
本文介绍了基于LHM调度迁移工具将EMR Worflow调度任务流迁移到DataWorks的方案与操作流程,包括三步,EMR Worflow任务导出、调度任务转换、DataWorks任务导入。
一、导出EMR Workflow调度任务流
调度工具通过EMR Workflow页面接口获取任务流、资源和数据源信息。导出方案如下。
1 前置条件
准备JDK17运行环境,打通运行环境和EMR Workflow的网络连接,下载调度迁移工具到本地并解压缩。
网络连接测试方法:验证能否连接EMR Workflow页面网址。
登录EMR Workflow控制台,获取地址,并在部署工具的环境中验证网络连接。
ping emr-workflow-cn-hangzhou.data.aliyun.com2 配置连接信息
在工程目录的conf文件夹下创建导出配置文件(JSON格式),如read.json。
使用前请删除json中的注释。
{
"schedule_datasource": {
"name": "YourEMR", // 给你的EMR Workflow起个名字!
"type": "EmrWorkflow",
"properties": {
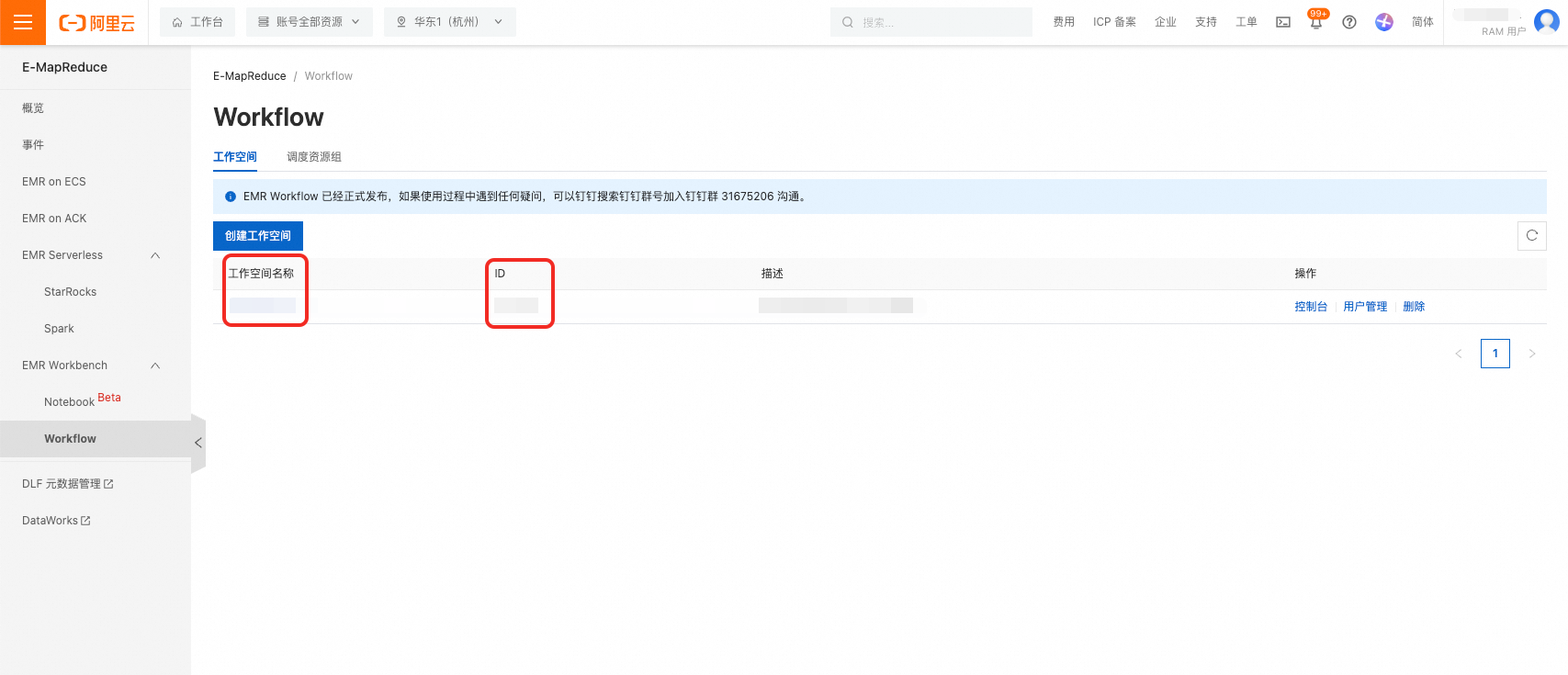
"project": "我的工作空间", // 工作空间名称
"projectId": "1201575", // 工作空间ID
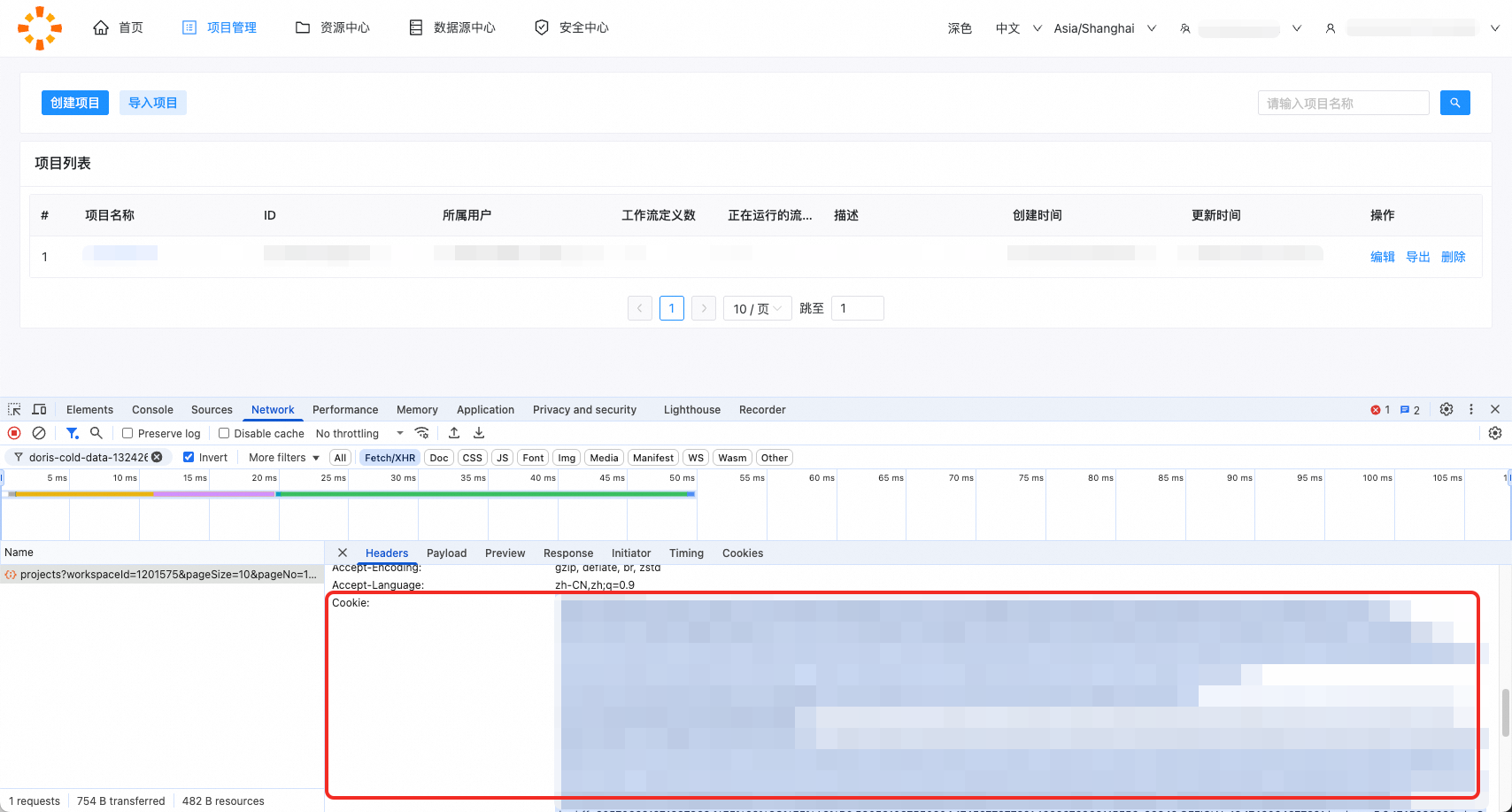
"cookie": "session.user=1663676968115556_1201575; sessionId=b1b46589-9050-4501-8306-a165f88aa9b6; cna=EqsbH4WKzkcBASQBsYAqwPbC; _abfpc=27b472bfc7f89623e8ed9d284f86de7a5942990e_2.0; t=b42b2d23a05efcfc3904fd27809e8876; tongyi_guest_ticket=u6xQ53c2yDcQuUoyW8m8_P$Euc2tK1vAJrbd0Pp8RqQlFXqgAxQlQbm5GMjKeLhhMmLVgmaWvv690; tongyi_sso_ticket=apRX0qcdzyjC5$ojKmLhMMmeswgxpWvG_dV8knnYvIBjexQnxm08QA6sXpfbGzzg_8yn1gsBH1oO0; bs_n_region=cn-hangzhou; yunpk=1663676968115556; login_aliyunid_pk=1663676968115556; login_current_pk=205706621271387868; help_csrf=1QU0Vd9goAw21fKSbkhMwV0BsXQrSRzyYlNzgRJH%2Bm1zjtkNMXBven%2BTyFm2hkxdBeFQC%2B9a%2B%2FUPNAeOxxzEYES1Ybz4HdCfbYmp3WHK1bDF1bb6loa86ycMrrV0dBU6sEOTH1LoEBE15m%2Fv%2BzdV4A%3D%3D; cr_token=80407c38-06df-44b6-b383-b7464af3f24f; bd=s0ouCmI%3D; sca=2fe2ea4a; ecsCustomBuyVersion=new; copilot-session-id-dw-copilot=be98f3db-e5dd-458d-bd56-53bb43c15b2d; bs_n_lang=zh_CN; activeRegionId=cn-hangzhou; notice_behavior=implied,eu; channel=r%2BOBdZKdhDzlinkO0n6spUNMqtdofQvlsXqge2s9iQMPfaUh1kgmvsuAjBSBefwJsQGEHPZJROwUH7DmRkyDtA%3D%3D; _samesite_flag_=true; cookie2=167d0d6e4a710c25359bc7ec926b0f40; _tb_token_=e3b766e8e037e; cnaui=%2522hesheng%2520%2540%25201663676968115556%2522; aui=%2522hesheng%2520%2540%25201663676968115556%2522; language=zh_CN; ck2=1dfffdf1279716911724407ae9119282; an=hesheng; lg=true; sg=g28; atpsida=6dd15eb4619a28ae3d50f053_1741692372_2; currentRegionId=cn-hangzhou; partitioned_cookie_flag=doubleRemove; aliyun_site=CN; aliyun_lang=zh; login_aliyunid_csrf=_csrf_tk_1216439968355914; login_aliyunid=\"hesheng @ 1663676968115556\"; login_aliyunid_ticket=3RctYK12wchS7wBJzHKJeoTE.1118Eu1zAQBswru9dwX3p626Hkye6D1zqmF4iKW2rjiRruDxeFL6TkGmxD94zf6dACfqLfEmPxA1FcHTRSpbBazr4oWhCMPAWPhXubTua1j6aeR2c5PfrgpP5UEJcKDQWHKbMqcTYYMeca46BiaSeZUx6uw7n3YvbyzhFytW88Ssyks5mzB.1QDta7ZWM7nyQUHpV7rKtSCR4bWExYZ7CEpGotZErJz844UFnjNEc4pRohJrZ7mYS; login_aliyunid_sc=3R5H3e3HY2c8gwLZuY5GmS7K.1113hM7ys3oXbRaRYNucf2xgCHC4tuX7FWZ2gYR18qCgHCDqFDK5JHMUcKeBLZckMwoh5W.2mWNaj35xPge9RXAhrfkJ4XtVqVFhv4QRSUVinmgzVoCwXMVBTfHwBYfhCWbqsFbgJ; dw_bff=205706621271387868.