
本文汇总了ACS Pod的相关事件并给出说明,其中包括通用自定义事件(Pod相关事件、资源事件、系统运维事件)以及GPU型和高性能网络GPU型相关的调度管控事件。
获取自定义事件
事件中心方式
-
登录容器计算服务控制台,在左侧导航栏选择集群列表。
-
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择运维管理 > 事件中心。
-
单击事件列表页签,根据级别、命名空间、名称等条件筛选目标资源的事件。
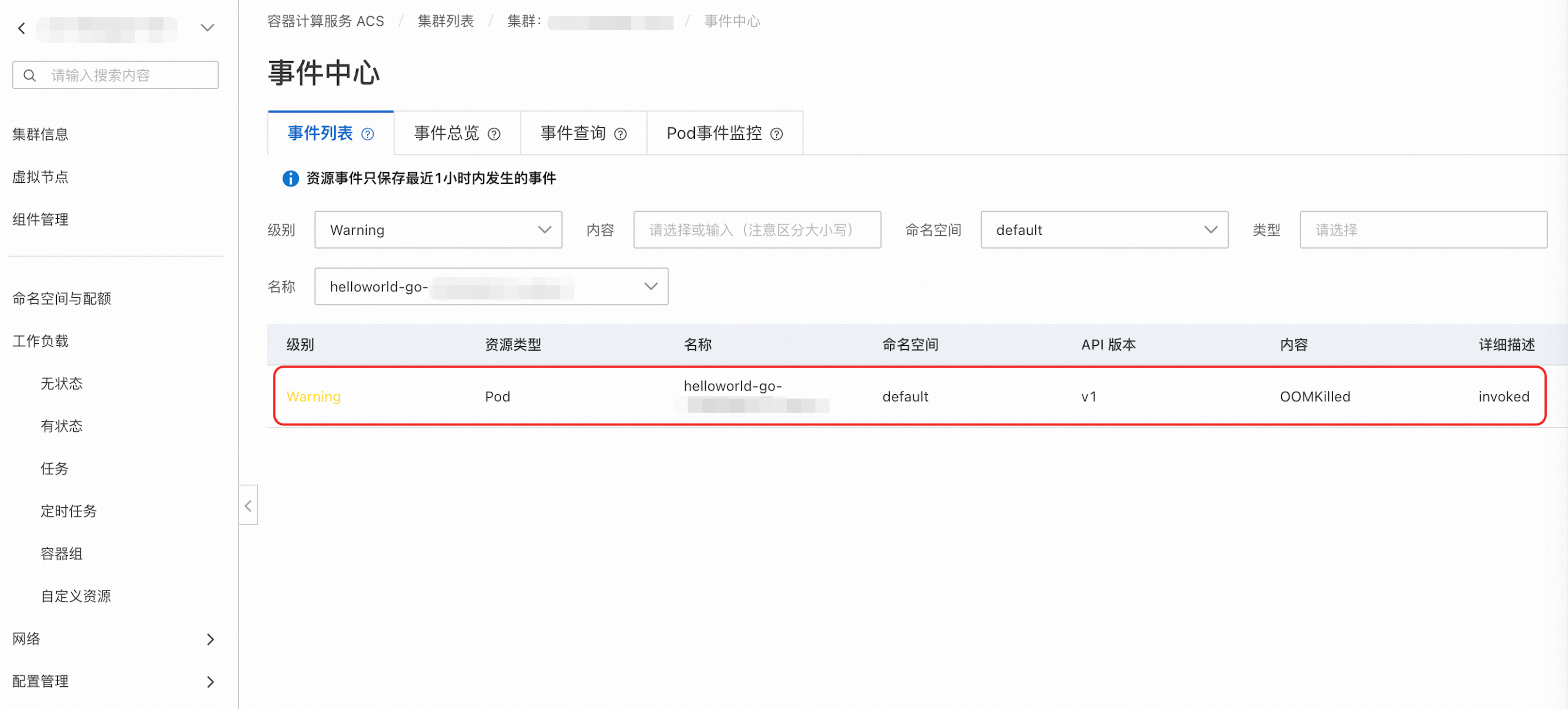
-
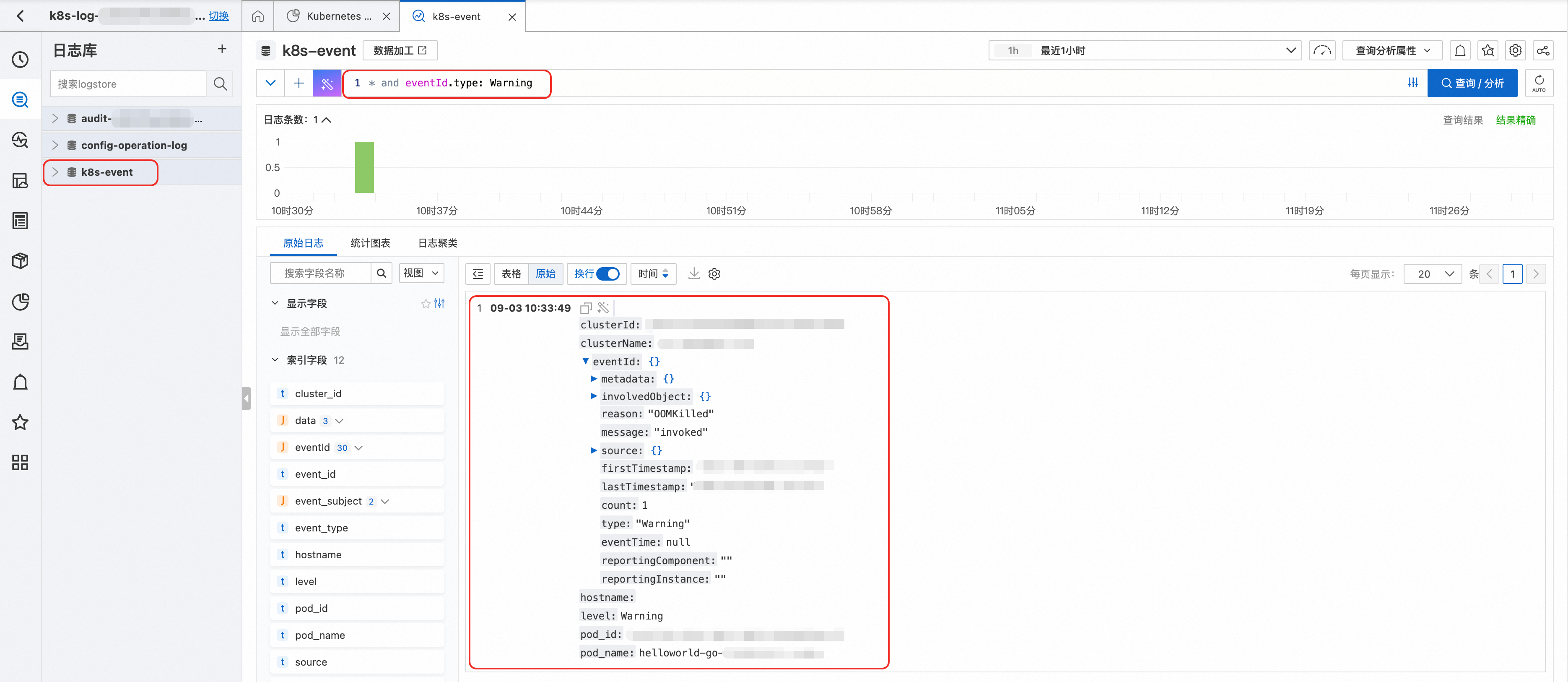
单击右上角查看事件中心历史数据,从日志服务SLS中查询事件。
该功能需安装alibaba-log-controller和kube-eventer组件,可通过组件管理安装。
-
以通用型和性能型的系统运维事件OOMKilled为例:
{ "eventId": { "metadata": {}, "involvedObject": { "kind": "Pod", "namespace": "default", "name": "helloworld-go-**********-*****", "uid": "*****", "apiVersion": "v1" }, "reason": "OOMKilled", "message": "invoked", "source": { "component": "AcsService" }, "firstTimestamp": "2025-**-**T02:33:49Z", "lastTimestamp": "2025-**-**T02:33:49Z", "count": 1, "type": "Warning", "eventTime": null, "reportingComponent": "", "reportingInstance": "" }, "hostname": "", "level": "Warning", "pod_id": "*****", "pod_name": "helloworld-go-**********-*****", "clusterName": "*****", "clusterId": "*****7ec556cb4680a3a1e71201a*****" } -
eventId主要字段说明:-
involvedObject:事件关联的资源对象。内容包括ACS实例的Kubernetes版本(apiVersion)、资源类型(kind)、资源名称(name)、资源所在命名空间(namespace)和资源ID(uid)。 -
message:事件信息。例如Out of memory。 -
reason:事件原因。例如OOMKilled。 -
type:事件类型。Normal或者Warning。
-
-
工作负载方式
-
登录容器计算服务控制台,在左侧导航栏选择集群列表。
-
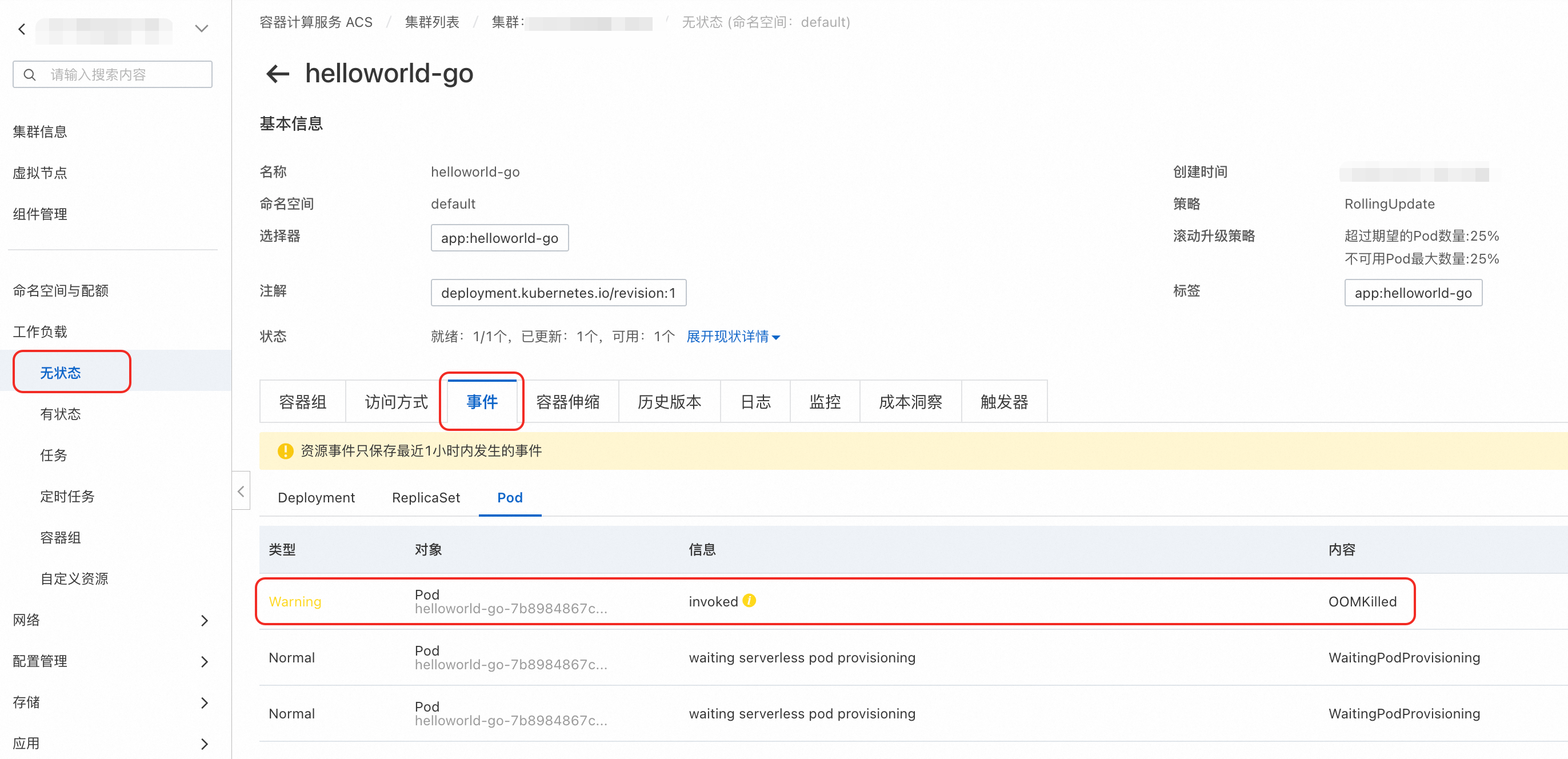
以无状态工作负载为例,在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
-
单击目标工作负载名称,然后单击事件页签,查看Pod事件列表。
-
以通用型和性能型的系统运维事件OOMKilled为例:
-
通用自定义事件说明
