大数据生产与迁移过程中,需要检查集成源端与目标端、迁移两端集群数据的一致性,湖仓迁移中心提供数据校验服务,可服务于数据集成、数据迁移、任务改造正确性验证、业务双跑、割接前准备等广泛场景。
1.支持的大数据产品与校验模式
湖仓迁移中心(LHM)支持在多种主流大数据产品之间进行数据一致性校验。
大数据产品 | 校验模式 |
Hive | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
MaxCompute | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
ClickHouse | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
Hologres | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
Synapse | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
Databricks | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
StarRocks | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
Doris | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
Redshift | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
MySQL | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
Athena | 行数校验 (Count比对)、聚合指标校验 (指标比对)、内容一致性校验 (弱内容比对) |
2.前置工作
2.1 开通DataWorks资源组并绑定
由于湖仓迁移中心数据校验任务的比对计算部分依赖DataWorks资源组,需要提前开通。前往DataWorks资源组页面,进行"创建资源组"操作,付费模式选择"按量付费"即可。
DataWorks资源组管理页面: https://dataworks.console.aliyun.com/resource/list,点击 即可前往。
即可前往。
点击"创建资源组"完成资源组的购买。购买完成后需要进行网络配置,点击右侧"网络设置",在"数据调度 & 数据集成"一栏如果尚未将资源组和待校验的集群vpc网络进行绑定的话,需要在此处进行网络绑定,以便后续数据校验等服务的网络联通正常。

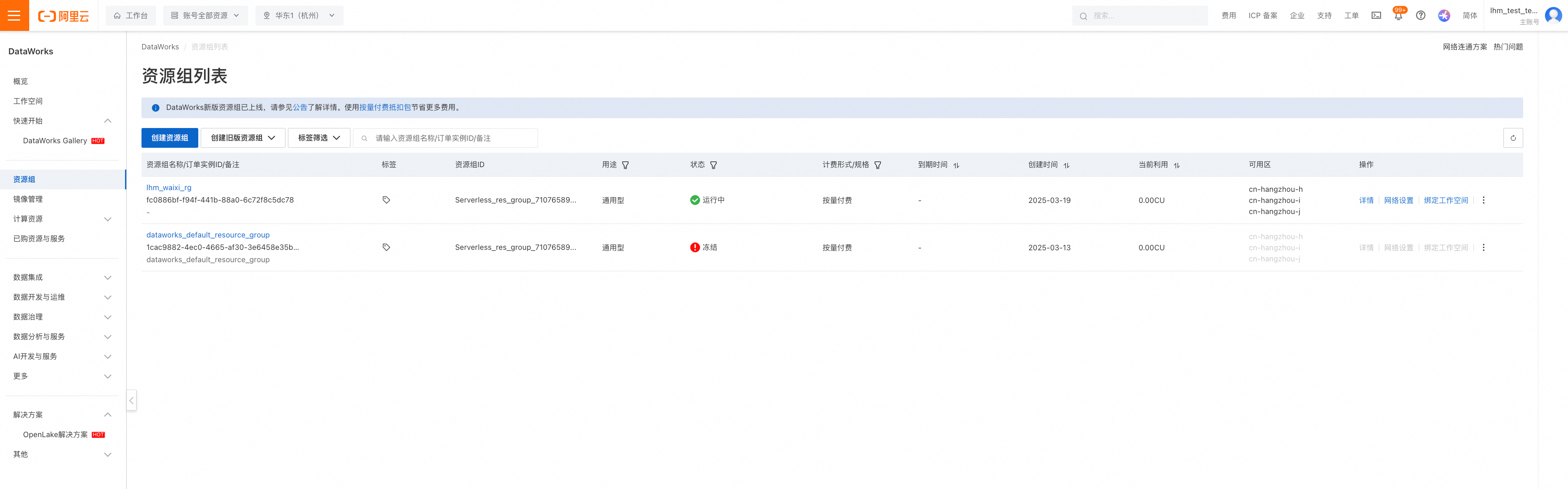
如果需要控制资源组上任务的cu使用额度,可以在资源组的"配额管理"页面控制最大cu使用额度。

比如在进行数据校验任务时,需要控制整体的cu使用上限不超过30cu(一般默认一个Task使用1cu,数据源连接最大并发上限即30),在"数据计算"-"CU上限"一栏改成30即可。后续执行数据校验任务时,最大的JDBC连接数将控制在30以内。
