
语义检索可基于用户请求,通过分析理解用户意图,智能选择合适的MCP工具,从而降低上下文Token,提升检索效率。本文介绍如何开启语义检索及相关配置。
背景信息
当用户开发的智能体需要调用大量MCP工具时,可能面临管理困难、工具选择不合适、Tokens消耗增加以及检索效率降低等问题。为解决相关问题,AI网关推出MCP语义检索功能,通过以下方式优化MCP工具调用过程。
统一入口管理:通过AI网关构建统一的MCP服务接入点,所有Agent可通过单一端点访问网关实例中注册的全部MCP工具,实现集中化接入,降低多MCP Server分散部署带来的运维复杂度。
智能工具检索:集成x_higress_tool_search语义搜索功能,基于AD向量数据库与Qwen系列大模型,提供高精度的工具推荐能力。Agent可通过自然语言描述需求,系统自动匹配并返回最相关的工具,无需预先了解具体工具名称。
双阶段检索机制:采用“向量召回 + 重排序”两阶段检索架构。首先利用Qwen Embedding模型进行向量化相似度计算,获取初步候选工具集,然后可选择性地使用Qwen Rerank模型对候选结果进行精细化排序,提升最终工具推荐的准确性与相关性。
实时元数据同步:建立完整的MCP工具生命周期管理流程。当用户在控制台执行MCP Server的增、删、改操作时,系统自动触发工具元信息的采集、向量化处理及持久化存储,确保向量数据库与实际部署的服务实例保持一致。
控制台集成化配置:在控制台启用“语义搜索”功能后,系统将自动完成ADB集合初始化、模型参数配置、路由规则下发及数据同步等全部配置流程,实现语义搜索能力的一站式开通与管理,提供即开即用的服务体验。
性能表现
在Salesforce的原始数据集xlam-function-calling-60k上,使用以下18个维度进行对比:
纯向量检索:3种相似度算法(cosine、L2、IP)。
RRF混合搜索双路召回:5个k值参数(10、30、60、100、200)。
说明倒数排序融合(Reciprocal rank fusion),有一个参数 k 控制融合效果,指定计算分数的算法的
1/(k+rank_i)中的 k 常数,范围大于 1 的正整数。Weight混合搜索:5个α值参数(0.0、0.2、0.5、0.8、1.0)。
说明比重排序,采用一个参数 alpha 控制向量和全文的分数比重,然后再排序,计算公式
alpha * vector_score + (1-alpha) * text_score,参数 alpha 表示向量和全文的检索分数比重,范围为 0~1,其中 0 表示仅全文,1 表示仅向量。Cascaded混合搜索:无参数算法。
说明先全文检索再在其基础上进行向量检索。
最优配置对比:4种最优配置的综合对比。
结果表明:
Weight算法优势:Weight混合搜索在精确测量下表现出微幅优势,α=0.8时Top-1准确率最高(80.6873%),α=0.5时Top-10准确率最高(98.3119%)
