
可用区级故障是云上业务可能遭遇的一种较为极端的故障类型。当可用区故障发生时,发生故障的可用区内的工作负载都将面临不可用、不可访问或数据错误等风险。本文介绍通过结合阿里云容器服务 Kubernetes 版 ACK(Container Service for Kubernetes)与阿里云服务网格 ASM(Service Mesh),应对可用区级故障容灾。
背景信息
阿里云托管组件多可用区高可用
ACK集群与ASM所有托管组件均严格采用多副本、多可用区均衡打散的部署策略,确保在单个可用区发生故障时,集群和服务网格控制面仍然能够正常地提供服务。同时,集群内的WorkerNode、弹性容器实例也同样被打散在不同可用区。在发生可用区级别故障时(例如因不可控因素导致的机房断电、断网),健康的可用区仍然能够正常提供服务。
使用集群高可用配置和服务网格来应对应用的可用区级故障
为了应对可用区级别的故障,第一步需要将应用的工作负载均匀地部署在不同的可用区。
ACK支持多可用区(AZ)节点池。在节点池的创建和运行过程中,推荐您为节点池选择多个不同AZ的vSwitch,并在配置扩缩容策略时选择均衡分布策略,允许在伸缩组指定的多可用区(即指定多个专有网络交换机)之间均匀分配ECS实例。进一步,基于节点的弹性伸缩、部署集、多AZ分布等手段,结合K8s调度中的拓扑分布约束(Topology Spread Constraints),可以实现将工作负载均匀部署在不同的可用区。具体细节可参考集群高可用架构推荐配置。
在应用实现多可用区部署后,需要能够在运行时及时有效地了解Kubernetes 应用程序和集群的健康状况,以发现可用区故障的情况,并能快速响应恢复。
服务网格技术可以帮助提高系统的网络可观测性,通过服务网格的数据平面代理可以暴露与网络请求和应用服务交互相关的关键指标,这些指标可以发出各种问题的信号,也包括了特定可用区的监控指标内容等。这些可观测性信息结合可以帮助发现可用区故障的情况。
在可用区级故障发生时,服务网格ASM还支持使用可用区流量转移能力结合负载均衡的可用区流量转移能力来进行容灾:当可用区处于不可用状态时,可以在收到相关告警信息后配置可用区转移,暂时将集群内网络流量从受影响的可用区重定向。当可用区恢复健康状态时,还可以恢复该可用区的流量管理。
容灾架构
当应对可用区级别的故障时,往往涉及到一系列上下相承的实践措施,包括:
在多个可用区中的均匀部署,并在每个可用区进行。
观测服务的相关指标并发现故障。
当可用区发生故障时,快速将流量从受影响可用区切走(通过手动或自动手段),以完成故障恢复,这主要涉及以下方面:
入口切流:确保作为流量入口的负载均衡不再向受影响可用区发送流量
集群内流量转移:确保集群内服务调用不会再将流量发送到受影响可用区
如下图,为应对多可用区级别的故障,需要准备一个具有多可用区worker节点的ACK集群,并在多可用区中均衡地部署工作负载。同时,可以将ACK集群和服务网格ASM实例的控制面日志、集群事件收集至日志服务SLS,并通过ACK集群和服务网格ASM将节点、容器和服务相关指标收集至阿里云可观测监控Prometheus版,以及时观测到不同级别的故障事件、并可以通过日志及Grafana仪表盘查看到集群内的服务状况。同时在使用集群流量入口时,建议使用具有多可用区多活机制的负载均衡作为入口流量承接(如NLB和ALB)。

