
本文通过 基于 Spark 的管道读写 的方式将 Synapse 数据表通过 Spark 管道读写的方式迁移到 MaxCompute,包括将 Synapse 存量数据迁移到 MaxCompute。
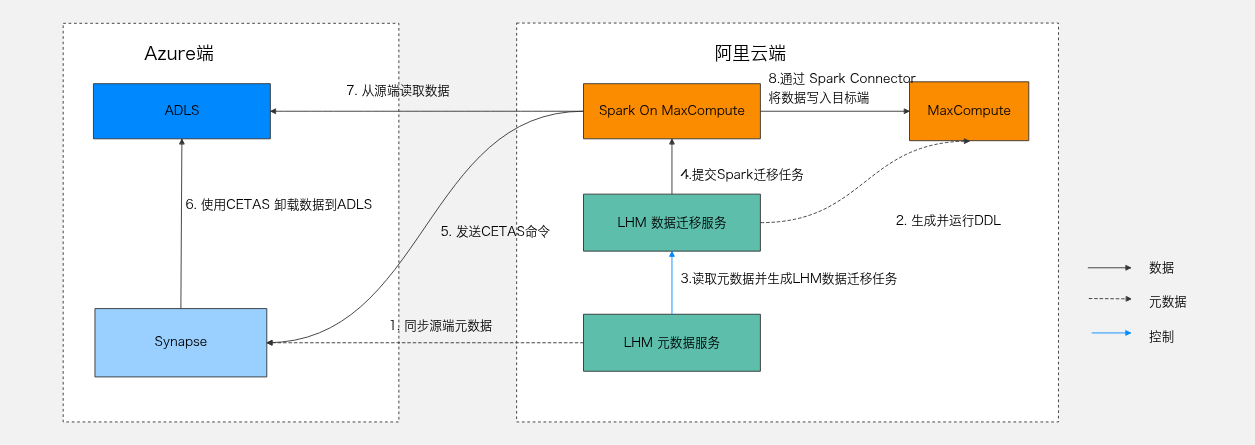
原理架构
适用范围
当前仅杭州、新加坡地域支持该功能。
前提条件
已创建实例,规格建议2核4G,操作系统建议 Alibaba Cloud Linux、CentOS 7.9,安装前请先开通私网连接服务。
已创建MaxCompute项目,并且用于迁移的账号具备以下权限:
已具备在 MaxCompute 项目中创建表(CreateTable)的权限。表操作的权限信息请参见 MaxCompute权限。
打通访问 Synapse集群的网络,具体操作,请参见网络开通流程。
已创建工作空间,并使用Serverless资源组,完成绑定工作空间,同时打通源端 Synapse 集群的网络。具体操作,请参见网络连通方案概述。
已准备好待迁移数据。
由于迁移程序在 Azure Synapse 侧依赖
EXTERNAL DATASOURCE功能,因此需要对应的账号具备较高的Control权限。若客户无法提供此级别的权限,可通过在迁移组配置中提供synapse.external.datasource相关配置项来规避该要求。
使用限制
目前不支持结构迁移。
计费说明
数据迁移会产生如下费用:
计算费用:将 Synapse 数据复制到 MaxCompute 时,会产生 DataWorks 资源组的数据计算费用。为降低成本,建议您采用包年包月模式的资源组来执行迁移作业。详情请参见包年包月资源组计费。
中转存储费用:迁移任务使用 Azure Data Lake Storage 作为中转存储,会产生相应的存储费用。迁移程序在迁移后会自动删除对应的临时存储,来节省您的存储开销。
网络费用:网络费用取决于您的连接方式。如果使用专线,将产生专线费用;如果通过公网传输,则通常按源端平台的数据流出流量进行计费。
操作步骤
步骤一:绑定资源组
在左侧导航栏,选择迁移准备 > 资源组与服务代理管理。
在资源组页签,单击绑定资源组,选择 DataWorks Serverless 资源组。
资源组绑定完成后,您可以在资源组页签,查看已绑定的资源组。
步骤二:安装服务代理
在使用数据迁移模块前,您需要预先安装服务代理,它会建立与数据源的连接,以执行元数据即席查询、元数据盘点等操作。
在左侧导航栏,选择迁移准备 > 资源组与服务代理管理。
在服务代理页签,单击申请License,会自动生成一个License,防止服务代理被滥用。
单击服务代理安装,输入服务代理名称,选择地域与ECS,即可自动化部署安装。
安装完成后,可通过服务代理列表查看服务代理在线状态。
步骤三:创建数据源
在左侧导航栏,选择迁移准备 > 数据源管理。
在湖仓存储及元数据管理页签,单击新建数据源。
配置 Synapse 数据源,数据源类型选择
AzureSynapse,详情见 Synapse数据源。配置 ADLS 数据源,数据源类型选择
AzureDataLakeStorage,详情见 ADLS数据源。配置 MaxCompute 数据源,数据源类型选择
MaxCompute,详情见 MaxCompute数据源。
步骤四:添加迁移组
在左侧导航栏,选择湖仓数据迁移 > 数据迁移。
在Synapse->MaxCompute页签,点击添加迁移组。
根据界面提示,配置迁移组。
参数名 | 是否必填 | 说明 |
迁移组名称 | 是 | 迁移组的名称。用于统一管理特定迁移场景下的所有相关任务。 |
源端数据源类型 | 是 | 指定数据来源的系统类型,当前仅支持 AzureSynapse。 |
目标端数据源类型 | 是 | 指定数据去向的系统类型,当前仅支持 MaxCompute。 |
源端数据源 | 是 | 从已注册的数据源列表中选择具体的源端 AzureSynapse 实例。 |
目标端数据源 | 是 | 从已注册的数据源列表中选择具体的目标端 MaxCompute 实例。 |
迁移方式 | 是 | 当前仅支持通过ODPS Spark迁移。 |
