
初始化Kerberos环境
更新时间:
复制为 MD 格式
本章节将为您介绍初始化Kerberos环境的步骤。
开始,在没有权限的情况下,执行以下命令
[root@cdp-utility-1 ~]# hdfs dfs -ls /
使用fayson用户运行MapReduce任务及操作Hive,需要在集群所有节点创建fayson用户.
使用kadmin创建一个fayson的principal
[root@cdp-utility-1 30-hdfs-JOURNALNODE]# kadmin.local Authenticating as principal root/admin@BDPHTSEC.COM with password. kadmin.local: addprinc fayson WARNING: no policy specified for fayson@BDPHTSEC.COM; defaulting to no policy Enter password for principal "fayson@BDPHTSEC.COM": Re-enter password for principal "fayson@BDPHTSEC.COM": Principal "fayson@BDPHTSEC.COM" created. kadmin.local: exit
在所有的节点添加用户fayson用户
useradd -p `openssl passwd -1 -salt 'cloudera' cloudera` fayson在/var/run/cloudera-scm-agent/process/下对应的角色目录下,找每个角色前ID最大的,这是当前存活的会话可以找到对应的keytab。
ls /var/run/cloudera-scm-agent/process/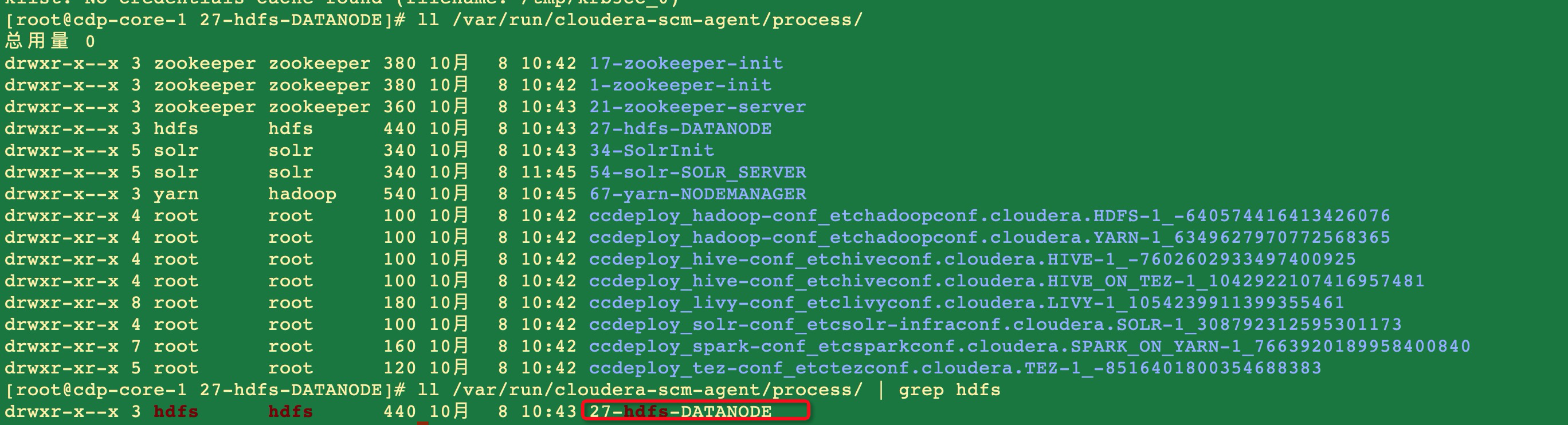
进入到hdfs的最新目录
cd /var/run/cloudera-scm-agent/process/108-hdfs-DATANODE/
查看hdfs.keytab认证的kdc
klist -kt hdfs.keytab
执行kinit授权hdfs的访问权限
[root@cdp-utility-1 30-hdfs-JOURNALNODE]# kinit -kt hdfs.keytab hdfs/cdp-core-1.c-5dbff5ef49a94c09.cn-hangzhou.cdp.aliyuncs.com@BDPHTSEC.COM [root@cdp-utility-1 30-hdfs-JOURNALNODE]# hdfs dfs -mkdir /user/fayson [root@cdp-utility-1 30-hdfs-JOURNALNODE]# hdfs dfs -chown -R fayson:fayson /user/fayson [root@cdp-utility-1 30-hdfs-JOURNALNODE]# kdestroy [root@cdp-utility-1 30-hdfs-JOURNALNODE]# kinit fayson执行Hadoop作业
hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 1[root@cdp-utility-1 30-hdfs-JOURNALNODE]# hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 1 WARNING: Use "yarn jar" to launch YARN applications. Number of Maps = 10 Samples per Map = 1 Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Wrote input for Map #5 Wrote input for Map #6 Wrote input for Map #7 Wrote input for Map #8 Wrote input for Map #9 Starting Job 21/09/06 16:47:39 INFO hdfs.DFSClient: Created token for fayson: HDFS_DELEGATION_TOKEN owner=fayson@BDPHTSEC.COM, renewer=yarn, realUser=, issueDate=1630918059144, maxDate=1631522859144, sequenceNumber=4, masterKeyId=2 on ha-hdfs:CDP-1 21/09/06 16:47:39 INFO security.TokenCache: Got dt for hdfs://CDP-1; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:CDP-1, Ident: (token for fayson: HDFS_DELEGATION_TOKEN owner=fayson@BDPHTSEC.COM, renewer=yarn, realUser=, issueDate=1630918059144, maxDate=1631522859144, sequenceNumber=4, masterKeyId=2) 21/09/06 16:47:39 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /user/fayson/.staging/job_1630916463023_0003 21/09/06 16:47:39 INFO input.FileInputFormat: Total input files to process : 10 21/09/06 16:47:39 INFO mapreduce.JobSubmitter: number of splits:10 21/09/06 16:47:39 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1630916463023_0003 21/09/06 16:47:39 INFO mapreduce.JobSubmitter: Executing with tokens: [Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:CDP-1, Ident: (token for fayson: HDFS_DELEGATION_TOKEN owner=fayson@BDPHTSEC.COM, renewer=yarn, realUser=, issueDate=1630918059144, maxDate=1631522859144, sequenceNumber=4, masterKeyId=2)] 21/09/06 16:47:39 INFO conf.Configuration: resource-types.xml not found 21/09/06 16:47:39 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 21/09/06 16:47:40 INFO impl.YarnClientImpl: Submitted application application_1630916463023_0003 21/09/06 16:47:40 INFO mapreduce.Job: The url to track the job: http://cdp-master-1.c-977b427fe38547eb:8088/proxy/application_1630916463023_0003/ 21/09/06 16:47:40 INFO mapreduce.Job: Running job: job_1630916463023_0003 21/09/06 16:47:51 INFO mapreduce.Job: Job job_1630916463023_0003 running in uber mode : false 21/09/06 16:47:51 INFO mapreduce.Job: map 0% reduce 0% 21/09/06 16:47:59 INFO mapreduce.Job: map 10% reduce 0% 21/09/06 16:48:00 INFO mapreduce.Job: map 20% reduce 0% 21/09/06 16:48:02 INFO mapreduce.Job: map 50% reduce 0% 21/09/06 16:48:03 INFO mapreduce.Job: map 80% reduce 0% 21/09/06 16:48:04 INFO mapreduce.Job: map 90% reduce 0% 21/09/06 16:48:05 INFO mapreduce.Job: map 100% reduce 0% 21/09/06 16:48:09 INFO mapreduce.Job: map 100% reduce 100% 21/09/06 16:48:09 INFO mapreduce.Job: Job job_1630916463023_0003 completed successfully 21/09/06 16:48:09 INFO mapreduce.Job: Counters: 55 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=2798786 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2570 HDFS: Number of bytes written=215 HDFS: Number of read operations=45 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=9 Rack-local map tasks=1 Total time spent by all maps in occupied slots (ms)=77868 Total time spent by all reduces in occupied slots (ms)=2759 Total time spent by all map tasks (ms)=77868 Total time spent by all reduce tasks (ms)=2759 Total vcore-milliseconds taken by all map tasks=77868 Total vcore-milliseconds taken by all reduce tasks=2759 Total megabyte-milliseconds taken by all map tasks=79736832 Total megabyte-milliseconds taken by all reduce tasks=2825216 Map-Reduce Framework Map input records=10 Map output records=20 Map output bytes=180 Map output materialized bytes=331 Input split bytes=1390 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=331 Reduce input records=20 Reduce output records=0 Spilled Records=40 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=1181 CPU time spent (ms)=8630 Physical memory (bytes) snapshot=5137514496 Virtual memory (bytes) snapshot=31019487232 Total committed heap usage (bytes)=5140643840 Peak Map Physical memory (bytes)=539742208 Peak Map Virtual memory (bytes)=2822160384 Peak Reduce Physical memory (bytes)=216817664 Peak Reduce Virtual memory (bytes)=2832429056 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1180 File Output Format Counters Bytes Written=97 Job Finished in 30.961 seconds Estimated value of Pi is 3.60000000000000000000
该文章对您有帮助吗?