ASM支持对运行于集群中的服务所发出以及接受的所有请求进行访问日志以及请求指标的持续上报,能够汇总请求相关的响应码、延迟和请求尺寸等相关信息,当可用区中发生灰色故障模式的故障时,服务网格提供的请求相关指标以及相关告警配置对确定故障范围以及故障表现可以形成有意义的参考。本示例将介绍如何查看服务网格上报的服务流量相关指标,有关集群工作负载相关指标及相关告警配置,请参见使用阿里云Prometheus监控、容器服务报警管理和事件监控。
容灾配置实践
本示例将通过创建一个包含多个可用区的集群来演示可用区级别故障的容灾动作。
步骤一:环境准备
创建一个ACK托管集群。在创建集群时,选择来自两个可用区的交换机以支持集群的多可用区。其它配置均保持默认即可,节点池将默认使用均衡分布的扩缩容策略。具体操作,请参见创建ACK托管集群。
创建与ACK集群相同可用区配置的ASM实例。具体操作,请参见创建ASM实例。
部署网关及示例应用。
在ASM实例中创建ASM网关、并绑定一个网络型负载均衡NLB。NLB可用区选择与ASM实例和ACK集群同样的两个可用区(本例中是cn-hangzhou-k和cn-hangzhou-h)。具体操作,请参见在ASM入口网关中使用网络型负载均衡NLB。
说明本例中采用关联网络型负载均衡NLB的ASM网关作为流量入口。您也可以使用应用型负载均衡ALB作为应用的流量入口,ALB同样具备多可用区容灾以及DNS摘除能力。
关闭NLB的跨AZ转发能力,使得每个可用区的NLB都只向自身可用区内的后端进行转发。
为命名空间default开启Sidecar自动注入。具体操作参考管理全局命名空间。
部署示例应用。
以上命令将部署一个包含mocka、mockb、mockc服务的应用,每个服务下包含两个只有1副本的无状态部署,分别通过不同的nodeSelector分布到不同可用区的节点上,并通过配置环境变量来返回自己所在的可用区。
说明出于示例演示直观的目的,本示例中直接使用pod的nodeSelector字段来手动选择pod所在的可用区。在实际高可用环境的构建中,您应该配置拓扑分布约束,来保证pod尽可能分布在不同的可用区中。具体配置方法,请参见工作负载高可用配置。
步骤二:观测服务指标
当故障发生时,与工作负载相关的日志及指标等可观测信息以及相关的告警可以帮助我们尽快发现故障事件、确定故障范围以及初步了解故障影响或理解故障成因。
为请求指标添加可用区维度。
网格代理可以自动检测工作负载部署的可用区,并存储在代理元数据中。我们可以通过编辑指标维度的方法,为服务网格指标添加
locality维度、并将取值设置为xds.node.locality.zone,即工作负载所在可用区。具体操作,请参见可观测配置。向示例应用发送请求,产生请求指标。
watch -n 0.1 curl nlb-xxxxxxxxxxxxx.cn-xxxxxxx.nlb.aliyuncsslb.com/mock -v预期输出:
> GET /mock HTTP/1.1 > Host: nlb-85h289ly4hz9qhaz58.cn-hangzhou.nlb.aliyuncsslb.com > User-Agent: curl/8.7.1 > Accept: */* > * Request completely sent off < HTTP/1.1 200 OK < date: Sun, 08 Dec 2024 11:53:26 GMT < content-length: 150 < content-type: text/plain; charset=utf-8 < x-envoy-upstream-service-time: 5 < server: istio-envoy < * Connection #0 to host nlb-85h289ly4hz9qhaz58.cn-hangzhou.nlb.aliyuncsslb.com left intact -> mocka(version: cn-hangzhou-h, ip: 192.168.122.66)-> mockb(version: cn-hangzhou-k, ip: 192.168.0.47)-> mockc(version: cn-hangzhou-h, ip: 192.168.122.44)%可以看到,请求会随机到两个不同的可用区,说明两个可用区的工作负载都处于可用状态。
持续发送一段时间请求后,在可观测监控Prometheus版中进行指标探索,具体操作,参考指标探索。
查看不同可用区的工作负载请求状态码信息。
在Prometheus实例中,通过以下PromQL,可以查询到指定可用区内的工作负载接收请求的速率,并按照服务名和响应码分组:
sum by(app, response_code) (rate(istio_requests_total{locality="cn-hangzhou-h", reporter="destination"}[$__rate_interval]))预期效果:
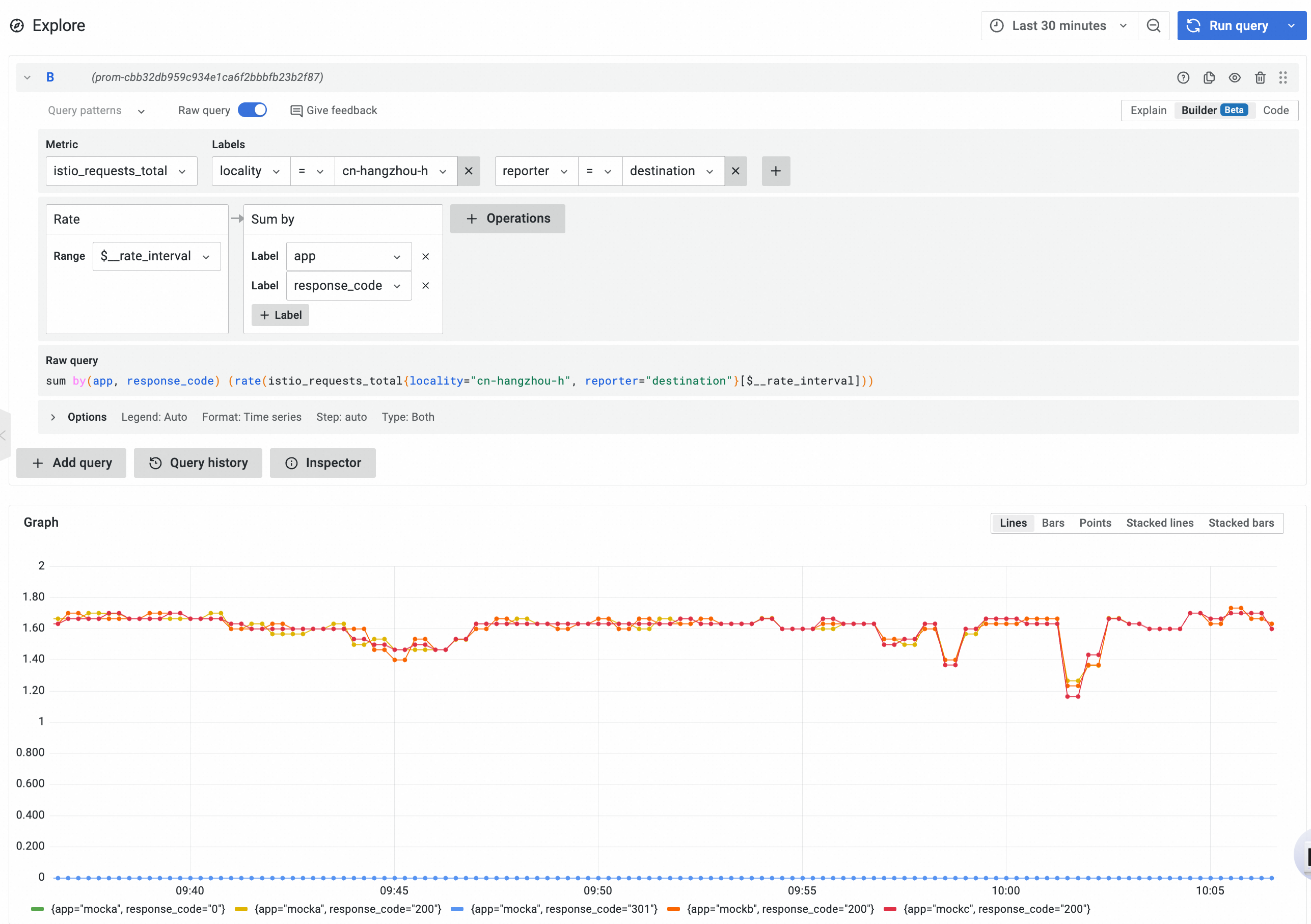
可以看到在均匀部署的情况下,两个可用区接收到的请求速率基本一致。您可以通过将筛选条件变更为
locality="cn-hangzhou-k"查看cn-hangzhou-k可用区下的请求速率及状态码信息。查看不同可用区的工作负载请求延迟信息。
在Prometheus实例中,通过以下PromQL,可以查询到指定可用区内的工作负载接收请求的平均延迟,并按照服务名和响应码分组:
sum by(app, response_code) (rate(istio_request_duration_milliseconds_sum{locality="cn-hangzhou-h", reporter="destination"}[$__rate_interval]))预期效果:
您可以将筛选条件变更为
locality="cn-hangzhou-k"查看cn-hangzhou-k可用区下的平均延迟信息。
基于指标信息配置告警规则。
您可以通过自定义PromQL的方式配置告警信息。当业务的延迟或状态码大于设定值时,为指定联系人发送告警信息。具体操作方式,请参见创建Prometheus告警规则。
基于应用延迟设置告警规则。
通过以下的PromQL来实现针对mockb服务的告警。
sum by(response_code, locality) (rate(istio_request_duration_milliseconds_sum{app="mockb",reporter= "destination"}[1m])) > 3上述PromQL表示当mockb服务1分钟之内的平均延迟在3ms以上时进行告警,告警针对状态码和可用区信息进行分组。
基于服务响应状态码设置告警规则。
通过如下的PromQL来实现针对mocka服务的告警。
sum by (locality, response_code) (rate(istio_requests_total{app="mocka",reporter="destination",response_code!="200"}[1m])) >= 0
