
DataHub Kafka兼容模式
DataHub 已经兼容 Kafka 的协议,用户可以直接使用Kafka的sdk来连接 DataHub 服务,进行数据的订阅和发布。
DataHub&Kafka概念映射
Kafka | Datahub |
Topic | Project.Topic |
partition | shard |
offset | sequence |
Kafka Topic
DataHub 也有 Topic,并且资源层级上 DataHub 还有 Project,而 Kafka 是没有 Project 的,所以为了兼容这个逻辑,DataHub 的 Project 和 Topic 组合后就是 Kafka 的 topic,组合方式采用"."来连接。例如:在 DataHub 中我有 Project 和 Topic 分别是 test_project 和 test_topic,那么使用 Kafka 协议的时候,Topic 名称就是 test_project.test_topic。
Kafka Parittion
Kafka 的 partition 和 DataHub 的 shard 一一对应,意义也相同,都是代表一个有序的队列。
Kafka Consumer Group
DataHub group行为和 Kafka 基本保持一致,用户可以在project下创建group并绑定想要订阅的topic,就可以使用该group订阅这个project下的多个topic。如果group绑定了topic,用户可以在topic页面的订阅列表页面,看到由group自动创建的订阅,删除该订阅会导致group无法订阅该topic,并且之前的消费点位都会消失。
因为 group 是 project 的子资源,所以指定时需要和 project 一起指定。例如:在 DataHub 中有 project 和 group 分别是 test_project 和 test_group,那么使用 Kafka 协议的时候,group 名称就是 test_project.test_group。
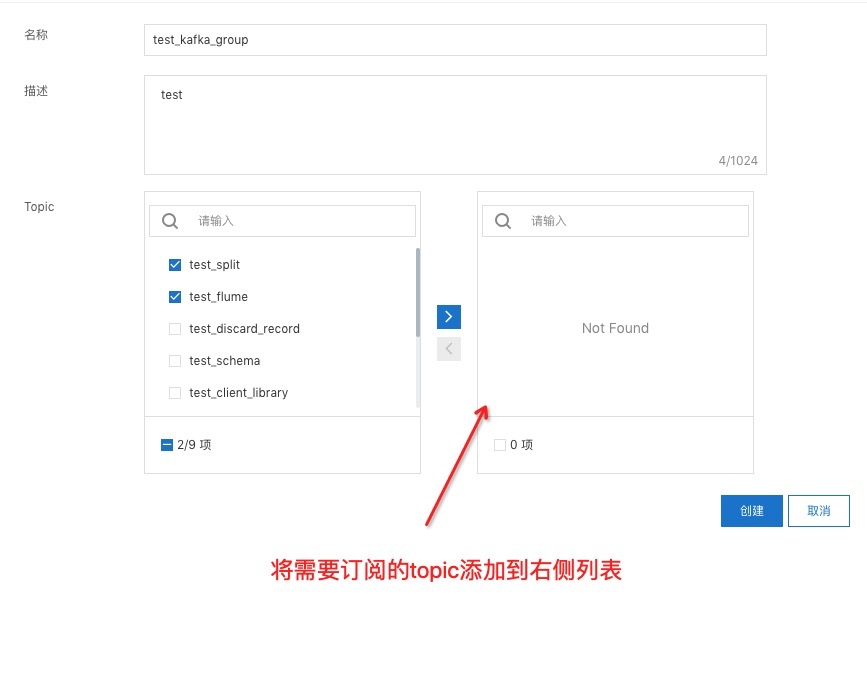
目前单个group限制最多可以订阅50个topic,如果需要订阅更多,请开工单联系我们。
Kafka Record
Kafka Record 是 key-val 的形势,而 DataHub 的 Record 分为两种形式 Tuple 和 Blob,Tuple 是强结构化数据, BlobRecord 是二进制数据。对于Kafka Record 一般分为两部分信息,Header 和 key-value。
Kafka 的 header
Kafka header 可以给数据添加额外信息,这个和 DataHub 的 attribute 作用一致,如果使用 Kafka 客户端写入数据时携带了 header 信息,那么这个信息会放到 DataHub 的 attribute 上。如果Kafka的Header的value为NULL,则会忽略掉对应的header。建议不要使用"__kafka_key__"作为Header的key,这个是内部保留 key。
Kafka 的 key-value 数据