%E5%92%8C%E5%A3%B0.580581087550304.1742181195731.1663676968115556..26842.OFFICIAL.18.1742267595731.hesheng.5.2.1742262992.zh_CN.f2a68809ec371fbcb96ebf58a9d7a0ea3fe8053a; c_token=16241d6d00c3d29488917ae3f47b612c; tfstk=gZIj2cgqa1IyJzllnSeyFJZxZot1c1ZUXA9OKOnqBnKvCh6h1jR27sROP6fsb-XToRZ139TwWSxVf_6CIIh20FP6565P01-Yi1_1KOW4InnqfF6CGZl2DPDcr6WK0izDbctDjhFUTkrUntxMXnOdIPRceTvTUKQldkQkjhFUa4o9oktGtXmuTGB8FdJZDKC96QeWQpttDFnxybdkBhK9WdH-2pvv6fdxk86JZdK961Kt6qcWQr9Oh-CUznygYCXvNcnO2lYXOt3ZXcIWhEsOHQ61Cg9XlBLzdgE1A9BAxdsgpVO1KZC2E1ZQN3IfGiLWflik09_RGU_b10Tly9j9PaVI-9XAGwLdDuwyPiXeDQsgIcAAuOIw5iFKQIIcggThjjNy_wWPDU1La01M5ZQpDGNQ2gzmYBTOhVMW-cpWT8wSSVVcc6qLHbYAtEpkHky7FbgMkLv5M8wSGFYvEKF_F8GSS; isg=BNfX5pEkfPamJ_k2pCb_1X4nZk0hHKt-NoZ1UCkEaaYPWPWaMe_mz2VwvvjGsIP2",
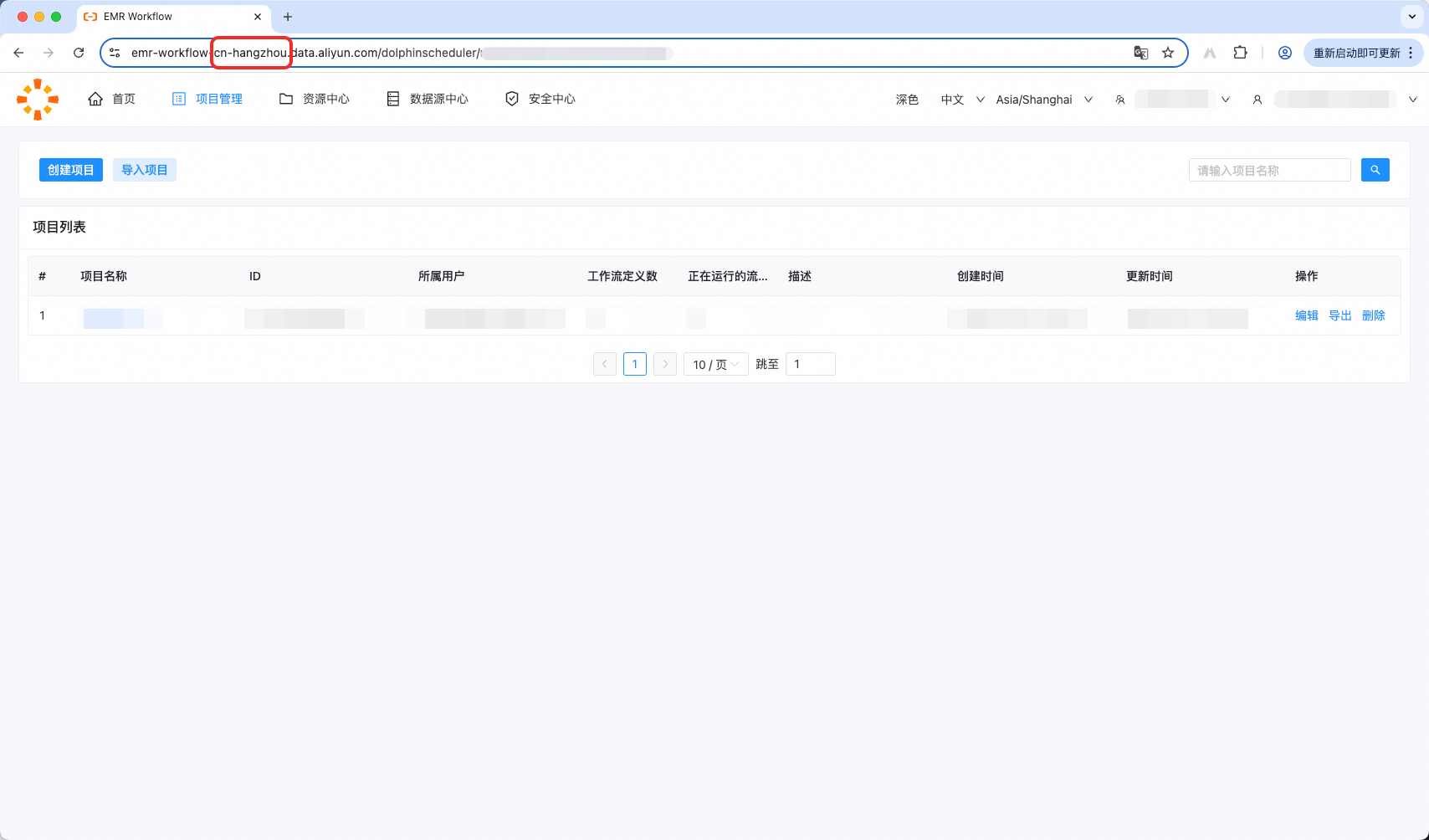
"region": "cn-hangzhou" // Region
},
"operaterType": "AUTO"
},
"conf": {
}
}2.1 工作空间名称与ID
打开EMR Workbench - Workflow控制台,获取工作空间名称与ID。
2.2 Cookie
由于工具通过前端接口获取调度信息,因此需要获取Cookie信息。用户可以打开浏览器开发者工具,在页面上进行任意操作,触发一次接口调用,从而在Headers中获取Cookie。请注意,Cookie会定期失效,工具导出前请更新Coockie。
2.3 Region
地区为枚举值,可从EMR Workflow的URL地址中获取。
3 EMR Workflow定义文件下载
利用EMR Workflow页面上的导出能力,下载工作流定义至本地。定义为json文件。
4 运行调度探查工具
调度探查工具的主要能力是解析、盘点EMR Workflow及其任务信息。将产生一个文件:
探查工具解析包,是对原始信息的数据结构标准化(简称ReaderOuput包)。
ReaderOutput是调度导出的最终结果。
探查工具通过命令行调用,调用命令如下:
sh ./bin/run.sh read \
-c ./conf/<你的配置文件>.json \
-f ./data/0_OriginalPackage/<EMR Workflow定义文件>.json \
-o ./data/1_ReaderOutput/<源端探查导出包>.zip \
-t emr-workflow-reader其中-c为配置文件路径,-f为EMR Workflow定义文件存储路径(见第三章),-o为ReaderOutput包存储路径,-t为探查插件名称。
例如,当前需要导出项目A:
sh ./bin/run.sh read \
-c ./conf/projectA_read.json \
-f ./data/0_OriginalPackage/47000000000.json \
-o ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-t emr-workflow-reader5 查看导出结果
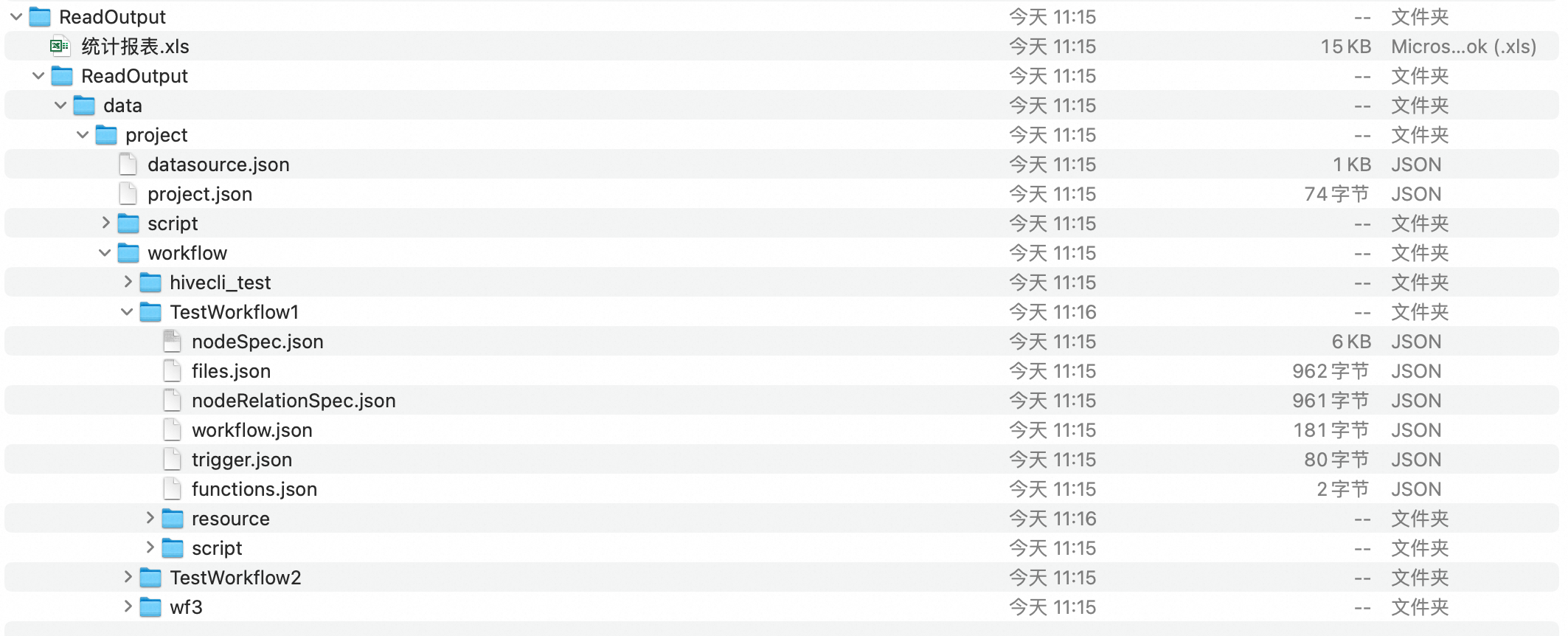
打开./data/1_ReaderOutput/下的生成包ReaderOutput.zip,可预览导出结果。
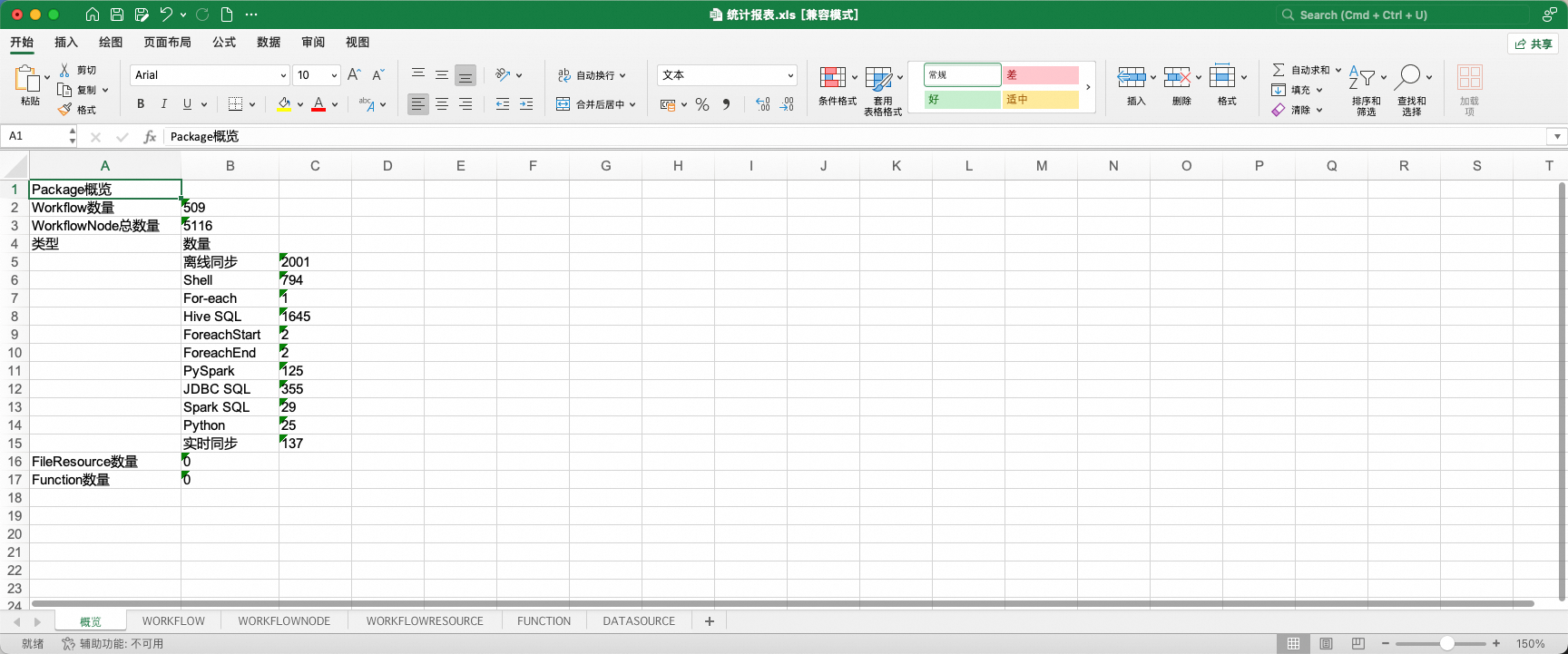
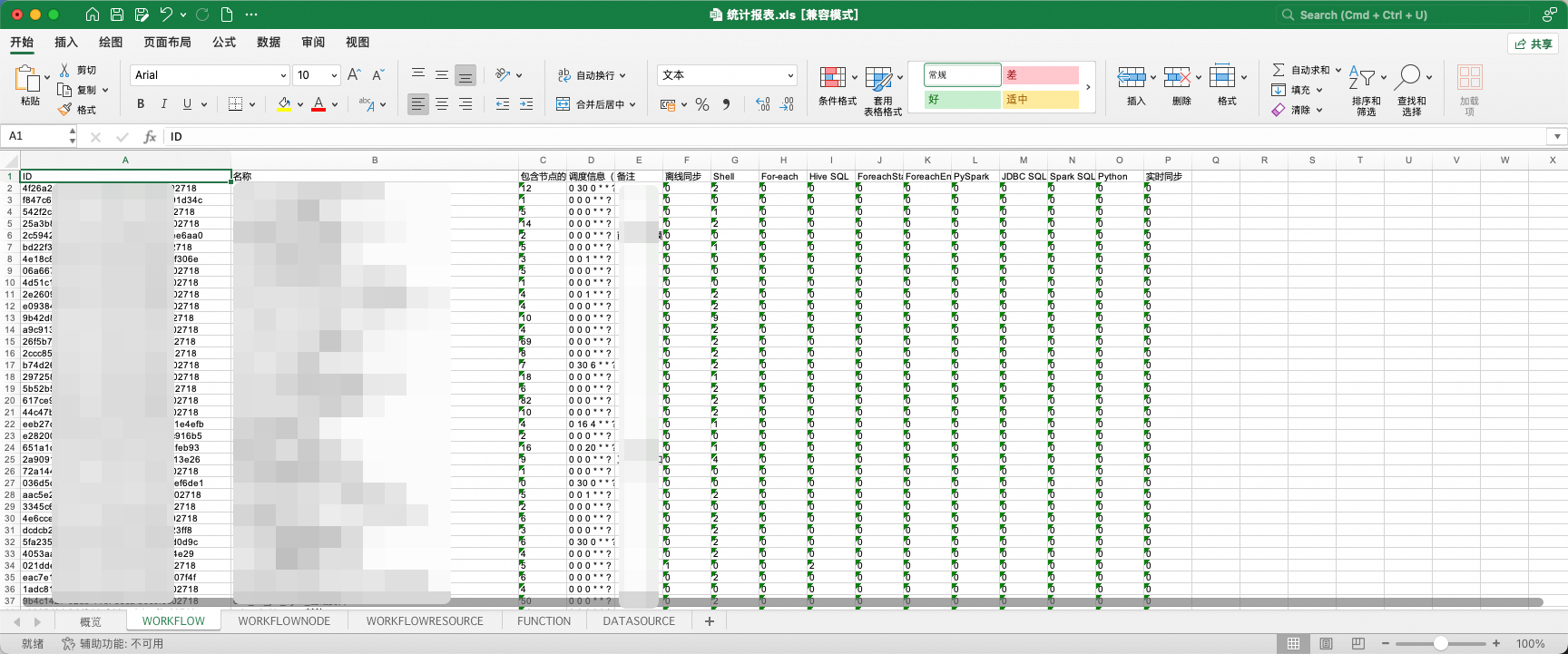
其中,统计报表是对EMR Workflow中任务流、节点、资源、函数、数据源基本信息的汇总展示。
而data/project文件夹下是对EMR Workflow调度信息数据结构标准化后的结果。
统计报表提供了两项特殊能力:
1、报表中工作流、节点的部分属性被允许更改,允许更改的字段以蓝色字体标识。在下一阶段调度转换中,在初始化阶段,工具将获取表格中的属性变更并使其生效。
2、报表允许通过删除工作流子表中的行,使得在转换时跳过这些工作流(工作流黑名单)。注意!若工作流存在相互依赖关系,相关联的工作流需要同批次转换,不可通过黑名单进行分割。分割会产生异常!
