
本文为您深度解析产生Too many parts错误的原因以及解决方案。
了解data part
基础概念
ClickHouse中的表,是由主键排序后的data part组成(默认情况下,在创建表时按ORDER BY子句排序)。
每个
data part都有自己的primary key index,以实现高效的扫描和定位数据在data part中的位置。当数据被插入到一个表中时,会创建单独的
data part,每个data part都按主键的字典顺序排序。例如,如果主键是 Date类型的CounterID,则
data part中的数据首先按CounterID排序,然后在每个CounterID值内按Date排序。ClickHouse合并
data part以实现更高效的存储,类似于Log-structured merge tree。当data part合并时,primary索引也会合并。
数据合并(Merge)机制
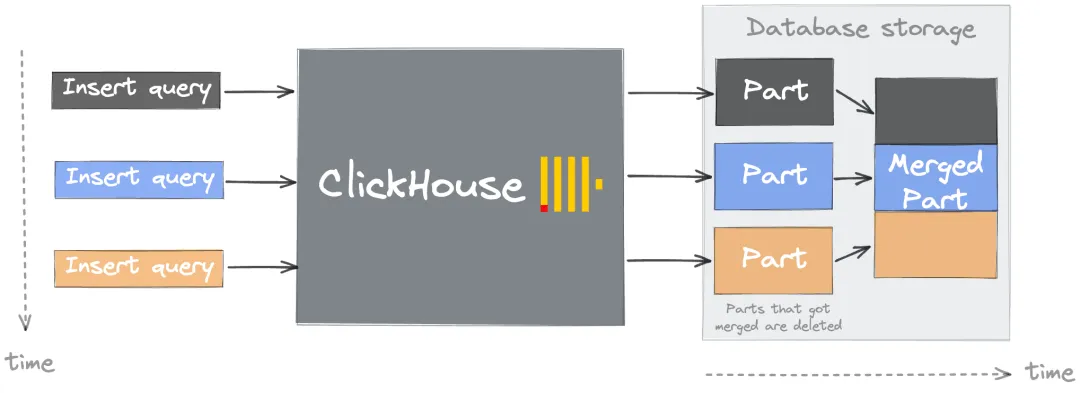
以上为ClickHouse数据合并(Merge)机制的大致流程图。
合并的触发:随着数据插入,Part 会逐渐增多。ClickHouse通过后台进程Merge Tree自动合并小的
data part到更大的data part,减少查询时需要扫描的data part数量。合并过程:
有序合并:合并时,系统会读取多个小
data part的数据,并按主键顺序依次写入新data part,确保合并后的data part仍保持有序。无需重新排序:由于每个参与合并的
data part已按主键有序,合并过程只需线性扫描并逐行写入,无需额外排序。压缩与优化:合并后的数据可能具有更好的压缩率(如相同值集中),进一步优化存储和查询效率。
合并策略:
合并的触发条件包括
data part的大小、数量、年龄等,具体控制触发的参数,请参见mergetree相关参数。合并会优先处理较旧的
data part,以此降低因频繁合并新插入数据而产生的资源争用。
data part太多的后果
查询性能下降:需扫描更多索引和文件,增加I/O开销,导致查询变慢。
启动延迟:大量
data part可能延长元数据加载时间,导致启动变慢。合并负担加重:系统需频繁合并
data part以维持高效查询,合并虽并行执行,但配置不当(如超出parts_to_throw_insert或max_parts_in_total限制)可能导致性能进一步恶化。配置妥协风险:为容纳过多
data part需调整参数(parts_to_throw_insert和max_parts_in_total),但会牺牲查询效率,反映使用方式存在问题。ClickHouse Keeper压力:大量
data part增加元数据管理负担,加剧Keeper负载。
分析及解决方案
以下为产生Too many parts错误的主要原因和解决方案。
原因一:选择不当的分区键
一个常见的原因是建表时使用有过多基数(cardinality)的列作为分区键。
分区键的特点如下:
在创建表时,用户可以指定一个列作为分区键,按该键来分隔数据。
每一个键值都会创建一个新的文件目录。
使用分区键是一个数据管理技巧,允许您在表中逻辑划分数据。
例如,按天进行分区后,DROP PARTITION这样的操作允许快速删除数据子集。
为什么过多基数(cardinality)的列作为分区键会导致Too many parts错误?
