
本文旨在帮助用户自助分析阿里云可观测监控 Prometheus 版的指标写入量,定位高额费用的来源(实例、Job、指标),并提供相应的优化治理方案,从而有效控制成本。
阿里云 Prometheus 计费主要分为指标传入费用和指标存储费用,具体参考计费概述。要优化用量,首先需要分析指标写入量较大的实例、Job 和指标。阿里云 Prometheus 提供了用量分析、指标统计和指标治理等功能来支持这一需求。
用量分析
1. 实例维度用量分析
首先从全局视角查看用量较高的Prometheus 实例。
-
登录云监控控制台。
-
在左侧导航栏单击。
-
在实例用量总览区域,您可以查看实例的上报量、写入量、归档存储量等计费相关统计。
-
操作建议:按自定义指标上报量(百万)或 自定义指标写入量(GB)倒排,快速识别指标传入 TopN 的实例。
实例用量总览面板以表格形式展示各实例的用量数据,除自定义指标相关列外,还包含实例ID、实例名、区域、基础指标上报量(百万)、基础指标写入量(GB)等列,可据此对比各实例的基础指标与自定义指标用量。
-
上报量和写入量是 Prometheus 实例数据传入不同的计费方式,用户可以二选一,一般情况下上报量比较高写入量也会比较高,具体参考计费概述。
2. Job 维度用量分析
分析完实例维度后,可以针对用量较大的实例,进一步下钻分析产生大量数据的具体Job。
-
在用量分析的大盘中,筛选期望下钻分析的实例。
-
查看Job排行:
-
在中查看上报量Top 10 的自定义Job。
-
在中查看写入量 Top 10 的Job。
job自定义指标写入量(Top10) 面板以表格形式展示写入量排名前 10 的 Job 信息,包含Job名、写入量(Bytes)和占比列。
-
3. 指标维度用量分析
若需要定位导致高用量的具体指标,可以进入具体的 Prometheus 实例进行分析。
-
在左侧导航栏选择实例列表,单击目标实例名称,访问具体的 Prometheus 实例。
-
在左侧导航栏选择指标管理,在指标统计页签下:
-
Top 10 指标数据条数:查看上报量比较高的指标。
-
Top 10 指标名数据量:查看写入量比较高的指标。
-
-
您也可以在大盘上筛选查看上一步中分析出的写入量比较高的Job。
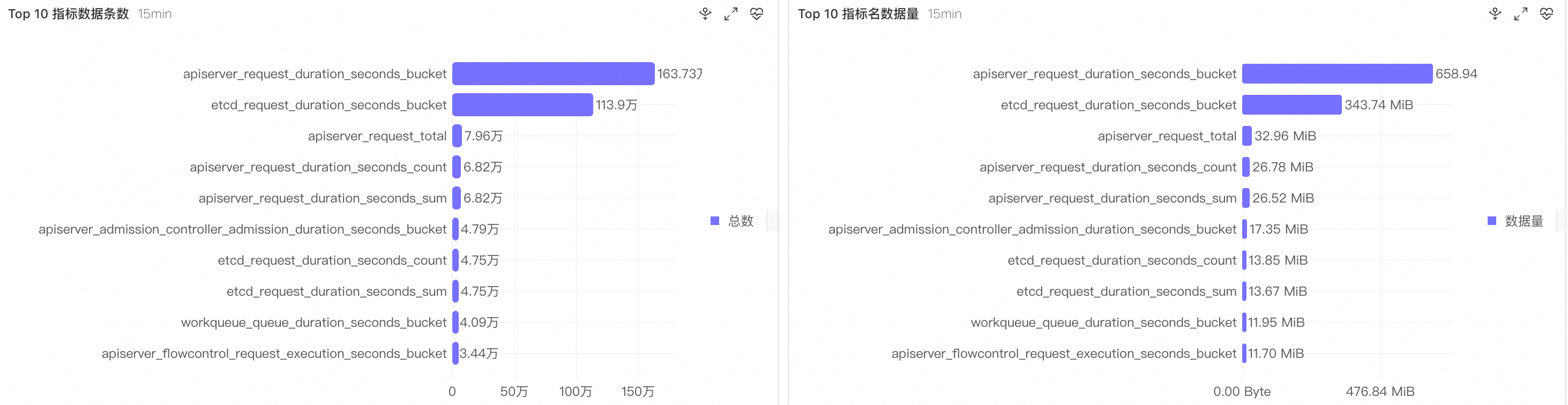
指标统计中的数据条数和数据量为实时统计,实际出账的上报量或写入量可能存在一定误差,请以实际账单为准。
4. 高基数指标分析
在 Prometheus 中,高基数(High Cardinality) 是指时间序列(time series)的数量异常庞大,通常是由于指标(metric)的 标签(labels)组合过多导致的,一般情况下是指标中存储在发散的 label。
在中,提供了时间线统计和label 统计能力:
-
指标快速分析:查看当前实例中时间线TopN的指标。
-
Label 快速分析:查看 Label数的TopN分析,也可以筛选具体的指标进行查看。
