本次ARMS Prometheus最新版本为Helm 1.1.17,对应的Agent版本为v4.0.0,包括有多项迭代,提升采集稳定性,修复已知Bug,优化资源消耗等。
如果您的集群内ARMS Prometheus Agent版本为v3.x.x 系列,由于历史版本存在一些未优化项,且存在数据断线的隐患和风险,因此建议您尽快升级至最新版本。
v4.0.0 版本特性说明
变更类型 | 发布内容 |
新增 | 集群事件采集任务,支持Kubernetes Deployment大盘。 |
新增 | 根据SLA进行自监控指标埋点,SLA稳定性大盘数据。 |
新增 | ServiceMonitor支持BasicAuth认证方式,Secret需要与ServiceMonitor在同一个命名空间下使用。 |
新增 | Metrics Metadata能力展示具体指标含义。 |
新增 | 支持传递Agent Chart版本到服务端,服务端根据该版本号初始化或升级大盘。 |
新增 | RemoteWrite自监控指标,统计每批次发送数据耗时。 |
新增 | 基础指标采集报错和采集延迟自监控指标。 |
新增 | 业务指标采集报错和延迟自监控指标。 |
优化 | RemoteWrite默认参数queue_config设置为min_shards=10,max_samples_per_send=5000,capacity=10000,提升大规模集群适应能力。 |
优化 | CSI采集Job服务发现方式,主要为PV采集相关。 |
优化 | senderLoop下发频率,修改syncWorkersSeries频率,减少不必要扰动。 |
优化 | 精简部分日志,优化部分日志增加抓取链路耗时更细节展示。 |
优化 | 基础指标采集Job单独固定采集周期和采集超时设置,不再使用Global配置,减少对基础指标采集受到的不必要干扰。 |