二、EMR Workflow->DataWorks任务流转换
1 前置条件
探查工具运行完成,EMR Workflow调度信息被成功导出,ReaderOutput.zip被成功生成。
(可选,推荐)打开探查导出包,查看统计报表,核对待迁移范围是否被导出完全。
2 转换配置项
2.1 转换配置项模板
使用前请删除json中的注释。
{
"conf": {},
"self": {
"if.use.default.convert": false,
"if.use.migrationx.before": false,
"if.use.dataworks.newidea": true,
"conf": [
{
"nodes": "all",
"rule": {
"settings": {
"workflow.converter.sql.submitAs": {
"HIVE": "ODPS_SQL",
"PRESTO": "ODPS_SQL",
"STARROCKS": "ODPS_SQL"
},
"workflow.converter.impalaShell.submitAs": "ODPS_SQL",
"workflow.converter.remoteShell.submitAs": "SSH",
"workflow.converter.shellNodeType": "DIDE_SHELL",
"workflow.converter.spark.submitAs": {
"JAVA": "ODPS_SPARK",
"PYTHON": "ODPS_SPARK",
"SQL": "ODPS_SQL"
},
"workflow.converter.target.engine.type": "MaxCompute",
"workflow.converter.target.unknownNodeTypeAs": "DIDE_SHELL",
"workflow.converter.mrNodeType": "ODPS_MR",
"workflow.converter.commandSqlAs": "DIDE_SHELL",
"workflow.converter.connection.mapping": {
"HiveSource": "hesheng_maxcompute_test4",
"PrestoSource": "hesheng_maxcompute_test4",
"SrSource": "hesheng_maxcompute_test4",
"SshSource": "sshecs1"
}
}
}
}
]
},
"schedule_datasource": {},
"target_schedule_datasource": {}
}2.2 责任人映射
EMR Workflow会记录任务流的所属用户,对于团队开发而言,所属用户是非常关键的信息。工具支持通过配置EMR Workflow用户与DataWorks用户的映射,对任务流和节点标记相应的责任人。
EMR Workflow用户未暴露于前端,可在项目管理页面打开浏览器开发者工具,在get-user-info中获取用户id。如下图,用户的id为430。
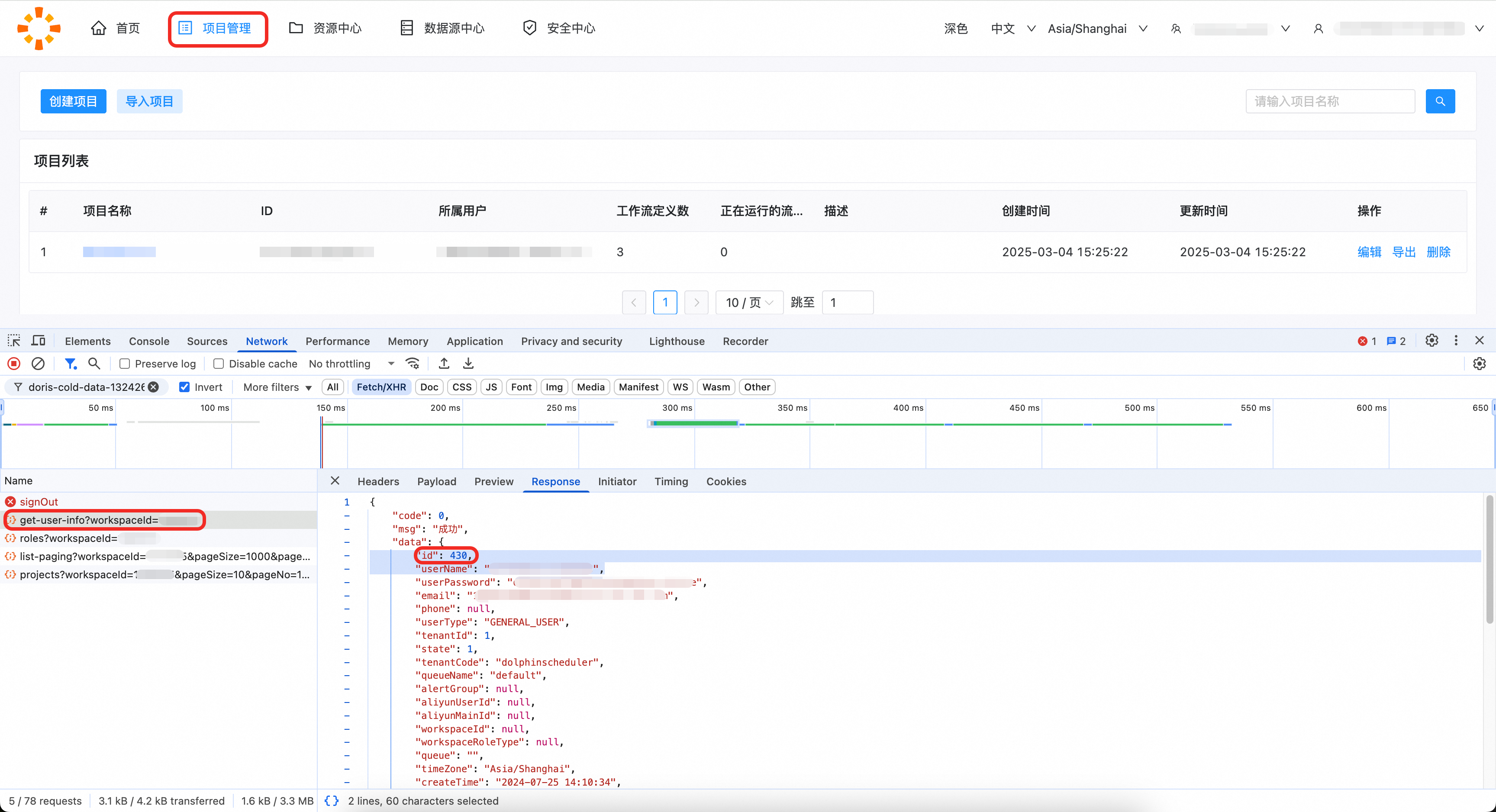
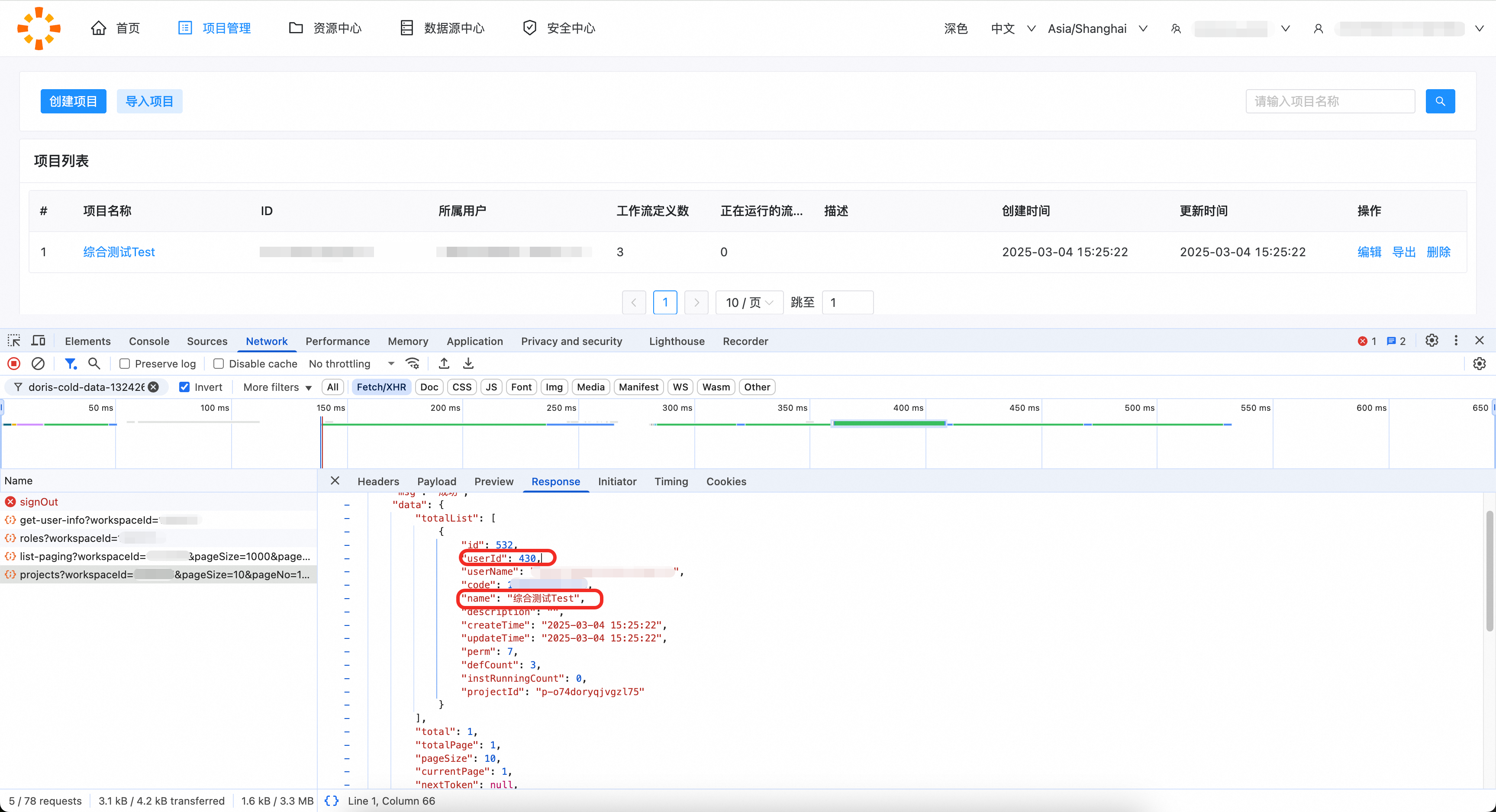
Workflow所属用户的id可通过projects请求查看。
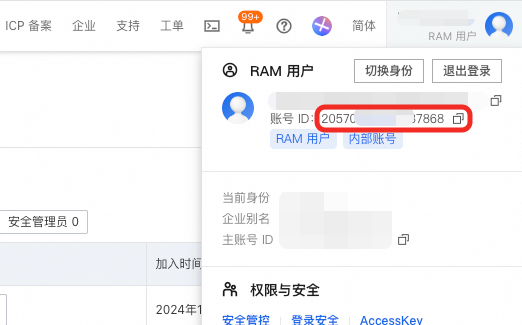
DataWorks工作空间中可以添加用户作为工作空间的成员,用户ID可以在右上角获取。
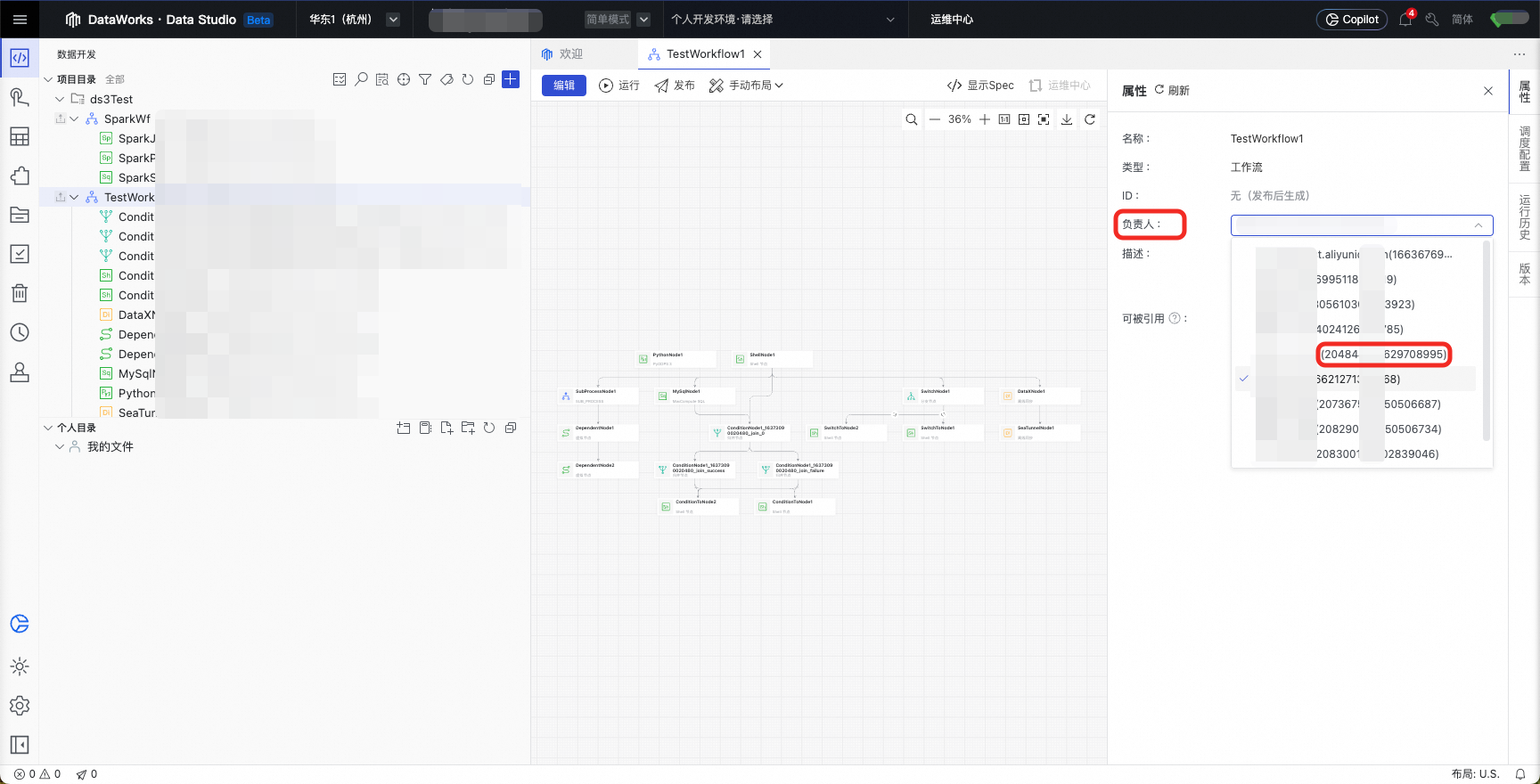
也可以在数据开发页面,责任人下拉框中获取ID。
2.3 节点转换规则
2.3.1 规则的生效范围
节点转换规则的配置规则可设置生效范围,如所有节点按统一规则转换,可以配置"nodes": "all"并填写Settings。通常,用户只需要配置一个all规则组即可。
{
"conf": {},
"self": {
"conf": [
{
"nodes": "all", // 规则组生效范围为ALL,所有节点依据此规则转换
"rule": {
"settings": {
// Settings
}
}
]
}
}如部分节点使用独立的转换规则,可以在nodes中填写任务ID/Name以指定规则的生效范围,需为一批节点设置时可使用逗号分隔填写生效范围。建议使用ID指定,使用Name指定可能导致误设置。此处也支持使用正则表达式匹配节点名称。此外,强烈建议设置一个normal规则组,为其余节点设置一个默认转换规则。
{
"conf": {},
"self": {
"conf": [
{
"nodes": "node1Name, node2Id", // 规则组生效范围为node1、node2
