
一、迁移原理
Elasticsearch的快照(Snapshot)是唯一官方承认的用来备份和恢复集群数据的方法。它允许将整个集群或特定索引的数据备份到一个远程的仓库(Repository),例如文件系统、Aliyun OSS、AWS S3、Google Cloud Storage等,除备份恢复外,快照也可以用于数据迁移。
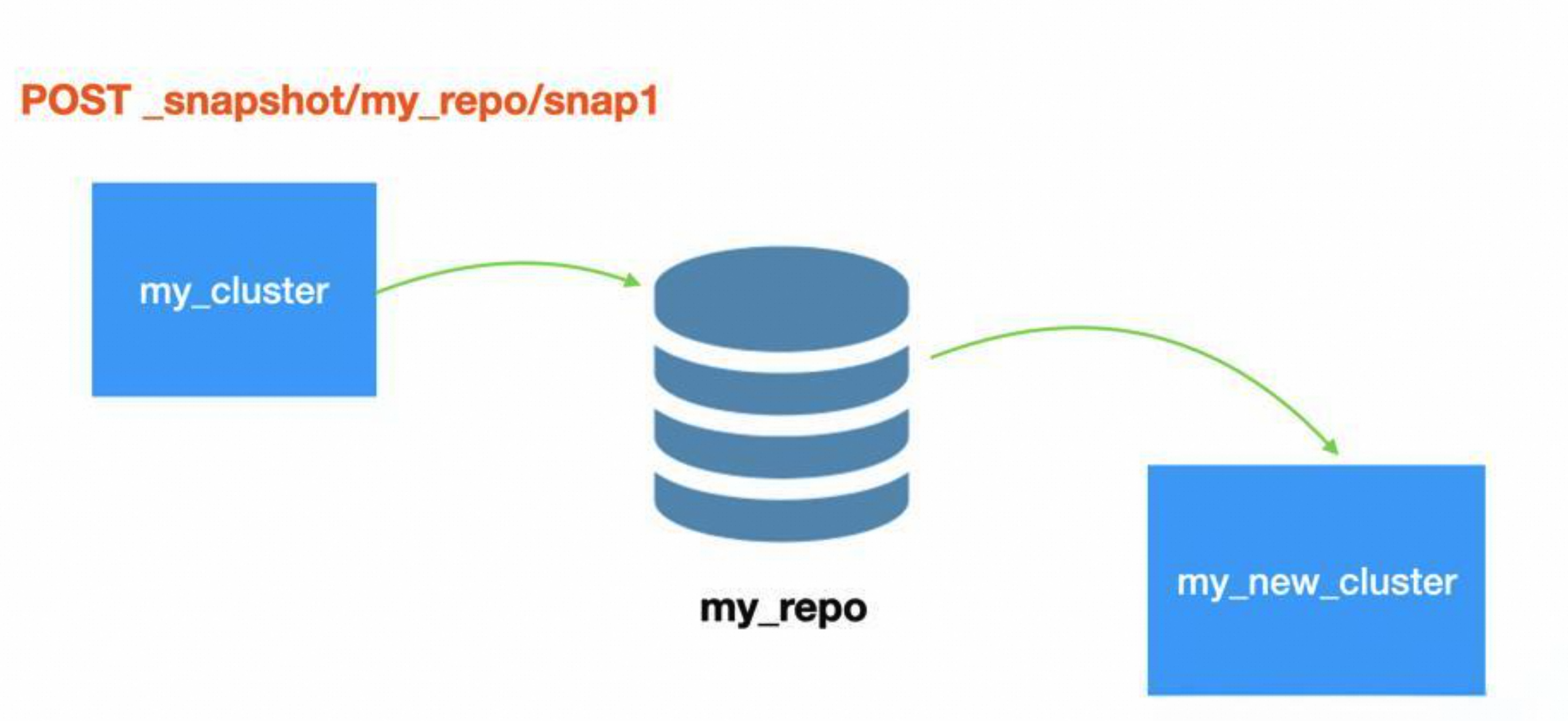
核心概念
仓库(Repository):快照存储的位置。可以是多种类型的存储,比如本地文件系统、远程文件系统或云存储服务。
快照(Snapshot):**特定时间段(不是时间点)**上,集群或指定索引的数据状态。针对一个仓库,第一个快照是全量的,后续快照都是增量的,Restore也是增量的,即只有自上次快照以来的变化会被存储,从而节省空间和时间。
支持的仓库类型
共享文件系统(fs):通过 NFS 或者本地磁盘进行快照存储。
文件系统路径(url):指定文件系统的 URL 路径,支持协议:HTTP、HTTPs、ftp、file、jar。
Amazon S3:快照存储在 AWS 的 S3 存储中,以插件形式支持,安装该插件请参考 repository-s3。
hdfs:快照存放于 hdfs 中,以插件形式支持,安装该插件请参考 repository-hdfs。
Azure Blob Storage:快照存储在 Azure 的 Blob 存储中,以插件形式支持,安装该插件请参考Azure Repository。
Google Cloud Storage:快照存储在 Google Cloud Storage 中,以插件形式支持,安装该插件请参考Google Cloud Storage Repository。
阿里云 OSS:快照存储在阿里云OSS存储中,以插件形式支持,安装该插件请参考OSS Repository。
腾讯云 COS:快照存储在腾讯云COS存储中,以插件形式支持,安装该插件请参考 cos-repository。
华为云 OBS:快照存储在华为云OBS存储中,没有开放插件,只支持华为云CSS Elasticsearch使用。
注意:
开源Elasticsearch从8.0版本开始,默认支持 S3, GCS和Azure仓库,无需手动安装插件。
尽管仓库存储位置不同,但它们的快照格式是一样的,因为 Elasticsearch 使用相同的内部机制来创建和管理快照。
二、阿里云 OSS 仓库
通过在自建Elasticsearch实例上安装elasticsearch-repository-oss插件,使其支持aliyun OSS 远程仓库,用来保存快照,从而实现基于OSS快照的数据迁移。
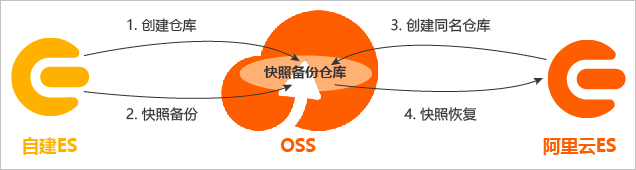
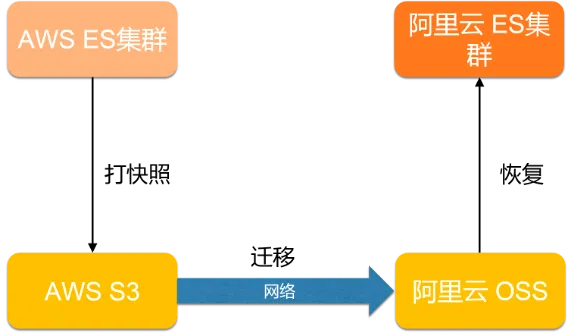
在第三方Elasticsearch迁移的场景下,通常采用先创建快照到第三方的对象存储上(如AWS S3、腾讯云COS等),然后迁移到阿里云OSS上,在执行restore到阿里云Elasticsearch上。
创建OSS仓库命令:
sudo curl -H "Content-Type: application/json" -XPUT localhost:9200/_snapshot/<yourBackupName> -d'
{
"type": "oss",
"settings": {
"endpoint": "http://oss-cn-beijing-internal.aliyuncs.com",
"access_key_id": "<yourAccesskeyId>",
"secret_access_key":"<yourAccesskeySecret>",
"bucket": "<yourBucketName>",