适用于所有计算类型的ACS Pod。
ACS Pod相关事件
|
事件名称(reason) |
事件类型(type) |
事件信息(message) |
事件说明 |
|
BestEffortDegraded |
Warning |
BestEffort instance will be degraded because the specified instance is out of stock |
创建BestEffort型的ACS Pod,由于BestEffort算力没有满足要求的库存,自动转为默认型。 |
|
BestEffortToBeReleased |
Warning |
BestEffort Instance will be released |
BestEffort型的ACS Pod即将过期,您需要在业务上进行兼容处理。 |
|
StockExhaust |
Warning |
The stock of the specified zones will be used up |
当前可用区的ACS算力资源库存即将耗尽。建议更换可用区。 |
|
NoStock |
Warning |
Create ACS Instance failed because the specified instance is out of stock |
当前可用区的ACS算力资源库存不足。您可以使用多可用区和多规格的方式创建ACS Pod来提高创建成功率。 |
|
StockClose |
Warning |
Create ACS Instance failed because current zone closed or limited without living instance |
创建ACS Pod失败,无法使用当前可用区。请更换可用区。 |
|
FailedScheduling |
Warning |
Unknown error occurred |
创建ACS Pod失败,发生未知错误。请提交工单。 |
|
FailedScheduling |
Warning |
Schedule ACS Instance failed |
调度ACS Pod失败。请重新尝试。 |
|
UnknownError |
Warning |
The ACS service is under heavy load while creating container, please wait and try again later |
ACS服务负载过大,请稍后再尝试创建ACS Pod。 |
|
UnknownError |
Warning |
An unknown error occurred |
发生未知错误。请提交工单。 |
|
DiskCapacityQuotaFull |
Warning |
Your disk capacity quota is exceeded |
磁盘容量已达到配额限制。请至配额中心申请提升配额。 |
|
AttachDiskFailed |
Warning |
Attach disk %s failed |
磁盘挂载失败。 |
|
SystemFailureReboot |
Warning |
The Specified Instance is rebooting |
ACS Pod正在重新启动。 |
|
StartingFailed |
Warning |
the Instance starting failed: %s |
