
本文介绍了如何使用本工具对DataWorks周期工作流进行批量发布。
1 批量发布能力概述
工具提供了对DataWorks周期任务流批量发布的能力,会自动解析任务流依赖、引用关系,按拓扑顺序依次发布。
2 使用场景
LHM调度迁移工具提供了对DataWorks周期工作流批量发布的能力,支持在两个场景中使用:
2.1 异构迁移场景
使用LHM调度迁移工具进行异构调度迁移后,可基于DataWorksWriter的输出包运行DataWorksDeployer完成本次迁移范围内任务流的批量发布。
完整链路如下:迁移源端调度信息导出(AnyReader) -> 调度转换(AnyConverter) -> 迁移目标端调度导入(DataWorksWriter) -> 批量发布(DataWorksDeployer)。
2.2 对DataWorks工作空间中的已有Workflow批量发布
先使用DataWorks导出工具获取当前DataWorks中的工作流信息,然后基于其输出包运行DataWorksDeployer完成工作空间内所有工作流的批量发布。
链路如下:DataWorks工作流导出(DataWorksReader) -> 批量发布(DataWorksDeployer)
DataWorks导出工具详见:DataWorks 跨空间迁移。
3 运行原理
DataWorksDeployer仅做发布操作,不会修改任何内容。
运行过程如下:
1、结合节点间跨工作流血缘依赖、工作流间血缘依赖、工作流与节点血缘依赖、Sub_Process节点引用关系,进行工作流拓扑排序。
