
地域级故障是云上业务可能遭遇的一种极端类型的故障。当地域级故障发生时,特定地域下任何可用区内的服务都面临着无法连接、数据丢失以及工作负载无法运行等风险。服务网格 ASM(Service Mesh)支持将ASM入口网关部署在Kubernetes集群或弹性容器实例 ECI(Elastic Container Instance)中,作为业务应用统一的流量入口,并在每个集群中拥有独立的流量入口IP地址。当其中一个地域发生故障的时候把故障IP剔除,并将流量全部转移到正常地域,以实现对地域级故障的容灾。
容灾架构
为验证应对地域级别故障的能力,以下以双地域、双集群为例,介绍容灾架构:
构建多主控制面架构,即在两个地域分别部署一个K8s集群,并且在两个集群中部署完全对等的业务云原生服务,服务之间通过K8s集群域名相互调用。
说明使用多主控制面,可以保证每个地域的网格代理的推送延迟都是可控的,并且达到生产可用水准。同时也可以确保在地域故障时,控制面的灾备高可用。
两个集群均需要部署ASM网关,并配置ASM网关通过公网CLB或NLB对外暴露公网入口的IP或域名。再结合云解析DNS和全局流量管理GTM,将域名分别解析到两个IP地址。
当发生地域级别的故障时,另一个健康地域中的业务不受影响。此时,全局流量管理GTM会自动将故障地域的IP剔除出解析池,并将流量全部解析至健康地域的ASM网关上。

当出现突发流量时,您可以通过配置以下功能,进一步优化地域故障时的流量转移行为。
为ASM网关启用扩缩容HPA:迅速扩容出更多的ASM网关实例,以应对突发流量。
说明扩缩容HPA功能仅适用于企业版或旗舰版ASM实例。
为ASM网关或集群中的关键服务配置限流:通过ASM的限流功能,可以有效防止突增流量超过集群服务的承载能力,从而避免健康地域的应用服务因大量流量转移而崩溃。
(可选)您还可以配置ASM的限流指标监测与告警机制,便于实时观察和及时发现故障事件,以迅速对健康地域的工作负载进行扩容。
容灾实践流程
跨地域容灾支持所有类型的集群。本实践以ACK托管集群为例,演示从创建集群和ASM实例开始,到完成所有容灾配置并进行故障演练的整个过程。

容灾配置实践
以下以CLB类型的入口网关为例进行实践操作。关于NLB类型入口网关接入GTM的具体操作,请参见业务域名接入GTM。
步骤一:构建多主控制面架构
在两个不同的地域创建两个集群,分别命名为cluster-1和cluster-2,并开启使用EIP暴露API Server。具体操作,请参见创建ACK托管集群。
在集群所在的地域分别创建服务网格实例,命名为mesh-1和mesh-2,并分别添加cluster-1和cluster-2到ASM实例,以构建多主控制面架构服务网格。具体操作,请参见通过ASM多主控制面架构实现多集群容灾的步骤一和步骤二。
步骤二:部署入口网关与示例应用
在两个ASM实例中,分别创建名为ingressgateway的ASM入口网关。具体操作,请参见创建入口网关。
在cluster-1和cluster-2集群中,分别部署Bookinfo示例应用。具体操作,请参见在ASM实例关联的集群中部署应用。
在两个ASM实例中,分别为示例应用创建网关规则和虚拟服务,将ASM网关作为Bookinfo应用的流量入口。具体操作,请参见使用Istio资源实现版本流量路由。
为两个ASM实例分别开启全局维度的集群内流量保持功能。具体操作,请参见按照全局开启集群内流量保持功能。
说明在地域级故障容灾的场景下,我们希望流量始终保持在单个集群中。当同一个服务网格实例加入两个及以上的Kubernetes集群时,如果不做任何配置,服务网格的默认负载均衡机制会使服务尝试调用对侧集群对等部署的服务。通过开启ASM集群内流量保持功能,可以将对服务的请求始终保持在集群内,避免出现跨集群调用的情况。
(可选)步骤三:验证服务状态
获取两个ASM网关的公网IP,用于验证服务状态及后续配置GTM。具体操作,请参见获取入口网关地址。
分别使用cluster-1和cluster-2集群的kubeconfig,查看reviews服务的Pod名称。
kubectl get pod| grep reviews预期输出:
reviews-v1-5d99dxxxxx-xxxxx 2/2 Running 0 3d17h reviews-v2-69fbbxxxxx-xxxxx 2/2 Running 0 3d17h reviews-v3-8c44xxxxx-xxxxx 2/2 Running 0 3d17h在浏览器地址栏,依次输入