"base_path": "snapshot/",
"compress": true }
}'
可在Github上下载插件,如果Github上没有对应版本的插件包,建议下载对应大版本的相近小版本的插件包,然后修改plugin-descriptor.properties文件中的参数值,重新打包再安装。
version=所需插件的版本
elasticsearch.version=自建Elasticsearch的版本
说明:插件版本与自建Elasticsearch版本要保证一致。
java.version=1.8
说明:
可以使用以下命令获取java的版本。
curl -X GET "localhost:9200/_nodes/jvm?pretty"
由于开源Elasticsearch集群的版本较多,各版本编译存在差异,因此在使用elasticsearch-repository-oss插件时,需要结合对应Elasticsearch的版本进行编译调试。例如自建Elasticsearch 7.6.2集群,要求JDK版本大于1.8及以上,编译调试后对应的插件为elasticsearch-repository-oss-7.6.2。
三、管理快照
配置仓库
首先,需要配置一个用于存储快照的仓库。以下是配置一个阿里云OSS仓库的示例:
PUT /_snapshot/my_backup
{
"type": "oss",
"settings": {
"endpoint": "http://oss-cn-beijing-internal.aliyuncs.com",
"access_key_id": "<access_key_id>",
"secret_access_key": "<secret_access_key>",
"bucket": "bj-oss",
"base_path": "my_backup/",
"compress": true
}
}
注意:
在目标端配置仓库时需要添加
readonly: true,确保同一时间只有一个ES集群可以向同一个仓库中写,避免数据冲突。
创建快照
配置好仓库后,可以创建快照。
1. 创建一个包含所有index数据的快照,名为 `snapshot_1` :
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
注意:
wait_for_completion参数是可选项,默认情况下,快照命令会立即返回,任务在后台执行,如果想等待任务完成API才返回,则可以将wait_for_completion 参数设置为true,默认为false。若在创建快照时未使用
wait_for_completion=true参数,可以使用_statusAPI 监控快照进度:GET /_snapshot/my_backup/snapshot_1/_status
2. 创建一个部分index的快照,名为 `snapshot_2` :
PUT /_snapshot/my_backup/snapshot_2?wait_for_completion=true
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false
}
注意:
针对同一仓库的多次备份,强制采用增量备份方式,例如上述snapshot_2中备份index_1、index_2,由于snapshot_1中已经做了所有indices的备份,因此snapshot_2只做这两个索引的增量备份。
恢复时只需要指定最新的备份快照即可,Elasticsearch会自动检索依赖关系,完成数据恢复。
参数设置:
* **indices**: 要本分的index,逗号分割。
* **max_wait**: 最大等待时间。
* **wait_interval**: 等待间隔。