ACS Pod启动失败。 |
|
Throttling |
Warning |
The request was denied due to system flow control, please wait and try again later |
由于系统流量控制,请求被拒绝。请稍候再尝试操作。 |
|
EphemeralStorageSizeExceededJobLimit |
Warning |
Ephemeral storage size: %s exceeded the limitation of job instance:%s |
临时存储空间的大小超出了限制。 |
|
InplaceResizing |
Normal |
Starting to resize container resource for container: %s cpu request: %v -> %v, cpu limit %v -> %v, memory request: %v -> %v, memory limit %v -> %v, time: %v |
开始对某容器进行原地变配。 |
|
InplaceResizing |
Warning |
Failed to do the inplace update, err message: %v |
原地变配失败。 |
|
InplaceResizedFinished |
Normal |
Pod vertical scaling cpu resource finished, consume: %v |
原地变配任务完成。 |
|
InplaceResizedFinished |
Normal |
scale task cancelled because pod resource already updated %v |
原地变配任务取消,因为Pod资源已经满足要求。 |
|
InplaceResizedTimeoutFailed |
Warning |
Pod vertical scaling cpu resource failed, reason: timeout, time: %v |
原地变配任务超时。 |
其他资源事件
|
资源模块 |
事件名称(reason) |
事件类型(type) |
事件信息(message) |
事件说明 |
|
vSwitch |
ResourceInsufficient |
Warning |
The maximum number of IP address in the VSwitch %s is exceeded |
交换机下可用的IP地址数量不足。请使用其他交换机。 |
|
SecurityGroup |
QuotaFull |
Warning |
The maximum number of instances in the security group %s is exceeded |
安全组内的实例数量已达到配额限制。请使用其他安全组。 |
|
ENI |
CreateENIFailed |
Warning |
%s |
创建ENI失败。 |
|
AttachENIFailed |
Warning |
%s |
挂载ENI失败。 |
|
|
AttachENIConflict |
Warning |
%s |
挂载ENI冲突。 |
|
|
MissDefaultVpc |
Warning |
%s |
缺少默认的VPC参数。 |
|
|
