准备工作
1. 创建ES index
DataHub⽀持将数据同步到Elasticsearch对应的index中,目前支持ES5、ES6和ES7的实例。
⽬前DataHub仅⽀持将TUPLE类型Topic的数据同步到Elasticsearch中。开始同步任务之前请保证已经在ES中创建index或者允许自动创建index,否则同步任务会失败。
2.准备同步任务账号并授权
新建同步ES任务时,需要用户手动填写ES的endpoint、index和账号密码等信息。请确保所填入信息账号信息真实有效,否则会导致创建同步任务失败。
创建同步任务
一次进入
项目列表/project详情/Topic详情页面点击右上角的
+同步选择
Elasticsearch类型作业,如下图所指示:
配置说明
1. Endpoint
ElasticSearch服务地址,需要填写内网地址和和内网端口,格式为内网地址:内网端口。
例如:内网地址为 es-cn-xxx.elasticsearch.aliyuncs.com,内网端口为9200,则填入es-cn-xxx.elasticsearch.aliyuncs.com:9200。
2. Index
目前支持两种index的指定方式:静态index和动态index。
静态index
用户预先创建好一个index或者允许自动创建index,所有的数据都会写入该index。
动态index
用户需要允许自动创建index,否则会写入失败。用户可以指定一个时间周期或者指定某列作为index的生成方式。如果采用数据列生成index,那么最多可以选择1列。
支持配置的时间格式
年 | 月 | 日 | 周 |
%Y | %m | %d | %U |
示例一:每天凌晨生成一个新的index配置index为test_${%Y-%m-%d},如果当前日期为2021年3月31日,那么最终写入的index为test_2021-03-31
示例二:根据数据列生成新的index数据列中包含有一列col1,配置index为test_${col1},如果有两条数据,这两条数据的col1分别为AAA和BBB,那么这两条数据写入的index分别为test_AAA和test_BBB。
当ES中的index数量增多时,写入数据会变慢,过多可能会导致DataHub写入超时,因此用户使用动态index时,需要尽量避免生成的index数量过多
3. User/Password
访问ES的用户名密码。
4. Type属性列
针对不同版本,DataHub同步ES的生成的Type也不一样。在ES5中,用户可以在一个index中创建多个type,但是ES6中,用户只能在一个index中创建一个type,因此,DataHub同步ES的行为也有所改变。Type不可以为空。
对于ES5,DataHub同步数据时,将会以用户选择作为Type的列的值作为一条数据的type,如果选择多列,则多列的值会以 “|” 分割作为一条数据的type。选择作为Type属性列的字段不能为null。
对于ES6,DataHub同步数据时,将会以用户选择的列的列名作为一条数据的type,如果选择多列,则多列的列名会以“|”分割作为一条数据的type,并且ES6支持以任意名称作为type。
例如:
DataHub Schema : f1 string, f2 string, f3 string, f4 string
数据 : ["test1","test2","test3",null]type属性列 | ES5 type | ES6 type |