指标快速分析 15min 面板包含指标名、时间线、总数、时间线采样列,示例中 TopN 指标包括 apiserver_request_duration_seconds_bucket(26153/1637280)、etcd_request_duration_seconds_bucket(19435/1139040)、apiserver_request_total(1345/79560)等。Label 快速分析 15min 面板包含 LabelKey、唯一数、总数、LabelValue采样列,示例中高基数标签包括 name(402/188202)、resource(228/3062640)、le(200/3066720)、instance(26/3790422)等。
成本优化策略
基于上述用量分析的洞察,您可以针对性地采取以下措施进行成本优化。
策略1:选择合适的实例计费方式
Prometheus 在实例维度提供了写入量和上报量 2 种计费方式,您可以基于用量统计页面计算哪种方式更划算。
-
操作:在 Prometheus 实例的设置中,切换不同的计费方式。
-
限制:单实例只允许切换一次。
在实例基础信息面板中,单击付费方式右侧的编辑图标即可进行切换。
策略2:提高采集频率
-
在接入管理页面,单击期望设置的环境名称,进入接入环境配置界面。
-
在组件管理中找到期望设置的组件,单击目标组件操作列的设置。
-
在配置界面中,设置采集间隔(秒)。
例如,将其设置为 15。
策略3:废弃无用指标
-
在左侧导航栏选择,单击目标环境名称操作列的指标采集。
-
在指标采集页面,单击指标废弃,输入期望废弃的指标即可。
-
如果指标是通过开源 Prometheus 采集后 Remote Write 写到阿里云 Prometheus,可在抓取配置中通过
metric_relabel_configs删除不需要的指标。具体操作参考常见metric_relabel_configs使用场景示例。 -
也可以在 Remote Write 阶段通过
write_relabel_configs进行指标丢弃配置。
-
策略4:优化高基数指标
-
禁止发散标签:在指标源头,禁止将高基数的指标作为label ,例如用户 ID、订单 ID、Trace ID 作为标签。
-
标签归一化:如果指标中存储了路径等 label ,建议进行归一化处理(
比如:/api/user/123/profile→/api/user/:id/profile)。
总结
各优化措施的对比汇总如下表所示:
|
优化措施 |
作用范围 |
使用限制 |
实施难度 |
|
选择合适的实例计费方式 |
实例维度 |
单实例只允许切换一次。 |
低 |
|
提高采集频率 |
Job维度 |
云服务指标不支持(云服务指标本身基本都是1分钟粒度) |
中 |
|
废弃无用指标 |
指标粒度 |
云服务高级指标不支持废弃 |
中 |
|
优化高基数指标 |
指标粒度 |
需要调整采集逻辑 |
高 |