EIP |
CreateEipFailed |
Warning |
%s |
创建EIP失败。 |
|
EipBandwidthPackageQuotaExceeded |
Warning |
%s |
EIP带宽包超出配额限制。 |
|
|
EipNotFound |
Warning |
The specified eip %s does not exist |
指定的EIP不存在。 |
|
|
EipBoundOtherInstance |
Warning |
The specified eip %s is already bound to another instance |
指定的EIP已绑定了其他实例。 |
|
|
SLS |
AliyunSlsQuotaExceed |
Warning |
%s |
SLS资源超出配额限制。请提交工单申请提升配额。 |
|
AliyunSlsError |
Warning |
%s |
SLS相关错误。 |
|
|
AliyunSlsProjectInvalid |
Warning |
%s |
指定的SLS Project是无效的。 |
|
|
AliyunSlsConfigFormatError |
Warning |
sls config %s value %s is invalid |
SLS的配置参数无效。 |
系统运维事件
|
事件名称(reason) |
事件信息(message)示例 |
事件说明 |
|
SandboxNotReady |
Critical error detected on Host OS |
主动运维重启。 |
|
SandboxNotReadyUnExpected |
Unexpected error occurred on underlying infrastructure |
非预期宕机重启。 |
|
SandboxRebootCanceled |
The reboot of current instance has been canceled |
重启被取消。 |
|
SandboxRebootSucceeded |
Current instance has been rebooted successfully. |
重启成功。 |
|
ScheduledMaintenance |
{"originReason":"Redeploy","originMessage":"Redeploy","planExecTime":"20**-03-12T09:00:00.000+08:00"} |
计划运维事件。 重要
message为JSON格式,其中 |
|
OOMKilled |
Memory cgroup out of memory: Kill process 15848 (xsim_traffic_fl) score 337 or sacrifice child |
ACS Pod内部出现OOM。 |
|
PodOOMKilled |
System OOM encountered, victim process: xxx, pid: xxx |
ACS Pod内部出现OOM(非内核crash)。OOM对象包括ACS系统组件和容器进程。 |
|
DiskFull |
There has insufficient disk space for current instance. |
磁盘空间已满。 |
|
NfsError |