分区键主要功能就是允许用户在表中地逻辑分隔数据。然而,这个功能很容易被误用。因为数据通过分区键逻辑隔离后,会被存储在每个分区键创建的文件中,这种情况下,不同分区的data part将不会合并。
例如,如果选择一个高基数的列date_time_ms(DATETIME类型)作为分区键,那么分散在成千上万个文件夹中的parts永远不会是合并的候选对象,一直到超过预配置的限制,并在后续的插入中引发"Too many inactive parts (N). Parts cleaning are processing significantly slower than inserts"错误。
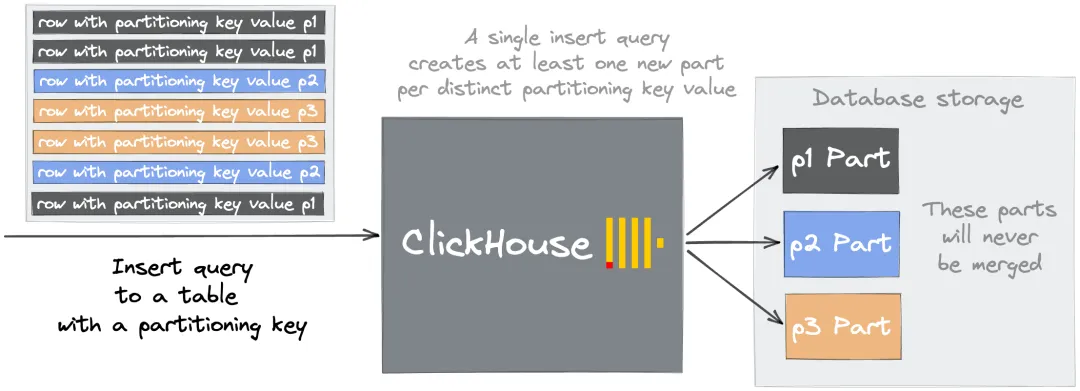
解决方案
面对上述问题,解决方案很简单,即选择一个基数 < 1000 的合理分区键。
原因二:许多小批量插入
除了分区键选择不恰当以外,这个问题也可能是由于许多小批量的插入所造成的。因为每次向ClickHouse中插入数据都会创建单独的data part。
解决方案
为了保持data part的数量在可管理的范围内,您可采用以下方案进行处理。
同步批量插入:您需在客户端缓存数据并批量插入数据。理想情况下,每次插入至少1000行。
异步批量插入:
本地缓存:如果客户端无法缓存,您可通过ClickHouse异步插入实现。在这种情况下,ClickHouse将在本地缓存插入的数据,随后再插入到底层表中。
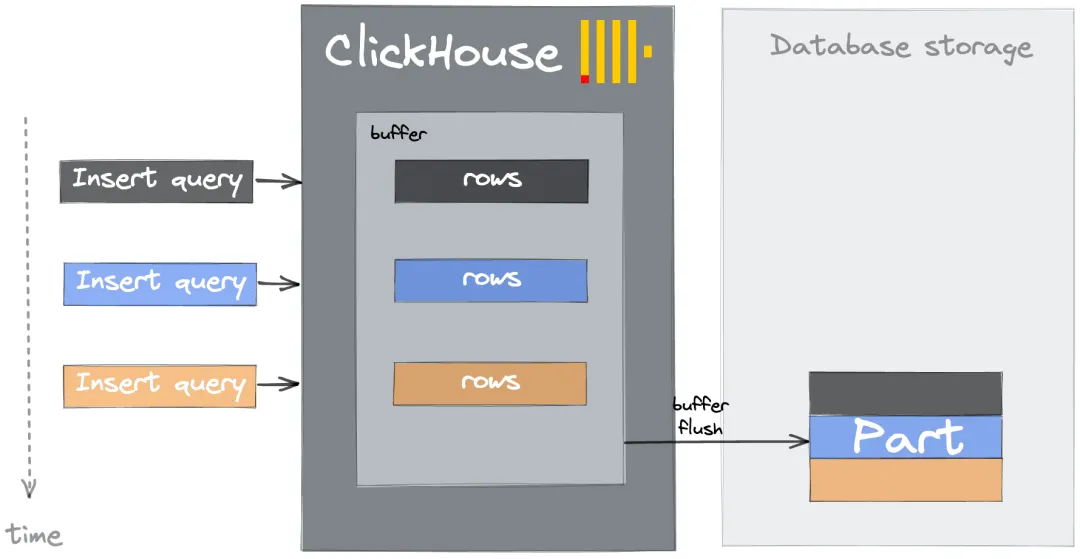
buffer表缓存:buffer表可将数据暂存在内存缓冲区中,随后定期批量写入到目标表。也可减少小批量插入导致的频繁写入和过多的
