本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文主要介绍HDFS如何创建及执行数据迁移任务,实现数据从数据源端读取后存入闪电立方本地NAS中。
如果迁移过程中设备断网或断电,可能会出现迁移数据遗漏的情况,请谨慎操作。
创建迁移任务
一、检查是否有迁移进程存在
输入
ps -ef | grep jar。查看是否有master.jar、worker.jar、tracker.jar 三个进程存在,如果有则执行kill -9 进程号,将3个进程都停止。
到指定目录下,输入
cd /mnt/cube1/software/ossimport。
二、配置hdfs-oss.cfg文件
任务需要指定到目录层级。
如果需要迁移源端所有的数据,创建1个迁移任务即可。
如果只迁移源端N个目录下的数据,则创建N个任务。
输入
cd /mnt/cube1/software/ossimport/conf,找到hdfs-oss.cfg文件。根据迁移任务个数复制hdfs-oss.cfg文件,并做好文件区分,例如hdfs-oss1.cfg。
执行命令,打开其中一个cfg文件,修改或填写配置文件里的下列内容。
参数名
示例
jobName
任务名,例如:example_job
srcType
数据源类型设置为hdfs
srcAccessKey
HDFS源超级管理员用户名设置为hdfs
srcSecretKey
HDFS源超级管理员用户名设置为hdfs
srcDomain
填写源端hdfs访问路径,格式为hdfs://hdfs主节点IP:hdfs服务端口,例如:hdfs://192.168.24.247:8020
srcBucket
HDFS源默认值为hdfs
srcPrefix
填写源路径,注意后面要加上/,例如:/mnt/nas/example_dir/
destType
写入闪电立方本地NAS服务设置为local
destPrefix
闪电立方存储池1的路径为/mnt/cube1/data/,存储池2的路径:/mnt/cube2/data
auditMode
simple
部署和提交任务
HDFS目录下有个console.sh脚本,以下操作均在HDFS目录下完成。
执行以下命令,部署服务
bash console.sh deploy执行以下命令,启动服务。
bash console.sh start执行以下命令,检查进程是否正常启动。
ps -ef | grep jar如果有master.jar、worker.jar、tracker.jar三个进程,说明启动正常。
执行以下命令,提交迁移任务。
bash console.sh submit conf/cfg文件名
(可选)增量配置
如果需要配置增量,需对cfg文件中以下3个参数进行修改。
isIncremental为增量模式,设置该值为true。incrementalModeInterval为增量间隔时间,单位是秒,不能低于900秒。repeatCount为增量的次数,最好不要配置太大,建议不超过30。配置值为实际增量次数+1,例如需要2次增量,则repeatCount=3。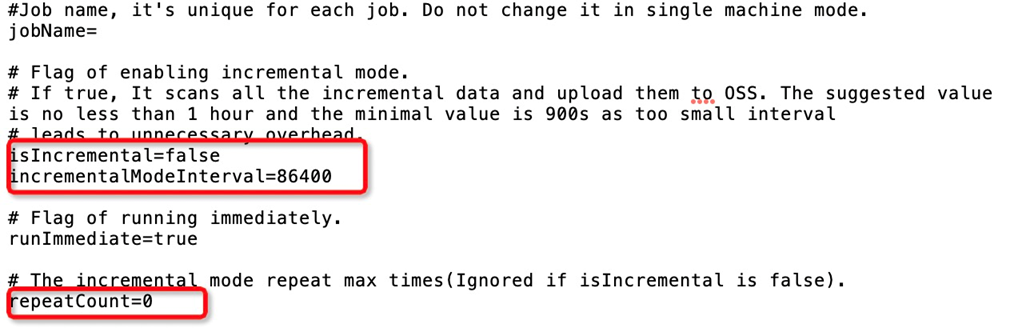
(可选) 配置sys.properties文件
workerTaskThreadNum调整任务线程数量。小文件数量多的情况下,适量调大线程可提升迁移速度。
jobNetFlowLimiter限制机器的网络流量。可对整机限流,也可仅对任务限流。
对整机限流:格式为
worker-level-netflow-policy,起始时间:终止时间:限流速度(单位是字节),如果需多时间段限流,每个时间段之间用逗号间隔。例如:
jobNetFlowLimiter=worker-level-netflow-policy,080000:200000:52428800,200000:235959:104857600,表示8点-20点限流50 MB,20点-23:59:59限流100 MB,其余时间不限流。对任务限流:格式为
job名称,起始时间::终止时间:限流速度(单位是字节),如果需多时间段限流,每个时间段之间用逗号间隔。如果多任务限流,任务之间用分号间隔。例如:
jobNetFlowLimiter=job1,080000:200000:41943040,200000:235959:62914560;job2,080000:180000:10485760,220000:235959:20971520,表示job1,8点-20点限流40 MB,20点-23:59:59限流60 MB,其余时间不限流。job2,8点-18点限流10 MB,22点-23:59:59限流20 MB,其余时间不限流。
(可选)重试任务
当您任务出现失败情况时,您可以通过这个命令进行重试任务:bash console.sh retry [job_name]
查看日志
在ossimport/workdir/logs/ 目录下,会存放一些日志用于记录文件的上传状态以及任务的状态。
任务进度日志
job_status.log该文件30秒更新一次,用于简单记录任务的状态信息。jobname 任务名称
jobState 任务状态(running表示任务进行中;succeed表示任务成功;failed表示任务失败,有未迁移成功的文件)。
pending task count 扫描预分发的task数量。
dispatched task count 分发的task数量。
succeed task count 成功的task 数量。
failed task count 失败的task数量。
is scan Finished 是否扫描完成(true表示已扫描完,false表示未扫描完)。注意:增量状态下这个值一直是false。
上传文件日志
fileStatusForSls_v1.log记录上传文件的日志,每条文件上传成功都会打印一条日志(字段间以逗号分割,以下数字表示该字段的相对位置)文件里面记录了如下信息:第4列:文件路径名称。
第6列:任务名称,
第12列:文件迁移状态( succeed,failed)。
第13列:失败原因。
第16列:Object大小。
任务状态日志
jobsForSls_v1.log 记录整个任务的状态信息,每分钟更新一次,直到所有任务都结束为止。记录如下信息:
第5列:任务名称。
第9列:任务状态。
第14列:总的文件数量。
第15列:总的文件大小。
第16列:成功文件数量。
第17列:成功的文件大小。
第21列:是否扫描完成(1 表示扫描完成,0 表示未扫描完成)。
- 本页导读 (1)