使用ASM定义应用服务级SLO,可以自动生成Prometheus规则。本文介绍如何将生成的规则导入Prometheus中执行SLO。
前提条件
已在ACK集群安装Prometheus监控。具体操作,请参见开源Prometheus监控和集成自建Prometheus实现网格监控。
步骤一:将规则导入Prometheus
本文采用Prometheus Operator模式部署Prometheus。在此模式下,Prometheus的相关配置由Prometheus定义的相关自定义资源决定。配置Recording Rules和告警规则时,您可以新建Prometheus CR,创建一个具有app: ack-prometheus-operator和release: ack-prometheus-operator标签的PrometheusRule对象。
标签的添加取决于在Prometheus CR中标签选择器
ruleSelector的设置。若ruleSelector为空,可以不添加标签。请您根据实际情况进行调整。不同的Prometheus部署方式,需要采用不同的方法部署生成的Prometheus规则。关于导入Prometheus规则的更多信息,请参见Prometheus。
在容器服务ACK中获取
ruleSelector。登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在资源定义(CustomResourceDefinition)页签,单击PrometheusRule。
在资源对象浏览器页签,命名空间选择monitoring,在ack-prometheus-operator-prometheus右侧的操作列下,单击YAML 编辑。
获取
ruleSelector字段信息。ruleSelector字段示例如下。为了被标签选择器选中,PrometheusRule中需要包含matchLabels中的标签。ruleSelector: matchLabels: app: ack-prometheus-operator release: ack-prometheus-operator
部署Prometheus。
使用以下内容,创建prometheusrule.yaml。
YAML文件中,
labels字段的内容由上一步获取,spec字段的内容为生成的Prometheus规则。apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: app: ack-prometheus-operator release: ack-prometheus-operator name: asm-rules namespace: monitoring spec: # 此处替换为生成的规则文件。在ACK集群中,执行以下命令,部署Prometheus。
kubectl apply -f prometheusrule.yaml
查看Prometheus是否配置成功。
登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在配置项页面上方,选择命名空间为monitoring,在Prometheus配置右侧的操作列下,单击YAML 编辑。
如下图所示,可以看到
PrometheusRule的对应Controller会自动将配置写入ConfigMap中供Prometheus读取。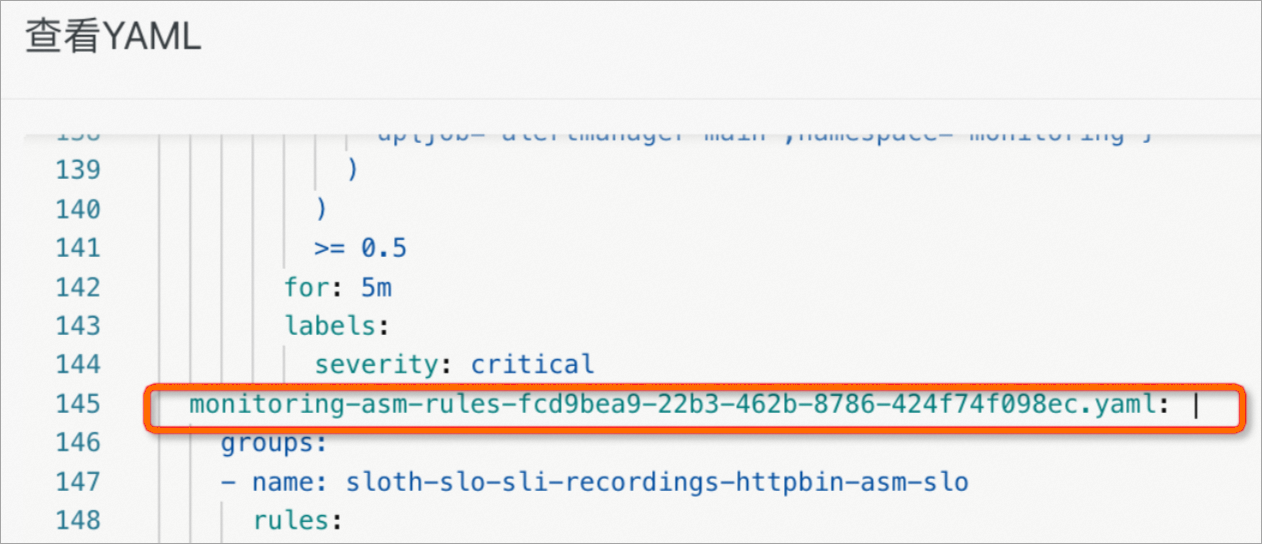
步骤二:执行SLO
查看Prometheus监控数据和告警信息
使用kubectl连接至ACK集群,在命令行执行以下命令,将ack-prometheus-operator-prometheus服务转发到本地端口。