DataHub Topic 是 Tuple 类型,key 对应第一列 String,value 对应第二列 String
DataHub Topic 是 Blob 类型,value 对应数据内容,key 放入 attribute,其中格式为<"**__kafka_key__**", key>
Kafka Offset
Kafka offset 是一个 64 位的整型数字,对于一个 partition 来说,offset 从 0 开始自增,因此每条数据都有独一无二的 offset,主要用于消费点位的记录。DataHub 的 sequence 和 Kafka 的 offset 含义一致,因此用户可以直接认为 DataHub 的 sequence 和 Kafka 的 offset 是完全对标的。
使用限制
DataHub不支持Kafka事务、幂等 、SchemaRegistry、Log Compaction。
快速开始
使用kafka client 推荐版本2.4.0,兼容0.10.0~4.0。
在 DataHub 上创建对应的资源,Project、Topic 和 Group。
安全认证方式切换为SASL+SSL,SASL 使用的是 PLAIN,同时配置好阿里云的 AK/SK。
Kafka 的broker 信息切换为 DataHub 的 Endpoint(参考服务域名列表)
资源创建
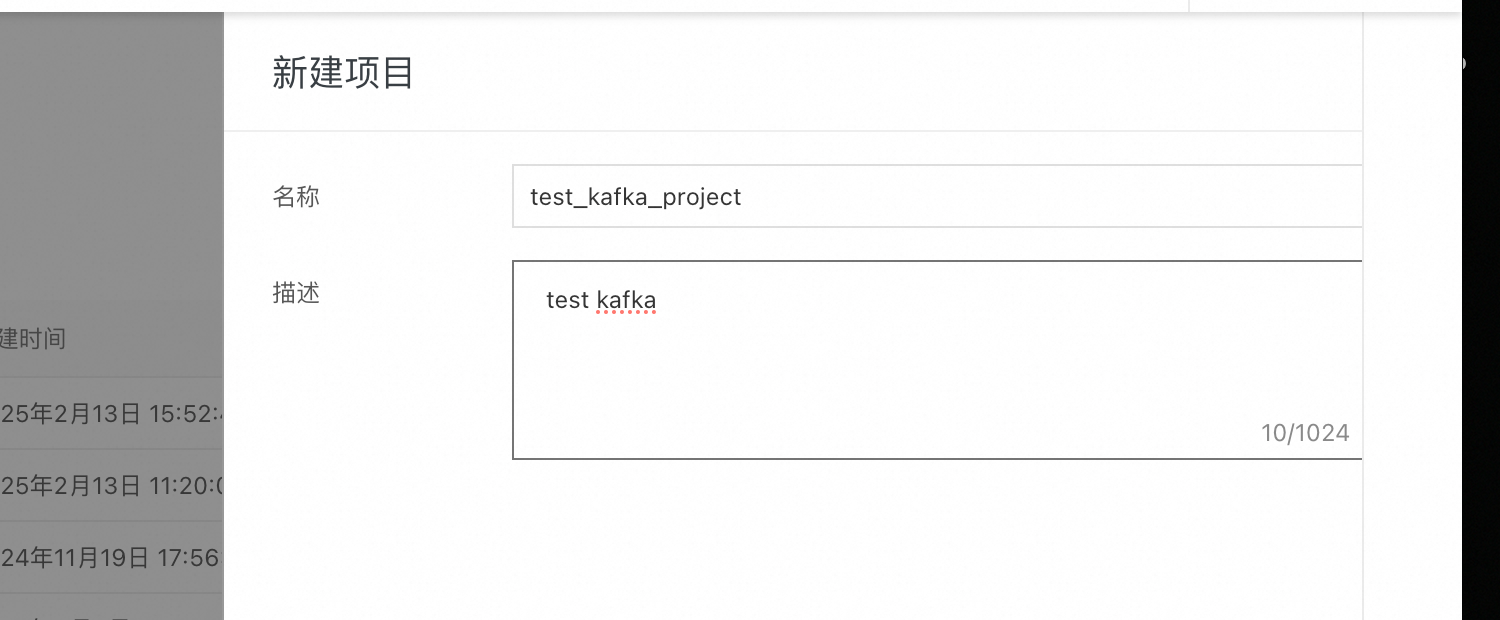
首先登录DataHub 控制台,创建 project
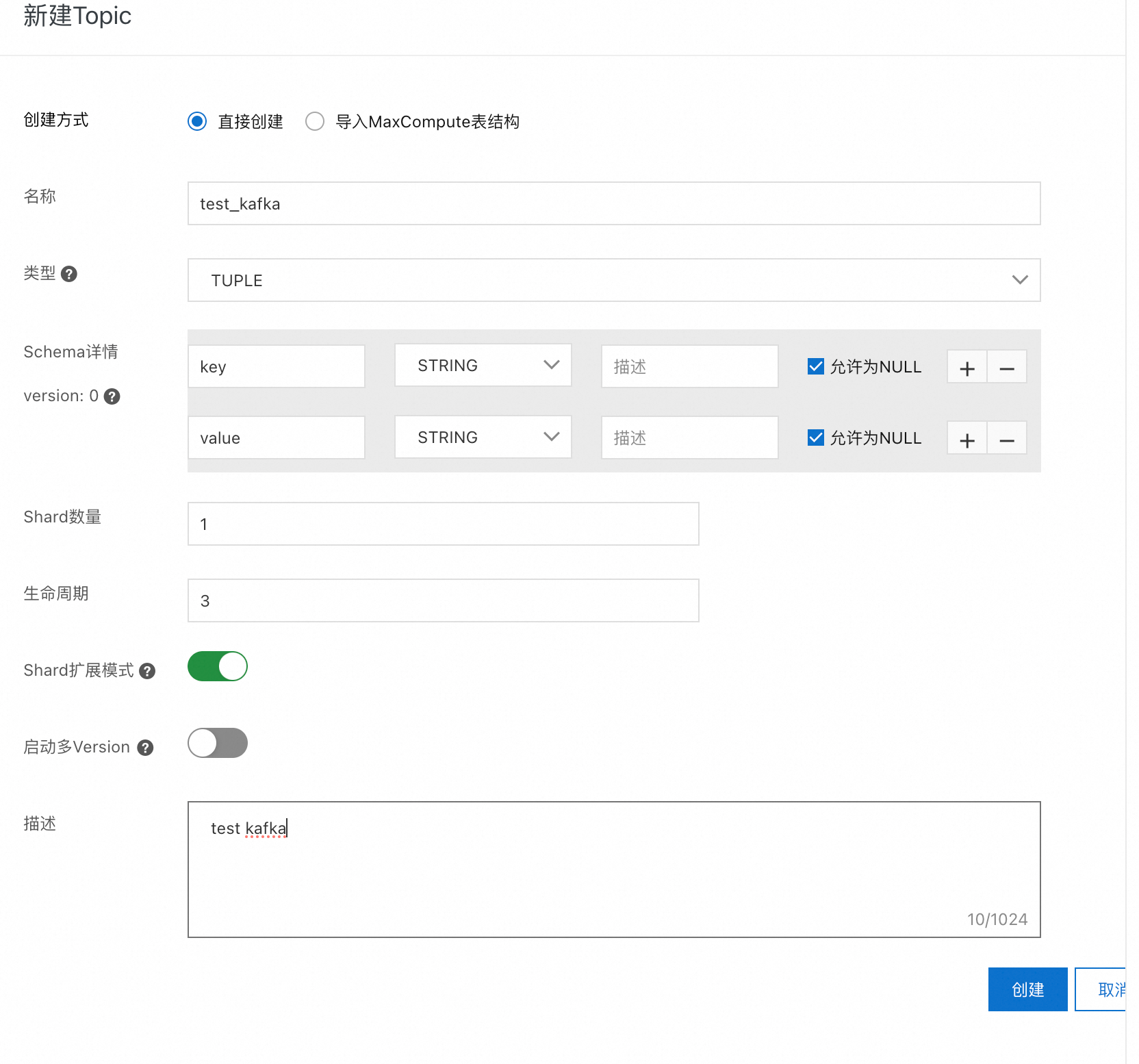
创建 topic
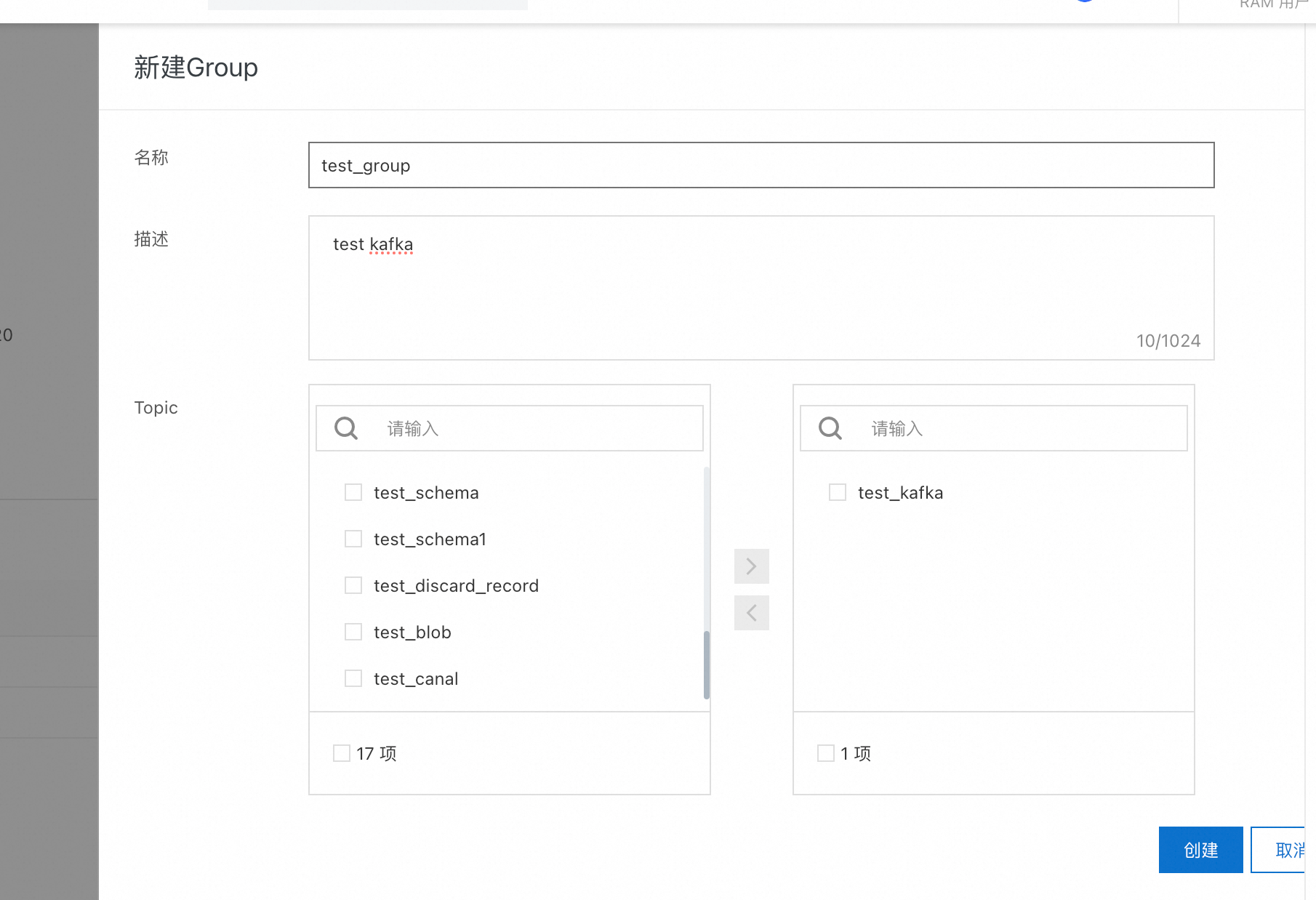
创建 group 并绑定需要消费的 topic,创建完成以后也可以修改绑定的 topic 列表。如果是非消费场景,那么可以直接跳过这一步。
认证方式
创建文件kafka_client_producer_jaas.conf,保存到任意路径,文件内容如下。
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="accessId"
password="accessKey";
};同时配置中添加如下内容
// 把ak的配置文件目录添加进来,也可以通过设置环境变量的方式设置
static {
System.setProperty("java.security.auth.login.config", "/xxxpath/kafka_client_producer_jaas.conf");
}
// 安全认证方式设置为 SASL + SSL
// Properties properties = new Properties();
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");Producer 示例
kafka clients pom 文件
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>
ProducerExample
public class ProducerExample {
static {