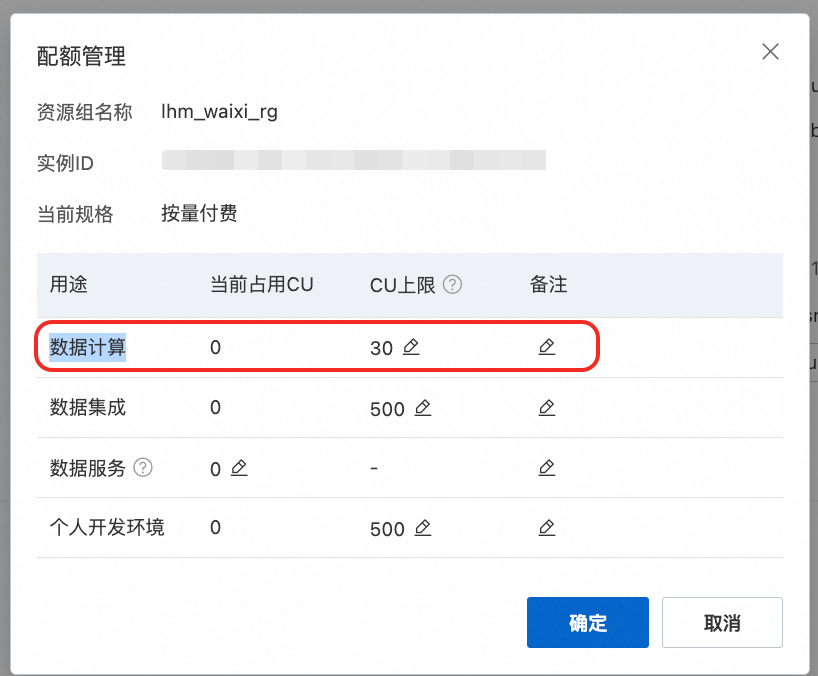
在"湖仓迁移中心"-"资源组与Agent管理"中进行绑定。
绑定完成:

2.2 安装Agent
由于湖仓迁移中心数据校验功能连接数据源端即席查询元数据信息等功能依赖Agent,且考虑到探查时的数据源敏感性保护,您需要在使用数据校验模块之前进行Agent安装。需要您提供一台服务器(阿里云ECS),之后通过操作自动在该服务器上安装一个数据校验的Agent。
安装之前,需先申请License,点击申请License按钮,会自动生成一个License。申请License是为了防止Agent被滥用,起到保护Agent的作用。申请完如下图所示:

目前,支持自动部署的地域有杭州,如有其他地域的部署需求,请通过售后在线联系我们。
注意:
自动部署只支持阿里云创建的ECS
安装前请先开通私网连接服务
通过私网连接打通网络会在用户的账号下创建反向终端节点,可能会产生费用,使用完成之后需要用户手动释放
确保该服务器与源端和目标端待校验数据源网络是连通的
点击安装:
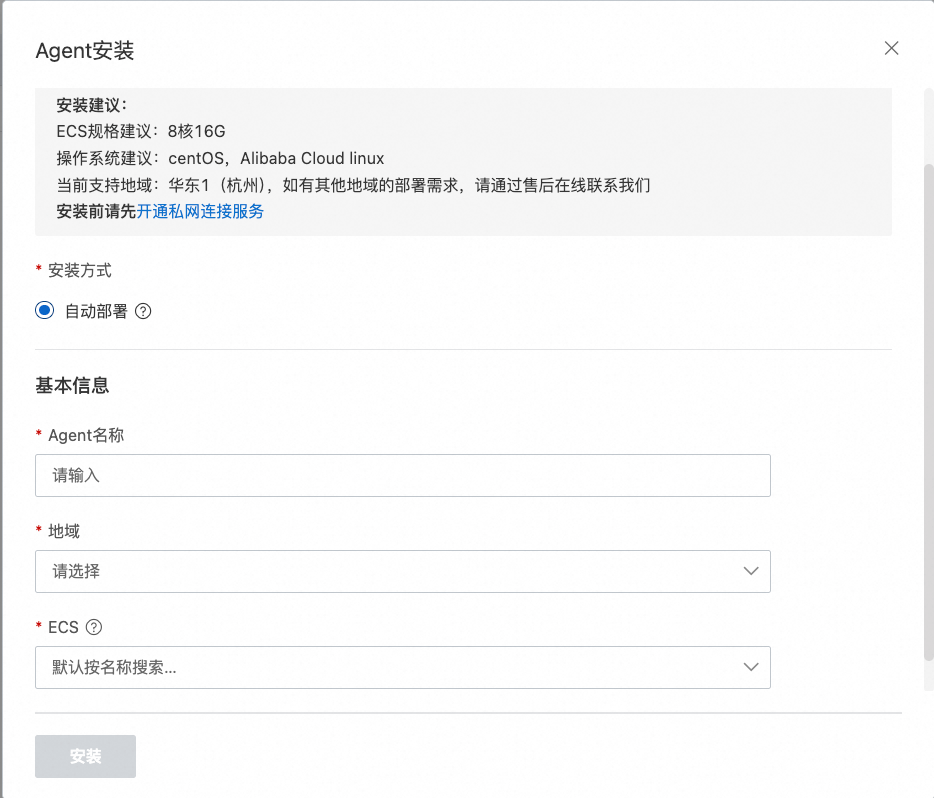
填充Agent名称,选择地域与待安装Agent的ECS,即可自动化部署安装。
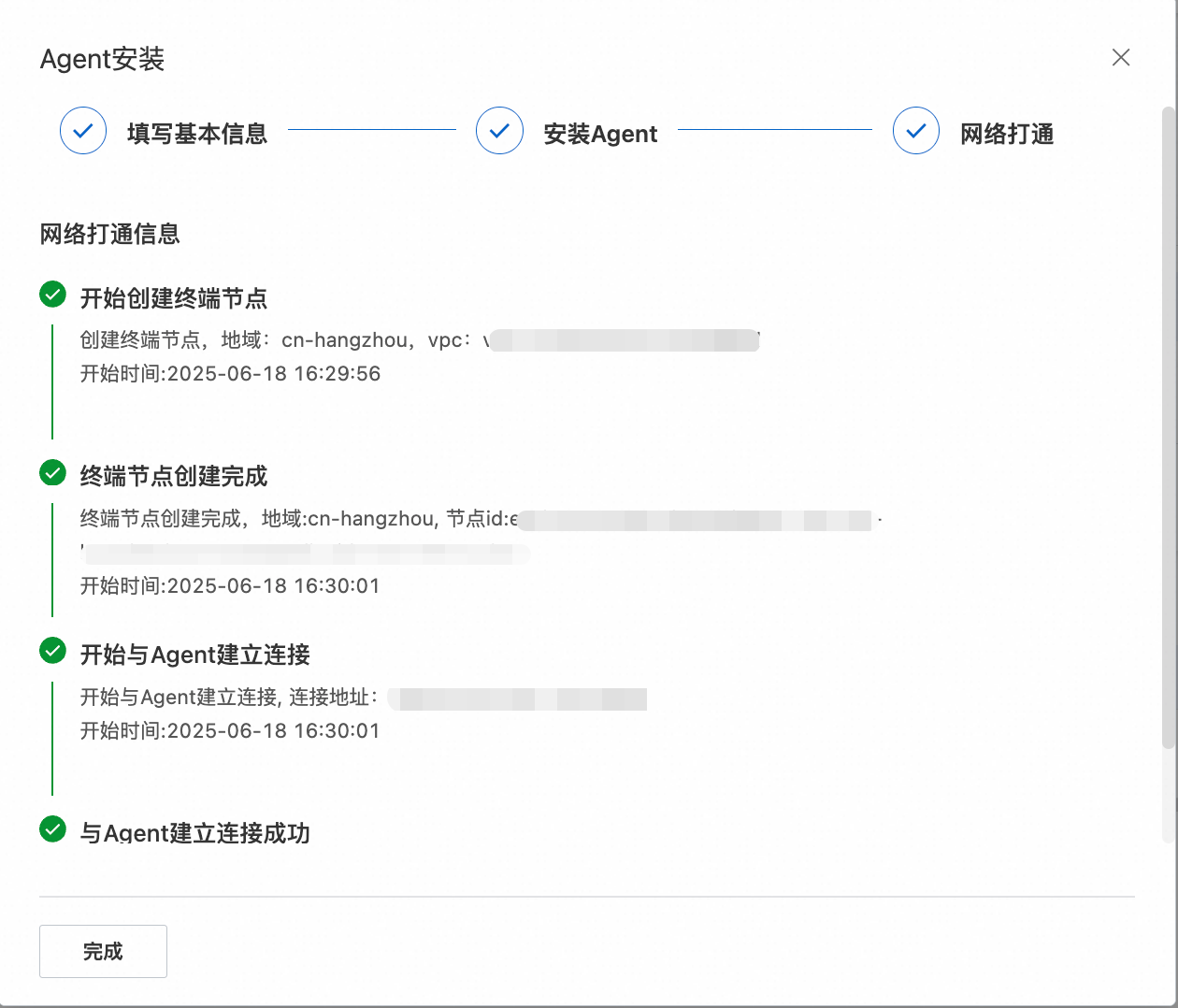
部署过程中,可以即席查看进度。
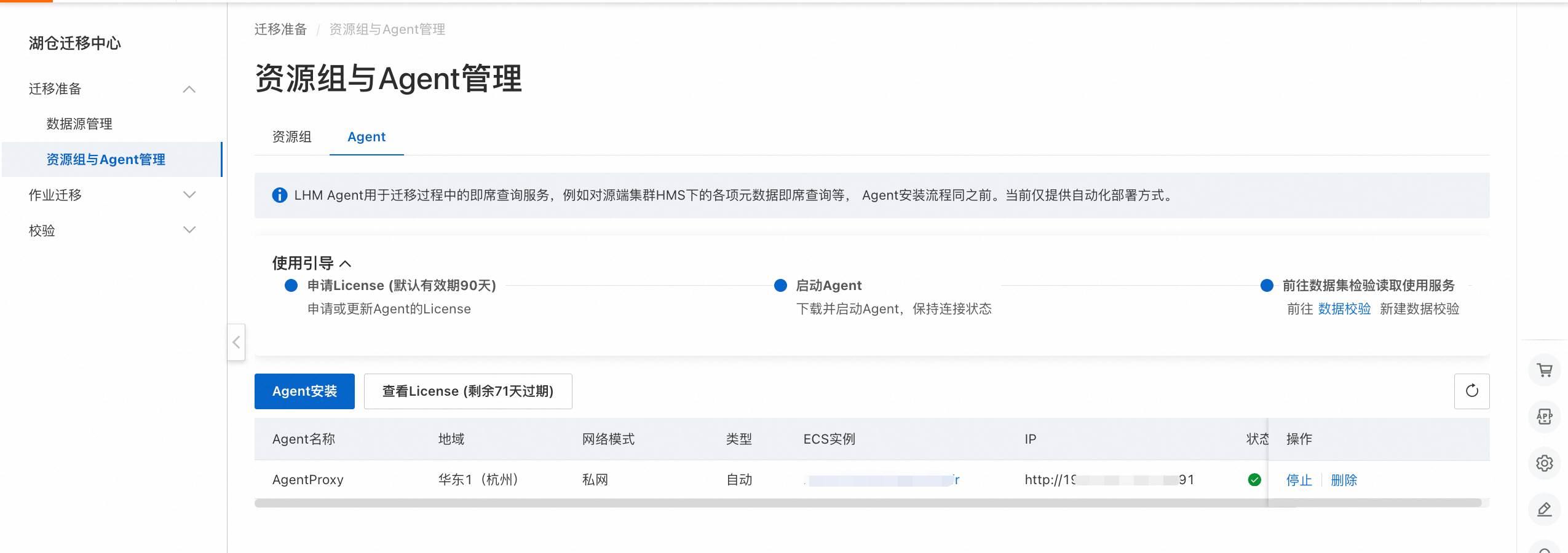
安装完,可通过Agent列表查看Agent在线状态:
3.数据校验操作步骤
3.1 准备数据源