kubectl --namespace monitoring port-forward svc/ack-prometheus-operator-prometheus 9090单击https://localhost:9090,访问Prometheus控制台。
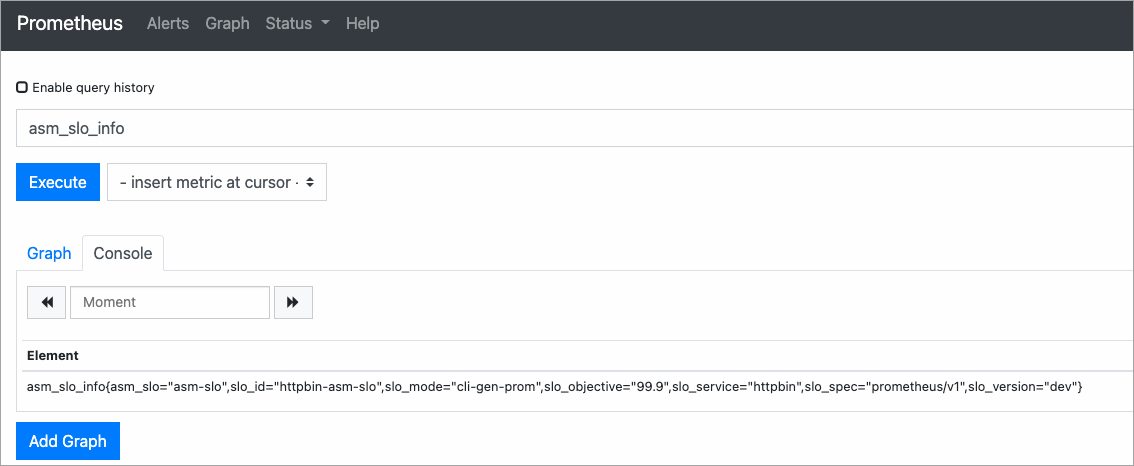
在Prometheus页面的文本框中,输入asm_slo_info,然后单击Execute,查看配置的SLO。
如下图所示,可以看到SLO配置,表示Prometheus Recording Rules配置成功。
在页面上方,单击Alerts,查看告警规则。
存在如下两条规则,表示Prometheus Alerting Rules配置成功。

场景一:模拟正常请求
在命令行执行以下脚本,模拟99.5%成功率的情况下产生的指标。
脚本中的
{网关IP}请替换为实际的网关IP。关于如何获取网关IP,请参见查看网关信息。#!/bin/bash for i in `seq 200` do if (( $i == 100 )) then curl -I http://{网关IP}/status/500; else curl -I http://{网关IP}/; fi echo "OK" sleep 0.01; done;返回Prometheus控制台的Prometheus页面,在文本框中输入slo:period_error_budget_remaining:ratio,然后单击Execute,查看剩余的错误预算的变化。
示例效果如下:
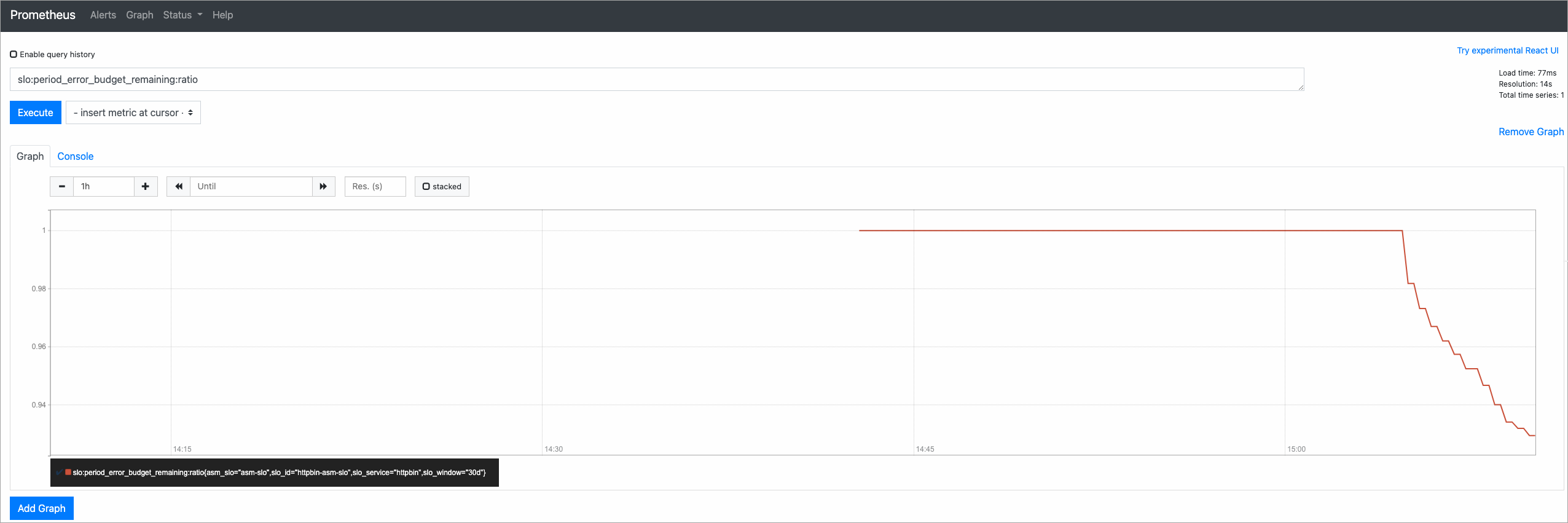
SLO的关键指标说明如下。更多信息,请参见服务等级目标SLO概述。
指标
说明
slo:period_error_budget_remaining:ratio
SLO持续时间(30d)的剩余错误预算。
