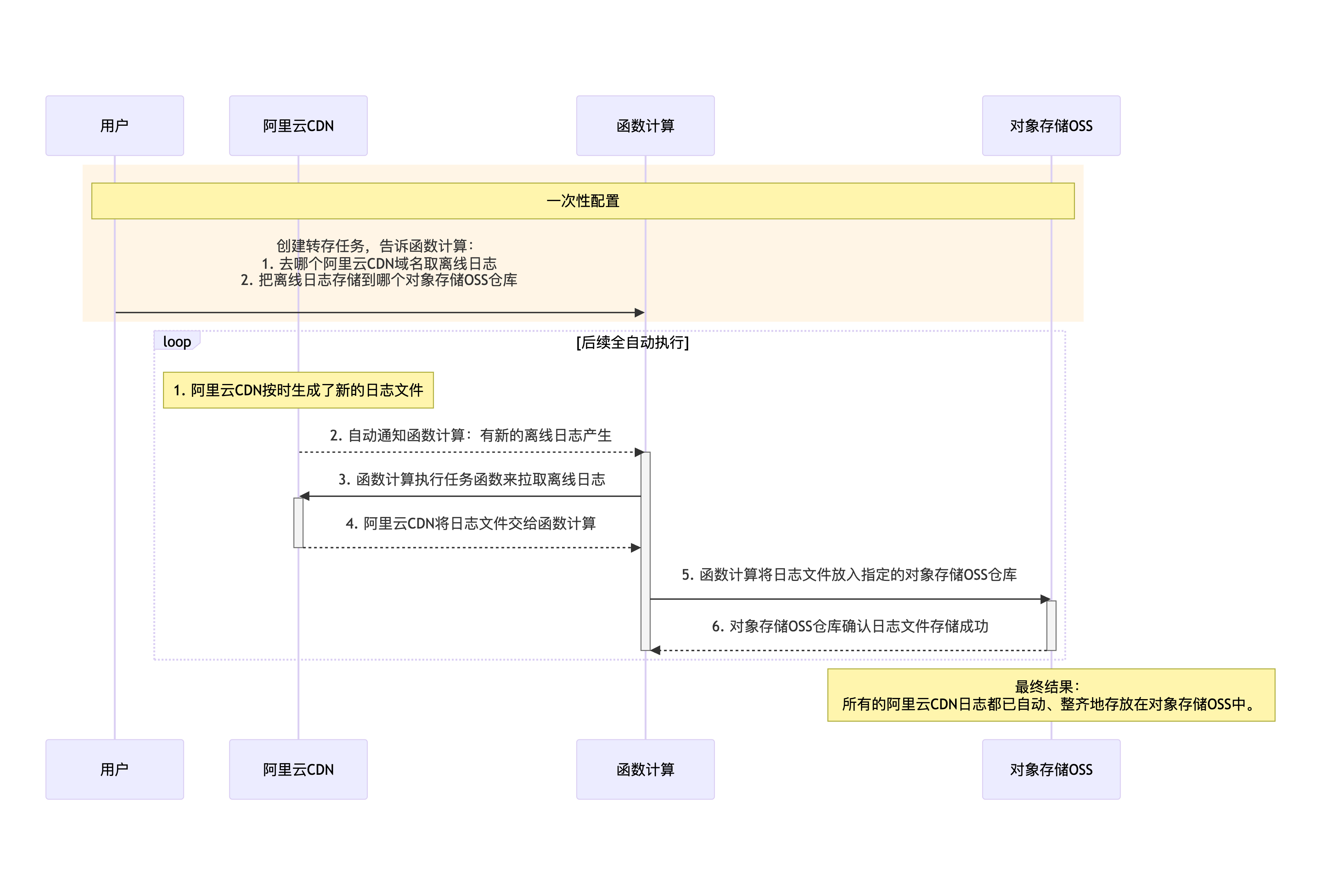
# coding=utf-8
import os, time, json, requests, traceback, oss2, fc2
from requests.exceptions import *
from fc2.fc_exceptions import *
from oss2.models import PartInfo
from oss2.exceptions import *
from multiprocessing import Pool
from contextlib import closing
MAX_PROCCESSES = 20 # 每个子任务中的工作进程数量
BLOCK_SIZE = 6 * 1024 * 1024 # 每个分片的大小
BLOCK_NUM_INTERNAL = 18 # 内部URL情况下每个子任务中的默认块数量
BLOCK_NUM = 10 # 每个子任务中的默认块数量
MAX_SUBTASKS = 49 # 执行子任务的工作进程数量
CHUNK_SIZE = 8 * 1024 # 每个块的大小
SLEEP_TIME = 0.1 # 重试时的初始等待秒数
MAX_RETRY_TIME = 10 # 最大重试次数
def retry(func):
"""
带重试机制的函数执行器。
:param func: (必需, lambda) 要执行的函数。
:return: func的执行结果。
"""
wait_time = SLEEP_TIME
retry_cnt = 1
while True:
if retry_cnt > MAX_RETRY_TIME:
return func()
try:
return func()
except (ConnectionError, SSLError, ConnectTimeout, Timeout) as e:
print(traceback.format_exc())
except (OssError) as e:
if 500 <= e.status < 600:
print(traceback.format_exc())
else:
raise Exception(e)
except (FcError) as e:
if (500 <= e.status_code < 600) or (e.status_code == 429):
print(traceback.format_exc())
else:
raise Exception(e)
print('重试第 %d 次...' % retry_cnt)
time.sleep(wait_time)
wait_time *= 2
retry_cnt += 1
def get_info(url):
"""
获取文件的CRC64和总长度。
:param url: (必需, string) 文件的URL地址。
:return: CRC64, 长度
"""
with retry(lambda : requests.get(url, {}, stream = True)) as r:
return r.headers['x-oss-hash-crc64ecma'], int(r.headers['content-length'])
class Response(object):