"rule": {
"settings": {
// Settings 1
}
},
{
"nodes": "node3Name, node4Id", // 规则组生效范围为node3、node4
"rule": {
"settings": {
// Settings 2
}
},
{
"nodes": "regexExpression", // 支持用正则表达式对节点名称进行筛选
"rule": {
"settings": {
// Settings 3
}
},
{
"nodes": "normal", // 其余节点的转换规则
"rule": {
"settings": {
// Settings 4
}
}
]
}
}2.3.2 转换规则
工具当前支持转换的EMR Workflow节点包括以下类型:
SHELL、SQL、PYTHON、DATAX、SQOOP、SEATUNNEL、HIVECLI、SPARK、IMPALASHELL、REMOTESHELL、MR、PROCEDURE、HTTP、CONDITIONS、SWITCH、DEPENDENT、SUB_PROCESS
其中可配置DataWorks映射规则的包括以下类型:
· SHELL(workflow.converter.shellNodeType):
推荐转换为DIDE_SHELL, EMR_SHELL, VIRTUAL节点等。
· SQL(workflow.converter.sql.submitAs):
源端数据库类型包括SSH、DORIS、STARROCKS、PRESTO、HIVE。
推荐转换为各类SQL节点、数据库节点等。
· PROCEDURE(workflow.converter.dolphinscheduler.sqlNodeTypeMapping):
推荐转换为各类SQL节点、数据库节点等。
· PYTHON(workflow.converter.pyNodeType):
推荐转换为PYTHON, PYODPS, PYODPS3, EMR_SHELL等。
· HIVECLI(workflow.converter.dolphinscheduler.sqlNodeTypeMapping/HIVE):
推荐转换为EMR_HIVE, ODPS_SQL等。
· SPARK(workflow.converter.sparkSubmitAs):
SparkJava、SparkPython推荐转换为ODPS_SPARK, EMR_SPARK;
SparkSql推荐转换为ODPS_SQL, EMR_SPARK_SQL。
· IMPALASHELL(workflow.converter.impalaShell.submitAs):
推荐转换为ODPS_SQL等节点。
· REMOTESHELL(workflow.converter.remoteShell.submitAs):
推荐转换为SSH等节点。
· MR(workflow.converter.mrNodeType):
推荐转换为ODPS_MR, EMR_MR。
DataWorks节点类型可参考此枚举类:
固定转换规则的节点类型:
· DATAX: 转换为DI节点,支持自定义模板模式(JSON Script模式)和常规模式(前端填写模式)。
支持以下数据源读插件配置项转换:MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb;
支持以下数据源写插件配置项转换:MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb。
· SQOOP: 转换为DI节点。
支持以下数据源读插件配置项转换:Mysql -> mysql, Hive -> hive, HDFS -> hdfs;
支持以下数据源写插件配置项转换:Mysql -> mysql, Hive -> hive, HDFS -> hdfs。
· SEATUNNEL: 转换为DI节点。
暂未支持脚本转换,仅转换节点和调度信息。
· HTTP: 转换为DIDE_SHELL(通用Shell)节点,迁移工具将请求参数自动拼接为curl命令。
· SWITCH: 转换为CONTROLLER_BRANCH(分支)节点,迁移前后功能一致。
· SUB_PROCESS: 转换为SUB_PROCESS节点,迁移前后功能一致;注意,在导入DataWorks时,迁移工具将会将被引用的任务流的“可被引用”开关打开,被引用的任务流只能通过SUB_PROCESS的调用而启动,无法自行调度启动。
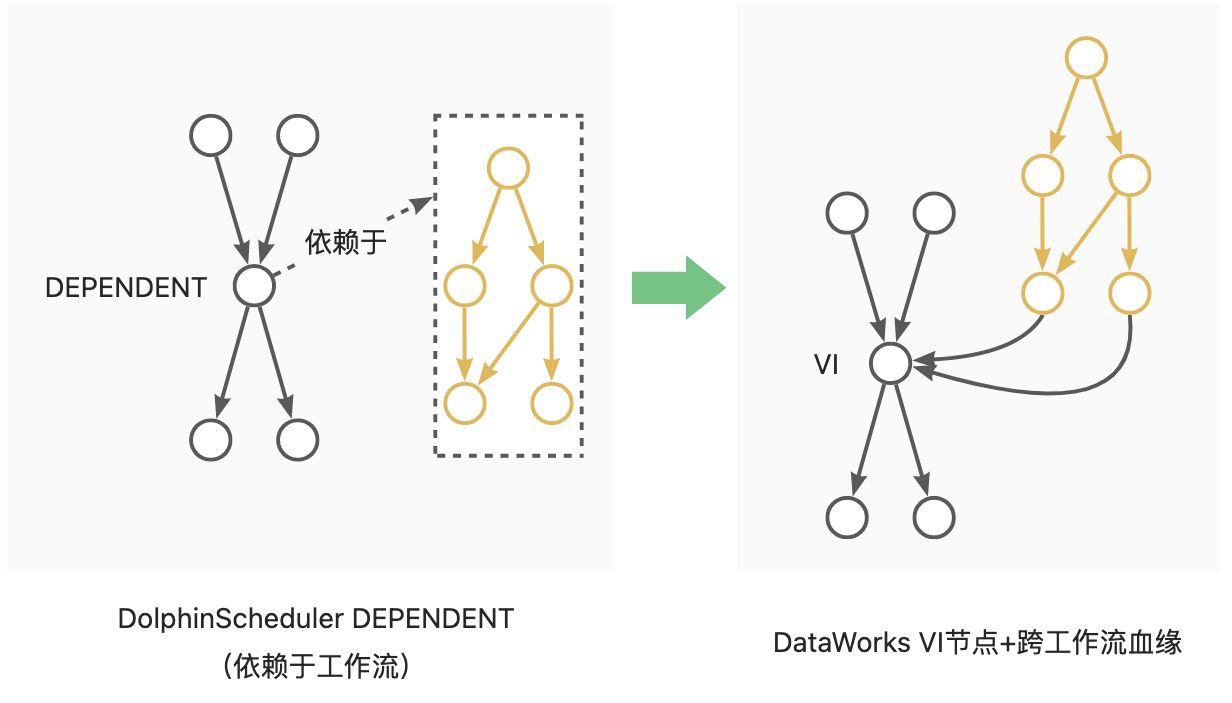
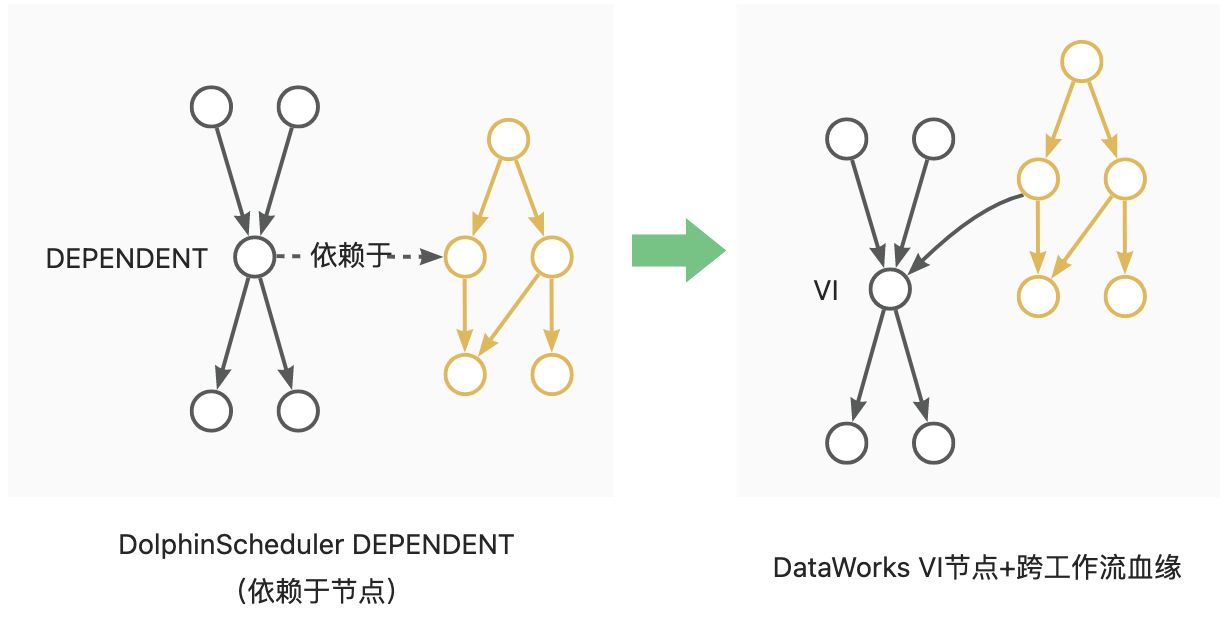