2、按拓扑顺序,针对每个工作流,创建DataWorks工作流上线Pipeline,依次进行发布包构建、生产检查器、发布到生产环境动作。
3、如果某个Workflow发布失败,Deployer将会Cancel其所有下游Workflow发布,非其下游的其他Workflow将正常依序发布。
4 使用方法
4.1 批量发布配置项
在工程目录的conf文件夹下创建导出配置文件(JSON格式),如deploy.json。
· 使用前请删除JSON中的注释。
{
"schedule_datasource": {
"type": "DataWorks",
"properties": {
"endpoint": "dataworks.cn-hangzhou.aliyuncs.com", // 服务接入点
"project_id": "YourProjectId", // 工作空间ID
"project_name": "YourProject", // 工作空间名称
"ak": "************", // AK
"sk": "************", // SK
}
},
"conf": {}
}4.1.1 服务接入点
根据DataWorks所在Region选择服务接入点,参考文档:
4.1.2 工作空间ID与名称
打开DataWorks控制台,打开工作空间详情页,从右侧基本信息中获取工作空间ID与名称。
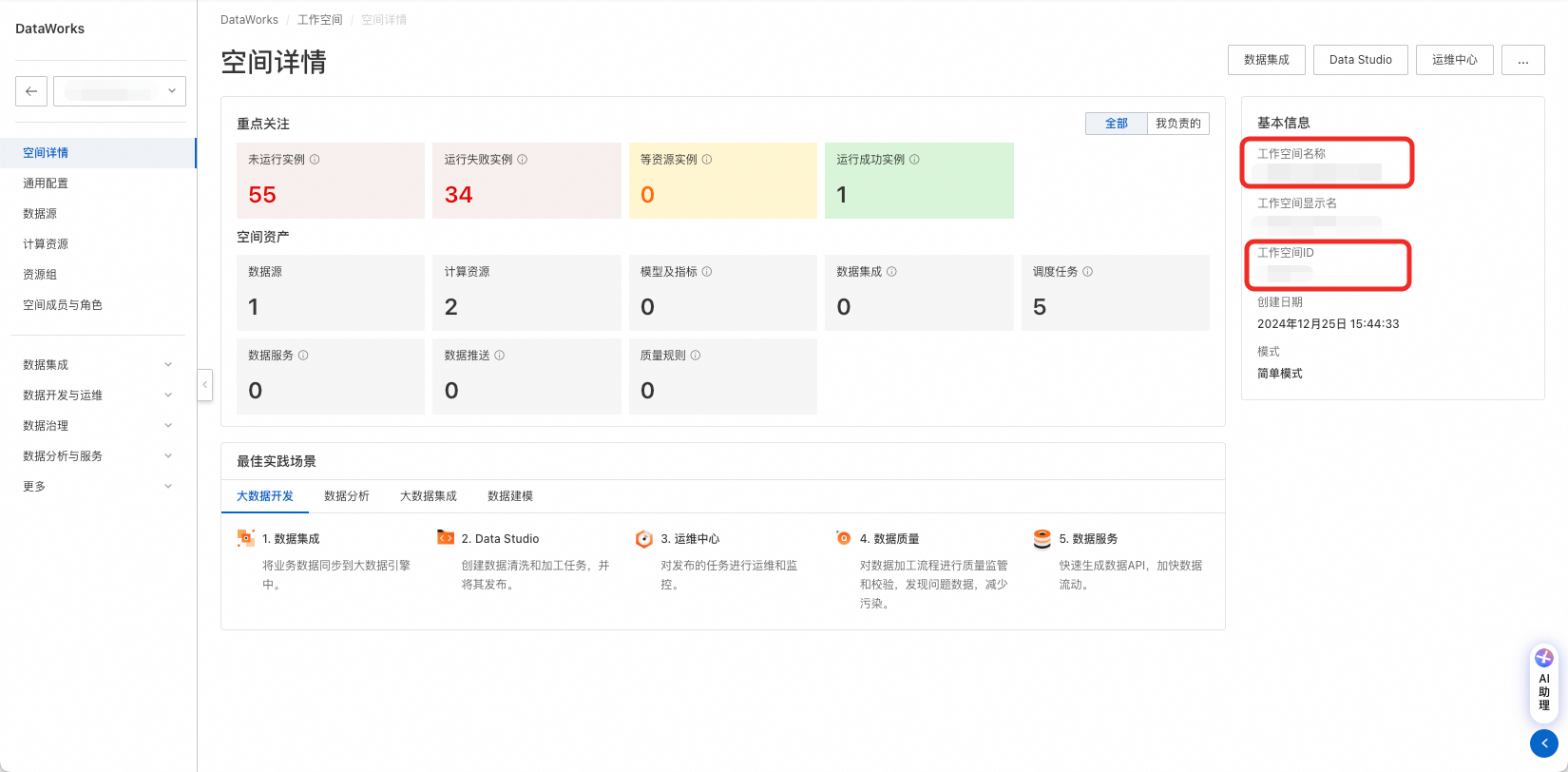
4.1.3 创建AK、SK并授权
在用户页创建AK、SK,要求对目标DataWorks工作空间拥有管理员读写权限。
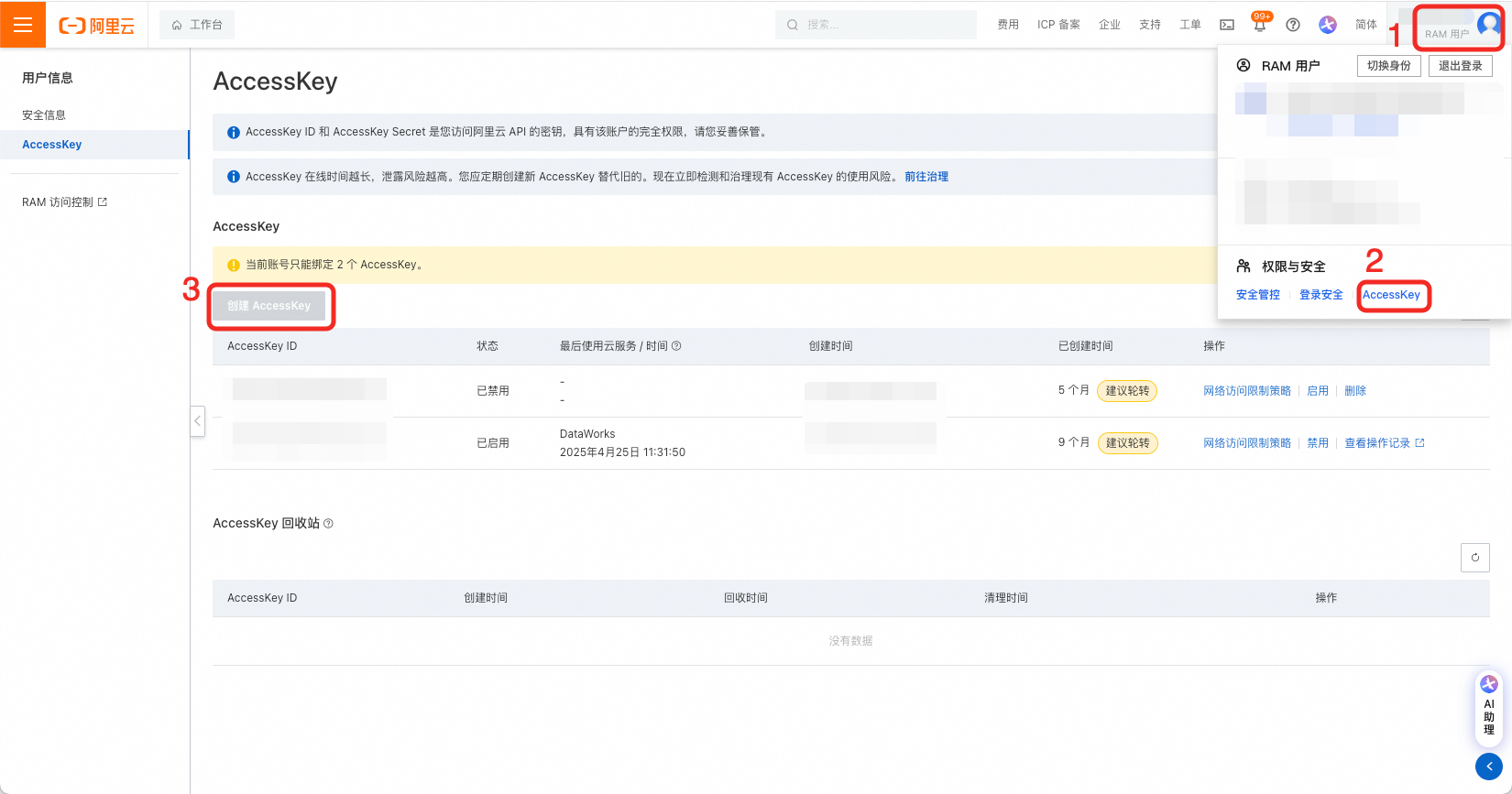
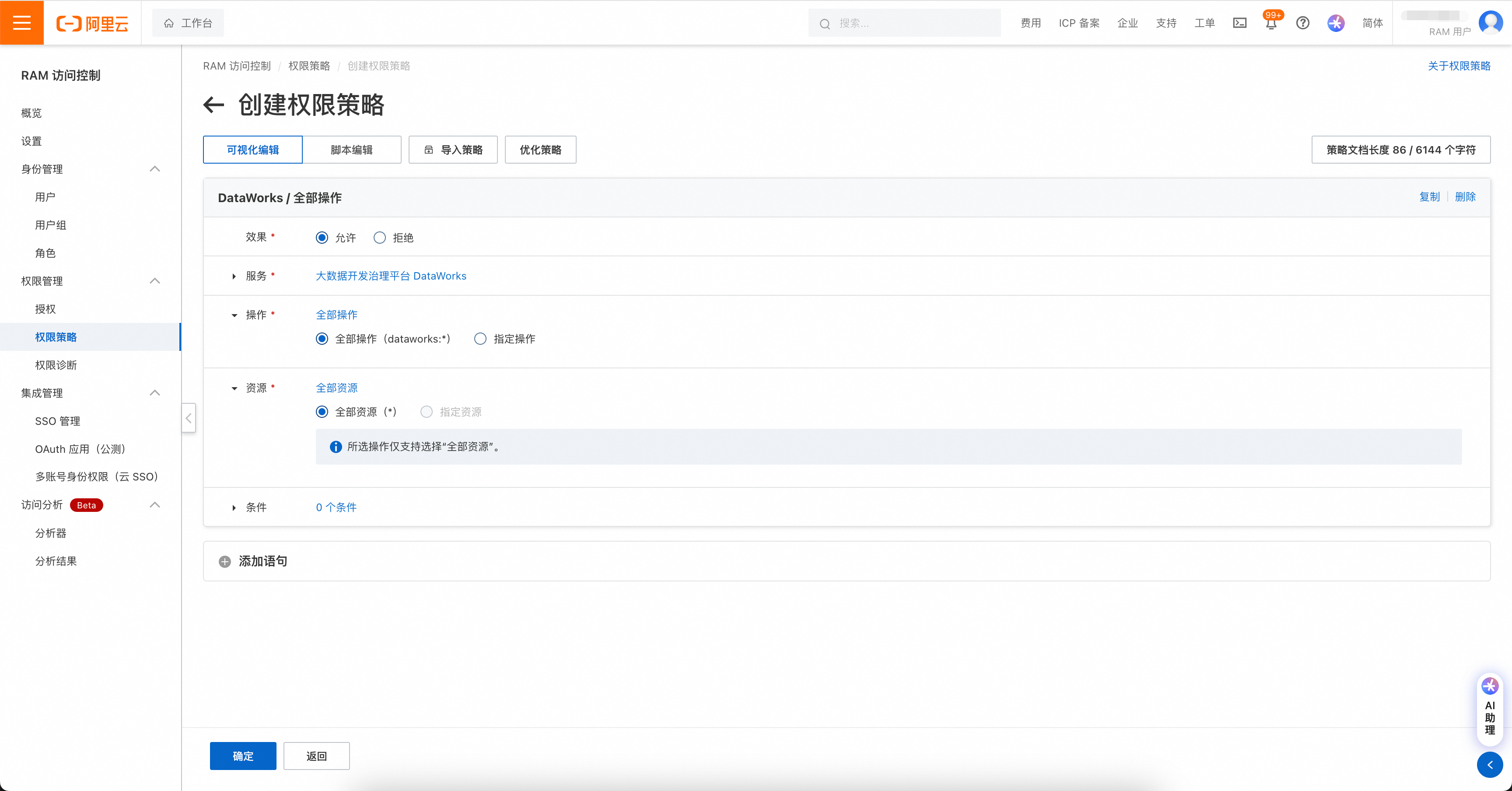
权限管理包括两处,如果账号是RAM账号,则需先对RAM账号进行DataWorks操作授权。
权限策略页面:https://ram.console.aliyun.com/policies
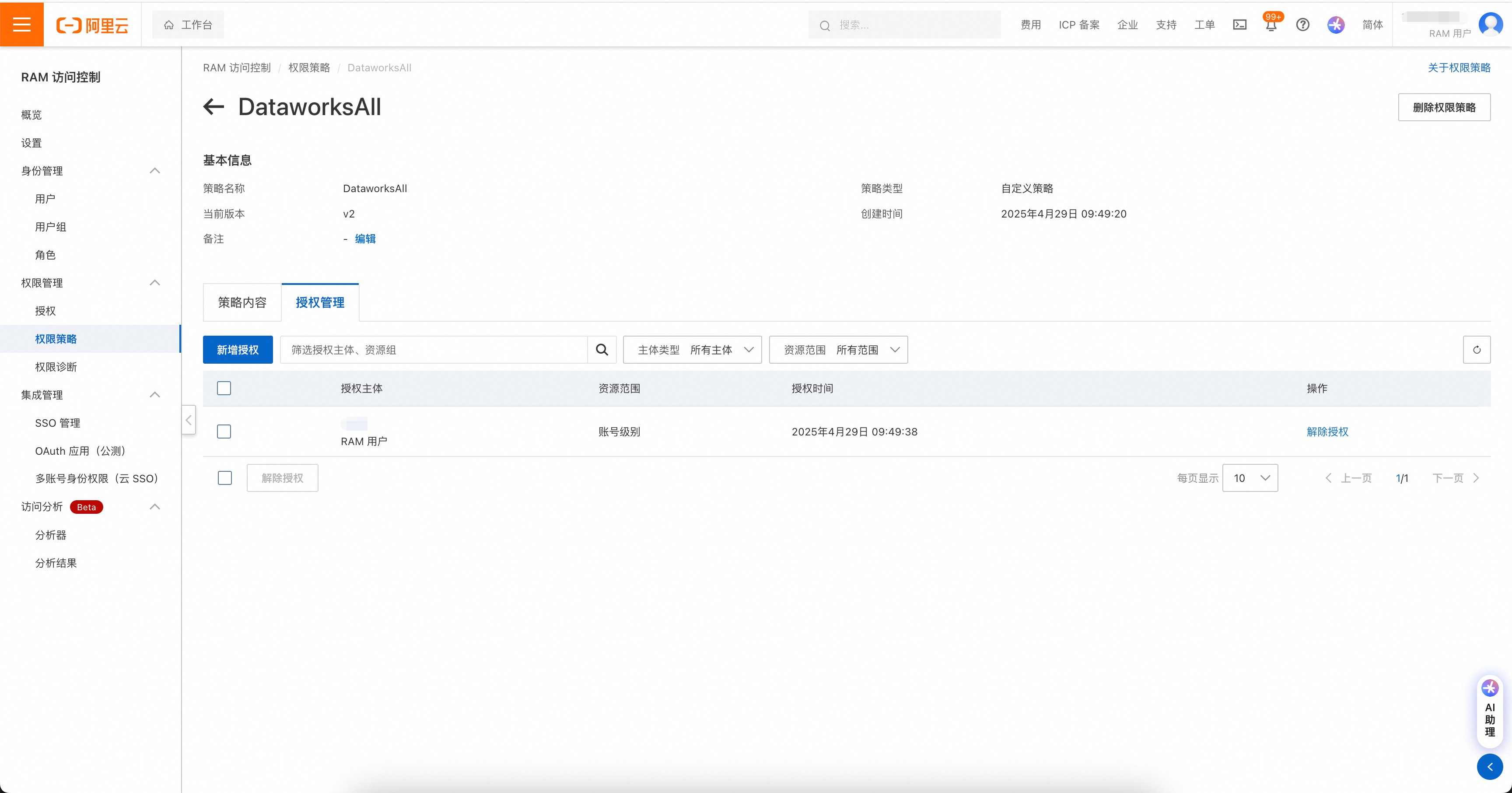
然后在DataWorks工作空间中,将工作空间权限赋给账号。