"""
支持分块读取的响应类。
"""
def __init__(self, response):
self.response = response
self.status = response.status_code
self.headers = response.headers
def read(self, amt = None):
if amt is None:
content = b''
for chunk in self.response.iter_content(CHUNK_SIZE):
content += chunk
return content
else:
try:
return next(self.response.iter_content(amt))
except StopIteration:
return b''
def __iter__(self):
return self.response.iter_content(CHUNK_SIZE)
def migrate_part(args):
"""
从URL下载一个分片,然后上传到OSS。
:param args: (bucket, object_name, upload_id, part_number, url, st, en)
:bucket: (必需, Bucket) 目标OSS存储桶。
:object_name: (必需, string) 目标对象名。
:upload_id: (必需, integer) 此上传任务的上传ID。
:part_number: (integer) 此分片的分片号。
:url: (必需, string) 文件的URL地址。
:st, en: (必需, integer) 此分片的字节范围,表示[st, en]。
:return: (part_number, etag)
:part_number: (integer) 此分片的分片号。
:etag: (string) upload_part结果的etag。
"""
bucket = args[0]
object_name = args[1]
upload_id = args[2]
part_number = args[3]
url = args[4]
st = args[5]
en = args[6]
try:
headers = {'Range' : 'bytes=%d-%d' % (st, en)}
resp = Response(retry(lambda : requests.get(url, headers = headers, stream = True)))
result = retry(lambda : bucket.upload_part(object_name, upload_id, part_number, resp))
return (part_number, result.etag)
except Exception as e:
print(traceback.format_exc())
raise Exception(e)
def do_subtask(event, context):
"""
从URL下载文件的一个范围,然后上传到OSS。
:param event: (必需, json) 事件的JSON格式。
:param context: (必需, FCContext) 处理器的上下文。