System.setProperty("java.security.auth.login.config", "/path/xxx/kafka_client_producer_jaas.conf");
}
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "dh-cn-hangzhou.aliyuncs.com:9092");
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("compression.type", "lz4");
properties.put("enable.idempotence", "false"); // 3.0.1及以上版本需要添加
String KafkaTopicName = "test_project.test_topic";
Producer<String, String> producer = new KafkaProducer<String, String>(properties);
try {
List<Header> headers = new ArrayList<>();
RecordHeader header1 = new RecordHeader("key1", "value1".getBytes());
RecordHeader header2 = new RecordHeader("key2", "value2".getBytes());
headers.add(header1);
headers.add(header2);
ProducerRecord<String, String> record = new ProducerRecord<>(KafkaTopicName, 0, "key", "Hello DataHub!", headers);
// sync send
producer.send(record).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
producer.close();
}
}
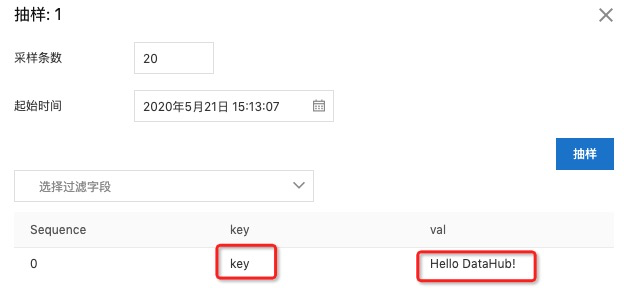
}运行成功之后,可以在 DataHub抽样一下,确认是否正常DataHub。
Consumer 示例
ConsumerExample
package com.aliyun.datahub.kafka.demo;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class ConsumerExample2 {
static {
System.setProperty("java.security.auth.login.config", "/path/xxx/kafka_client_producer_jaas.conf");
}
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "dh-cn-hangzhou.aliyuncs.com:9092");
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");