· DEPENDENT: 转换为VITRTUAL节点,依赖关系转换为节点血缘依赖。如Dependent节点依赖于Workflow A时,依赖关系转换为Workflow A尾节点到Dependent节点的血缘;如Dependent节点依赖于Node A,自来关系转换为Node A到Dependent节点的血缘。见下图示意:
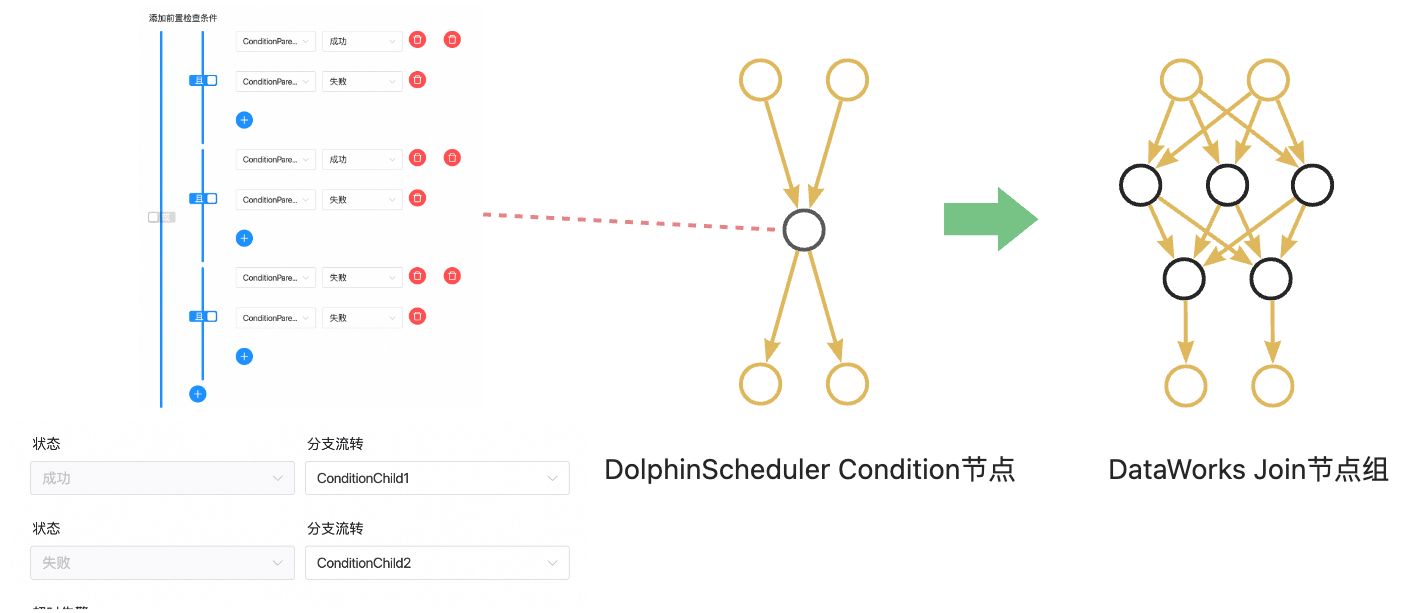
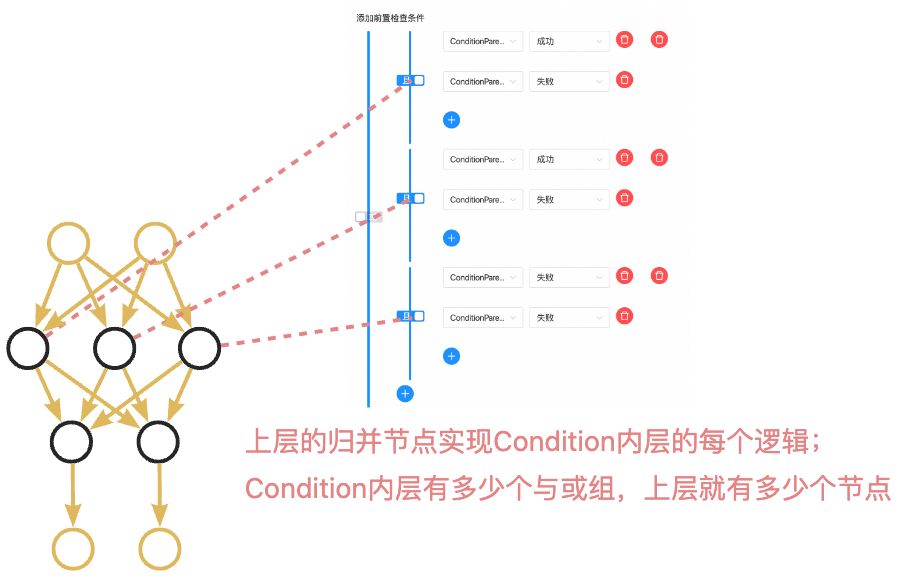
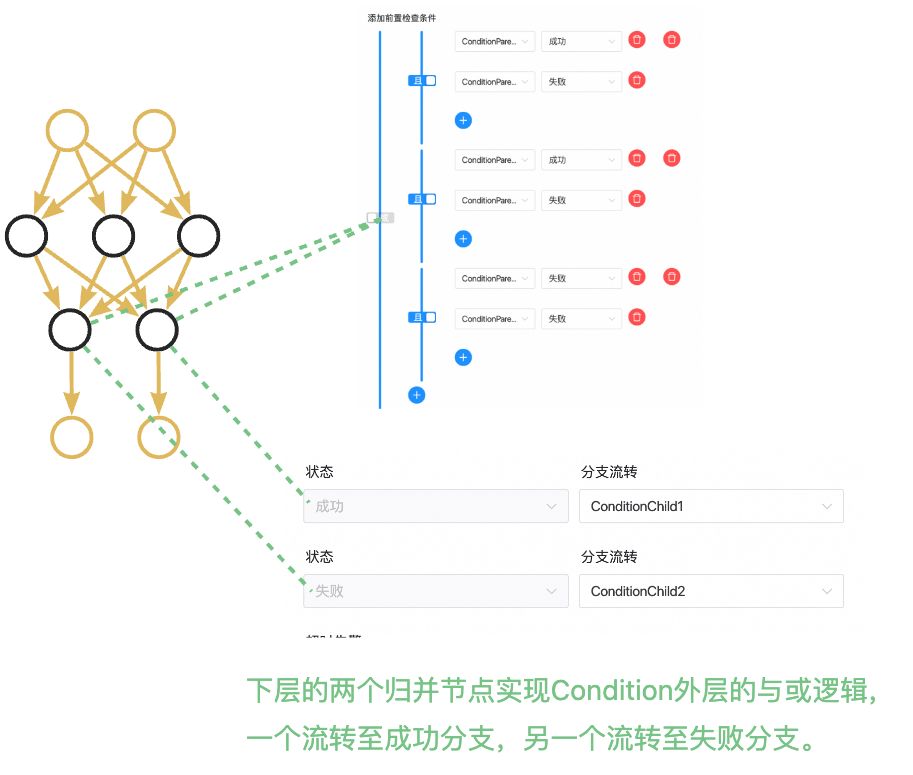
· CONDITIONS: 节点中包含两层逻辑,使用双层CONTROLLER_JOIN(归并)节点进行分别实现。以下图中的Case为例,CONDITIONS有两个上游A和B、两个下游C和D,逻辑表达式为((!A&B)|(A&!B)|(!A&!B)),若为真则流转至C,若为假则流转至D。上层生成了3个归并节点分别用来计算!A&B、A&!B、!A&!B的结果,下层生成了2个节点,其中一个在((!A&B)|(A&!B)|(!A&!B))==true时触发下游C节点执行,另一个在(!(!A&B)&!(A&!B)&!(!A&!B))==true时触发下游D节点执行,以实现CONDITIONS的效果。
3 运行调度转换工具
转换工具通过命令行调用,调用命令如下:
sh ./bin/run.sh convert \
-c ./conf/<你的配置文件>.json \
-f ./data/1_ReaderOutput/<源端探查导出包>.zip \
-o ./data/2_ConverterOutput/<转换结果输出包>.zip \
-t emrworkflow-dw-converter其中-c为配置文件路径;-f为ReaderOutput包存储路径;-o为ConverterOutput包存储路径;-t为转换插件。
例如,当前需要转换的EMR Workflow项目A:
sh ./bin/run.sh convert \
-c ./conf/projectA_convert.json \
-f ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-o ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-t emrworkflow-dw-converter转换工具运行中将打印过程信息,请关注运行过程中是否有报错。转换完成后将在命令行中打印转换成功与失败的统计信息。注意,部分节点的转换失败不会影响整体转换流程,如遇少量节点转换失败,可在迁移至DataWorks后进行手动修改。
4 查看转换结果
打开./data/2_ConverterOutput/下的生成包ConverterOutput.zip,可预览导出结果。
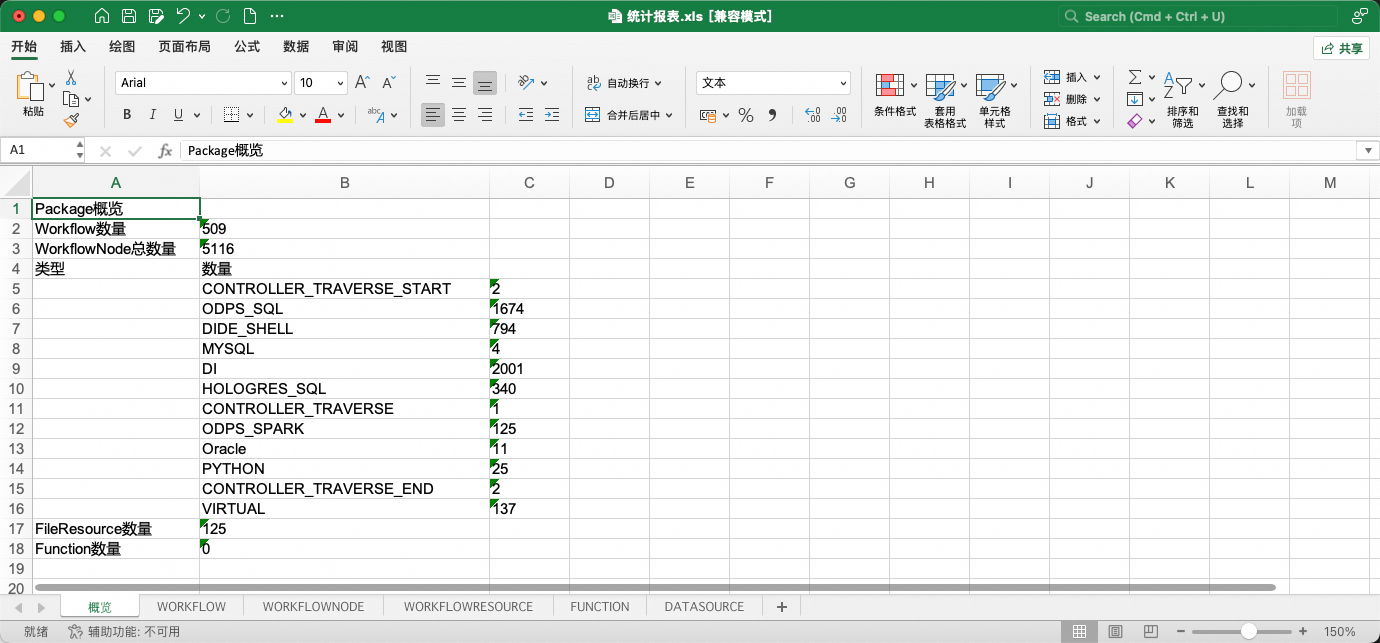
其中,统计报表是对转换结果任务流、节点、资源、函数、数据源基本信息的汇总展示。
而data/project文件夹是转换完成的调度迁移包本体。
统计报表提供了两项特殊能力:
1、报表中工作流、节点的部分属性被允许更改,允许更改的字段以蓝色字体标识。在下一阶段导入DataWorks时,工具将获取表格中的属性变更并使其生效。
2、报表允许通过删除工作流子表中的行,使得在导入DataWorks时跳过这些工作流(工作流黑名单)。注意!若工作流存在相互依赖关系,相关联的工作流需要同批次导入,不可通过黑名单进行分割。分割会产生异常!
三、导入DataWorks
LHM迁移工具异构转换已将迁移源端的调度元素转换为DataWorks调度格式,工具得以针对不同的迁移场景提供了统一的上传入口,实现任务流导入DataWorks。
导入工具支持多轮刷写,会自动选择创建/更新任务流(OverWrite模式)。
1 前置条件
1.1 转换成功
转换工具运行完成,源端调度信息被成功转换为DataWorks调度信息,ConverterOutput.zip被成功生成。
(可选,推荐)打开转换输出包,查看统计报表,核对待迁移范围是否被转换成功。
1.2 DataWorks侧配置
DataWorks侧需进行以下动作:
1、创建工作空间。
2、创建AK、SK且保证AK、SK对工作空间具有管理员权限。(强烈建议建立与账号有绑定关系的AK、SK,以便在写入遇到问题时进行排查)
3、在工作空间中建立数据源、绑定计算资源、创建资源组。
4、在工作空间中上传文件资源、创建UDF。
1.3 网络连通性检查
验证能否连接DataWorks Endpoint。
服务接入点列表:
ping dataworks.aliyuncs.com2 导入配置项
在工程目录的conf文件夹下创建导出配置文件(JSON格式),如writer.json。
使用前请删除json中的注释。
{
"schedule_datasource": {
"name": "YourDataWorks", //给你的DataWorks数据源起个名字!