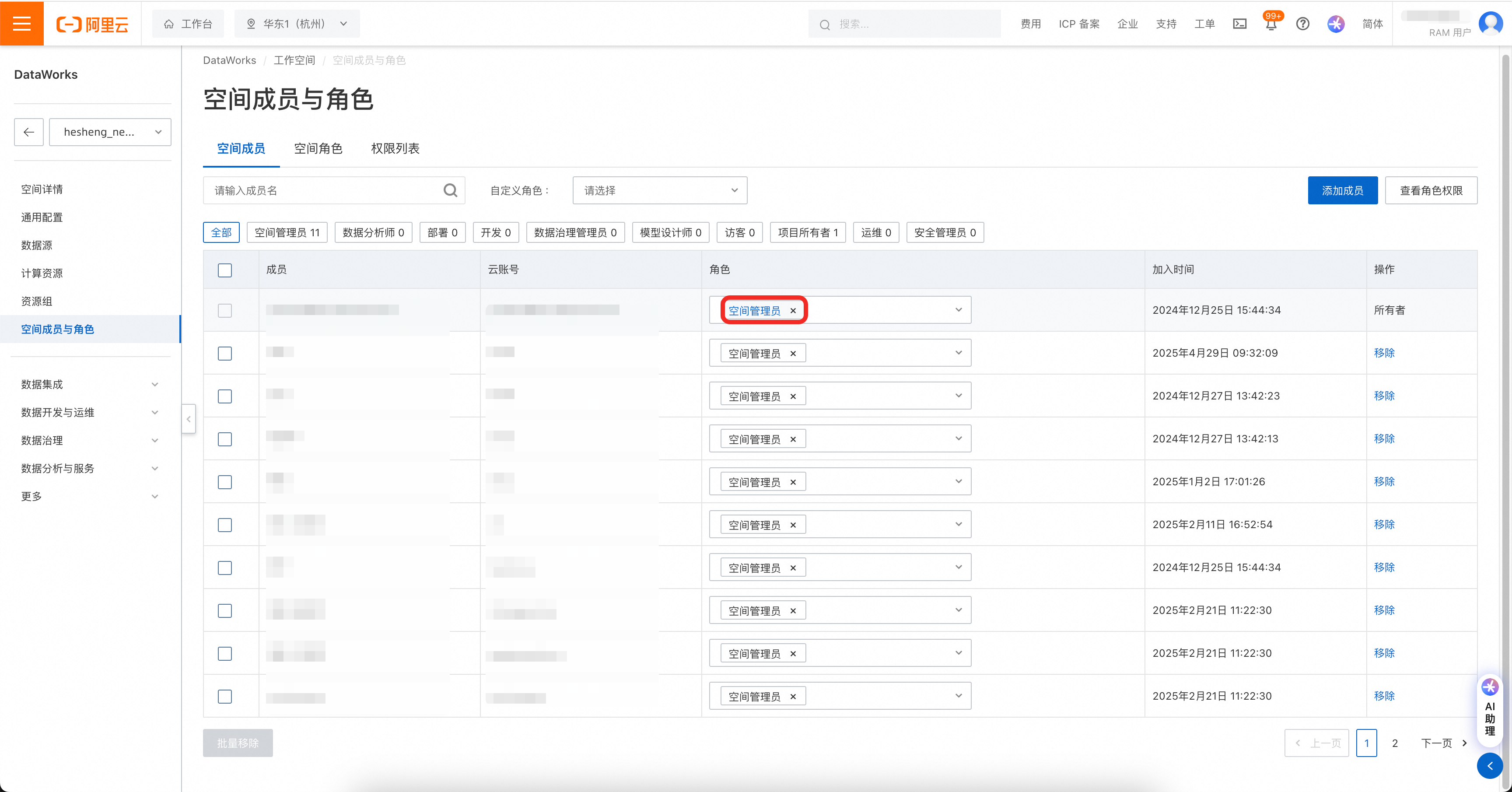
注意!AccessKey可设置网络访问限制策略,请务必保证迁移工具所在机器的IP被允许访问。
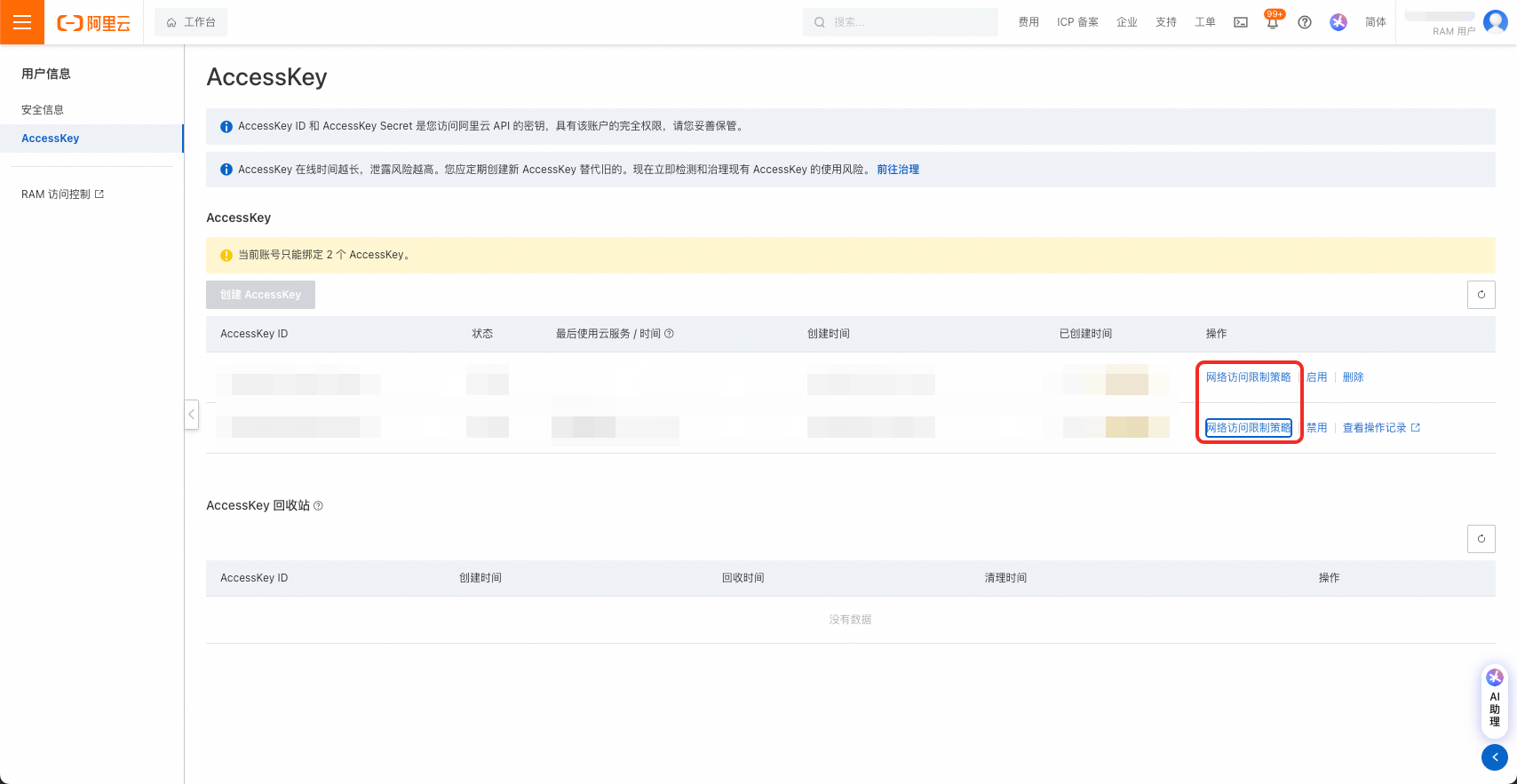
4.2 发布范围圈选
用户可通过删除统计报表中Workflow子表的行,来跳过部分工作流的发布,详见:
使用调度迁移中的统计报表补充修改调度属性 - 2.4 工作流黑名单
4.3 运行DataWorks批量发布工具
批量发布工具通过命令行调用,调用命令如下:
sh ./bin/run.sh write \
-c ./conf/<你的配置文件>.json \
-f ./data/<待发布的包>.zip \