properties.put("group.id", "test_project.test_kafka_group");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "60000");
properties.put("heartbeat.interval.ms", "40000");
properties.put("ssl.endpoint.identification.algorithm", "");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
List<String> topicList = new ArrayList<>();
topicList.add("test_project.test_topic1");
topicList.add("test_project.test_topic2");
topicList.add("test_project.test_topic3");
kafkaConsumer.subscribe(topicList);
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.toString());
}
}
}
}运行成功之后,便可以在终端看到读取到的数据。
ConsumerRecord(topic = test_project.test_topic, partition = 0, leaderEpoch = 0, offset = 0, LogAppendTime = 1611040892661, serialized key size = 3, serialized value size = 14, headers = RecordHeaders(headers = [RecordHeader(key = key1, value = [118, 97, 108, 117, 101, 49]), RecordHeader(key = key2, value = [118, 97, 108, 117, 101, 50])], isReadOnly = false), key = key, value = Hello DataHub!)Streams示例
这里读取test_project下input的数据,将key和value的字符串转为小写重新写入output。
public class StreamExample {
static {
System.setProperty("java.security.auth.login.config", "/path/xxx/kafka_client_producer_jaas.conf");
}
public static void main(final String[] args) {
final String input = "test_project.input";
final String output = "test_project.output";
final Properties properties = new Properties();
properties.put("bootstrap.servers", "dh-cn-hangzhou.aliyuncs.com:9092");