"type": "DataWorks",
"properties": {
"endpoint": "dataworks.cn-hangzhou.aliyuncs.com", // 服务接入点
"project_id": "YourProjectId", // 工作空间ID
"project_name": "YourProject", // 工作空间名称
"ak": "************", // AK
"sk": "************", // SK
},
"operaterType": "MANUAL"
},
"conf": {
"di.resource.group.identifier": "Serverless_res_group_***_***", // 调度资源组
"resource.group.identifier": "Serverless_res_group_***_***", // 数据集成资源组
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls", // DataWorks节点类型表的路径
"qps.limit": 5 // 向DataWorks发送API请求的QPS上限
}
}2.1 服务接入点
根据DataWorks所在Region选择服务接入点,参考文档:
2.2 工作空间ID与名称
打开DataWorks控制台,打开工作空间详情页,从右侧基本信息中获取工作空间ID与名称。
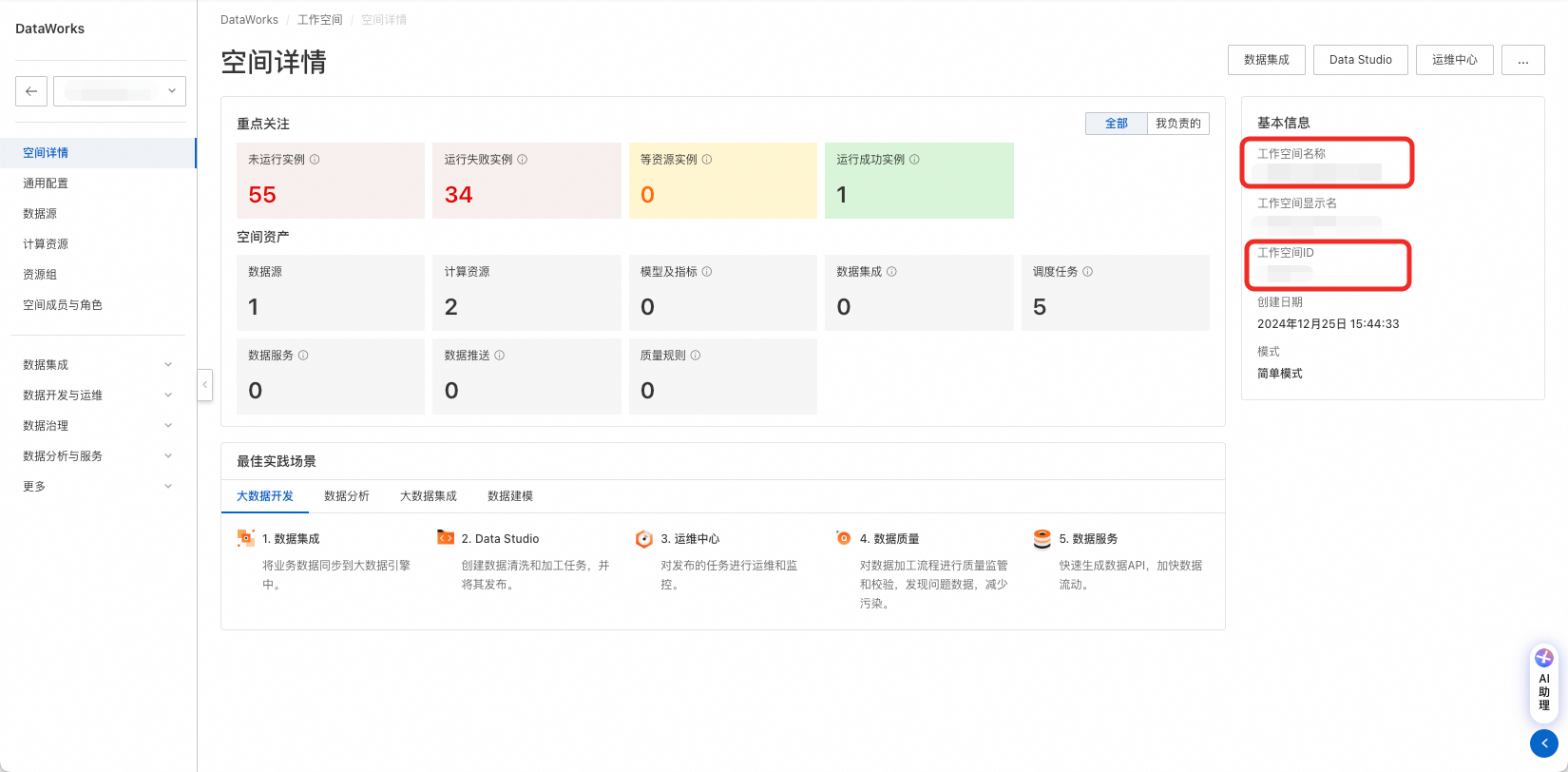
2.3 创建AK、SK并授权
在用户页创建AK、SK,要求对目标DataWorks工作空间拥有管理员读写权限。
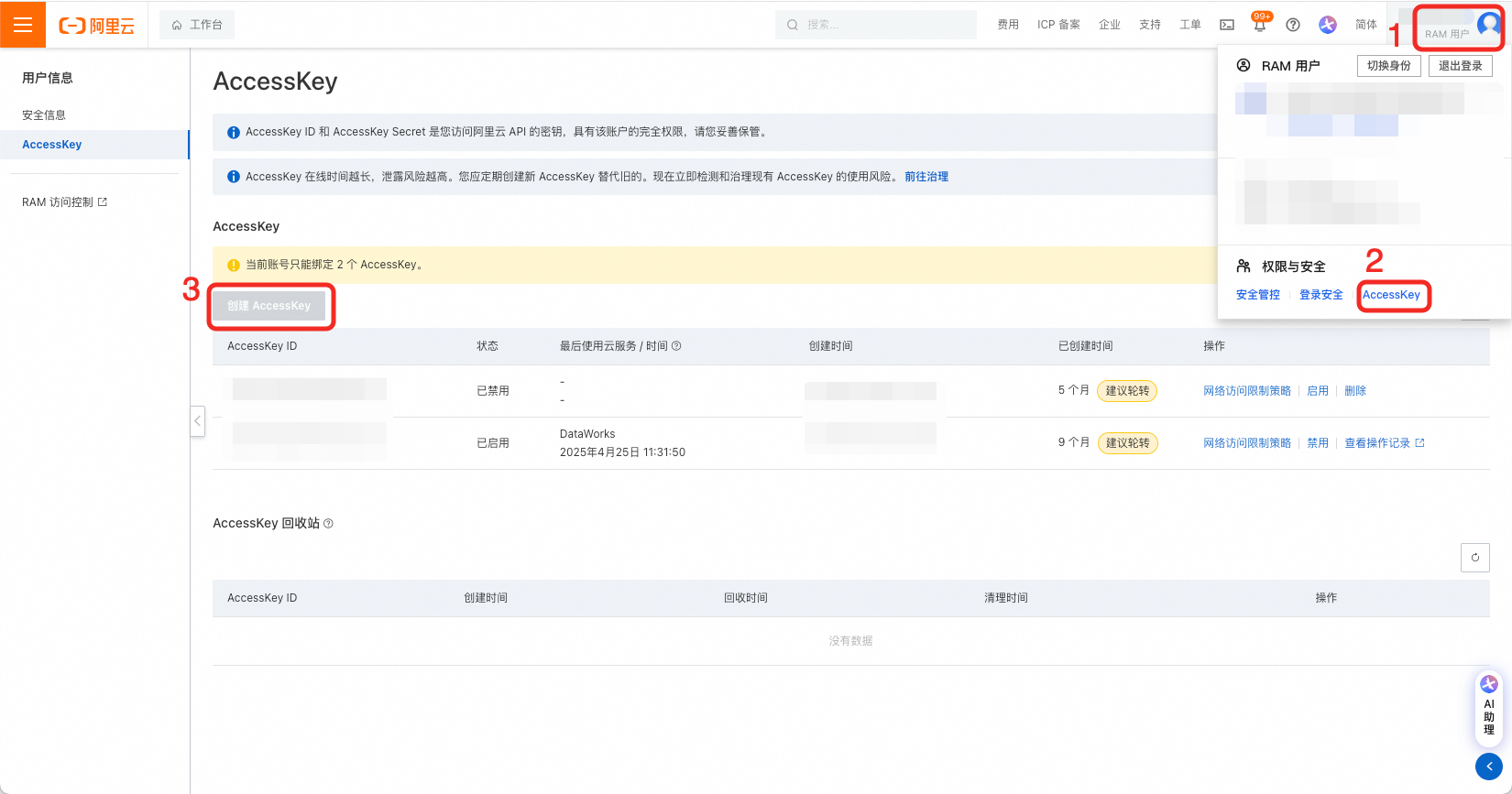
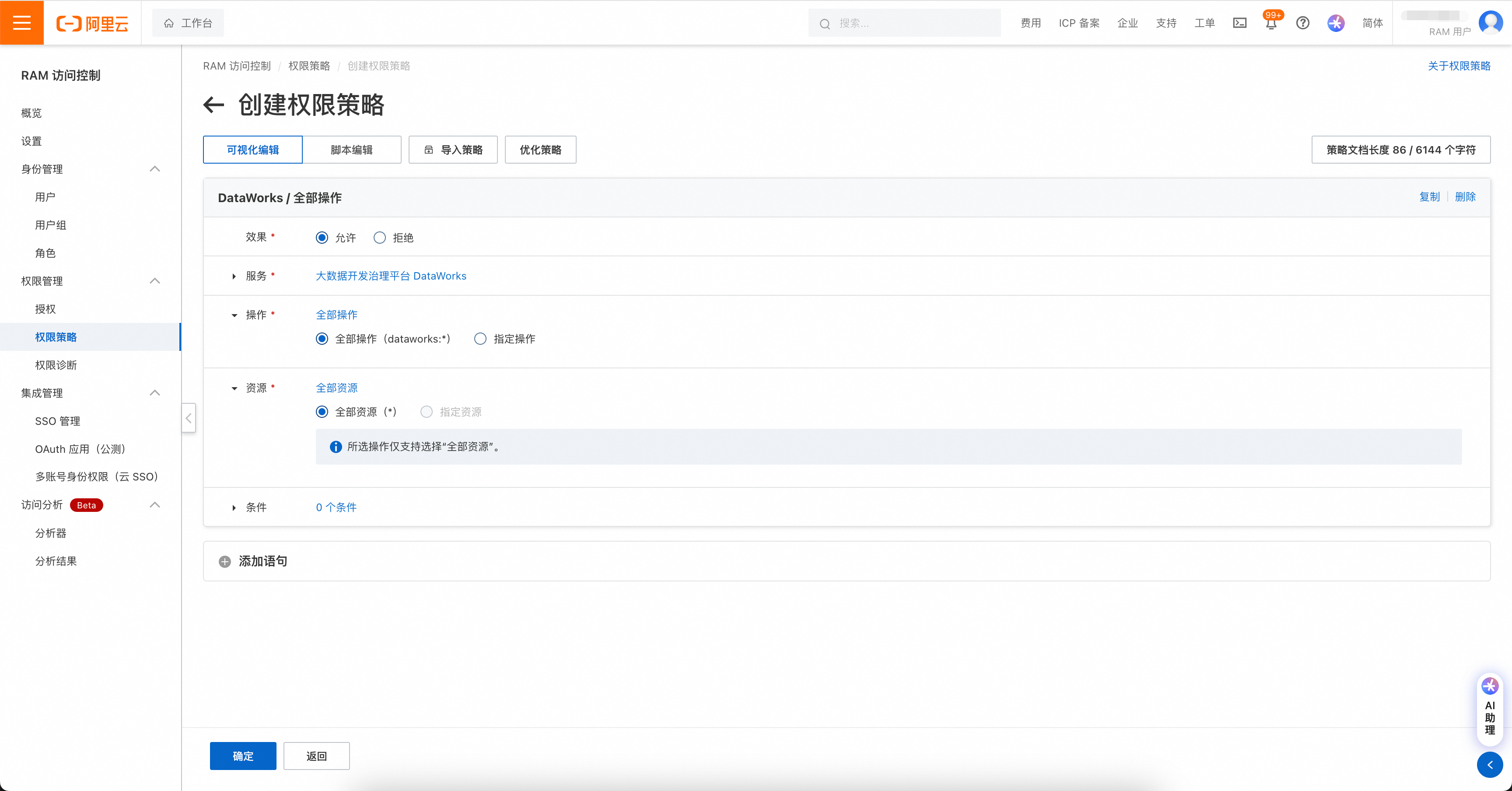
权限管理包括两处,如果账号是RAM账号,则需先对RAM账号进行DataWorks操作授权。
权限策略页面:https://ram.console.aliyun.com/policies
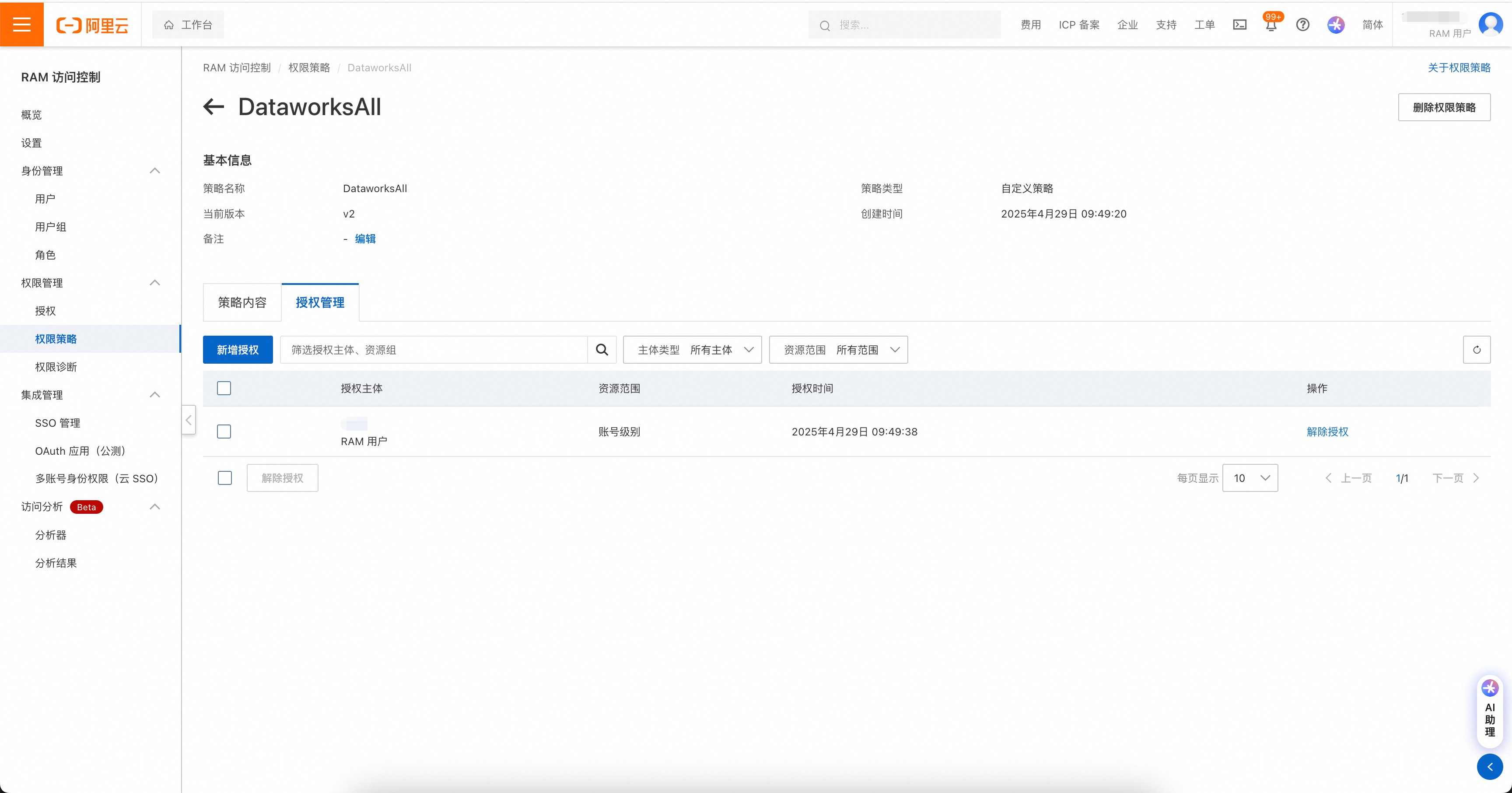
然后在DataWorks工作空间中,将工作空间权限赋给账号。
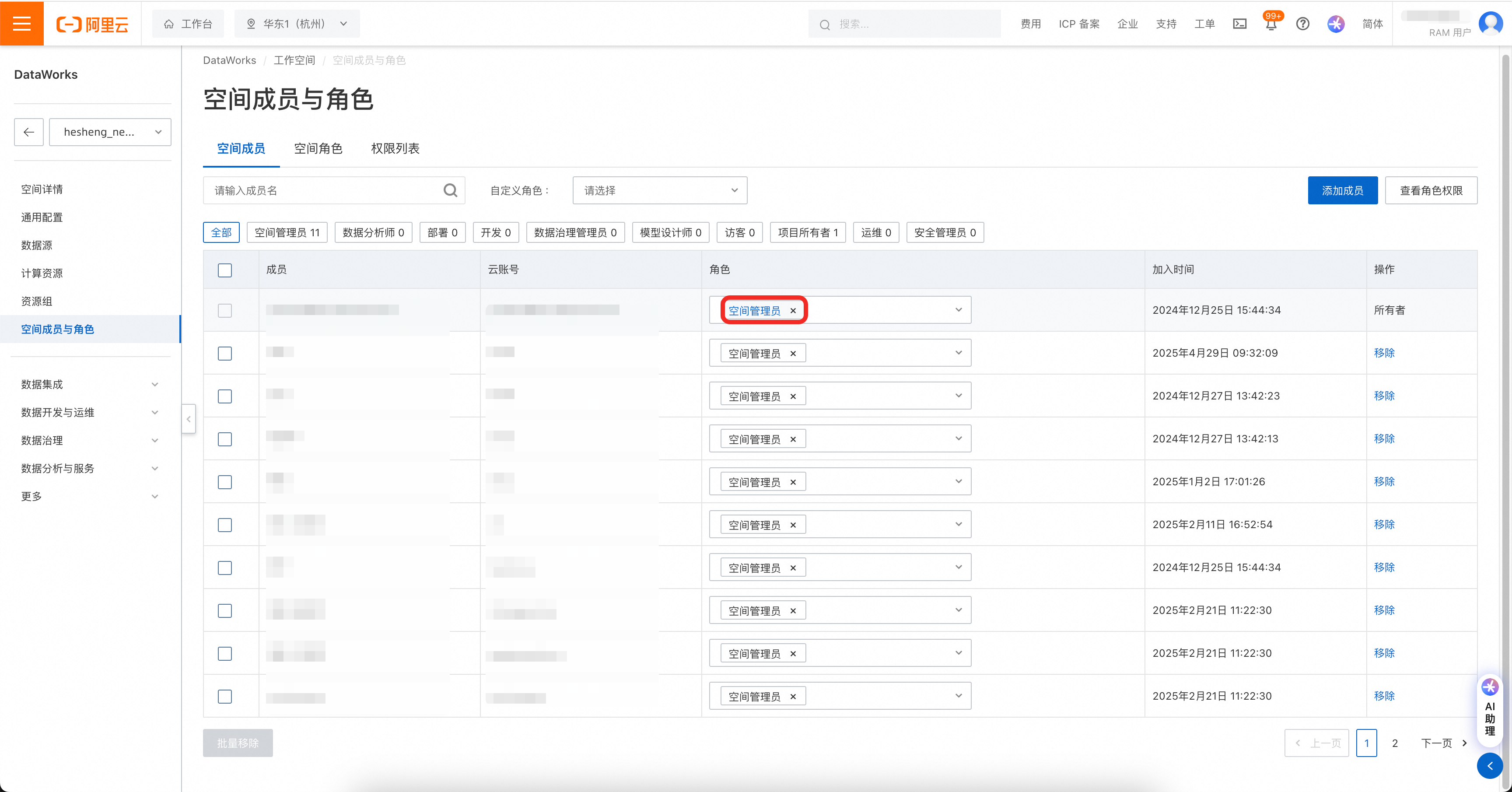
注意!AccessKey可设置网络访问限制策略,请务必保证迁移工具所在机器的IP被允许访问。