f1 | test1 | f1 |
f1,f3 | test1 | test3 |
ff | 创建失败 | ff |
f1,ff | 创建失败 | f1|ff |
f4 | 创建成功,但同步失败,脏数据 | 创建成功,并成功同步 |
备注:
目前在页面上创建同步ES6任务时无法自定义type名称,如果想要自定义用户可以使用SDK来创建。
ES7中所有的type均采用默认type,所以 ES7不需要选择type属性列。
5. ID属性列
用户可以根据写入DataHub的数据来生成写入ES的数据id,也可以不选择任何列,由ES将会为每条数据生成一个唯一的id。DataHub同步ES时,将会以用户选择的列的值作为一条数据的id,如果选择多列,则多列的值会以 “|” 分割作为一条数据的id。选择作为ID属性列的字段不能为null。
例如:
DataHub Schema : f1 string, f2 string, f3 string, f4 string
数据 : ["test1","test2","test3",null]ID属性列 | 数据id |
ES自动生成唯一ID | |
f1 | test1 |
f1,f3 | test1|test3 |
ff | 创建失败 |
f4 | 创建成功,但是同步失败,脏数据 |
6. Router属性列
用户可以根据写入DataHub的数据来生成写入ES的router,也可以不选择任何列,不选择时将不使用ES的Router功能。DataHub同步ES时,将会以用户选择的列的值作为一条数据的router,如果选择多列,则多列的值会以 “|” 分割作为一条数据的id。选择作为Router属性列的字段不能为null。
示例可参考ID属性列。
7. 导入字段
DataHub需要导入到ES的字段,对于未选择的字段,DataHub不会同步到ES中。对于作为ID的字段和ES5中作为Type的字段,不会再放到数据中。因为导入字段并不能完全决定最后生成的数据,因此不再给出示例,下文会给出完整的数据同步示例。
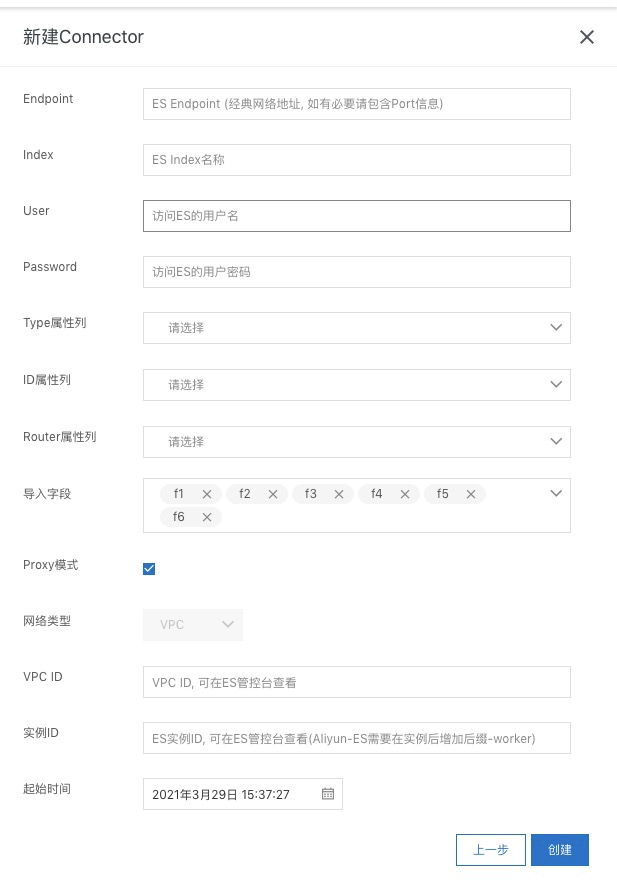
8. 网络类型
需要根据ES示例的类型选择,因为目前公有云上的ES实例均为VPC实例,所以DataHub公有云同步ES任务只支持VPC网络类型。使用VPC网络类型时,需要填写VPC ID和实例ID等信息,查看方式如下图。
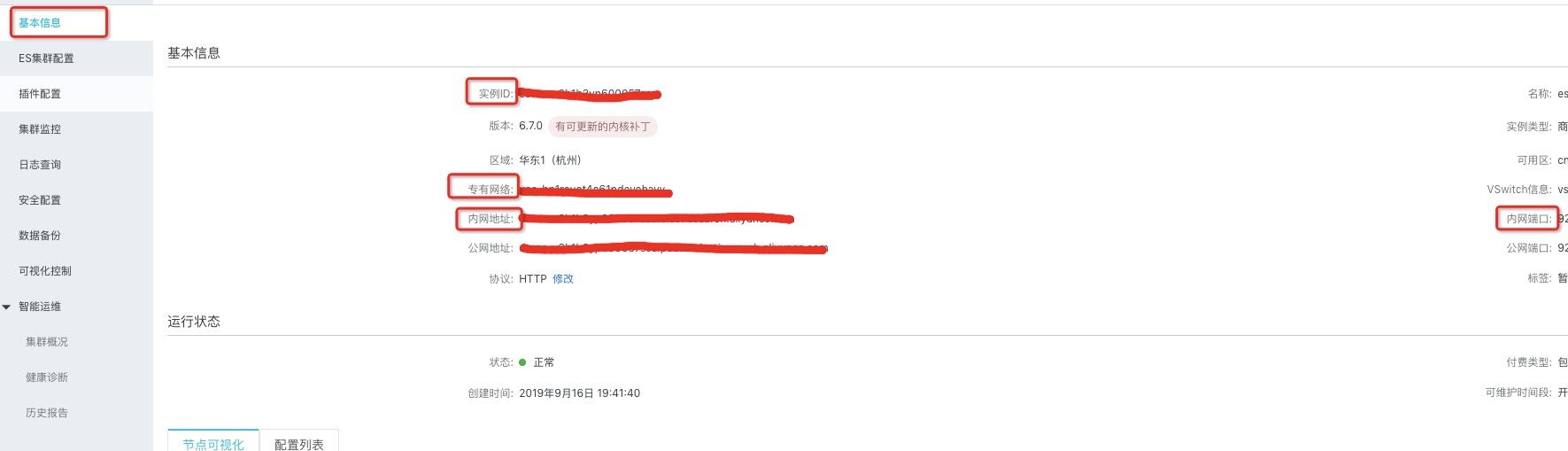
注意:填入实例ID时需要注意加上-worker,例如实例ID为es-cn-xxx,则实例ID填写es-cn-xxx-worker。
写入数据示例
这里的示例是指创建同步ES任务成功之后,如果创建同步ES任务失败,则参考上述的配置进行修改。
DataHub Schema为:
字段名称 | 字段类型 |
f1 | BIGINT |
f2 | STRING |
f3 | BOOLEAN |
f4 | DOUBLE |
f5 | TIMESTAMP |
f6 | DECIMAL |
示例1:
Type属性列 = f1(ES7无Type属性列)
ID属性列 = f2
导入字段 = f1,f2,f3,f4,f5,f6
数据 = v1,v2,v3,v4,v5,v6
ES版本 | type | id | data |
ES5 | v1 | v2 |
|