-o ./data/temp.zip \
-t dw-newide-deployer其中-c为配置文件路径,-f为待发布包的存储路径。
发布工具运行中将打印过程信息,请关注运行过程中是否有报错。若某一工作流发布失败,工具将取消其直接下游和间接下游工作流发布。当工作流存在环时,工具将提示环的存在并取消所有发布。
5 使用样例
5.1 样例概览
当前工作空间中存在4个Workflow

通过跨Workflow节点血缘,存在如下的依赖关系:
mainflow2 -> mainFlow -> moreWf
此外,mainFlow中存在SUB_PROCESS节点,引用了subflow任务流。
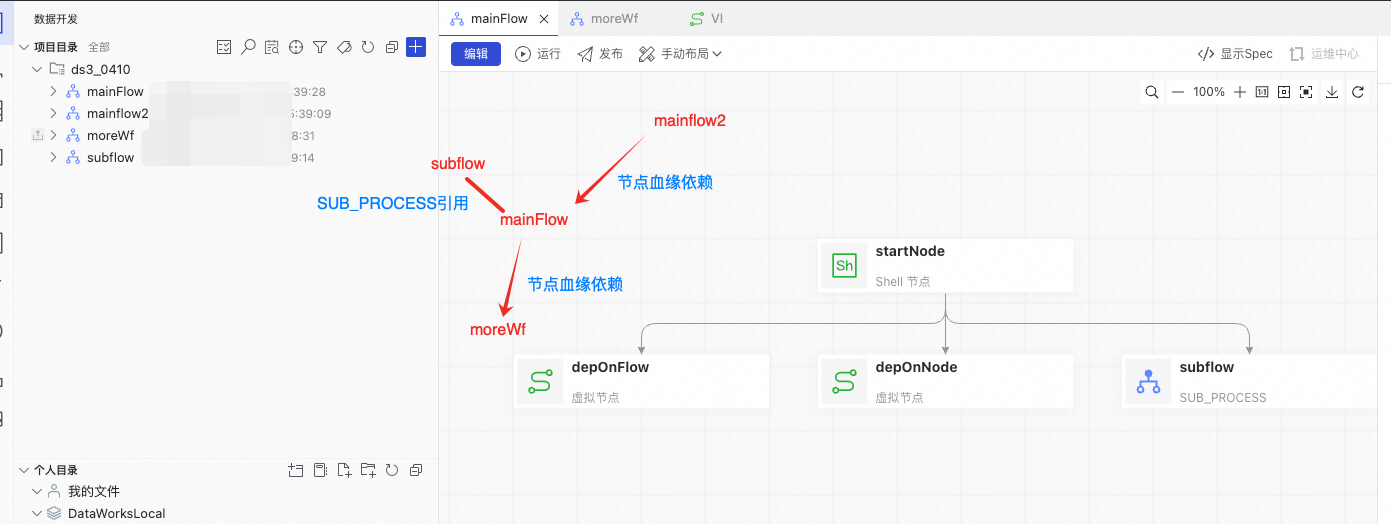