http://{mesh-1入口网关的IP地址}/productpage和http://{mesh-2入口网关的IP地址}/productpage,并持续刷新页面10次,访问Bookinfo应用。每次刷新都会访问reviews服务的v1、v2或v3版本。您可以看到,两个集群的reviews服务三个版本均与上一步输出的Pod名称一致。即服务运行状态正常,并且集群内流量保持功能已生效。
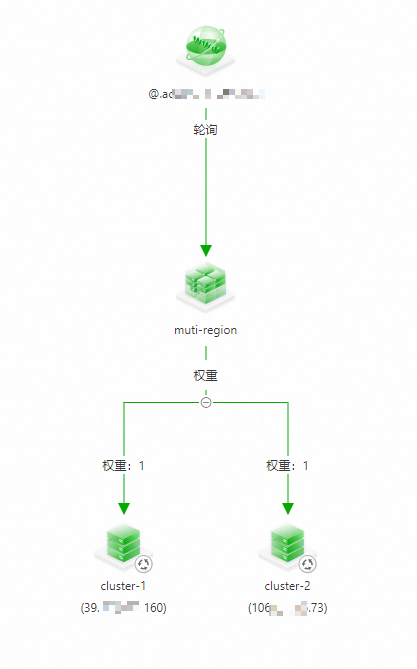
步骤四:配置全局流量管理GTM
将获取的两个公网IP作为应用的流量入口IP,并配置GTM的多活负载和容灾。具体操作,请参见GTM如何实现多活负载并容灾。
配置完成后的效果如下:
(可选)步骤五:配置本地限流和基于限流的观测及告警
使用以下内容,分别为mesh-1和mesh-2配置本地限流规则。具体操作,请参见为入口网关配置本地限流。
apiVersion: istio.alibabacloud.com/v1beta1 kind: ASMLocalRateLimiter metadata: name: ingressgateway namespace: istio-system spec: configs: - limit: fill_interval: seconds: 1 quota: 100 match: vhost: name: '*' port: 80 route: name_match: gw-to-productage isGateway: true workloadSelector: labels: istio: ingressgateway分别为两个ASM实例配置本地限流的指标采集和告警。具体操作,请参见配置本地限流指标采集和告警。
故障演练
本演练使用fortio工具对示例应用进行压测,来模拟外部用户进行访问。压测期间,将通过手动删除入口网关工作负载的方式模拟地域发生故障,以观察容灾转移的效果。
执行以下命令,对示例应用进行五分钟的压测。请将命令中的域名替换为实际在GTM中配置的域名。
fortio load -jitter=False -c 1 -qps 100 -t 300s -keepalive=False -a http://{域名}/productpage在压测进行的同时,以cluster-2为故障集群,模拟地域故障。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
单击命名空间下拉框,选择istio-system。
在工作负载列表中找到istio-ingressgateway,单击操作列的。
等待压测结束,预期输出如下。
# range, mid point, percentile, count >= -261.054 <= -0.0693516 , -130.561 , 100.00, 3899 # target 50% -130.595 WARNING 100.00% of sleep were falling behind Aggregated Function Time : count 3899 avg 0.076910055 +/- 0.02867 min 0.062074583 max 1.079674 sum 299.872304 # range, mid point, percentile, count >= 0.0620746 <= 0.07 , 0.0660373 , 19.34, 754 > 0.07 <= 0.08 , 0.075 , 71.94, 2051 > 0.08 <= 0.09 , 0.085 , 96.08, 941 > 0.09 <= 0.1 , 0.095 , 99.23, 123 > 0.1 <= 0.12 , 0.11 , 99.62, 15 > 0.12 <= 0.14 , 0.13 , 99.82, 8 > 0.14 <= 0.16 , 0.15 , 99.92, 4 > 1 <= 1.07967 , 1.03984 , 100.00, 3 # target 50% 0.0758289 # target 75% 0.0812673 # target 90% 0.0874825 # target 99% 0.0992691 # target 99.9% 0.155505 Error cases : count 527 avg 0.074144883 +/- 0.07572 min 0.062074583 