parts。但其也有优缺点。优点:相对本地缓存,buffer表缓存有一定优势。即数据在缓冲区中时可查询,并且buffer表缓存与物化视图的目标表的缓冲区兼容。
缺点:Buffer表缓存处理失败的能力较差,因为数据会在内存中保持插入,直到发生刷新。
下图为buffer表处理数据的大概流程。
原因三:过多的物化视图
其他可能原因是过多的物化视图导致太多data part。分析如下。
当数据写入物化视图中SELECT子句所指定的源表时,插入的数据会通过SELECT子句查询进行转换并将最终结果插入到物化视图中。若源表频繁插入小批量数据(如每秒几次),每个物化视图会持续生成大量小data part。从而导致过多的data part。如下图所示:
表T对应的有2个物化视图MV-1和MV-2,当T有一条数据插入时,T表会产生一个data part,物化视图MV-1会产生一个data part,物化视图MV-2也会产生一个data part。
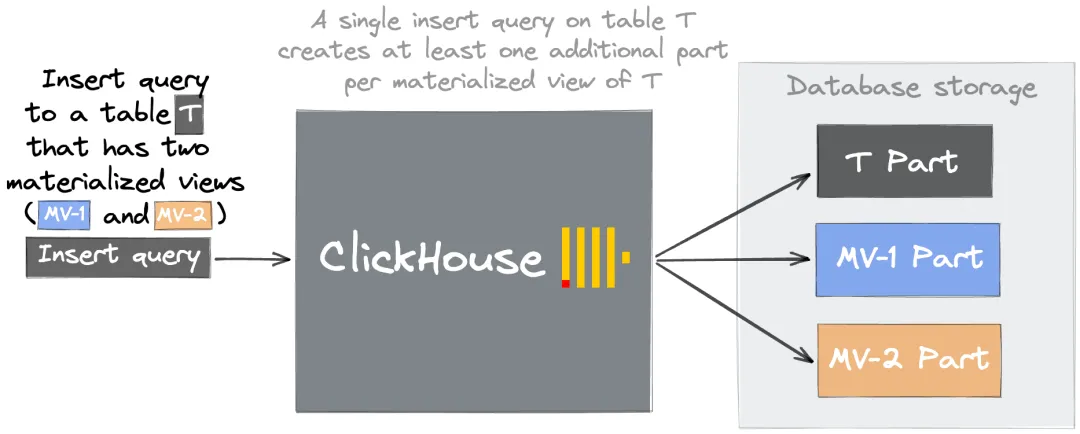
除了上述原因,视图表未设置合理的 ORDER BY 或 PARTITION BY,可导致data part无法合并。进而导致data part过多。关于物化视图的更多注意事项,请参见创建物化视图。
解决方案
优化物化视图设计:
合理设置分区与主键:合理的
ORDER BY或PARTITION BY。避免高基数分区键:高基数分区键(如DATETIME类型的列作为分区键)会导致
data part分散,无法合并。
减少冗余视图:
合并同类视图:若多个视图执行相似的聚合逻辑,可整合为一个视图并统一输出结果。
评估必要性:删除不常用的物化视图,或改用轻量级查询替代预计算。
原因四:mutation之痛
此外,mutation也可能引起data part的积累。更多详情,请参见Mutation之痛。