因此,在发布次序上存在如下约束:
· subflow、mainflow2需要早于mainFlow发布。
· moreWf需要晚于mainFlow发布。
5.2 运行结果
DataWorksDeployer运行结果如下:
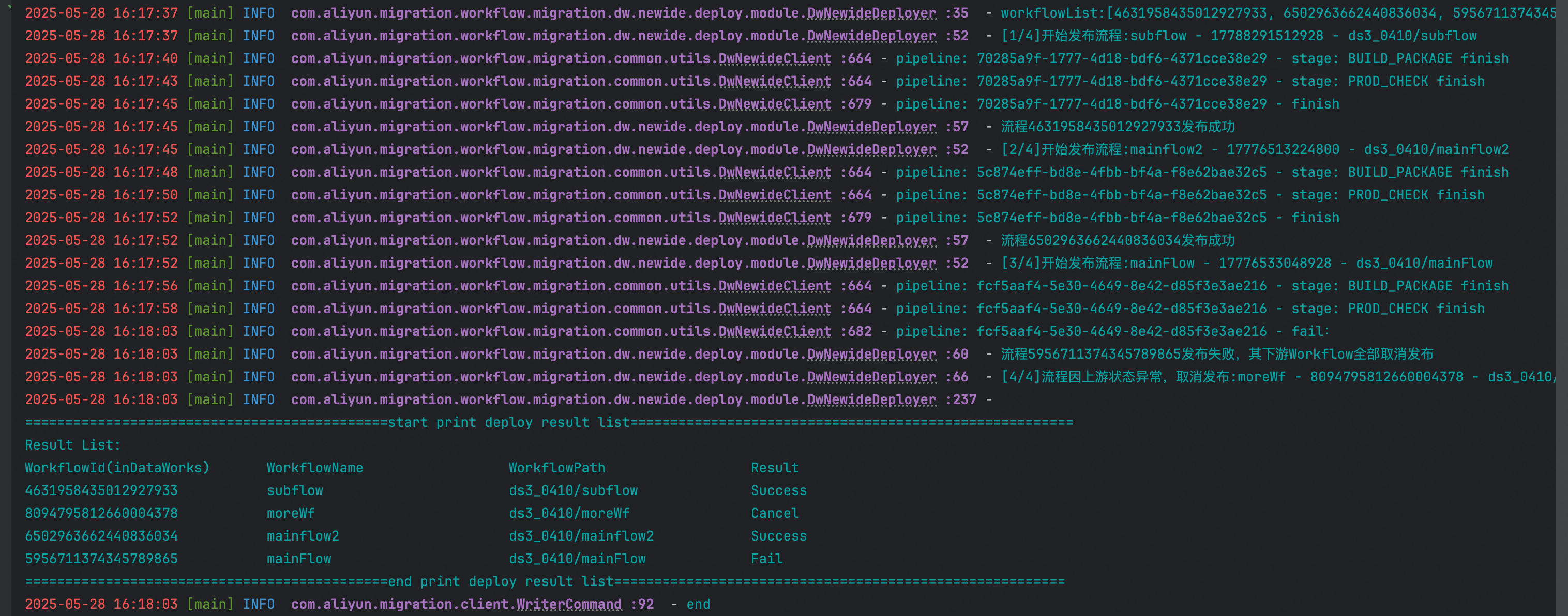
Deployer拓扑排序的结果为subflow、mainflow2、mainFlow、moreWf,并按此顺序进行了发布。
subflow、mainflow2发布成功,mainFlow发布失败,mainFlow的下游moreWf被取消发布。
用户可通过检查mainFlow任务流,修复问题后重新运行Deployer后再次发布。