NFS: state manager: bind conn to session failed on NFSv4 server 172.16.0.1 with error 121 |
NFS出现错误。 |
|
RuntimeCrashed |
Unexpected crash occurred on underlying infrastructure |
容器运行时异常崩溃。 |
|
RuntimeIssueDetected |
Unexpected issue occurred on underlying infrastructure |
检测到底层基础设施未预期的异常事件。 |
GPU型和高性能网络GPU型自定义事件说明
包括计算类型为GPU型和高性能网络GPU型的ACS Pod的特殊自定义事件。
调度管控相关事件
|
事件名称(reason) |
事件类型(type) |
事件信息(message)或者示例 |
事件说明 |
|
Scheduled |
Normal |
Successfully assigned [namespace]/[Pod name] |
Pod成功调度并绑定到目标节点。 |
|
GPUComputeClassScheduling |
Normal |
Waiting for ACS resource for scheduling |
GPU类型Pod正在等待ACS资源分配,可能因GPU配额或资源不足导致延迟。 |
|
FailedScheduling |
Warning |
The Pod scheduling failed, [%s] |
Pod调度失败,需检查资源配额、存储卷配置或节点亲和性规则是否冲突。 |
|
PVCUnbound |
Warning |
The Pod scheduling failed, persistentvolumeclaim "[PVC name]" is being deleted/not found |
Pod调度失败,因PVC(持久化卷声明)被删除或未找到,需检查PVC状态。 |
|
InsufficientResources |
Warning |
The Pod scheduling failed, [CPU/Memory/GPU] resources are insufficient on all nodes |
所有节点资源不足(如CPU、内存或GPU),需扩容或调整资源请求。 |
|
AffinityConflict |
Warning |
The Pod scheduling failed, [X] Node(s) didn't match pod affinity/anti-affinity rules |
无可用节点满足亲和性/反亲和性规则,需检查Pod的Affinity配置。 |
|
TopologySpreadConstraint |
Warning |
The Pod scheduling failed, GPU resources are unavailable or insufficient |
GPU资源不可用或不足,需检查GPU配额。 |
|
GPUSharePreempted |
Warning |
GPU is preempted by <new-pod-name> |
表示当前Pod的GPU资源被抢占,触发抢占的Pod名称是<new-pod-name>。具体请参见GPU共享Pod被抢占时,有哪些提示信息可以查看。 |
|
GPUSharePreempt |