优化 | Master-Slave多副本模式下互相影响逻辑,Master与Worker,Worker与Worker之间互相不再影响,提升稳定性。 |
优化 | Master下发Targets策略,节省大约30%的CPU40%的Memory资源开销,提升采集性能。 |
优化 | metrics_relabel优化,CPU占用降低70%。 |
优化 | 多租场景Informer监听逻辑,多租场景下节省CPU开销约20%。 |
优化 | CoreDNS域名解析偶发失败,自动切换缓存IP并沿用,弱依赖CoreDNS实时域名解析,提升数据发送稳定性。 |
优化 | SendConfig下发采集配置逻辑,提升下发稳定性。 |
优化 | Master预抓取策略,节省Master资源开销,提升Master服务发现和Targets调度能力。 |
优化 | 单批次大包大于1 MB自适应,减少因后端限制导致数据包丢失情况。 |
BugFix | ScrapeLoop个别采集Target无法停止导致采集重复问题。 |
BugFix | 多租场景Pod的Label缓存中更新不及时,造成一个时间线变为两条问题。 |
BugFix | Master对于OOM或者Restart副本偶发Targets下发异常,导致部分采集Targets丢失问题。 |
BugFix | RemoteWrite中解析Secret类型问题和传输Header问题。 |
BugFix | Kubernetes-pods关闭操作偶发不生效问题。 |
BugFix | 修复Global默认参数和external_labels不生效问题,同时支持自定义修改。 |
升级风险
升级风险:本次升级到Helm 1.1.17/Agent v4.0.0为有损升级,按照集群监控数据采集量级的不同(Targets和Series的量级),存在监控数据断线的风险,预计断线时间在0~5分钟,不同集群可能存在一定的差异。
