k <arg>] [-l <arg>] [-m <arg>] [-n <arg>] [-N <arg>] [-O <arg>] [-o <arg>] [-p <arg>] [-P <arg>] [-Q <arg>] [-s <arg>] [-S <arg>] [-t <arg>] [-T <arg>] [-u <arg>] [-w <arg>][-x <arg>] [-y <arg>] [-z <arg>]参数
是否必填
说明
-h,--ip <arg>必填
AnalyticDB for MySQL集群的连接地址。
-u,--username <arg>AnalyticDB for MySQL集群的数据库账号。
-p,--password <arg>AnalyticDB for MySQL集群的数据库账号对应的密码。
-P,--port <arg>AnalyticDB for MySQL集群使用的端口号。
-D,--databaseName <arg>AnalyticDB for MySQL集群的数据库名称。
-f,--dataFile <arg>需要导入的文件或文件夹的绝对路径,支持如下几种导入场景:
仅导入单个文件或单个文件夹。
同时导入多个文件,多个文件的路径间用英文逗号(,)分隔。
-t,--tableName <arg>需要导入的表名。
-a,--createEmptyFinishFilePath <arg>选填
导入完毕后是否生成一个标志文件。默认为空字符串,表示不生成。若需要生成标志文件,直接输入文件名即可。例如您可以设置
-a file_a,即可生成一个名为file_a的标志文件。-b,--batchSize <arg>设置
INSERT INTO tablename VALUES (..),(..)中批量写入VALUES的数量。默认值:1。说明为更好地实现数据批量写入效果,建议将该值设置在1024~4096之间。
-B,--encryptPassword <arg>数据库密码是否使用加密算法加密。默认值:false,表示不使用加密算法加密数据库密码。
-c,--printRowCount <arg>每个文件导入完毕后是否打印目标表实际行数。默认值:false,表示不打印。
-d,--skipHeader <arg>是否跳过表头。默认值:false,表示不跳过表头。
-E,--escapeSlashAndSingleQuote <arg>是否转义列中的
\以及'符号。默认值:true,表示需要转义。说明转义对于客户端字符串解析的性能有一定损失,若确保需要导入的文件中没有转义字符,可以设置该参数为false。
-I,--ignoreErrors <arg>导入数据遇到错误,是否忽略失败批次。默认值:false,表示不忽略。
-k,--skipLineNum <arg>跳过的行数,类似
IGNORE number {LINES | ROWS}参数。默认值:0,表示不跳过。-l,--delimiter <arg>列分隔符。AnalyticDB for MySQL默认使用可见符
\\|作为列分隔符。同时也支持使用不可见符作为分隔符,如需使用不可见符,需要使用十六进制来表示。例如,\x07\x07需使用十六进制表示为hex0707。-m,--maxConcurrentNumOfFilesToImport <arg>当dataFile是一个文件夹时,并行读取文件的数量。默认值:
Integer.MAX_VALUE,表示读所有文件。-n,--nullAsQuotes <arg>当需要导入的文件中存在
||时,是否需要将其设置为''。默认值:false,表示不将||设置为'',而是设置为null。-N,--printErrorSql <arg>导入数据遇到错误,是否打印出错的SQL。默认值:true,表示打印出错误的SQL。
-O,--connectionPoolSize <arg>AnalyticDB for MySQL数据库连接池大小。默认值:2。
-o,--encoding <arg>文件编码方式。取值范围:GBK或UTF-8(默认值)。
-Q,--disableInsertOnlyPrintSql <arg>导入数据库时是否不执行INSERT,仅打印INSERT的SQL命令。选填,默认值:false,表示执行INSERT。
-s,--lineSeparator <arg>行分隔符。AnalyticDB for MySQL默认使用可见符
\\n作为行分隔符。同时也支持使用不可见符作为分隔符,如需使用不可见符,需要使用十六进制来表示。例如,\x0d\x06\x08\x0a需使用十六进制表示为hex0d06080a。-S,--printErrorStackTrace <arg>当导入数据遇到错误,且
printErrorSql=true时,是否打印出错的栈信息。默认值:false,表示不打印。-w,--windowSize <arg>INSERT SQL的缓冲数量。便于将INSERT SQL命令发送至AnalyticDB for MySQL时,实现流水线加速以及IO和计算分离,从而提高客户端性能。默认值:128。
-x,--insertWithColumnNames <arg>执行
INSERT INTO命令时是否带上列名,即是否执行INSERT INTO tb(column1, column2)命令进行数据导入。默认值:true,表示导入时需要带上列名。-y,--failureSqlPrintLengthLimit <arg>当执行INSERT 命令失败时需要打印错误SQL,使用该参数设置错误SQL的打印截断长度。默认值:1000。
-z,--connectionUrlParam <arg>数据库连接参数。默认值:
?characterEncoding=utf-8。示例:
?characterEncoding=utf-8&autoReconnect=true。案例1:使用默认参数配置导入单个文件,命令如下:
java -Xmx8G -Xms8G -jar adb-import-tool.jar -hyourhost.ads.aliyuncs.com -uadbuser -ppassword -P3306 -Dtest --dataFile /data/lineitem.sample --tableName LINEITEM案例2:修改相关参数实现最大化吞吐导入文件夹下所有文件,命令如下:
java -Xmx16G -Xms16G -jar adb-import-tool.jar -hyourhost.ads.aliyuncs.com -uadbuser -ppassword -P3306 -Dtest --dataFile /data/tpch100g --tableName LINEITEM --concurrency 64 --batchSize 2048