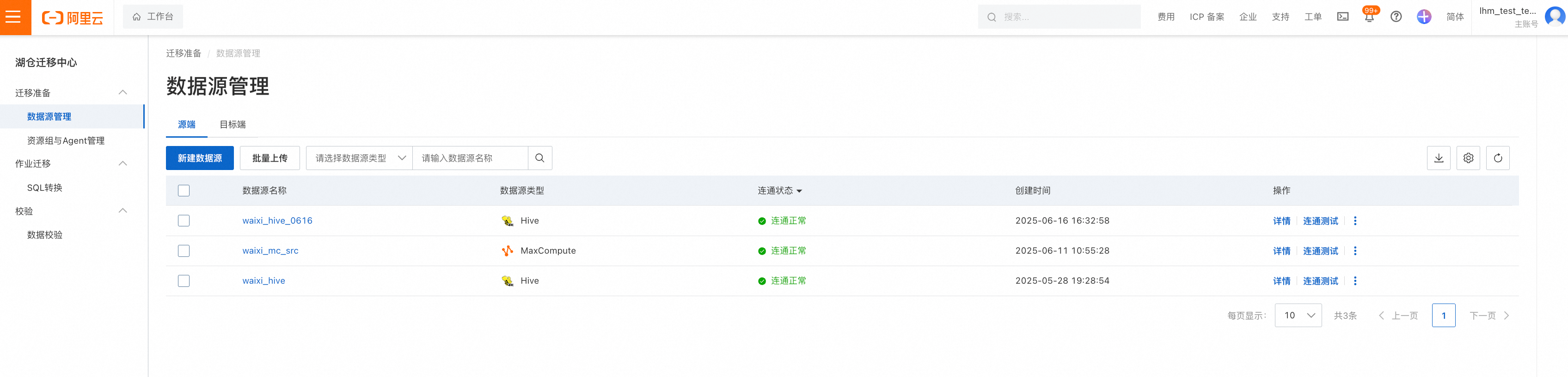
前往"迁移准备"-"数据源管理",新建要探查的数据源
3.2 创建数据校验(Count比对、弱内容比对)
3.2.1 创建数据校验任务
前往"校验"-"数据校验"模块页面,新建校验任务
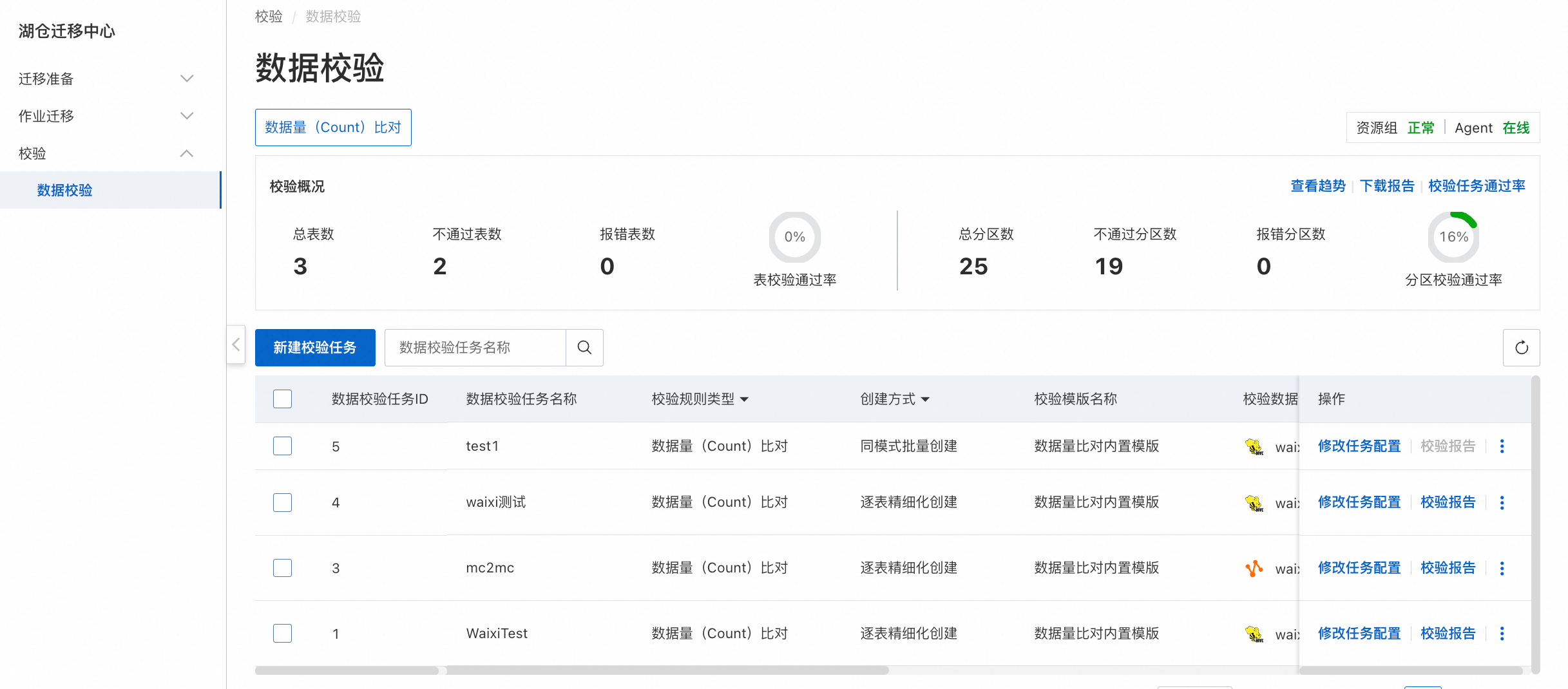
新建校验任务时需检查Agent和DataWorks资源组 状态,资源组显示为"正常"且Agent显示为"在线",方可正常创建数据校验任务
创建界面:
Step1.任务基础信息
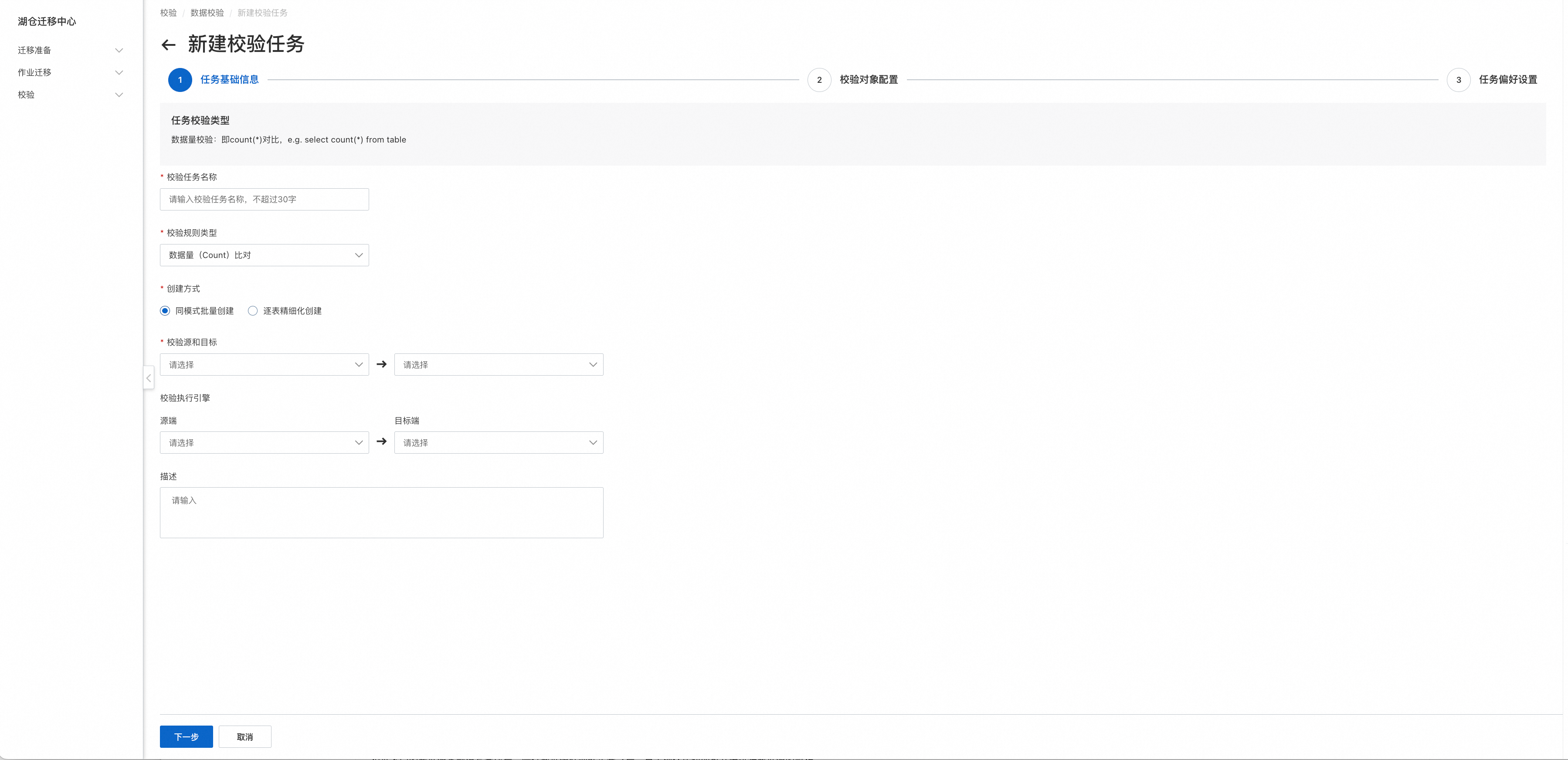
提供两种创建模式:
同模式批量创建:用于对一批表进行校验任务的创建
逐表精细化创建:针对每张表进行单独的校验配置,以满足个性化诉求,例如group by、where、hint等具备业务属性含义的条件
校验源和目标(必选):待校验的数据源
校验执行引擎: 最终查询数据源数据的查询执行引擎,例如Hive可以选择MapReduce、MaxCompute默认MaxCompute本身
Step2.校验对象配置(同模式批量创建)
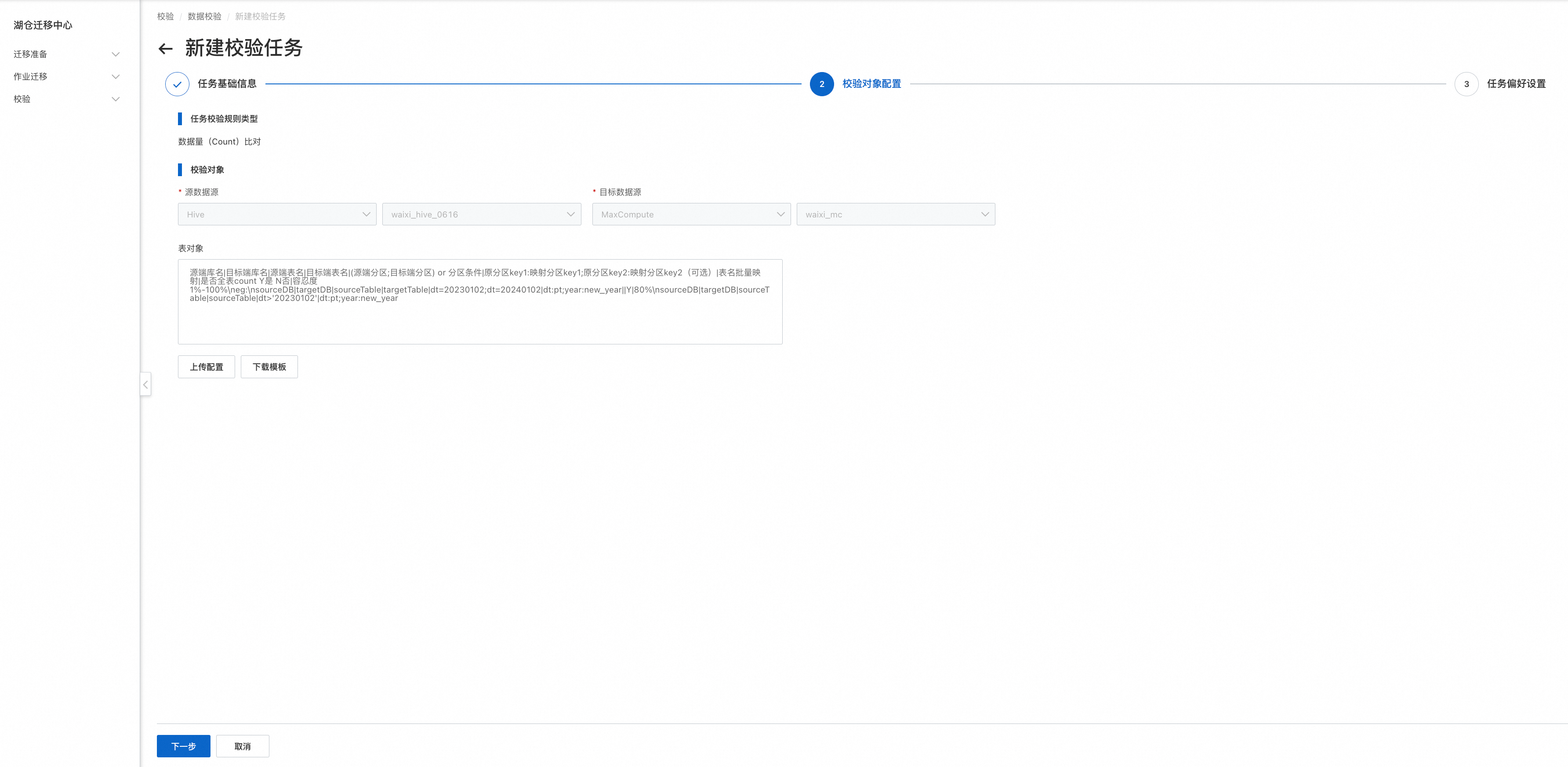
表对象可以配置需要进行校验的库表信息,表名可支持正则,主要规则如下:
源端库名|目标端库名|源端表名|目标端表名|(源端分区;目标端分区) or 分区条件|原分区key1:映射分区key1;原分区key2:映射分区key2(可选)|表名批量映射|是否全表count Y是 N否|容忍度 1%-100%