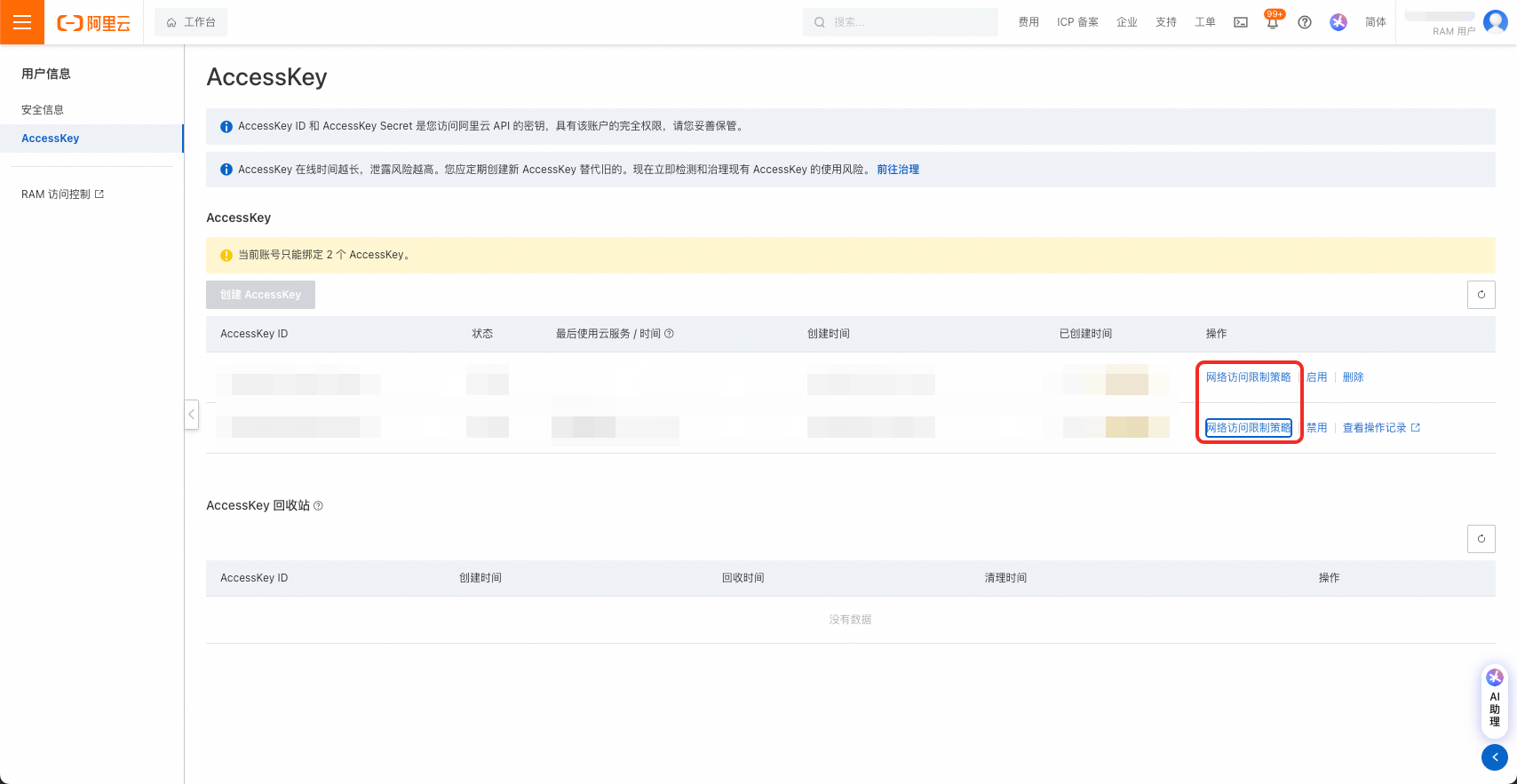
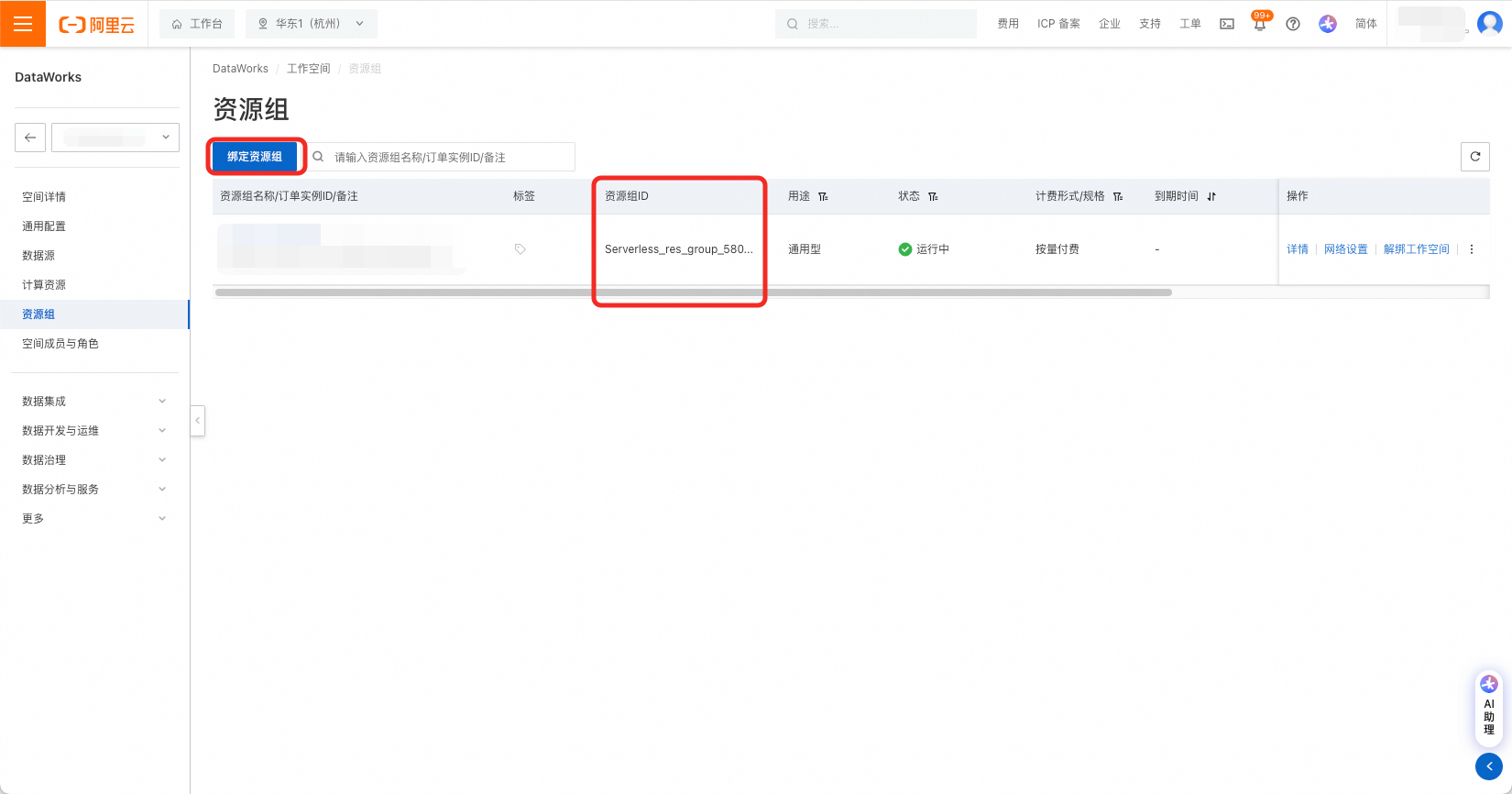
2.4 资源组
由DataWorks工作空间详情页左侧菜单栏进入资源组页面,绑定资源组,并获取资源组ID。
通用资源组可用于节点调度,也可用于数据集成。配置项中调度资源组resource.group.identifier和数据集成资源组di.resource.group.identifier可以配置为同一通用资源组。
2.5 QPS设置
工具通过调用DataWorks的API进行导入操作。不同DataWorks版本中的读、写OpenAPI分别有相应的QPS限制和每日调用次数限制,详见链接:使用限制。
DataWorks基础版、标准版、专业版建议填写"qps.limit": 5,企业版建议填写"qps.limit": 20。
注意,请尽可能避免多个导入工具同时运行。
2.6 DataWorks节点类型ID设置
在DataWorks中,部分节点类型在不同Region中被分配了不同的TypeId。具体TypeID以DataWorks数据开发实际界面为准。存在此特性的节点类型以数据库节点为主:数据库节点。
如:MySQL节点在杭州Region的NodeTypeId为1000039、在深圳Region的NodeTypeId为1000041。
为适应上述DataWorks不同Region的差异特性,工具提供了一种可配置的方式,允许用户配置工具所使用的节点TypeId表。
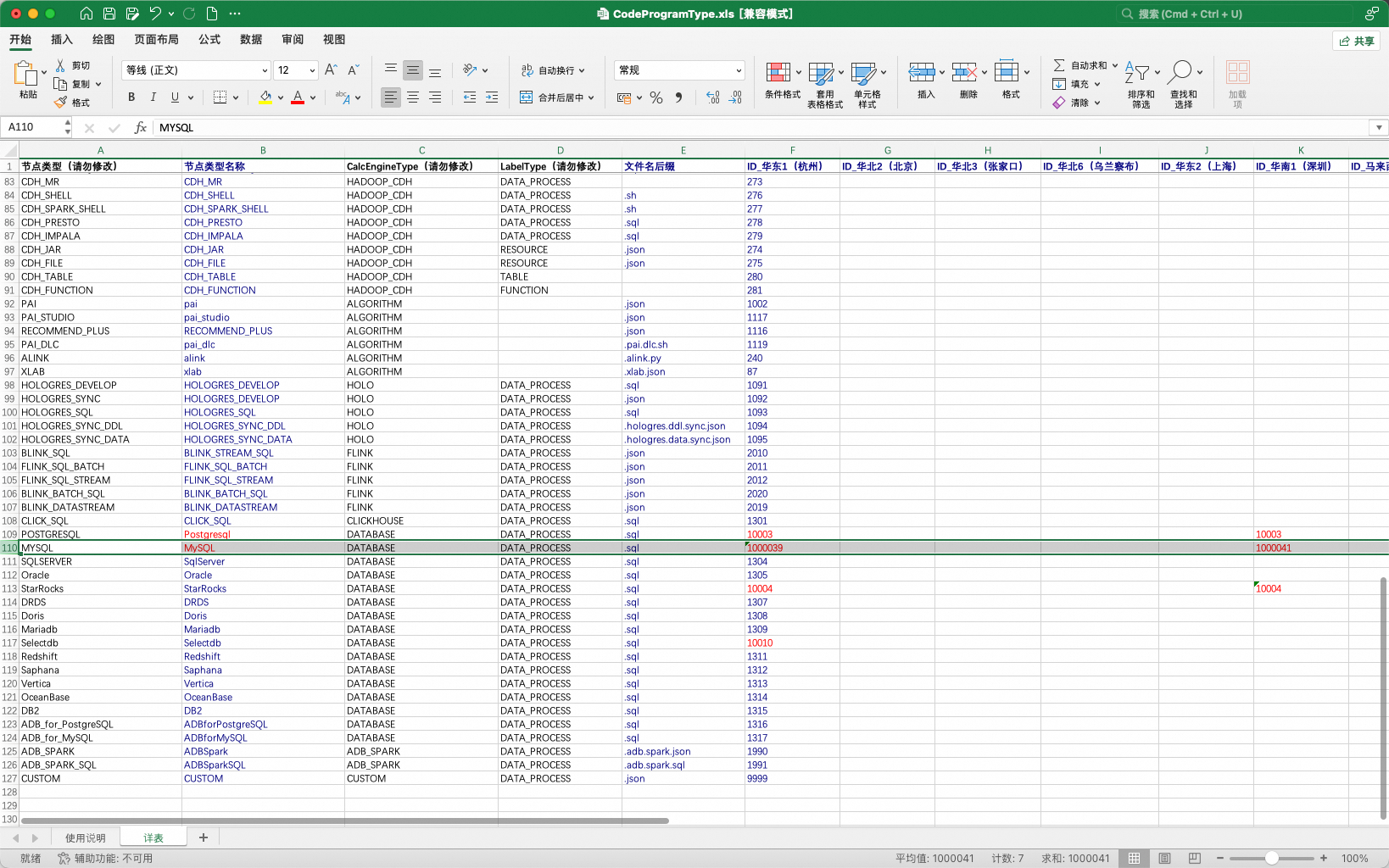
表格通过导入工具的配置项引入:
"conf": {
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls" // DataWorks节点类型表的路径
}从DataWorks数据开发界面上获取节点类型Id的方法:在界面上新建一个工作流,并在工作流中新建一个节点,在点击保存后查看工作流的Spec。
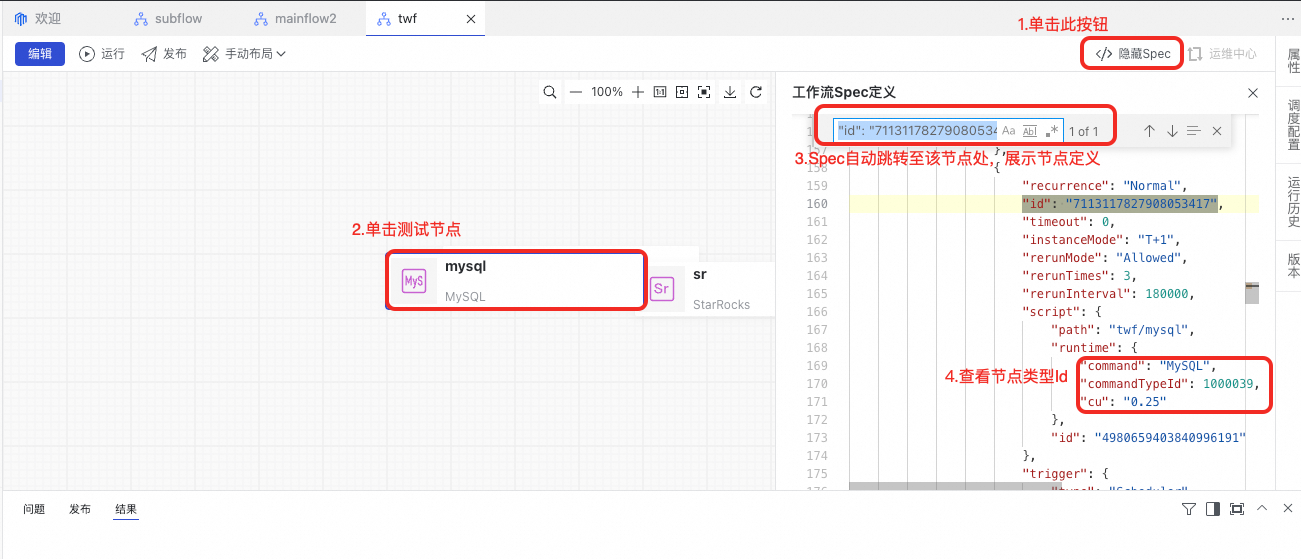
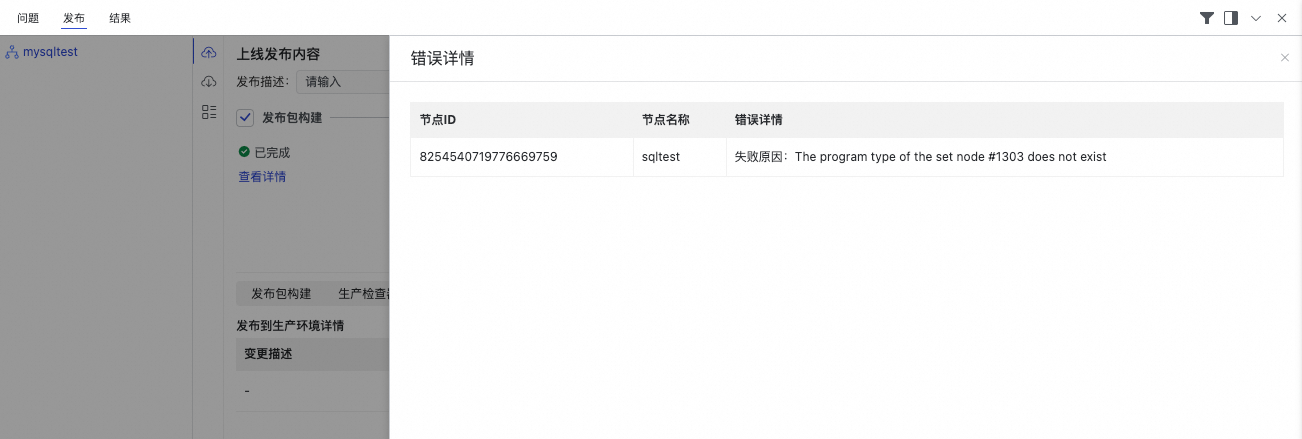
若节点类型配置错误,在任务流发布时将提示以下错误。
3 运行DataWorks导入工具
转换工具通过命令行调用,调用命令如下:
sh ./bin/run.sh write \