:return: parts
:parts: ([(integer, string)]) 每个进程的分片号和etag。
"""
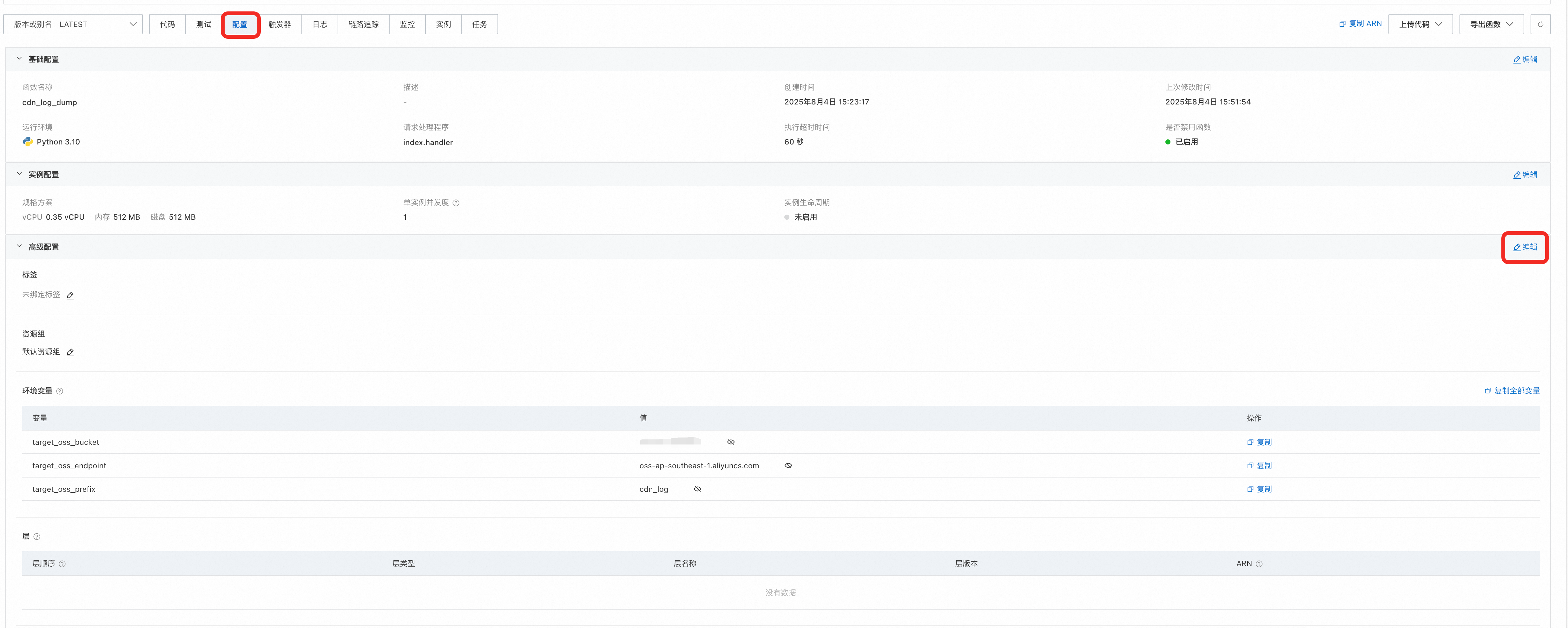
oss_endpoint = os.environ.get('target_oss_endpoint')
oss_bucket_name = os.environ.get('target_oss_bucket')
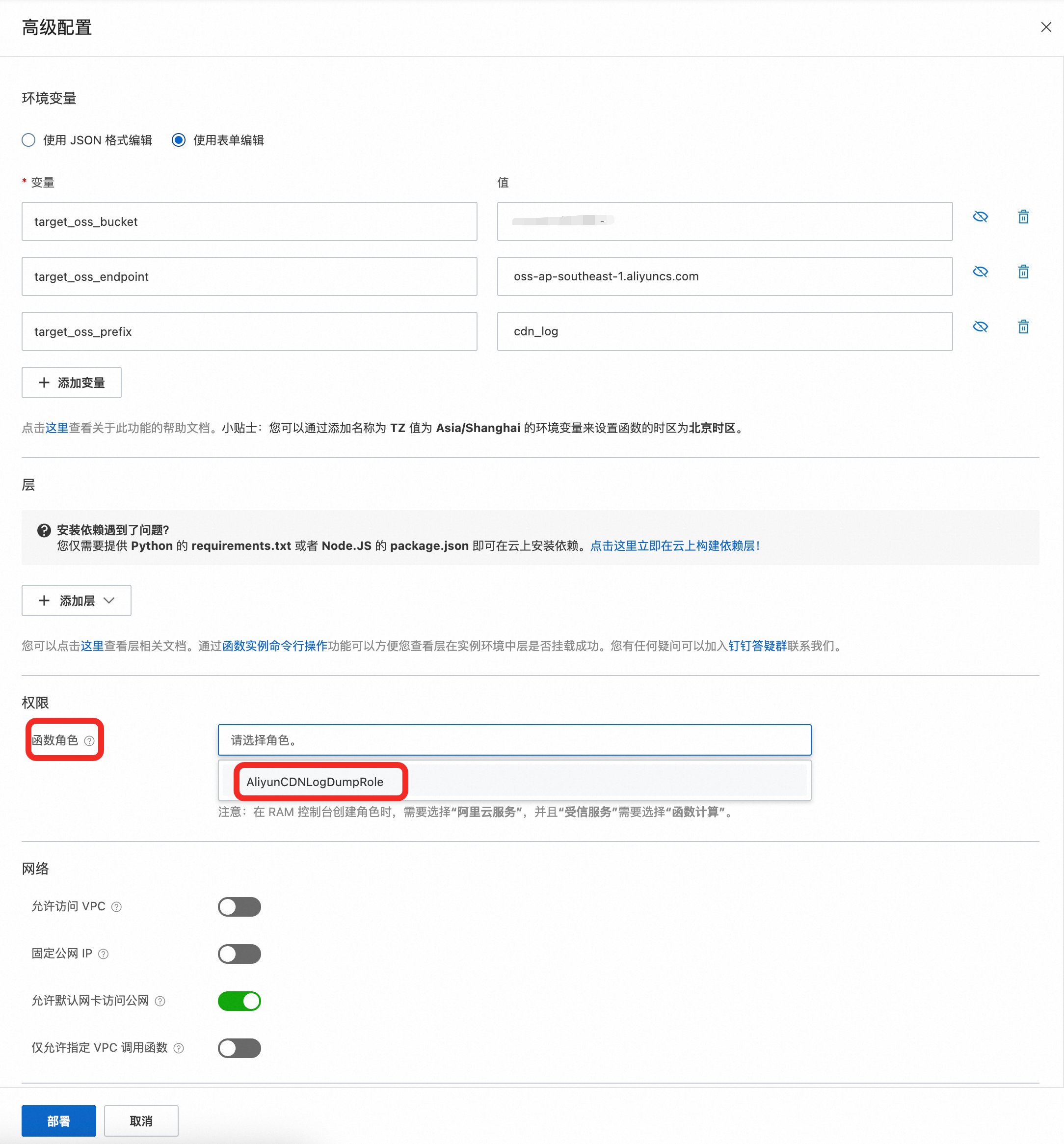
access_key_id = context.credentials.access_key_id
access_key_secret = context.credentials.access_key_secret
security_token = context.credentials.security_token
auth = oss2.StsAuth(access_key_id, access_key_secret, security_token)
bucket = oss2.Bucket(auth, oss_endpoint, oss_bucket_name)
object_name = event['object_name']
upload_id = event['upload_id']
part_number = event['part_number']
url = event['url']
st = event['st']
en = event['en']
if part_number == 1:
return [migrate_part((bucket, object_name, upload_id, part_number, url, st, en))]
pool = Pool(MAX_PROCCESSES)
tasks = []
while st <= en:
nxt = min(en, st + BLOCK_SIZE - 1)
tasks.append((bucket, object_name, upload_id, part_number, url, st, nxt))
part_number += 1
st = nxt + 1
parts = pool.map(migrate_part, tasks)
pool.close()
pool.join()
return parts
def invoke_subtask(args):
"""
同步调用同一个函数来启动子任务。
:param args: (object_name, upload_id, part_number, url, st, en, context)
:object_name: (必需, string) 目标对象名。
:upload_id: (必需, integer) 此上传任务的上传ID。
:part_number: (integer) 此子任务中第一个分片的分片号。
:url: (必需, string) 文件的URL地址。
:st, en: (必需, integer) 此子任务的字节范围,表示[st, en]。
:context: (必需, FCContext) 处理器的上下文。
:return: 被调用函数的返回值。
"""