eg:
sourceDB|targetDB|sourceTable|targetTable|dt=20230102;dt=20240102|dt:pt;year:new_year||Y|80%
sourceDB|targetDB|sourceTable|sourceTable|dt>'20230102'|dt:pt;year:new_year具体配置规则见: 校验范围批量配置规则
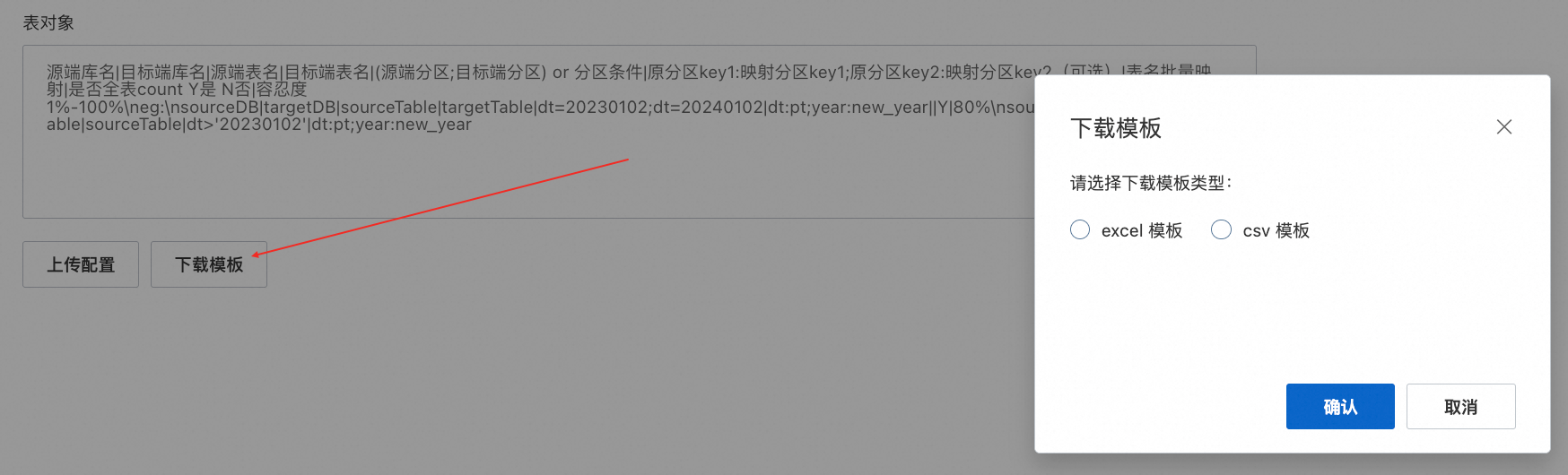
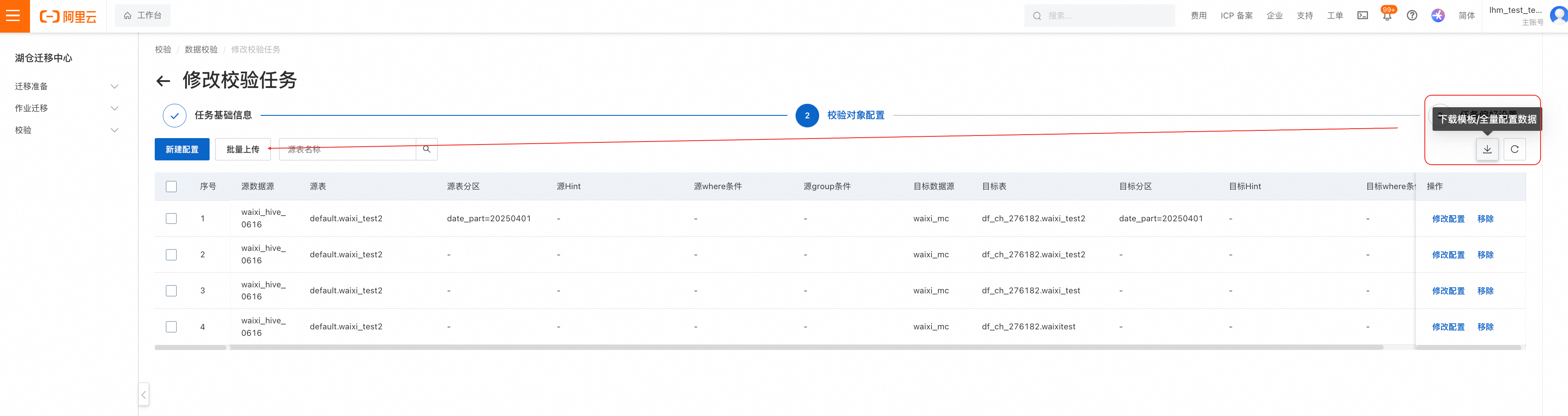
除此之外,用户还可以通过Excel/CSV批量上传需要进行校验的对象的配置
Step2.校验对象配置(逐表精细化批量创建)
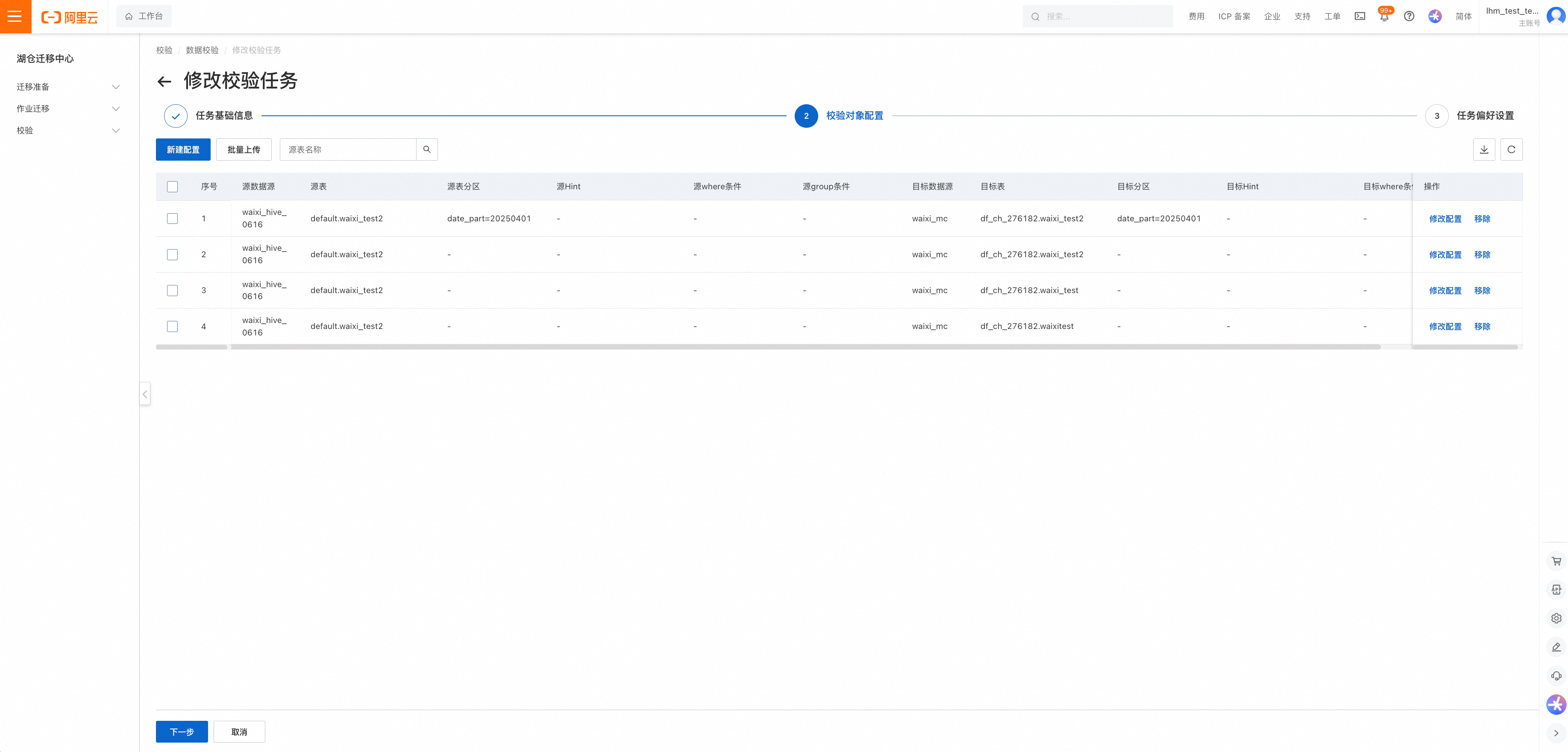
为单表设置校验任务配置,下图为Count比对配置
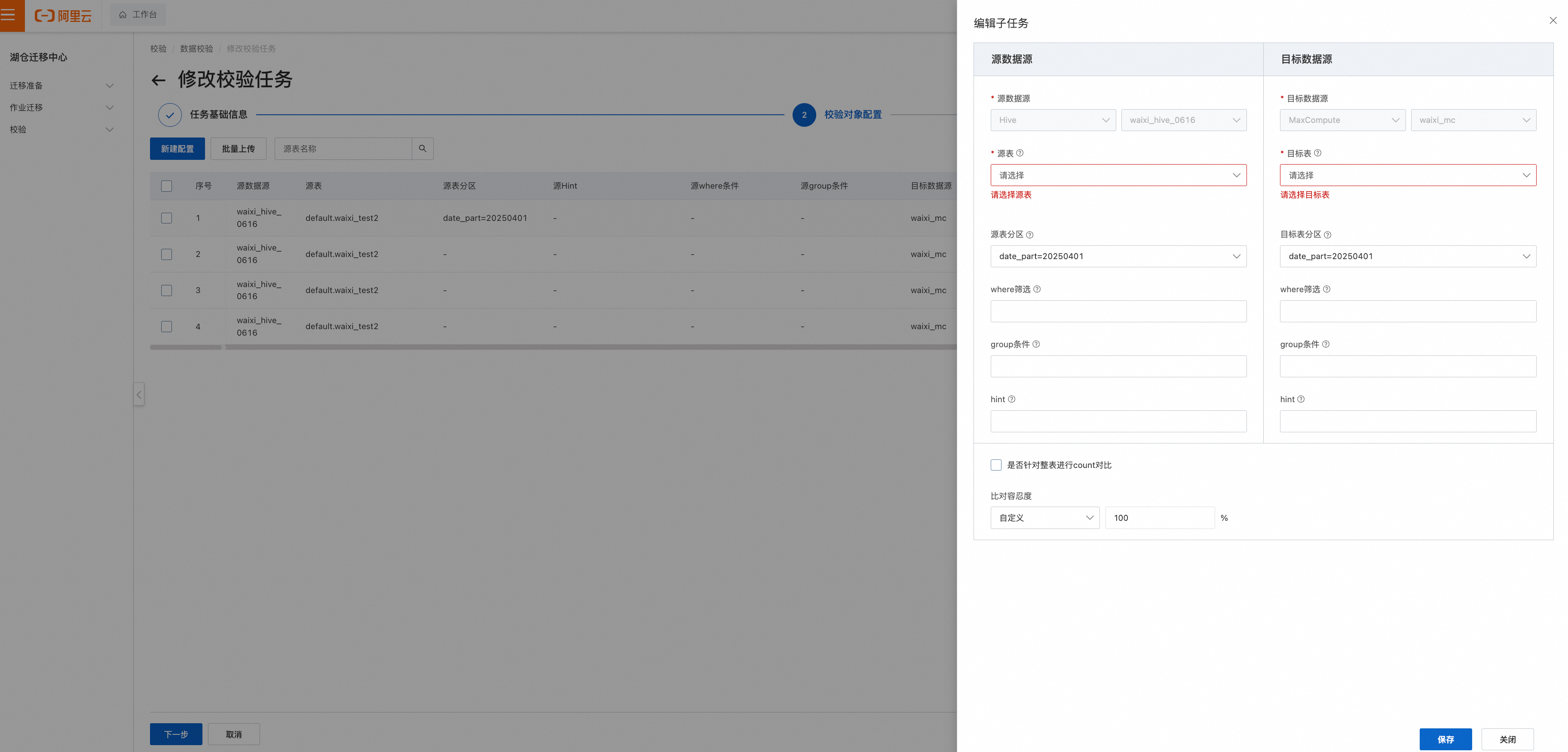
其中分区表达式见: 校验范围批量配置规则 中分区表达式部分
也支持批量上传,如下所示操作
下图为弱内容比对单表配置
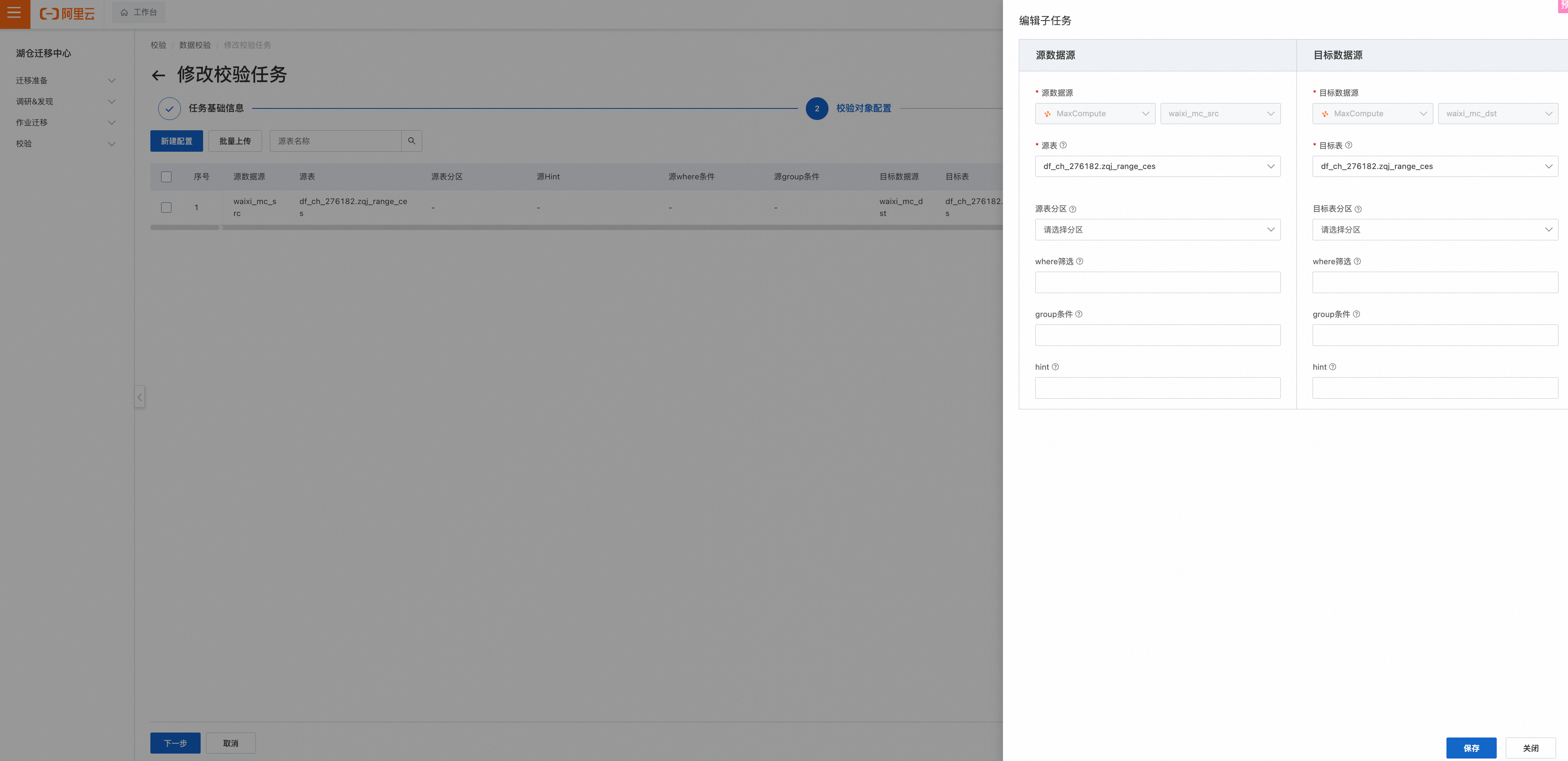
Step3.任务偏好设置
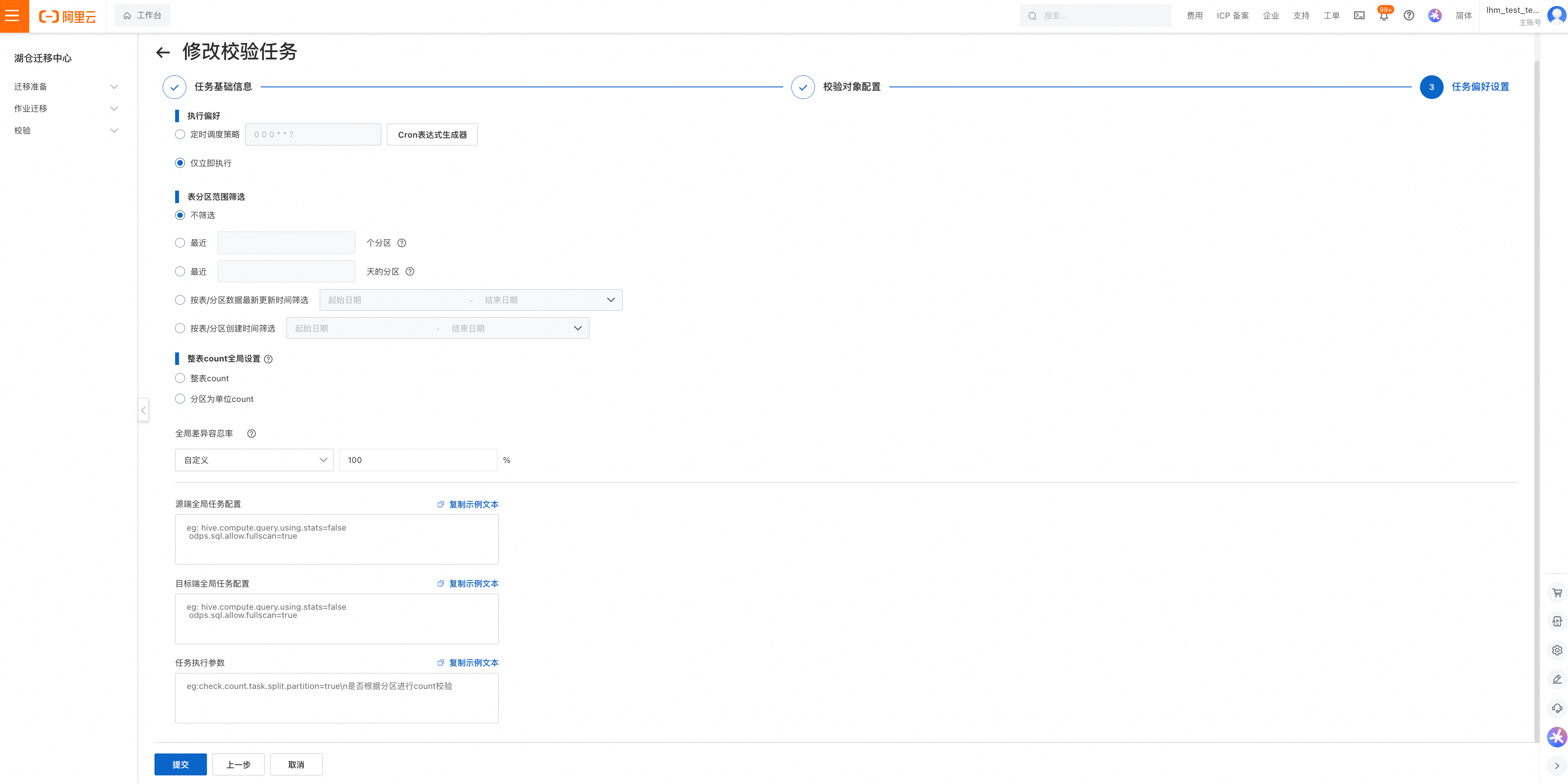
执行偏好:
支持"定时调度启动"或"仅立即执行"
"仅立即执行"后,点击保存校验任务会立即触发一次校验任务的执行。此外,可以在校验任务列表进行触发。