纯向量算法等效性:cosine和L2算法完全一致(80.6471%),IP算法略低(80.6270%),推荐使用cosine(业界标准)
混合搜索价值验证:Weight算法相比纯向量提升0.04个百分点,虽然幅度微小但在大规模应用中具有统计学意义
RRF算法局限:RRF算法在所有k值下Top-1准确率显著低于纯向量(57-59% vs 80.6%),存在系统性性能瓶颈
全文搜索局限性:Weight(α=0.2)准确率显著下降至76.19%,证明过度依赖全文搜索的风险
Cascaded表现:Cascaded算法Top-10准确率97.6%,略低于其他算法但仍保持较高水准
性能一致性:所有算法搜索时间均在0.32-0.35秒范围内,性能差异微小
评测结果
工具检索准确性
算法类型 | 配置 | Top-1准确率 | Top-10准确率 | 平均搜索时间 |
Weight混合 | α=0.8 | 80.687% | 98.292% | 0.3498s |
纯向量 | Cosine | 80.647% | 98.272% | 0.3194s |
纯向量 | L2 | 80.647% | 98.272% | 0.3187s |
Weight混合 | α=1.0 | 80.647% | 98.272% | 0.3177s |
纯向量 | IP | 80.627% | 98.252% | 0.3237s |
Weight混合 | α=0.5 | 80.527% | 98.312% | 0.3503s |
Weight混合 | α=0.2 | 76.186% | 98.292% | 0.3464s |
RRF混合 | k=10 | 59.043% | 96.805% | 0.3519s |
RRF混合 | k=60 | 57.918% | 96.744% | 0.3508s |
关键发现:
Weight算法微幅领先:Weight(α=0.8)在Top-1准确率上比纯向量高0.0402个百分点,Weight(α=0.5)在Top-10准确率上比纯向量高0.0402个百分点
算法精确排序:cosine=L2 > IP,Weight(α=1.0)等同于纯向量cosine,证明α=1.0时完全退化为纯向量搜索
RRF算法系统性劣势:所有k值配置下Top-1准确率均低于80%,与纯向量存在20+个百分点差距,不适合精确匹配场景
Top-K准确率分析
纯向量算法梯度表现:
Top-1: 80.647%
Top-3: 92.785%
Top-5: 95.96%
Top-10: 98.272%
Top-15: 98.995%
Top-20: 99.297%
检索召回率:99.3%的查询能够在Top-20结果中找到正确工具,表明向量搜索具有优秀的召回能力。
混合搜索算法深度分析
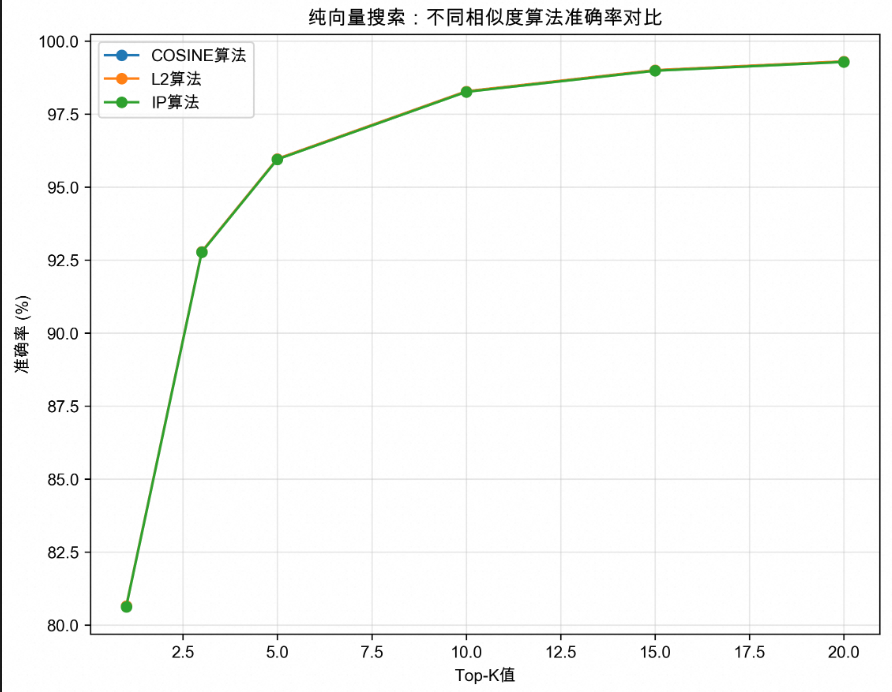
Weight算法参数优化