properties.put("application.id", "test_project.test_kafka_group");
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");
properties.put("session.timeout.ms", "60000");
properties.put("heartbeat.interval.ms", "40000");
properties.put("auto.offset.reset", "earliest");
final StreamsBuilder builder = new StreamsBuilder();
TestMapper testMapper = new TestMapper();
builder.stream(input, Consumed.with(Serdes.String(), Serdes.String()))
.map(testMapper)
.to(output, Produced.with(Serdes.String(), Serdes.String()));
final KafkaStreams streams = new KafkaStreams(builder.build(), properties);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
static class TestMapper implements KeyValueMapper<String, String, KeyValue<String, String>> {
@Override
public KeyValue<String, String> apply(String s, String s2) {
return new KeyValue<>(StringUtils.lowerCase(s), StringUtils.lowerCase(s2));
}
}
}启动Streams任务之后,分配shard大概需要1分钟左右,1分钟之后就可以在控制台看到当前的task数量,task数量和输入topic的shard数量保持一致,示例输入topic为3个shard。
currently assigned active tasks: [0_0, 0_1, 0_2]
currently assigned standby tasks: []
revoked active tasks: []
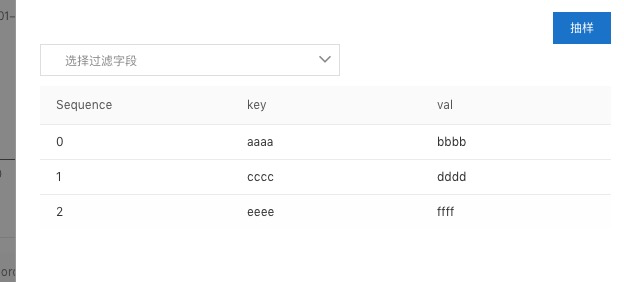
revoked standby tasks: []shard分配成功之后,可以向input中写入一组测试数据 (AAAA,BBBB),(CCCC,DDDD),(EEEE,FFFF),之后再output抽样一下,查看数据是否正确写入。
自建Kafka切流到DataHub
切换broker地址,具体可以参考下文的域名列表;
在DataHub上创建资源并修改代码中的资源名称,具体可以参考上文的资源创建;
认证方式切换为SASL_SSL,具体使用的认证机制是PLAIN,username和password分别填写阿里云的ak和sk即可;