升级前:建议您在升级前执行步骤一、升级前预检查项(必选),确保最大程度降低升级对于集群监控数据的影响。
升级后:如果您在升级后发现数据异常,升级后请务必按照三、升级后检查项(可选)进行检查,一旦发现问题可参考升级后的常见问题进行检查和应对,如果未能解决您可以在钉钉中搜索Prometheus值班号(钉号:aliprometheus),联系产品技术专家进行咨询。
升级方式
一、升级前预检查项(必选)
Helm 1.1.16之前版本(不包含1.1.16)升级到最新Helm 1.1.17,曾经修改过的一些参数在升级过程中不会保留,需要升级前进行检查,如果存在修改过的参数需要在新版本中保留,需要您在升级后手动修改为升级前的参数值。
Helm 1.1.16之后的版本升级(包含1.1.16)支持参数的继承,后续升级则不需要再关注修改的参数。升级前参数检查方法如下:
登录容器服务管理控制台。
单击目标集群名称超链接,然后在左侧导航栏选择工作负载 > 无状态,切换命名空间为
arms-prom,并在目标arms-prometheus-ack-arms-prometheus的操作列选择更多 > 查看Yaml,查看完整YAML。需要检查的参数如下。
spec.replicas副本数,如果为1(升级后默认为1)则不需要单独关注。
spec.containers下的args(Agent)启动参数,未开启多租则此参数不存在,如果有自行设定则在升级后需要手动修改回升级前值。
tenant_userid
tenant_clusterid
tenant_token
spec.containers.resources limits默认为3核4 GB,requests默认为1核1 GB。
若非默认则需要记录,建议在升级后手动修改回升级前的数值。

对于上述参数有修改且需要保留的,需要自行记录数值,在升级后使用同样方法获取完整YAML后,修改并单击更新即可。
二、升级具体方法