表分区范围筛选: 可以根据筛选范围定义待校验的表或分区范围
整表Count全局设置:Count校验模式时,支持整表Count或者以分区为单位Count,冲突时以单表设置为准
全局差异容忍率:
差异率: (|目标端值-源端值|)/源端值 *100%
差异率 < 差异容忍率 视为通过,即 (|目标端值-源端值|)/源端值 *100% < 差异容忍率视为通过,例如源端count校验结果100,目标端校验结果95,差异容忍率10%,差异率=5%<差异容忍率,判定为通过
支持对源端或目标端执行引擎的任务参数设置:
如在Hive端设置,如下为示例
mapreduce.job.queuename=queue-name
hive.compute.query.using.stats=false
在MaxCompute端设置,如下为示例
odps.task.wlm.quota=<quotaname>
odps.sql.allow.fullscan=true
校验任务执行参数:
check.count.task.split.partition=true count执行时是否按照分区进行切片;true:按照分区切片,false:整表count
3.3 创建数据校验(指标校验为例)
3.3.1 创建数据校验任务
前往"校验"-"数据校验"模块页面,新建校验任务

新建校验任务时需检查Agent和DataWorks资源组 状态,资源组显示为"正常"且Agent显示为"在线",方可正常创建数据校验任务

创建界面:
Step1.任务基础信息
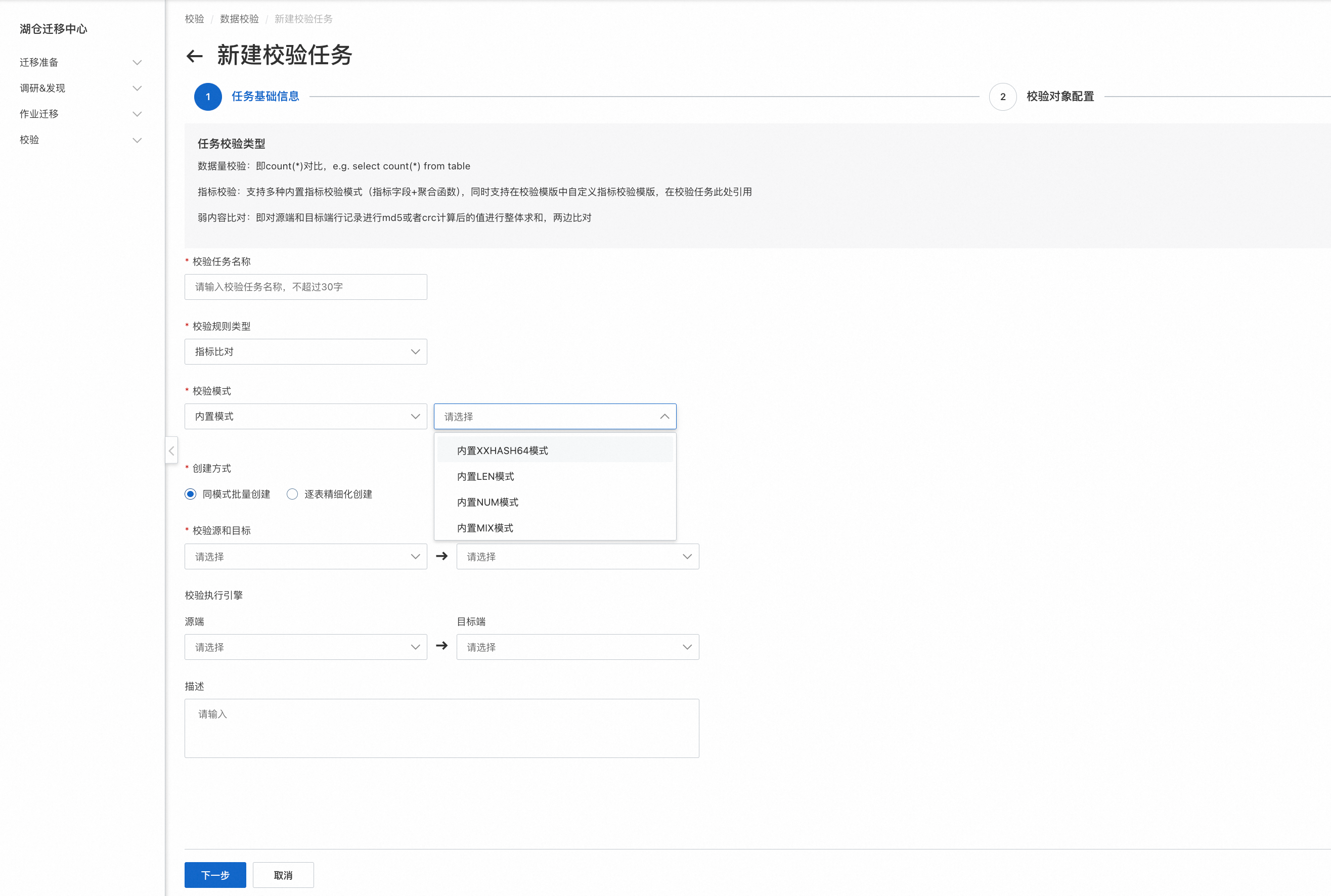