max 1.079674 sum 39.0743532 # range, mid point, percentile, count >= 0.0620746 <= 0.07 , 0.0660373 , 82.54, 435 > 0.07 <= 0.08 , 0.075 , 96.58, 74 > 0.08 <= 0.09 , 0.085 , 99.05, 13 > 0.09 <= 0.1 , 0.095 , 99.24, 1 > 0.12 <= 0.14 , 0.13 , 99.43, 1 > 1 <= 1.07967 , 1.03984 , 100.00, 3 # target 50% 0.0668682 # target 75% 0.0692741 # target 90% 0.0753108 # target 99% 0.0897923 # target 99.9% 1.06568 # Socket and IP used for each connection: [0] 3900 socket used, resolved to [39.XXX.XXX.160:80 (3373), 106.XXX.XXX.73:80 (527)], connection timing : count 3900 avg 0.038202153 +/- 0.03097 min 0.027057 max 1.07747175 sum 148.988395 Connection time histogram (s) : count 3900 avg 0.038202153 +/- 0.03097 min 0.027057 max 1.07747175 sum 148.988395 # range, mid point, percentile, count >= 0.027057 <= 0.03 , 0.0285285 , 13.28, 518 > 0.03 <= 0.035 , 0.0325 , 62.79, 1931 > 0.035 <= 0.04 , 0.0375 , 83.95, 825 > 0.04 <= 0.045 , 0.0425 , 86.13, 85 > 0.045 <= 0.05 , 0.0475 , 86.18, 2 > 0.05 <= 0.06 , 0.055 , 86.28, 4 > 0.06 <= 0.07 , 0.065 , 98.03, 458 > 0.07 <= 0.08 , 0.075 , 99.77, 68 > 0.08 <= 0.09 , 0.085 , 99.92, 6 > 1 <= 1.07747 , 1.03874 , 100.00, 3 # target 50% 0.0337079 # target 75% 0.0378848 # target 90% 0.0631659 # target 99% 0.0755882 # target 99.9% 0.0885 Sockets used: 3900 (for perfect keepalive, would be 1) Uniform: false, Jitter: false, Catchup allowed: true IP addresses distribution: 39.XXX.XXX.160:80: 3373 106.XXX.XXX.73:80: 527 Code -1 : 527 (13.5 %) Code 200 : 3372 (86.5 %) Response Header Sizes : count 3899 avg 178.19851 +/- 70.45 min 0 max 207 sum 694796 Response Body/Total Sizes : count 3899 avg 4477.7081 +/- 1822 min 0 max 5501 sum 17458584 All done 3899 calls (plus 1 warmup) 76.910 ms avg, 13.0 qps可以看到,有少量请求在模拟的地域故障下发生了无法连接的错误,但大部分请求成功。这证明ASM结合GTM有效地对地域级别的故障完成了容灾。
查看GTM中的接入域名状态,可以看到cluster-2的IP地址已经被剔除。
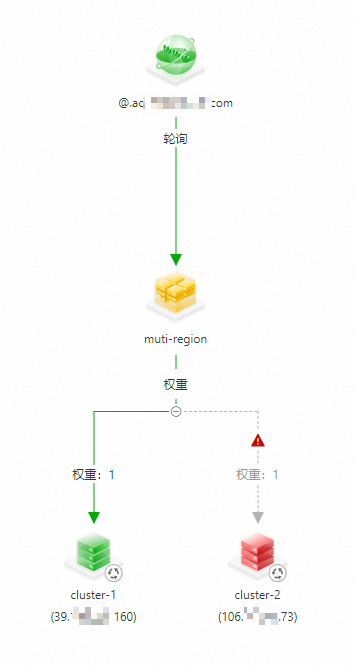
您也可以通过配置告警的方式,在IP不可用时接收告警,并手动剔除不可用的IP地址。具体操作,请参见告警配置。