建议通过ACK容器页面,进行ARMS Prometheus组件升级Helm版本,具体操作如下:
登录容器服务管理控制台。
单击目标集群名称超链接,然后在左侧导航栏选择运维管理 > 组件管理,单击日志与监控页签,找到ack-arms-prometheus卡片,单击升级进行升级。
升级完成后,在左侧导航栏选择运维管理 > Prometheus监控,然后单击右上角的跳转到Prometheus服务,系统会跳转至Prometheus控制台的Prometheus实例大盘列表页面,您可以查看具体Agent运行状态、指标采集情况等。
同时在左侧导航栏单击设置,然后在设置页签,查看Helm组件是否已经升级到最新版本。

三、升级后检查项(可选)
登录ARMS控制台。
在左侧导航栏选择,进入可观测监控 Prometheus 版的实例列表页面。
单击目标Prometheus实例名称,然后在左侧导航栏单击服务发现。单击Targets页签,升级后查看Job采集情况,总览采集情况。
在左侧导航栏单击设置,然后在自监控页签右上角单击前往Grafana查看大盘。Helm组件升级后可重点关注Agent运行状态,包括:副本数符合预期、数据发送速率无异常、资源消耗无异常、数据发送无异常。
在自监控页面的agent自监控页签,可以查看Prometheus Agent自监控大盘。
Helm组件升级后,可重点关注4个基础指标采集Job:_arms/kubelet/cadvisor、_arms/kubelet/metric、_kube-state-metrics、node-exporter。同时在页面右上角可选择时间范围,查看时间跨度覆盖升级前后,观察升级前后采集是否存在异常情况。
升级后的常见问题
升级后,实际运行副本数与预期Replica不相等