-c ./conf/<你的配置文件>.json \
-f ./data/2_ConverterOutput/<转换结果输出包>.zip \
-o ./data/4_WriterOutput/<导入结果存储包>.zip \
-t dw-newide-writer其中-c为配置文件路径,-f为ConverterOutput包存储路径,-o为WriterOutput包存储路径,-t为提交插件名称。
例如,当前需要导入DataWorks的项目A:
sh ./bin/run.sh write \
-c ./conf/projectA_write.json \
-f ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-o ./data/4_WriterOutput/projectA_WriterOutput.zip \
-t dw-newide-writer导入工具运行中将打印过程信息,请关注运行过程中是否有报错。导入完成后将在命令行中打印导入成功与失败的统计信息。注意,部分节点的导入失败不会影响整体导入流程,如遇少量节点导入失败,可在DataWorks中进行手动修改。
4 查看导入结果
导入完成后,可在DataWorks中查看导入结果。导入过程中亦可查看工作流逐个导入的过程,如发现问题需要终止导入,可运行jps命令找到BwmClientApp,并使用kill -9终止导入。
5 Q&A
5.1 源端持续在进行开发,这些增量与变更如何提交到DataWorks?
迁移工具为OverWrite模式,重新运行导出、转换、导入可实现将源端增量提交到DataWorks的能力。请注意,工具将根据全路径匹配任务流以选择创建任务流/更新任务流。如需进行变更迁移,请勿移动任务流。
5.2 源端持续在进行开发,同时进行DataWorks上任务流改造与治理,增量迁移时是否会覆盖DataWorks上的变更?
是的,迁移工具为OverWrite模式,建议您在完成迁移后再在DataWorks上进行后续改造。或者采用分批迁移的方式,已迁移等任务流再确认不再刷写后开始DataWorks改造,不同批次之间互相不会影响。
5.3 整个包导入耗时太长,能否只导入一部分
可以,可手动裁剪待导入包来实现部分导入:将data/project/workflow文件夹下需要导入的任务流保留、其他任务流删除,重新压缩回压缩包,再运行导入工具。注意,存在相互依赖的任务流需要捆绑导入,否则任务流间的节点血缘将会丢失。