object_name = args[0]
upload_id = args[1]
part_number = args[2]
url = args[3]
st = args[4]
en = args[5]
context = args[6]
account_id = context.account_id
access_key_id = context.credentials.access_key_id
access_key_secret = context.credentials.access_key_secret
security_token = context.credentials.security_token
region = context.region
service_name = context.service.name
function_name = context.function.name
endpoint = 'http://%s.%s-internal.fc.aliyuncs.com' % (account_id, region)
client = fc2.Client(
endpoint = endpoint,
accessKeyID = access_key_id,
accessKeySecret = access_key_secret,
securityToken = security_token
)
payload = {
'object_name' : object_name,
'upload_id' : upload_id,
'part_number' : part_number,
'url' : url,
'st' : st,
'en' : en,
'is_children' : True
}
if part_number == 1:
return json.dumps(do_subtask(payload, context))
ret = retry(lambda : client.invoke_function(service_name, function_name, payload = json.dumps(payload)))
return ret.data
def divide(n, m):
"""
不使用浮点运算计算ceil(n / m)。
:param n, m: (integer)
:return: (integer) ceil(n / m)。
"""
ret = n // m
if n % m > 0:
ret += 1
return ret
def migrate_file(url, oss_object_name, context):
"""
从URL下载文件,然后上传到OSS。
:param url: (必需, string) 文件的URL地址。
:param oss_object_name: (必需, string) 目标对象名。
:param context: (必需, FCContext) 处理器的上下文。
:return: actual_crc64, expect_crc64
:actual_crc64: (string) 上传的CRC64。
:expect_crc64: (string) 源文件的CRC64。
"""
crc64, total_size = get_info(url)