您需要检查是否有Agent处于Pending状态,ARMS Prometheus强依赖于全部副本处于Running状态才可以正常工作。您可以在容器服务控制台的目标集群工作负载 > 无状态页面的arms-prom命名空间下,查看全部副本的运行状态。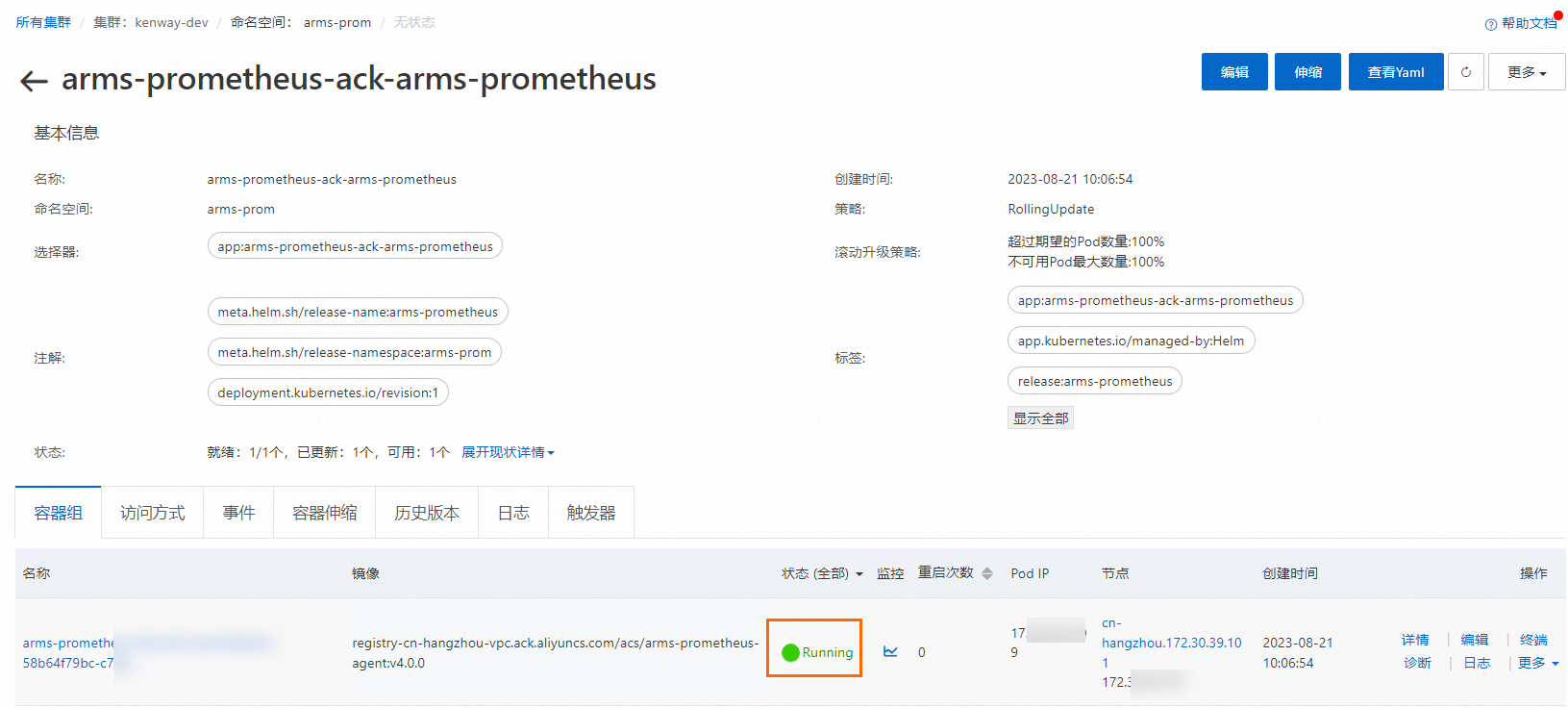
升级后,Agent消耗Memory/CPU较高
您需要检查是否有发送数据出现异常,数据发送异常会导致Agent内存堆积数据,进而导致资源消耗增高。您可以在容器服务控制台的目标集群运维管理 > Prometheus监控页面,单击其他页签,在Prometheus Agent中查看Memory/CPU的资源消耗情况。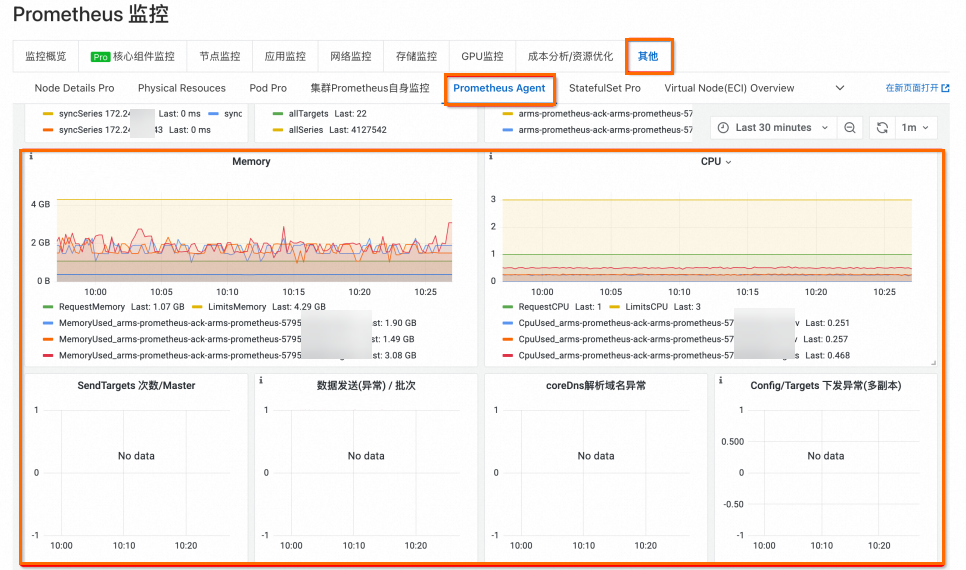
升级后,出现基础指标异常(完全断线或者不连续)
例如node_*** (图标①)、container_***(图标②)、kubelet_***(图标③)、kube_***(图标④)指标等,则需要排查基础指标采集Job是否有报错,您可以在Prometheus服务控制台的服务发现页面的Targets页签下,查看这些指标的情况。若发现存在报错请在钉钉中搜索Prometheus值班号(钉号:aliprometheus),联系产品技术专家协助解决。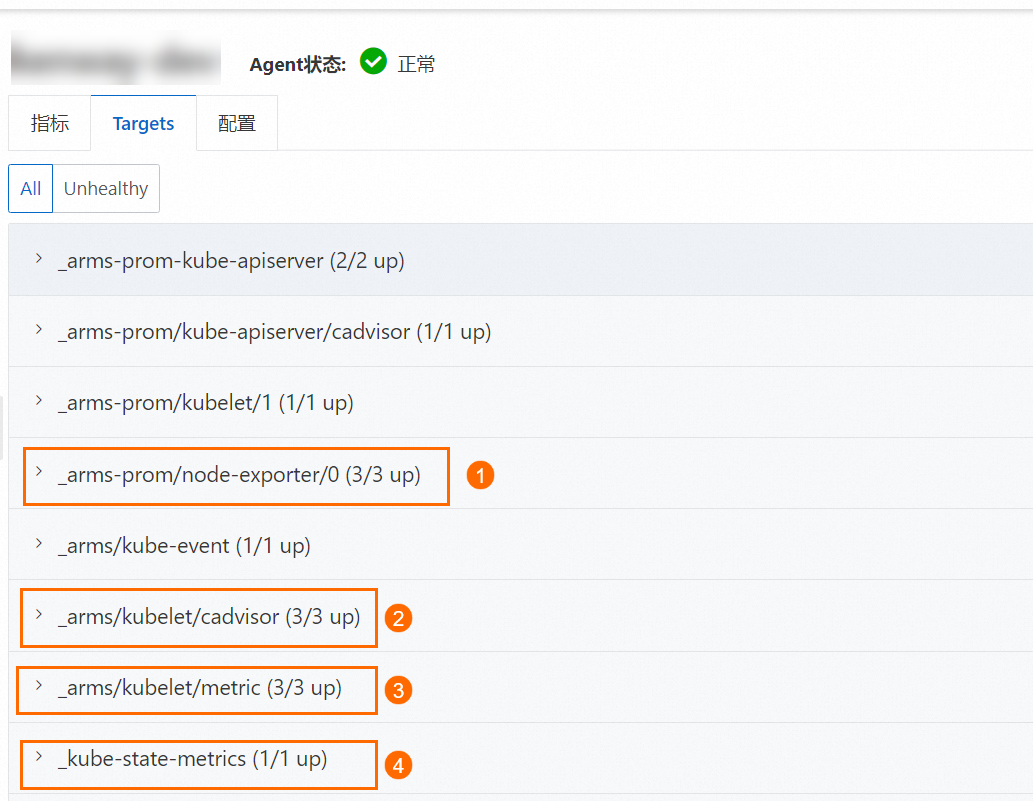
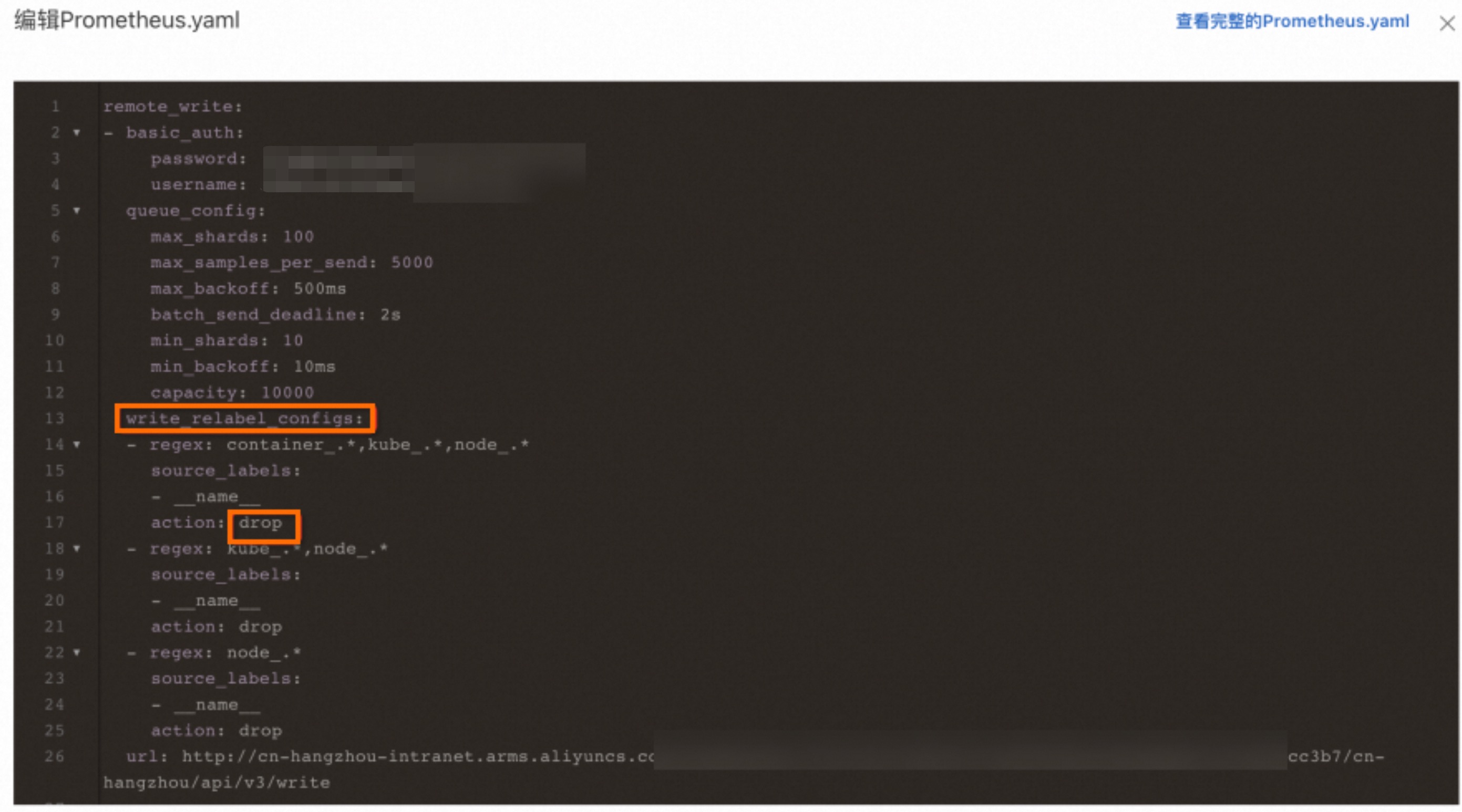
升级后,出现RemoteWrite流量下跌或者出现RemoteWrite侧部分数据缺失(若没有配置则忽略)
新版本v4.0.0中RemoteWrite的write_relabel_configs会自动生效,历史版本中该字段对应的能力未生效,若配置了drop、keep等动作,则会出现流量一定程度上的下跌,可自行酌情修改该字段。您可以在Prometheus服务控制台的设置页面的设置页签下,单击编辑Prometheus.yaml,然后在弹出的对话框中修改该字段。