* **ignore_unavailable**: 把这个选项设置为 true 的时候在创建快照的过程中会忽略不存在的索引。默认情况下, 如果没有设置 ignore_unavailable 在索引不存在的情况下快照请求将会失败。
* **include_global_state**: 是否快照集群状态,集群状态包函集群持久设置(persistent settings)、模板等,snapshot时默认为true,restore时默认为false,因此**默认是不会迁移集群状态的**。
注意:
如果是迁移个别索引的数据,无需迁移集群状态,因此include_global_state设置为false**。**
如果设置为 true,快照中的持久性设置、索引模板、管道和 ILM 策略会被恢复到当前集群。这将覆盖任何已有的、名称与快照中相匹配的集群设置、模板、管道和 ILM 策略。
恢复快照
当需要从快照中恢复数据时,可以执行恢复操作。以下是从 my_backup 仓库中的 snapshot_2 快照恢复的示例:
POST /_snapshot/my_backup/snapshot_1/_restore?wait_for_completion=true
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_aliases": true
}
注意:
include_aliases只在restore时可以使用,官方默认值为false(实际测试阿里云上默认值是true),如果snapshot时,include_global_state设置为false,则快照里不包含alias信息,restore时即便include_aliases设置为true也没有实际效果。
POST /_snapshot/my_backup/snapshot_1/_restore?wait_for_completion=true
{
"indices": "*,-.*"
}
注意:
"-.*"是排除名称以"."开头的index,此类索引为系统索引,Elasticsearch集群会根据实际情况默认选择创建,因此不能手动恢复。
查看仓库和快照:
查看所有仓库:
GET /_snapshot查看特定仓库:
GET /_snapshot/my_backup查看快照:
GET /_snapshot/my_backup/snapshot_1删除快照:
DELETE /_snapshot/my_backup/snapshot_1四、索引兼容性
从快照恢复的任何索引也必须与当前集群的版本兼容。
索引创建版本/目标集群版本 | 6.8 | 7.0–7.1 | 7.2–7.17 | 8.0–8.2 | 8.3-8.14 |
5.0–5.6 | 支持 | 支持 | |||
6.0–6.7 | 支持 | 支持 | 支持 | 支持 | |
6.8 | 支持 | 支持 | 支持 | ||
7.0–7.1 | 支持 | 支持 | 支持 | 支持 | |
7.2–7.17 | 支持 | 支持 | 支持 | ||
8.0–8.14 | 支持 | 支持 |
注意:
无法将索引还原到早期版本的 Elasticsearch。例如,您无法将 7.6.0 中创建的索引还原到运行 7.5.0 的集群。
五、前置条件
自建Elasticsearch实例可以公网、内网或者专线访问阿里云OSS服务。
确保用于存储快照的OSS具备适当的读写权限以及访问策略。
提前在阿里云OSS中创建好对应的bucket,bucket地域的选择应与阿里云Elasticsearch的地域保持一致。
六、风险以及注意事项
性能影响:创建快照时可能对集群性能产生影响,建议在非高峰期操作,或者控制快照的并发数。
版本兼容性:
确保 Elasticsearch 集群的版本与快照仓库兼容,避免由于版本不匹配导致的恢复问题。
无法将索引还原到早期版本的 Elasticsearch。例如,您无法将 7.6.0 中创建的索引还原到运行 7.5.0 的集群。