1.提供两种校验模式选择
支持内置指标校验:
模式 | 规则说明 |
NUM模式 | 校验表行数 & 校验数值类字段的avg/max/min |
LEN模式 | 校验表中String、Map、Array类型字段的长度之和 |
MIX模式 | 校验表行数 & 校验数值类字段的avg/max/min & 校验String、Map、Array类型字段的长度之和 |
xxhash64 | 校验表中基础类型字段(包含int, bigint, float, double, decimal, string类型)的xxhash之后的中位数/25分位/75分位数 |
支持自定义指标校验:自己定义指标校验模板,见后问自定义指标校验规则
2.提供两种创建模式:
同模式批量创建:用于对一批表进行校验任务的创建
逐表精细化创建:针对每张表进行单独的校验配置,以满足个性化诉求,例如group by、where、hint等具备业务属性含义的条件
3.校验源和目标(必选):待校验的数据源
校验执行引擎: 最终查询数据源数据的查询执行引擎,例如Hive可以选择MapReduce、MaxCompute默认MaxCompute本身
Step2.校验对象配置(同模式批量创建)
同3.2中相同部分
Step2.校验对象配置(逐表精细化批量创建)
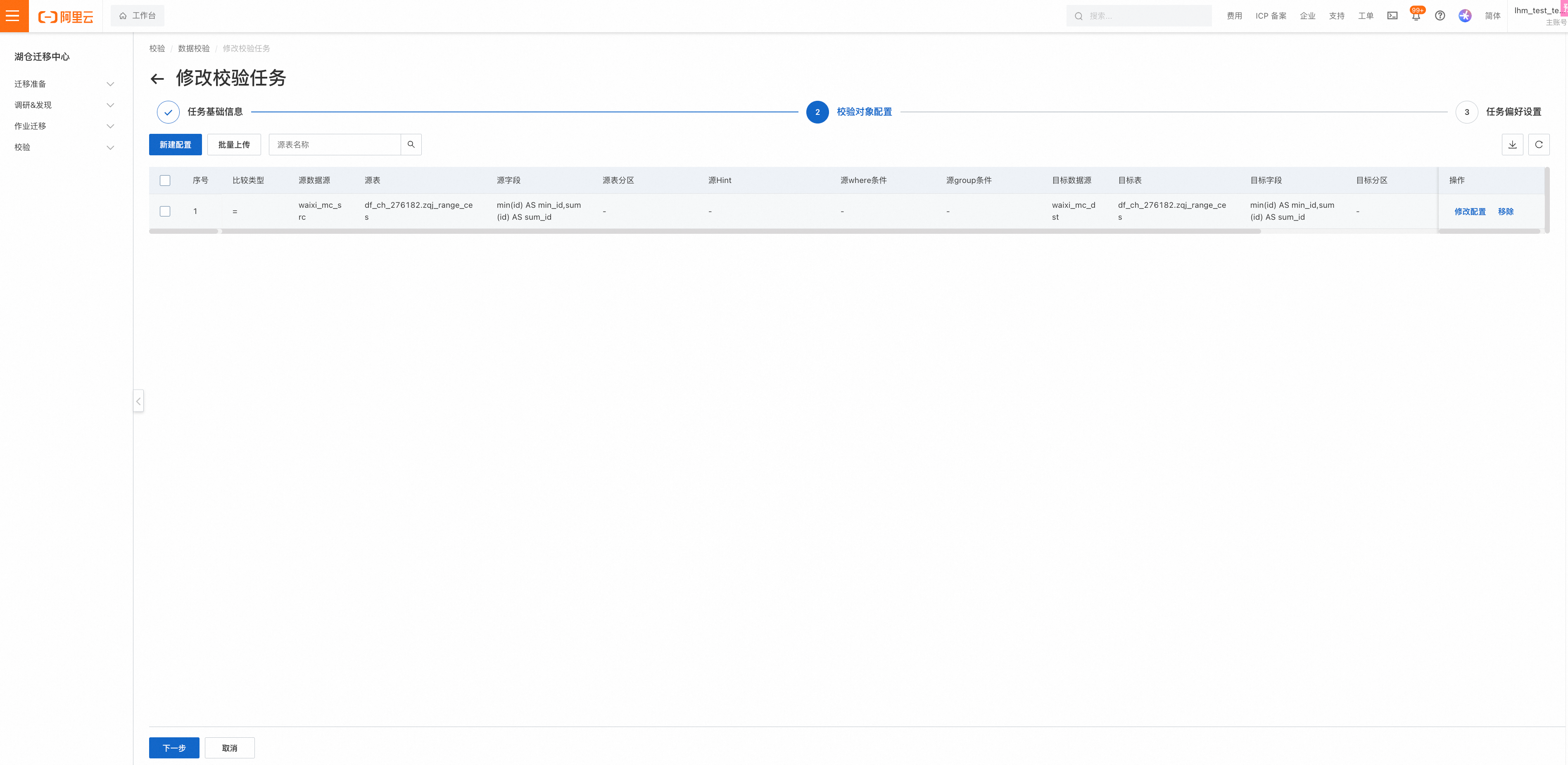
为单表设置校验任务配置
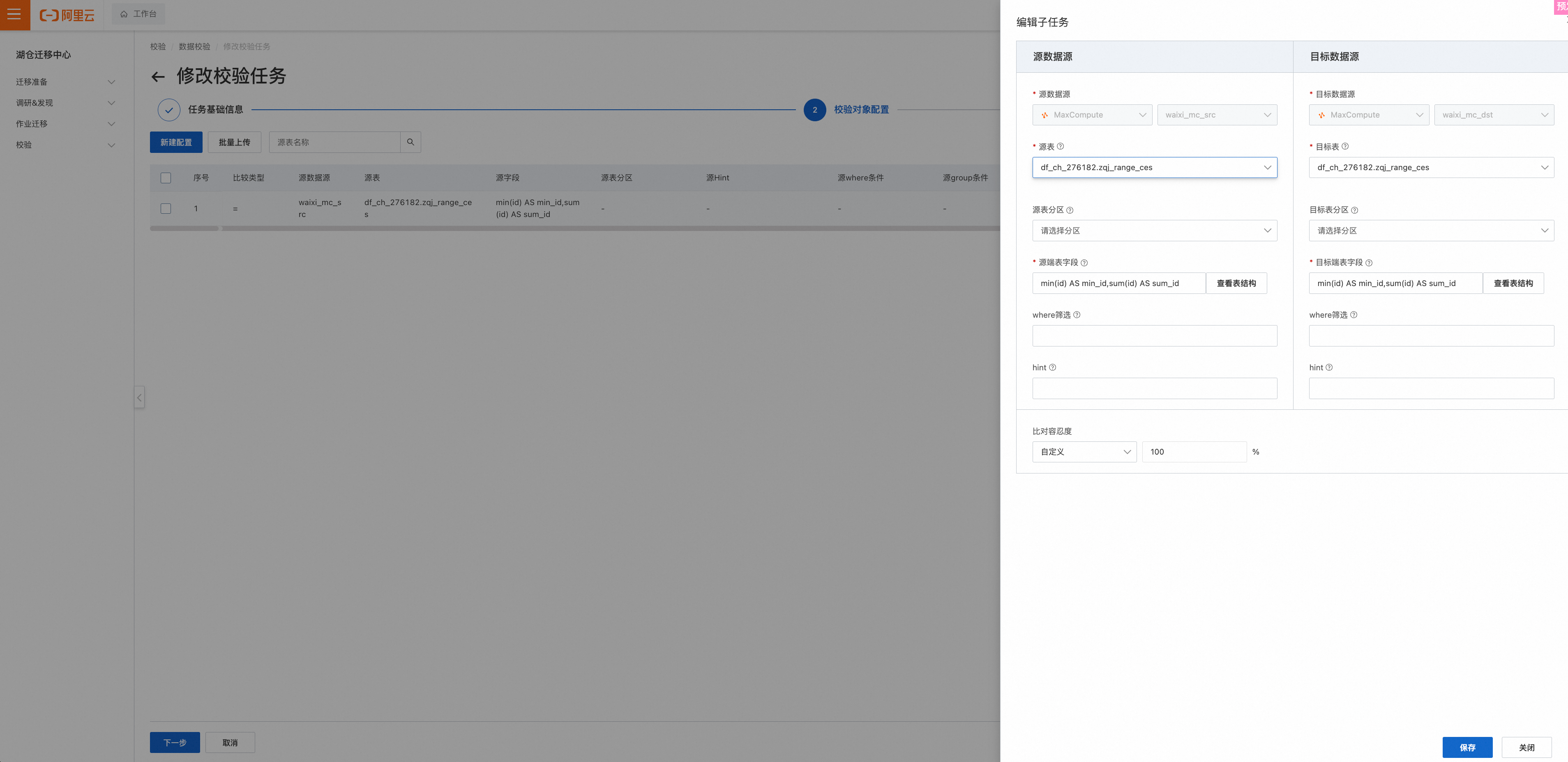
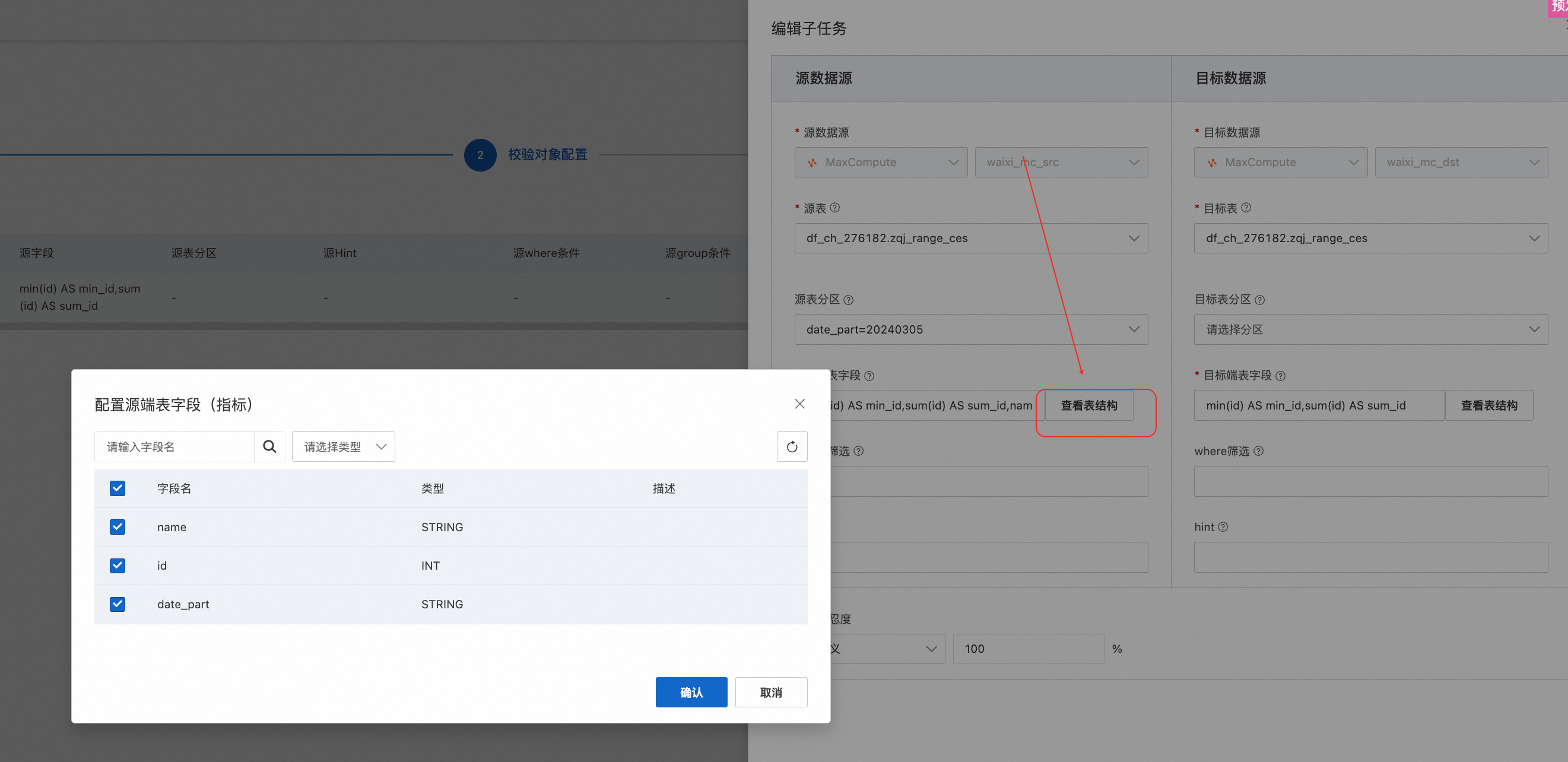