源端存储数据源 | 是 | 支持 AzureDataLakeStorage。 |
全局参数 | 否 | 自定义参数,用于控制 Synapse 数据加载至 MaxCompute 的行为以及环境配置。具体参数参阅 Spark Connector。 |
一些必填的全局参数说明如下:
参数名 | 示例值 | 备注 |
synapse.adls.temp_dir | abfss://container@storage_account.dfs.core.windows.net/synapse_tmp_dir | 迁移组中源端存储数据源中存储临时文件的目录,需要用户提前建好。 |
synapse.external.datasource | lhm_external_datasource | 提前准备的外部数据源名称,创建参考 Create External Datasource |
spark.hadoop.odps.cupid.eni.info | cn-hangzhou:vpc-bp1m56flshw6hst7cyvjv | 迁移时访问源端资源所需VPC,迁移程序需要通过该VPC网络访问,参考 网络开通流程。 |
spark.hadoop.odps.cupid.eni.info | axi-synapse.sql.azuresynapse.net:1433 | 访问源端资源的地址,用逗号(,)分隔 |
步骤五:环境初始化
在左侧导航栏,选择湖仓数据迁移 > 数据迁移。
在Synapse->MaxCompute页签,选择已经建好的迁移组,点击环境初始化。
步骤六:创建并执行迁移任务
在Synapse->MaxCompute页签,点击新建迁移任务的按钮。
填写基本信息。
参数名 | 是否必填 | 说明 |
迁移任务名称 | 是 | 迁移任务的名称。 |
Synapse数据库 | 是 | 指定作为数据来源的源端 Synapse 数据库。 |
MaxCompute Project | 是 | 指定用于接收数据的目标端 MaxCompute 项目空间。 |
描述 | 否 | 填写关于该迁移任务的备注或补充说明信息。 |
进行迁移任务设置。
参数名 | 是否必填 | 说明 |
迁移类型 | 是 | 指定数据迁移的模式。“结构+存量文件迁移”仅迁移历史存量数据及表结构;“结构+存量+增量文件迁移”在存量基础上增加对后续增量数据的迁移支持。 |
迁移数据对象选择 | 是 | 指定用于筛选迁移对象的规则模式,支持“白名单模式”或“黑名单模式”。具体规则参阅 黑白名单配置。 |
是否开启迁移结果校验(内置count校验) | 是 | 开启后,迁移任务完成后将自动执行源端与目标端的数据量(Count)一致性校验。 |
自定义参数配置 | 否 | 自定义参数,用于控制 Spark 程序运行行为。具体参数参阅 Spark Configuration。 |
一些参数参考如下:
参数名 | 示例值 | 说明 |
spark.executor.cores | 1 | 定义每个 Executor 进程可以使用的 CPU 核心数量 |
spark.executor.memory | 4g | 定义每个 Executor 进程可以使用的内存总量 |
spark.driver.cores | 1 | 定义 Driver 进程可以使用的 CPU 核心数量 |
spark.driver.memory | 4g | 定义 Driver 进程可以使用的内存总量 |
在迁移任务列表页面,找到创建完成的迁移任务,点击操作列的执行迁移。
步骤七:查看迁移任务详情
创建完成后,您可在Synapse->MaxCompute页签,查看迁移任务状态,若迁移任务运行失败后:
您可以单击迁移任务左侧的箭头
v,展开任务执行情况,再点击操作列的任务详情,查看每张表的执行情况。

在迁移明细页面,您可以按照表名、分区名、是否分区表、迁移状态和校验状态等进行筛选,单击目标任务操作列中查看,以确定具体失败原因。

您可以根据需求选择以下方式重跑任务:
重跑所有失败作业:返回迁移任务列表页面,再次点击操作列的执行迁移。
批量重跑指定表/分区:在迁移明细页面底部点击批量重跑,勾选目标表和分区后,点击确定按钮。
重跑单个表/分区:在迁移明细页面找到对应的表或分区,点击操作列的重跑。