附录
配置介绍
C=Consumer, P=Producer, S=Streams
参数 | C/P/S | 可选配置 | 是否必须 | 描述 |
bootstrap.servers | * | 参考域名列表 | 是 | |
security.protocol | * | SASL_SSL | 是 | 为了保证数据传输的安全性,Kafka写入DataHub默认使用SSL加密传输 |
sasl.mechanism | * | PLAIN | 是 | AK认证方式,仅支持PLAIN |
compression.type | P | LZ4 | 否 | 是否开启压缩传输,目前仅支持LZ4 |
enable.idempotence | P | false | 否 | kafka client 从 3.0.1 开始默认开启了幂等,因 DataHub 暂不支持幂等,所以需要手动关闭,小于 3.0.1 的版本不需要添加此配置 |
group.id | C | project.group | 是 | |
partition.assignment.strategy | C | org.apache.kafka.clients.consumer.RangeAssignor | 否 | Kafka默认为RangeAssignor,并且DataHub目前只支持RangeAssignor,请不要修改此配置 |
session.timeout.ms | C/S | [60000, 180000] | 否 | kafka默认为10000, 但是因为DataHub限制最小为60000,所以这里默认会变为60000 |
heartbeat.interval.ms | C/S | 建议session.timeout.ms的 2/3 | 否 | Kafka默认为3000,但是因为 |
application.id | S | project.topic:subId或者project.group | 是 | 使用project.topic:subId时必须和订阅的topic保持一致,否则无法读取数据,推荐使用project.group |
服务域名列表
地区 | Region | 公网Endpoint | VPC ECS Endpoint |
华东1(杭州) | cn-hangzhou | dh-cn-hangzhou.aliyuncs.com:9092 | dh-cn-hangzhou-int-vpc.aliyuncs.com:9094 |
华东2(上海) | cn-shanghai | dh-cn-shanghai.aliyuncs.com:9092 | dh-cn-shanghai-int-vpc.aliyuncs.com:9094 |
华北2(北京) | cn-beijing | dh-cn-beijing.aliyuncs.com:9092 | dh-cn-beijing-int-vpc.aliyuncs.com:9094 |
乌兰察布 | cn-wulanchabu | dh-cn-wulanchabu.aliyuncs.com:9092 | dh-cn-wulanchabu-int-vpc.aliyuncs.com:9094 |