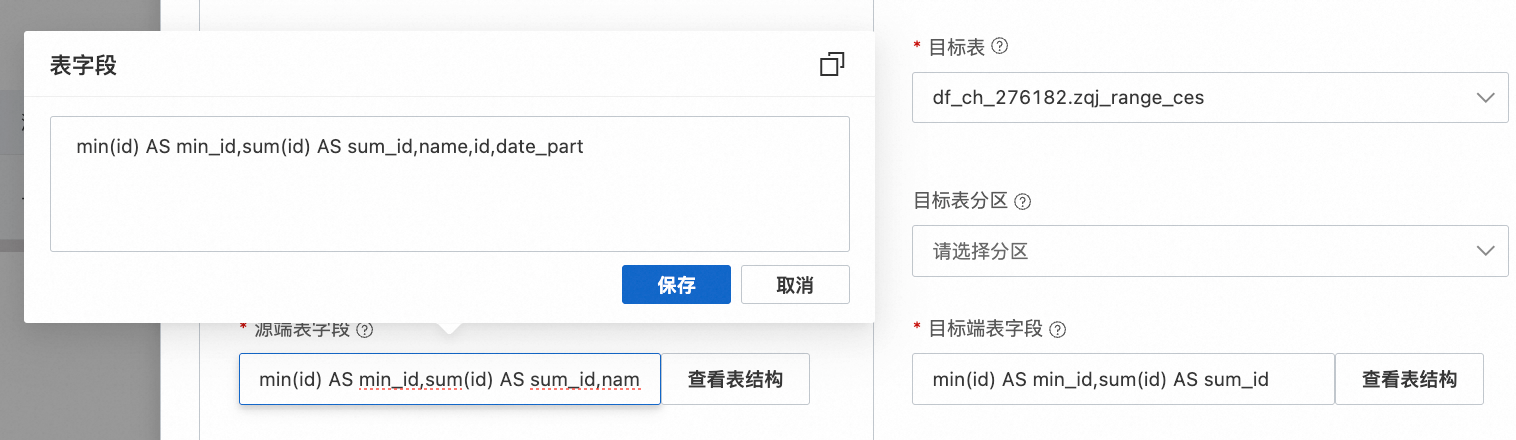
支持通过表DDL结合校验模式自动化生成校验SQL,并可以点击查看具体SQL
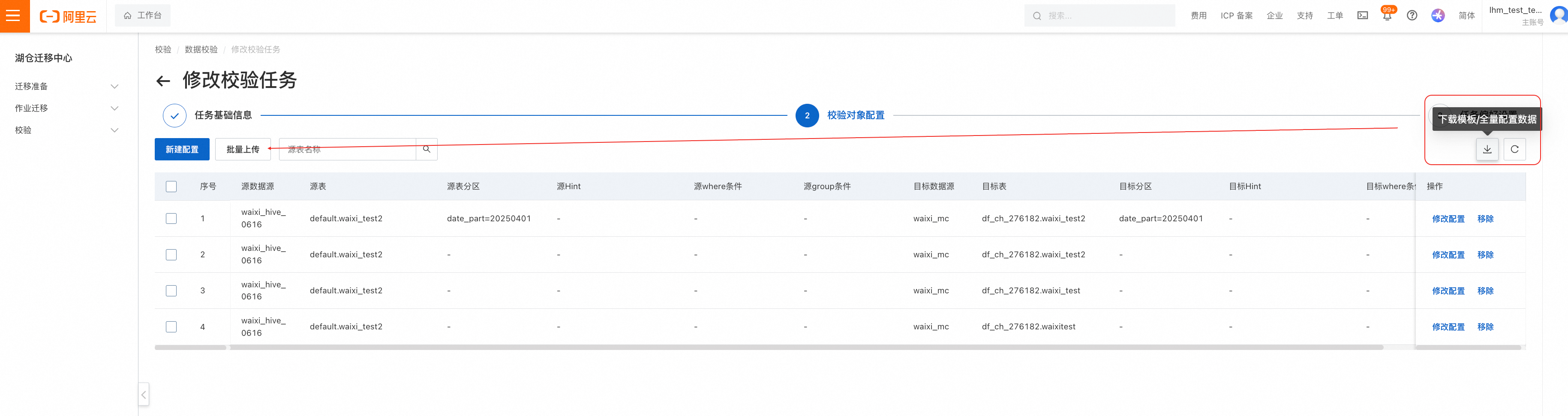
也支持批量上传,如下所示操作
Step3.任务偏好设置
同3.2中相同部分
3.3 查看校验任务列表
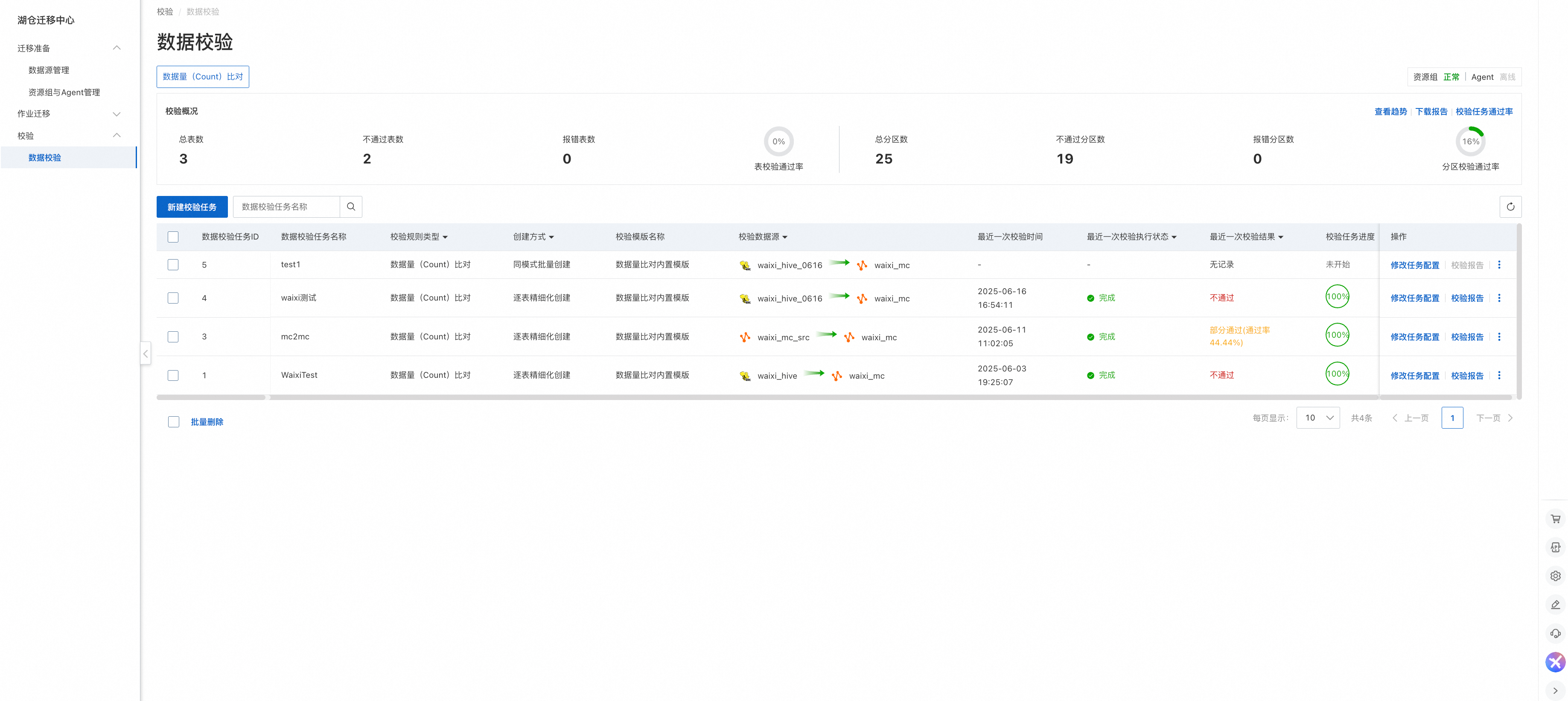
支持如下操作
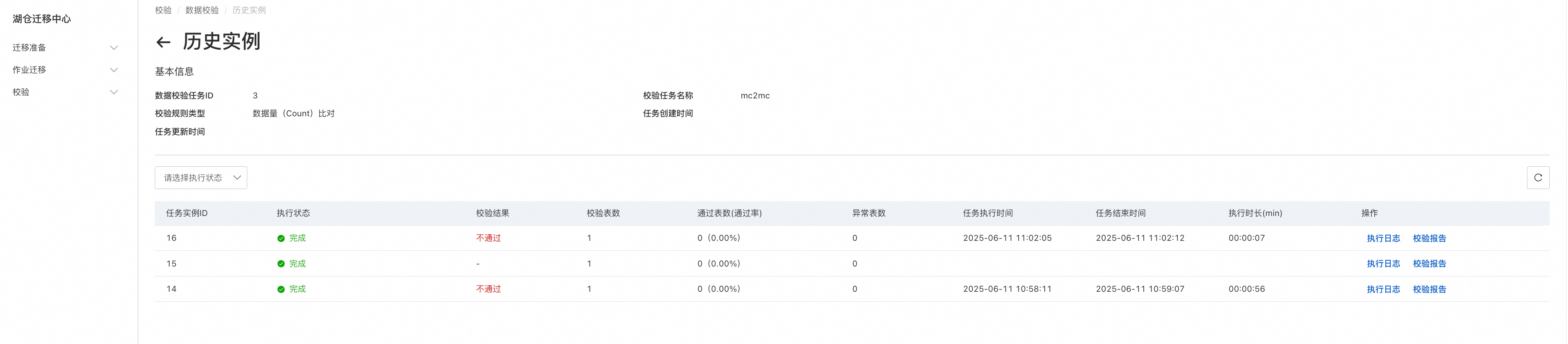
"历史实例"中可以查看该校验任务下过往所有执行实例的信息,包含执行日志和校验报告:
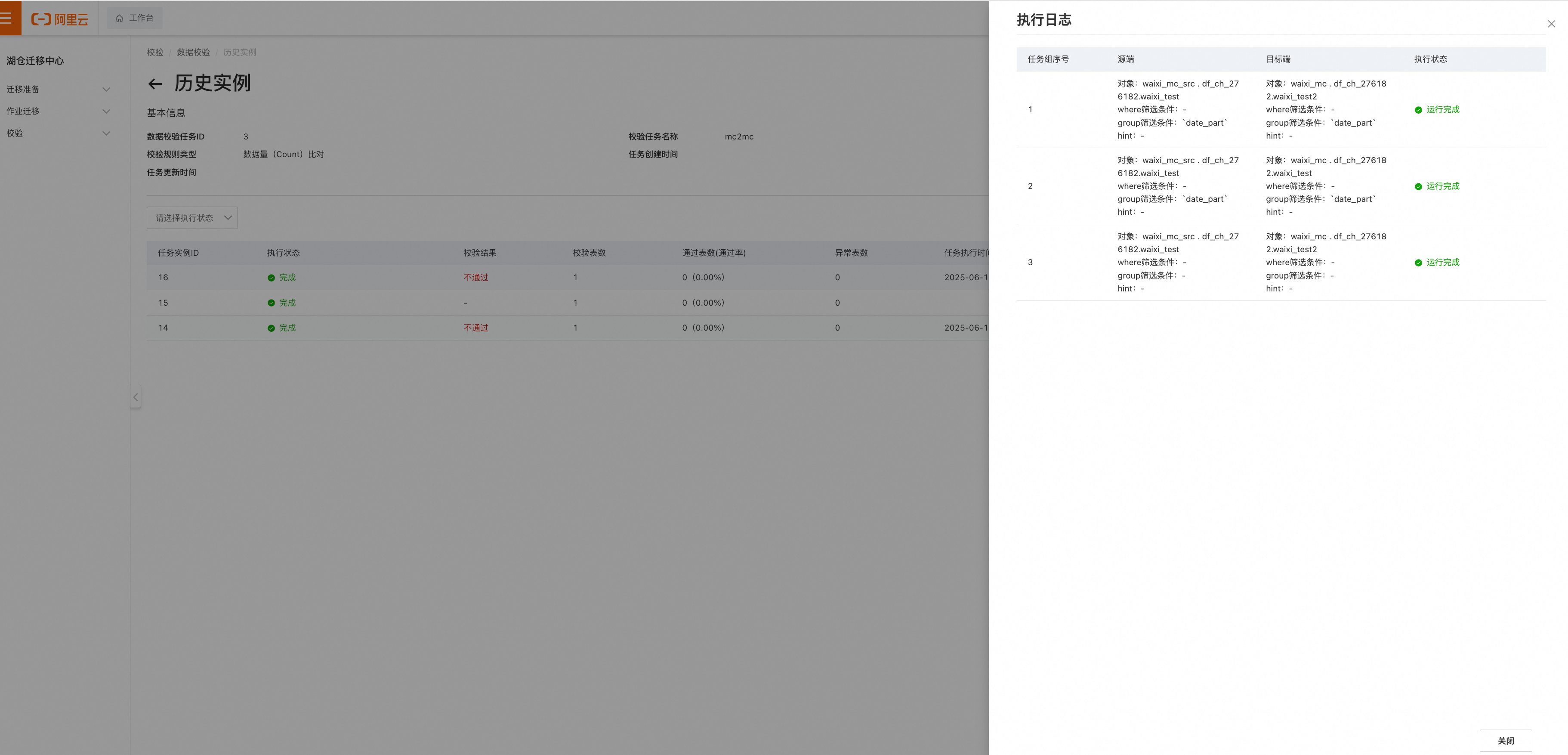
"执行日志":
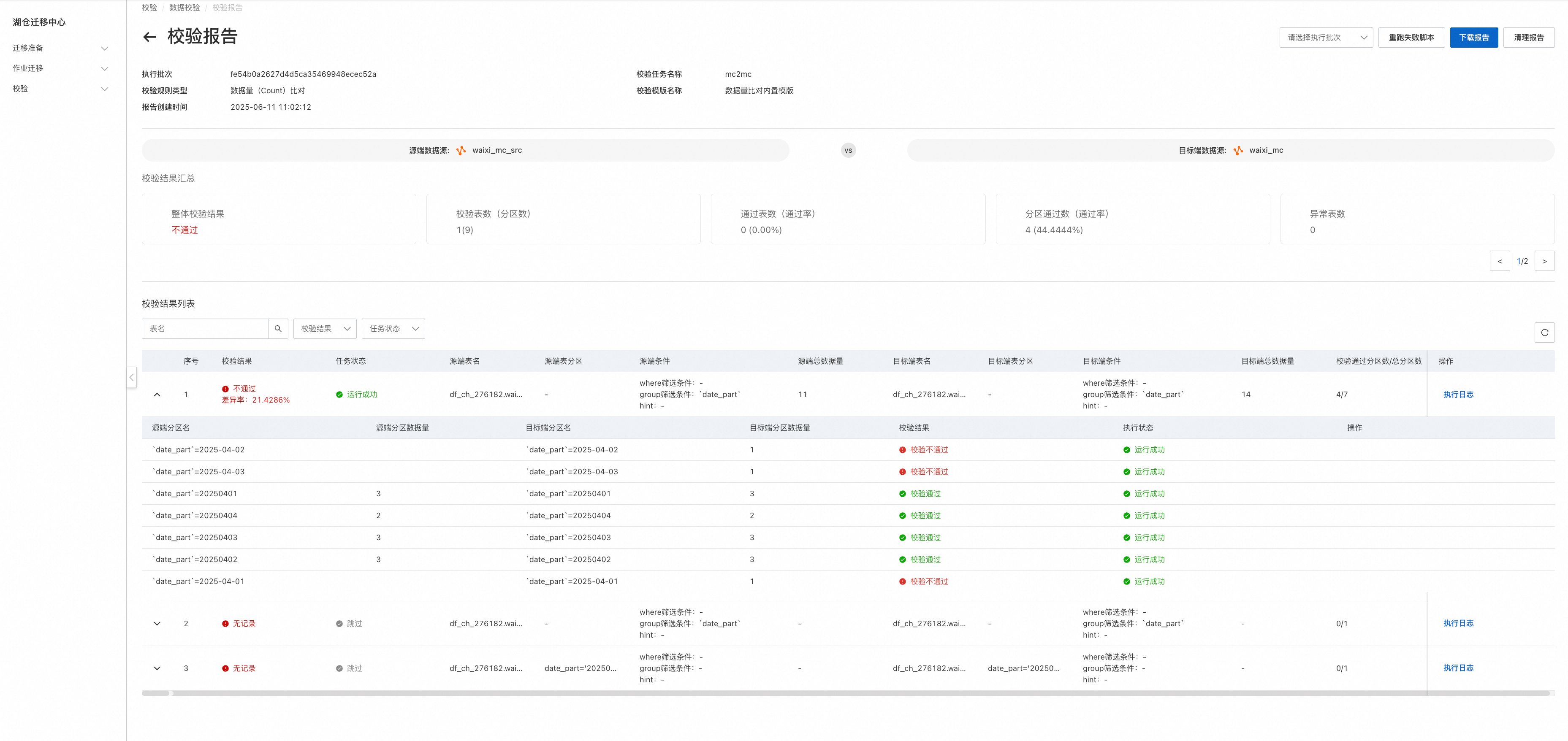
3.4 校验报告
Count校验报告:
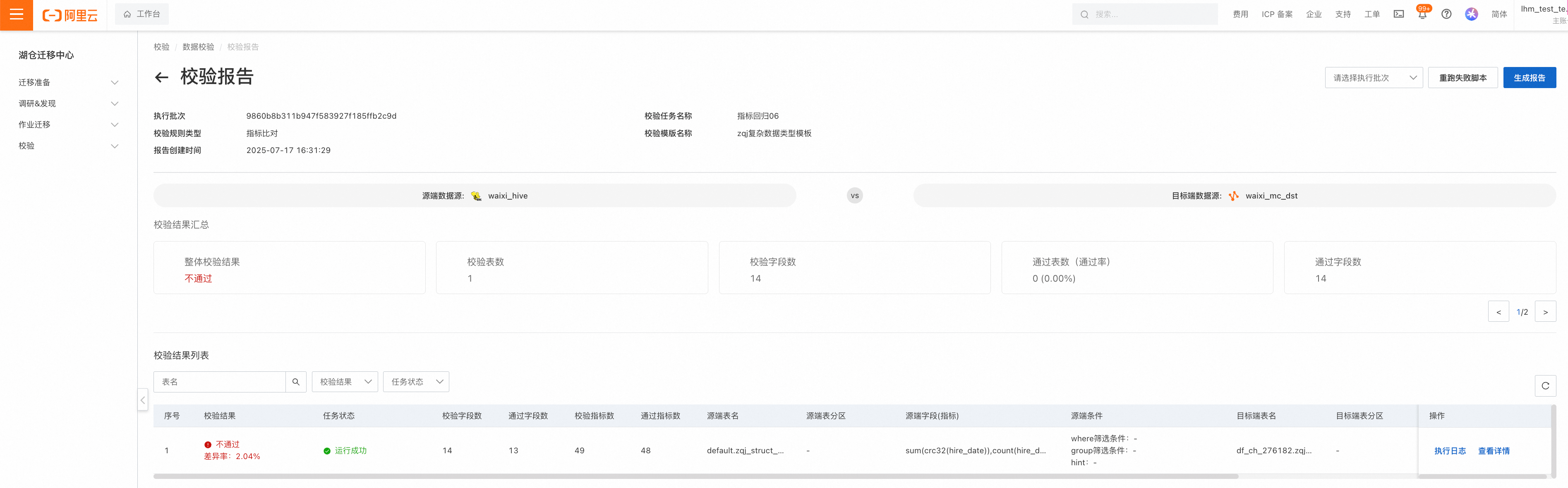
指标校验报告:
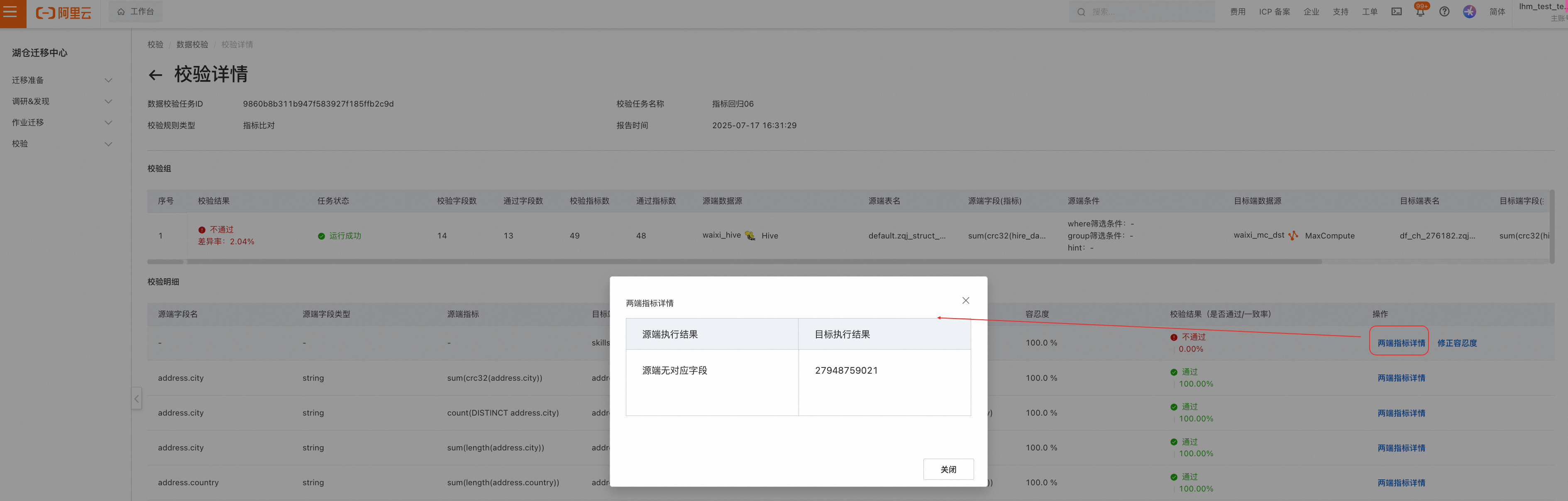
查看详情

两端指标详情:
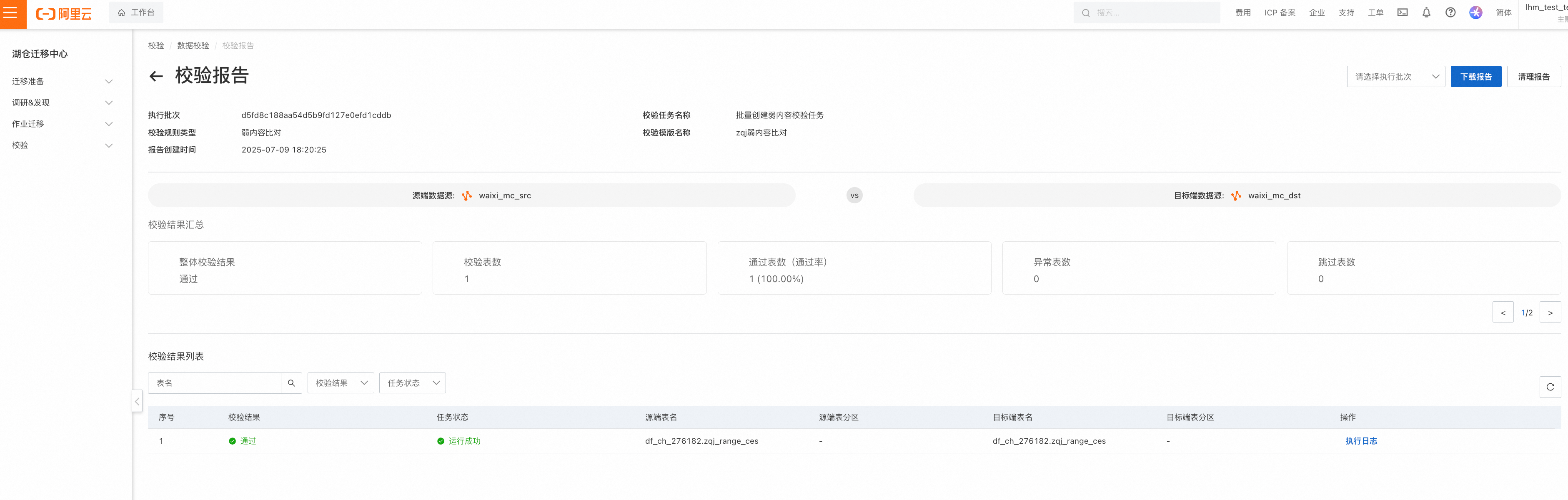
弱内容比对报告:
校验报告通用能力:
支持针对运行失败或校验不通过对象(表/分区)的校验任务进行批量重跑
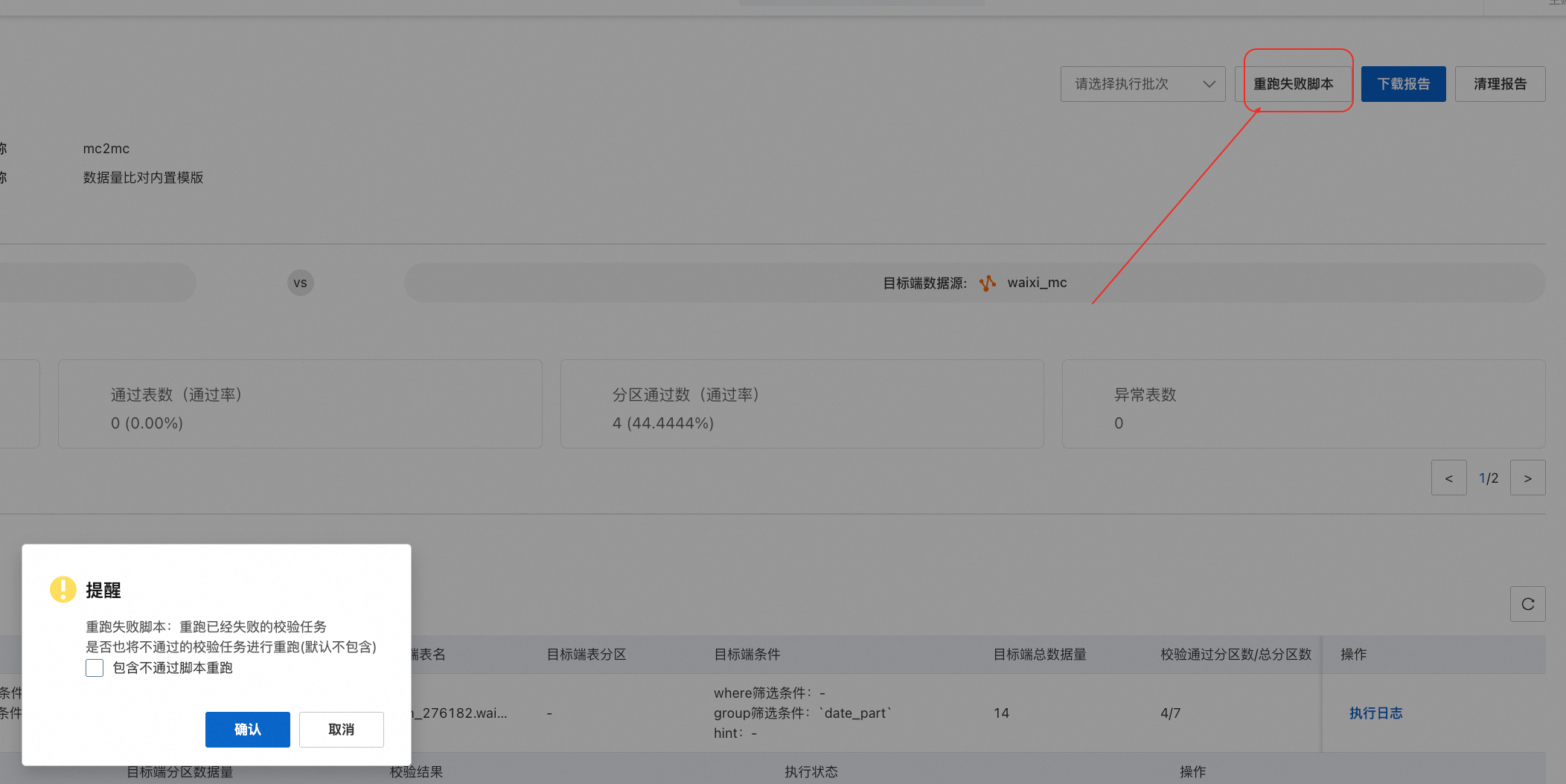
支持下载报告

支持选中执行批次后进行清理报告