Warning |
GPU is preempted from <old-pod-name> |
表示当前Pod抢占了其他Pod的GPU资源,被抢占的Pod名称是<old-pod-name>。具体请参见GPU共享Pod被抢占时,有哪些提示信息可以查看。 |
|
CPFSAttachFailed |
Warning |
CPFS filesystem ID is invalid or does not exist |
CPFS文件系统ID不存在或不合法。 |
|
CPFSAttachFailed |
Warning |
Waiting for CPFS mountpoints to become ready |
CPFS VSC挂载超时。 |
|
InvalidPovPV |
Warning |
Missing filesystem ID in PV configuration |
PV缺少CPFS文件系统ID配置。 |
|
DiskAttached |
Normal |
Attached disk d-xxxxxxxxx |
块存储挂载成功。 |
|
DiskAttached |
Warning |
error attach disk d-xxxxxxxxx: server returned error: The specified disk does not exist. (InvalidDiskId.NotFound) |
块存储挂载失败,显示具体失败原因。 |
|
ResourceDiskAttachFailed |
Warning |
Failed to attach resource disk |
资源盘(镜像缓存等)挂载失败。如持续发生请提交工单。 |
|
PullImageFailed |
Warning |
Failed to pull image [image1] for [error message] |
镜像拉取失败,显示具体的镜像名称和失败原因。 |
|
FailedCreate (PVC) |
Warning |
failed to create pvc: [pvc-name] |
PVC创建失败,显示失败的PVC名称。 |
|
FailedCreate (Pod) |
Warning |
failed to create pod: [pod-name] |
Pod创建失败,显示失败的Pod名称。 |
|
NodeBroken |
Warning |
The pod is proposed to be evicted at 20xx-xx-xx xx:xx:xx +0000 UTC, reason: xxx |
GPU-HPN整机故障。建议您在收到故障信息后,将故障节点的Pod尽快驱逐,ACS将在所有Pod驱逐完成后,自动开始节点修复自愈。 |
|
GPUCardBroken |
Warning |
The pod is proposed to be evicted at 20xx-xx-xx xx:xx:xx +0000 UTC, reason: xxx |
GPU卡损坏。建议您在收到故障信息后,将故障节点的Pod尽快驱逐,ACS将在所有Pod驱逐完成后,自动开始节点修复自愈。 |
|
BestEffortToBeReleased |
Warning |
Best Effort Instance will be released |
BestEffort实例即将过期,您需要在业务上进行兼容处理。 |