oss_endpoint = os.environ.get('target_oss_endpoint')
oss_bucket_name = os.environ.get('target_oss_bucket')
access_key_id = context.credentials.access_key_id
access_key_secret = context.credentials.access_key_secret
security_token = context.credentials.security_token
auth = oss2.StsAuth(access_key_id, access_key_secret, security_token)
bucket = oss2.Bucket(auth, oss_endpoint, oss_bucket_name)
upload_id = retry(lambda : bucket.init_multipart_upload(oss_object_name)).upload_id
pool = Pool(MAX_SUBTASKS)
st = 0
part_number = 1
tasks = []
block_num = BLOCK_NUM_INTERNAL if '-internal.aliyuncs.com' in oss_endpoint else BLOCK_NUM
block_num = min(block_num, divide(divide(total_size, BLOCK_SIZE), MAX_SUBTASKS + 1))
while st < total_size:
en = min(total_size - 1, st + block_num * BLOCK_SIZE - 1)
tasks.append((oss_object_name, upload_id, part_number, url, st, en, context))
size = en - st + 1
cnt = divide(size, BLOCK_SIZE)
part_number += cnt
st = en + 1
subtasks = pool.map(invoke_subtask, tasks)
pool.close()
pool.join()
parts = []
for it in subtasks:
for part in json.loads(it):
parts.append(PartInfo(part[0], part[1]))
res = retry(lambda : bucket.complete_multipart_upload(oss_object_name, upload_id, parts))
return str(res.crc), str(crc64)
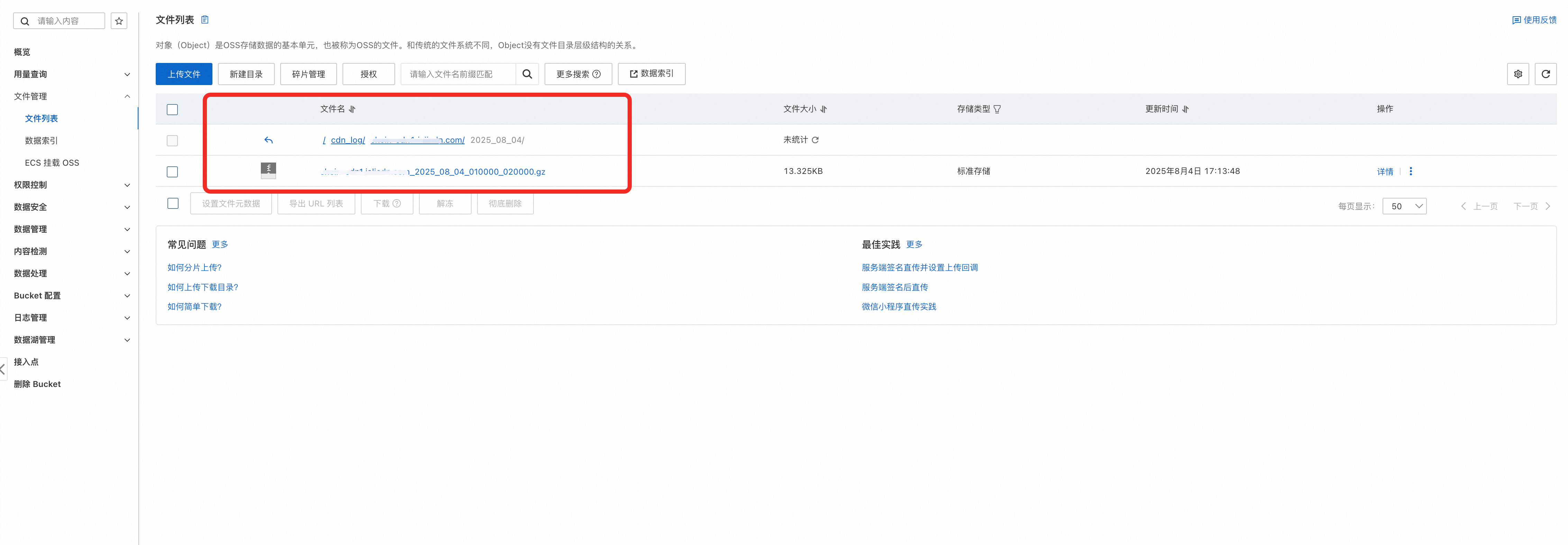
def get_oss_object_name(url):
"""
获取OSS对象名。
:param url: (必需, string) 文件的URL地址。
:return: (string) OSS对象名。
"""
prefix = os.environ.get('target_oss_prefix')
tmps = url.split('?')
