
本文介绍training-nv-pytorch 25.05版本发布记录。
Main Features and Bug Fix Lists
Main Features
基础镜像CUDA升级至12.9.0。
Bugs Fix
pytorch升级至2.6.0.7.post1,修复开源社区的 profile crash 问题。
Contents
应用场景 | 训练/推理 |
框架 | pytorch |
Requirements | NVIDIA Driver release >= 575 |
核心组件 |
|
Assets
25.05
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.05-serverless
VPC镜像
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}为您使用的ACS产品所在的开服地域,比如:cn-beijing、cn-wulanchabu等。{image:tag}为实际镜像的名称和Tag。
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.05-serverless镜像适用于ACS产品形态、灵骏多租产品形态;该镜像不适用于灵骏单租产品形态,请勿在灵骏单租场景使用。egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.05镜像适用于灵骏单租场景。
Driver Requirements
25.05 Release 对齐NGC pytorch 25.04镜像版本更新(因NGC是每月月底发布镜像,Golden镜像研发月只能基于上月版本的NGC),因此Golden-gpu的驱动遵循对应NGC镜像版本的要求。该release基于CUDA 12.9.0,需要NVIDIA驱动程序版本575或更高版本。但是,如果您在数据中心GPU(例如T4或任何其他数据中心GPU)上运行,则可以使用NVIDIA驱动程序版本470.57(或更高版本R470)、525.85(或更高版本 R525)、535.86(或更高版本 R535),或545.23(或更高版本的 R545)。
CUDA驱动程序的兼容性包只支持特定的驱动程序。因此,用户应该从所有R418、R440、R450、R460、R510、R520、R530、R545 、R555和R560驱动程序升级,这些驱动程序不向前兼容CUDA 12.8。有关支持的驱动程序的完整列表,请参阅CUDA 应用程序兼容性主题。有关更多信息,请参阅 CUDA 兼容性和升级。
Key Features and Enhancements
PyTorch编译优化
PyTorch 2.0引入的编译优化能力在单卡小规模下通常可以获得显著的收益,但是在LLM训练中需要引入显存优化、FSDP/DeepSpeed等分布式框架,导致torch.compile()无法简单地获得收益或者存在负收益:
在DeepSpeed框架下控制通信的颗粒度,帮助编译器获取更完整的计算图,做更大范围的编译优化
优化版本的PyTorch:
优化PyTorch编译器前端,确保在计算图中出现任意graph break的情况下仍能正常编译
强化模式匹配以及dynamic shape能力,提高编译后代码性能
结合上述优化,在8B LLM训练下通常可以获得20%左右的E2E吞吐收益。
重计算显存优化
基于大量性能评测数据,包括不同模型在不同集群以及不同训练参数配置,以及评测过程中采集的相关显存利用率等系统指标数据,我们进行模型显存开销的预测建模分析,并推荐出最佳的激活值重算层数,并集成到PyTorch中,让用户可以低门槛的使用显存优化带来的性能收益。当前已支持该特性在DeepSpeed框架中的适配。
ACCL通信库
ACCL是阿里针对灵骏产品自研的高性能网络通信库,针对GPU场景提供ACCL-N版本。ACCL-N是阿里云基于英伟达NCCL定制后提供的高性能通信库,在完全兼容NCCL的基础上,修复了官方NCCL版本的一些BUG,并进行了性能和稳定性相关的优化。
E2E性能收益评估
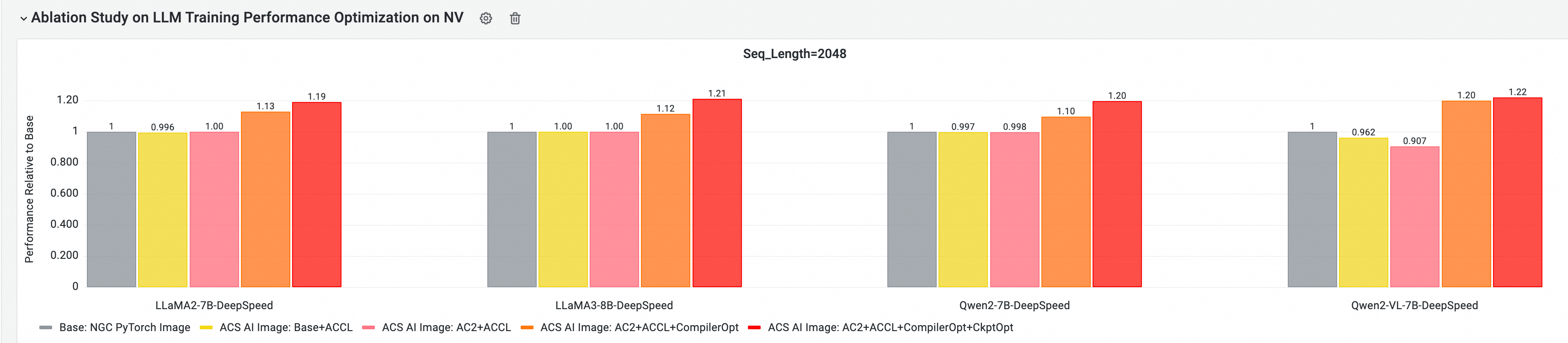
利用云原生AI性能评测分析工具CNP,我们采用主流开源模型和框架配置,与标准的基础镜像进行了全面的端到端性能比较分析,并通过消融实验分析,进一步评估了每个优化组件对整体模型训练性能的收益贡献。
GPU核心组件E2E训练性能贡献分析
以下测试基于Golden-25.05, 在多节点GPU集群上进行E2E性能评测和对比分析,对比项包括:
Base:NGC PyTorch Image
ACS AI Image:Base+ACCL: 镜像使用ACCL通信库
ACS AI Image:AC2+ACCL: Golden镜像使用AC2 BaseOS,不开启任何优化
ACS AI Image:AC2+ACCL+CompilerOpt: Golden镜像使用AC2 BaseOS,只启用torch compile优化
ACS AI Image:AC2+ACCL+CompilerOpt+CkptOpt:Golden镜像使用AC2 BaseOS,且同时开启torch compile和selective gradient checkpoint优化
Quick Start
以下示例内容仅通过Docker方式拉取training-nv-pytorch镜像。
在ACS中使用training-nv-pytorch镜像需要通过控制台创建工作负载界面的制品中心页面选取,或者通过YAML文件指定镜像引用。
1. 选择镜像
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. 调用API开启编译器+重计算显存优化
启用编译优化
使用transformers Trainer API:

启用重计算显存优化
export CHECKPOINT_OPTIMIZATION=true
3. 启动容器
镜像中内置了模型训练工具ljperf,以此说明启动容器和运行训练任务的步骤。
LLM类
# 启动容器并进入
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# 运行训练demo
ljperf benchmark --model deepspeed/llama3-8b 4. 使用建议
镜像中的改动涉及Pytorch、DeepSpeed等库(后续会upstream),请勿重装。
DeepSpeed配置中的
zero_optimization.stage3_prefetch_bucket_size留空或设置为auto。
Known Issues
镜像升级pytorch2.6,针对LLM类模型重计算显存优化性能收益效果不及历史镜像、持续优化中。