α值 | 语义含义 | Top-1准确率 | Top-10准确率 | 推荐场景 |
0.0 | 纯全文搜索 | 54.7% | 95.5% | 关键词匹配 |
0.2 | 主要全文+少量向量 | 76.2% | 98.3% | 文本相关性优先 |
0.5 | 平衡混合 | 80.5% | 98.3% | 推荐配置 |
0.8 | 主要向量+少量全文 | 80.7% | 98.3% | 语义理解优先 |
1.0 | 纯向量搜索 | 80.6% | 98.3% | 等同纯向量 |
优化建议:α=0.5-0.8区间为最优选择,能够充分利用向量语义理解和全文检索的优势。
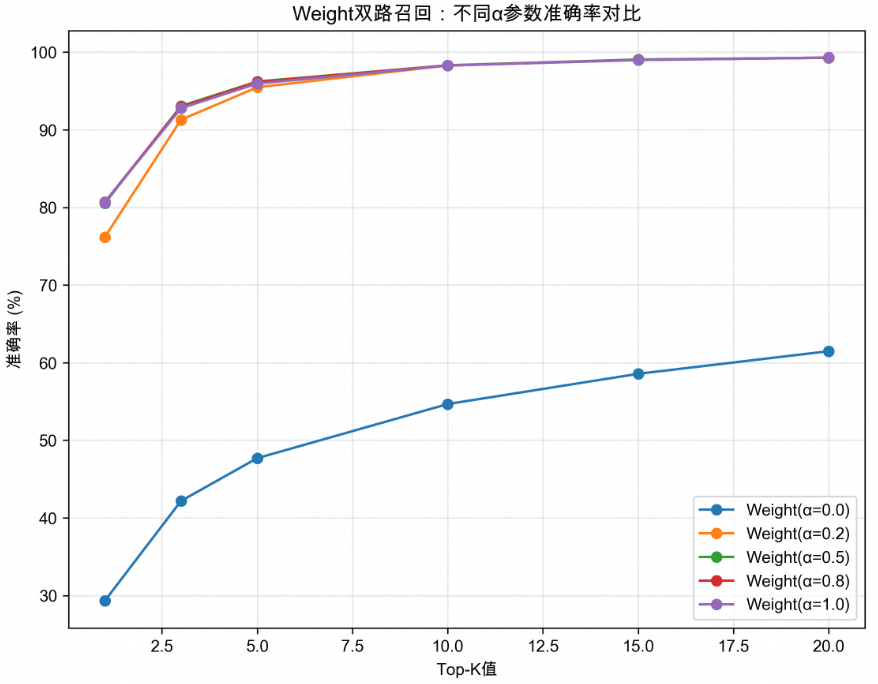
RRF算法性能分析
k值 | Top-1准确率 | Top-10准确率 | 性能特点 |
10 | 59.0% | 96.8% | 偏向排名靠前结果 |
30 | 57.4% | 96.7% | 中等平衡 |
60 | 57.9% | 96.7% | 经验推荐值 |
100 | 57.6% | 96.7% | 更平衡的融合 |
200 | 57.6% | 96.7% | 接近线性组合 |
性能瓶颈:RRF算法在所有k值配置下均表现出Top-1准确率的系统性劣势,建议在对精确匹配要求较高的场景中谨慎使用。
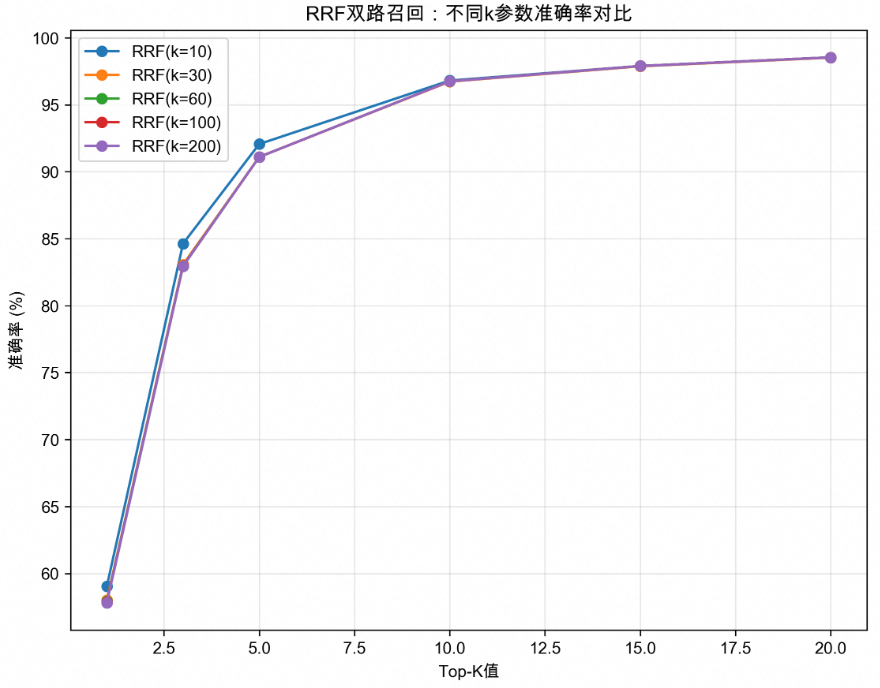
搜索性能分析
响应时间对比
纯向量搜索:0.319-0.324秒
Weight混合搜索:0.318-0.350秒
RRF混合搜索:0.351-0.352秒
Cascaded搜索:0.320秒
性能结论:所有算法的搜索时间均控制在350毫秒以内,满足实时检索需求。混合搜索相比纯向量搜索仅增加约30毫秒延迟。
错误案例分析
总错误案例:4,214个(占总查询的4.7%)。
错误分布:
Weight(α=0.0):2,255个错误(纯全文搜索局限性)。
RRF系列:平均161个错误/配置。
纯向量系列:平均85个错误/配置。
Weight(α=0.2-1.0):83-85个错误/配置。
错误模式:主要集中在语义相似但功能不同的工具混淆,以及多工具场景下的优先级判断。
操作步骤
启用语义检索
在AI 网关控制台的实例页面,在顶部菜单栏选择目标实例所在地域。
在实例页面,单击目标网关实例ID。
在左侧导航栏选择MCP 管理,单击语义检索页签。
单击编辑,开启启用语义检索,选择检索工具接入点,单击确定发布语义检索。
配置消费者认证
语义检索支持配置认证鉴权,开启后仅授权的消费者可通过API Key访问,无认证或认证异常的请求将被拒绝。
在语义检索页签,选择消费者认证。
单击配置信息功能编辑按钮,在MCP 服务消费者认证开启启用状态。认证方式默认选择API KEY。
单击授权,在添加消费者授权页面选择消费者。
说明消费者认证方式需使用API Key,不支持JWT认证方式的消费者使用语义检索。
单击添加完成授权。