slo:sli_error:ratio_rate30d
SLO持续时间(30d)内的平均错误率。
slo:period_burn_rate:ratio
SLO持续时间(30d)内的燃烧率。
slo:current_burn_rate:ratio
当前燃烧率。
场景二:模拟异常请求
手动触发故障,测试告警。
在命令行执行以下脚本,模拟请求出错时,50%成功率(燃烧率为50)的情况下产生的指标。
脚本中的
{网关IP}请替换为实际的网关IP。#!/bin/bash for i in `seq 200` do curl -I http://{网关IP}/ curl -I http://{网关IP}/status/500; echo "OK" sleep 0.01; done;返回Prometheus控制台的Alerts页面,查看告警。
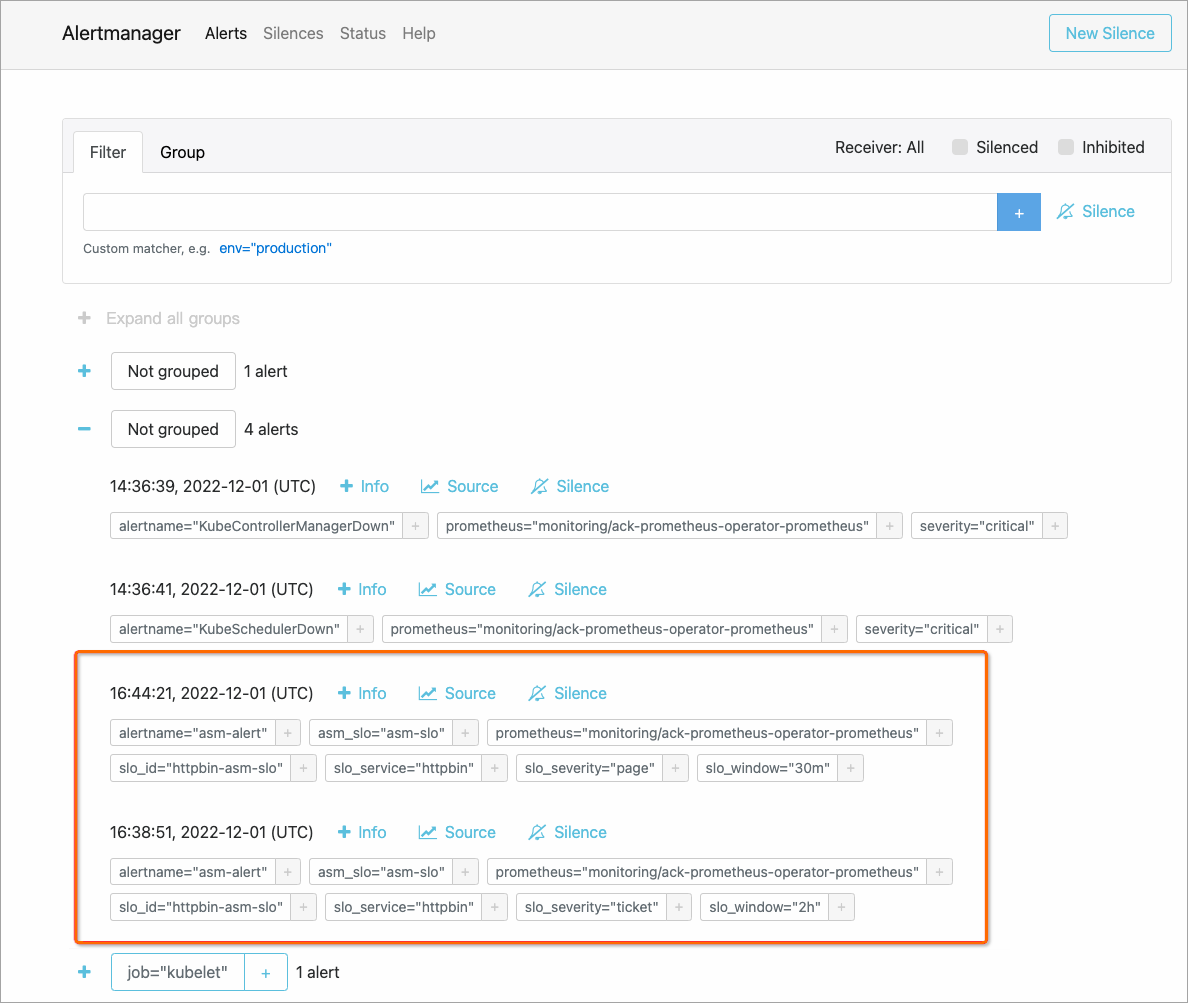
告警触发后的示例效果如下:
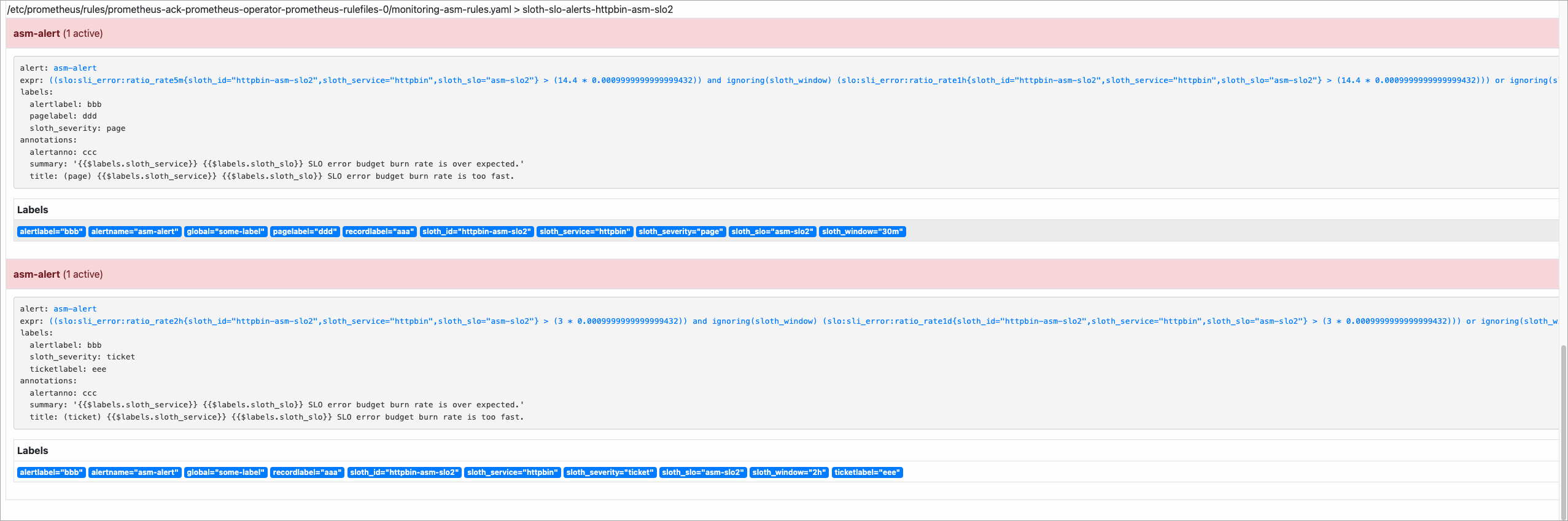
在AlertManager控制台查看告警
在Prometheus框架中,由AlertManager组件负责收集Prometheus Server产生的告警信息,并根据您的配置发送给各个接收者。
执行以下命令,将ack-prometheus-operator-alertmanager服务转发到本地端口。
kubectl --namespace monitoring port-forward svc/ack-prometheus-operator-alertmanager 9093单击https://localhost:9093,访问AlertManager控制台。
在Alertmanager页面,单击
 图标,查看告警。
图标,查看告警。如下图所示,可以看到自定义告警信息采集成功。