if len(tmps) != 2:
raise Exception('无效的URL: %s' % url)
urlObject = tmps[0]
if urlObject.count('/') < 3:
raise Exception('无效的URL: %s' % url)
objectParts = urlObject.split('/')
objectParts = [prefix] + objectParts[len(objectParts) - 3 : len(objectParts)]
return '/'.join(objectParts)
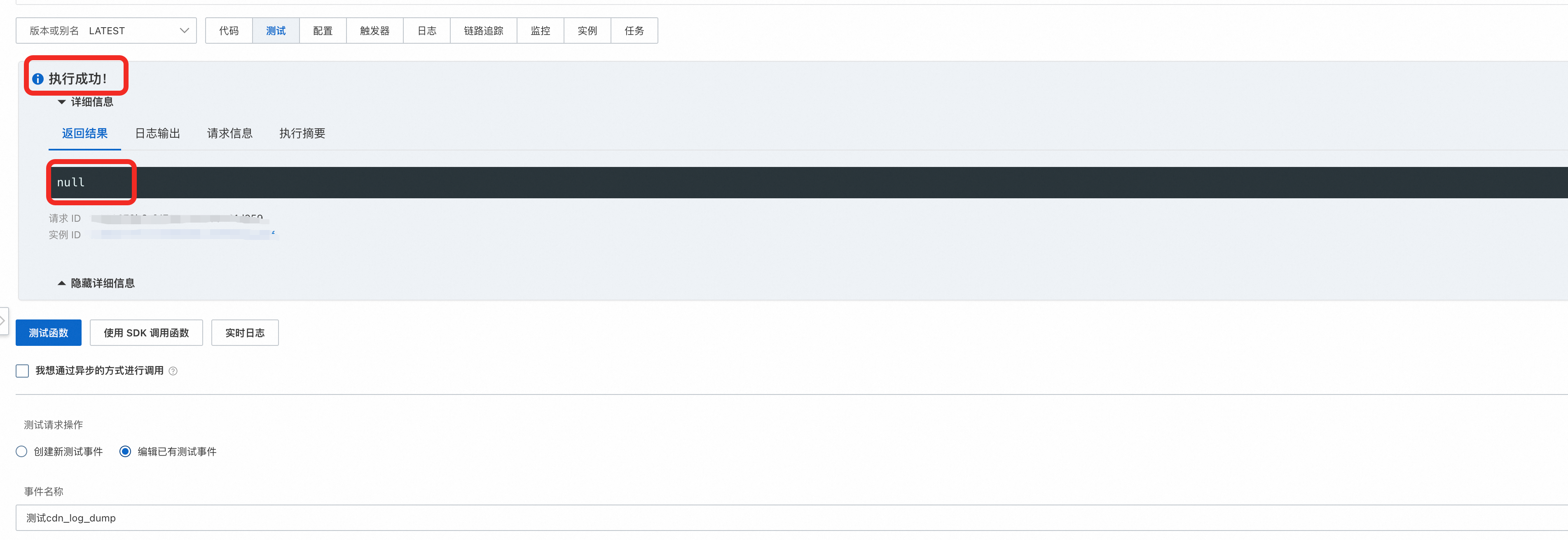
def handler(event, context):
evt = json.loads(event)
if list(evt.keys()).count('is_children'):
return json.dumps(do_subtask(evt, context))
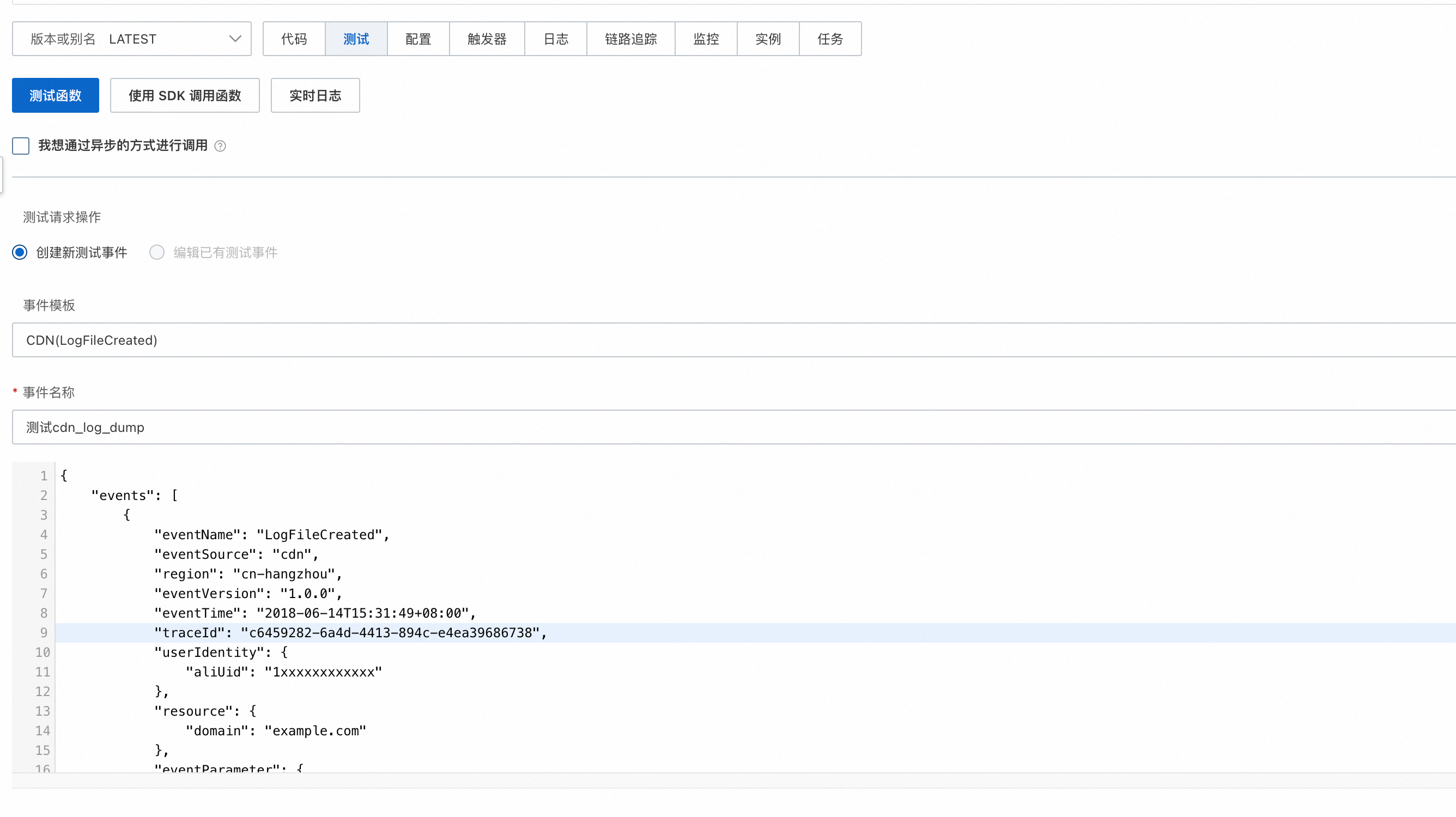
url = evt['events'][0]['eventParameter']['filePath']
if not (url.startswith('http://') or url.startswith('https://')):
url = 'https://' + url
oss_object_name = get_oss_object_name(url)
st_time = int(time.time())
wait_time = SLEEP_TIME
retry_cnt = 1
while True:
actual_crc64, expect_crc64 = migrate_file(url, oss_object_name, context)
if actual_crc64 == expect_crc64:
break
print('迁移对象CRC64不匹配,期望值: %s,实际值: %s' % (expect_crc64, actual_crc64))
if retry_cnt > MAX_RETRY_TIME:
raise Exception('超过最大重试次数。')
print('重试第 %d 次...' % retry_cnt)
time.sleep(wait_time)
wait_time *= 2
retry_cnt += 1
print('成功!总耗时: %d 秒。' % (int(time.time()) - st_time))