您可以通过修改上述两种告警规则的设置方式中的
app="mockb"为其他应用设置告警规则。
步骤三:容灾演练
当ACK集群中的一个可用区不健康或受损并收到告警后,我们可以将该可用区内部署的服务工作负载与其它可用区进行隔离,在保持业务依然正常运行的情况下对故障原因进行详细调查、并在故障恢复时让流量返回到拥有完整容量的可用区。
隔离受影响可用区中的节点。
通过设置污点,禁止新的Pod向可用区内的节点进行调度。设置后,节点将进入不可调度状态,已有Pod仍将留存在节点上、但新的Pod不会在该可用区内再进行调度。具体操作,参考设置节点调度状态。以下以隔离cn-hangzhou-h可用区为例,将cn-hangzhou-h可用区中的节点都标识为不可调度。
转移南北向入口流量。
由于配置了NLB的同可用区转发,当故障发生时,需要使用NLB(或ALB)的DNS摘除能力,快速在入口南北向流量层级切走流量,防止外部流量继续流入故障可用区。
进入NLB控制台,单击ASM网关绑定的NLB实例。
在NLB的实例详情页面,可用区页签下,找到受影响可用区,在右侧操作列中单击DNS摘除,并在弹框中单击确定。进行DNS摘除后,受影响可用区的NLB公网IP将不再出现在域名解析记录中。
转移东西向流量。
通过使用阿里云服务网格ASM的可用区转移能力,可以快速转移集群中的东西向流量走向,防止流量发送到指定可用区的端点。
进入服务网格控制台,单击管理集群的服务网格实例。
在网格详情页面,单击服务发现范围配置。找到展开高级选项,填写Pod所在的地域和可用区信息,并单击确定。
操作后,实例会进入短暂的更新状态。更新完成后,指定可用区内的端点将被排除出服务发现范围。
观察隔离效果。
继续持续访问示例应用,可以发现响应的服务均来自cn-hangzhou-k的服务,说明流量已经完全从cn-hangzhou-h可用区切走。预期输出:
> Host: nlb-xxxxxxxxxxxxxxxxxxx8.cn-hangzhou.nlb.aliyuncsslb.com > User-Agent: curl/8.7.1q > Accept: */* > A * Request completely sent off < HTTP/1.1 200 OKe < date: Tue, 10 Dec 2024 04:03:26 GMT < content-length: 1500 < content-type: text/plain; charset=utf-8 < x-envoy-upstream-service-time: 30 < server: istio-envoyr < s { [150 bytes data] {100 150 100 150 0 0 2262 0 --:--:-- --:--:-- --:--:-- 2238 * Connection #0 to host nlb-xxxxxxxxxxxxxxxxxxx8.cn-hangzhou.nlb.aliyuncsslb.com left intact -> mocka(version: cn-hangzhou-k, ip: 192.168.0.44)-> mockb(version: cn-hangzhou-k, ip: 192.168.0.47)-> mockc(version: cn-hangzhou-k, ip: 192.168.0.46)