华南1(深圳) | cn-shenzhen | dh-cn-shenzhen.aliyuncs.com:9092 | dh-cn-shenzhen-int-vpc.aliyuncs.com:9094 |
华北3(张家口) | cn-zhangjiakou | dh-cn-zhangjiakou.aliyuncs.com:9092 | dh-cn-zhangjiakou-int-vpc.aliyuncs.com:9094 |
亚太东南1(新加坡) | ap-southeast-1 | dh-ap-southeast-1.aliyuncs.com:9092 | dh-ap-southeast-1-int-vpc.aliyuncs.com:9094 |
亚太东南3(吉隆坡) | ap-southeast-3 | dh-ap-southeast-3.aliyuncs.com:9092 | dh-ap-southeast-3-int-vpc.aliyuncs.com:9094 |
欧洲中部1(法兰克福) | eu-central-1 | dh-eu-central-1.aliyuncs.com:9092 | dh-eu-central-1-int-vpc.aliyuncs.com:9094 |
上海金融云 | cn-shanghai-finance-1 | dh-cn-shanghai-finance-1.aliyuncs.com:9092 | dh-cn-shanghai-finance-1-int-vpc.aliyuncs.com:9094 |
中国香港 | cn-hongkong | dh-cn-hongkong.aliyuncs.com:9092 | dh-cn-hongkong-int-vpc.aliyuncs.com:9094 |
Kafka API 兼容情况
Kafka 官方文档列出了所有的 api,为了方便用户了解 kod 的兼容情况,我们也把已兼容的 API 列表给出。
接口 | 描述 |
Produce | 数据写入 |
Fetch | 数据读取 |
ListOffsets | 旧版本根据时间获取offset列表,新版本根据时间获取offset |
Metadata | 读写数据时获取meta信息 |
OffsetCommit | 提交点位 |
OffsetFetch | 获取点位 |
FindCoordinator | 查找coordinator所在broker,直接返回vip即可 |
JoinGroup | 加入group |
Heartbeat | 心跳 |
LeaveGroup | 离开group |
SyncGroup | leader用来发送分配方案,leader和follower获取分配方案 |
SaslHandshake | 鉴权相关 |
ApiVersions | 获取所有可用接口 |
CreateTopics | 创建topic |
DeleteTopics | 删除topic |
OffsetForLeaderEpoch | 获取最新的offset |
SaslAuthenticate | 鉴权相关 |
CreatePartitions | 添加partition |
DeleteGroups | 删除group |
OffsetDelete | 清除点位 |