ES6 | f1 | v2 |
|
ES7 | - | v2 |
|
数据 = null,v2,v3,v4,v5,v6
ES版本 | type | id | data |
ES5 | - | - | type属性列为null,脏数据 |
ES6 | f1 | v2 |
|
ES7 | - | v2 |
|
数据 = v1,null,v3,v4,v5,v6
ES版本 | type | id | data |
ES5 | - | - | id属性列为null,脏数据 |
ES6 | - | - | id属性列为null,脏数据 |
ES7 | - | - | id属性列为null,脏数据 |
示例2:
Type属性列 = f1,f2(ES7无Type属性列)
ID属性列 = f3,f4
导入字段 = f1,f2,f3,f4,f5,f6
数据 = v1,v2,v3,v4,v5,v6
ES版本 | type | id | data |
ES5 | v1|v2 | v3|v4 |
|
ES6 | f1|f2 | v3|v4 | {f1:v1,f2:v2,f5:v5,f6:v6} |
ES7 | - | v3|v4 | {f1:v1,f2:v2,f5:v5,f6:v6} |
数据 = v1,null,v3,v4,v5,v6
ES版本 | type | id | data |
ES5 | - | - | type属性列为null,脏数据 |
ES6 | f1|f2 | v3|v4 | {f1:v1,f2:v2,f5:v5,f6:v6} |
ES7 | - | v3|v4 | {f1:v1,f2:v2,f5:v5,f6:v6} |
数据 = v1,v2,null,v4,v5,v6
ES版本 | type | id | data |
ES5 | - | - | id属性列为null,脏数据 |
ES6 | - | - | id属性列为null,脏数据 |
ES7 | - | - | id属性列为null,脏数据 |
示例3:
Type属性列 = f1(ES7无Type属性列)
ID属性列 = f2
Router属性列 = f3
导入字段 = f1,f2,f3,f4,f5,f6
数据 = v1,v2,v3,v4,v5,v6
ES版本 | type | id | router | data |
ES5 | v1 | v2 | v3 |
|
ES6 | f1 | v2 | v3 |
|
ES7 | - | v2 | v3 |
|
数据 = null,v2,v3,v4,v5,v6
ES版本 | type | id | data |
ES5 | - | - | type属性列为null,脏数据 |
ES6 | f1 | v2 |
|
ES7 | - | v2 |
|
数据 = v1,null,v3,v4,v5,v6
ES版本 | type | id | data |
ES5 | - | - | id属性列为null,脏数据 |
ES6 | - | - | id属性列为null,脏数据 |
ES7 | - | - | id属性列为null,脏数据 |
数据 = v1,v2,null,v4,v5,v6
ES版本 | type | id | data |
ES5 | - | - | router属性列为null,脏数据 |
ES6 | - | - | router属性列为null,脏数据 |
ES7 | - | - | router属性列为null,脏数据 |
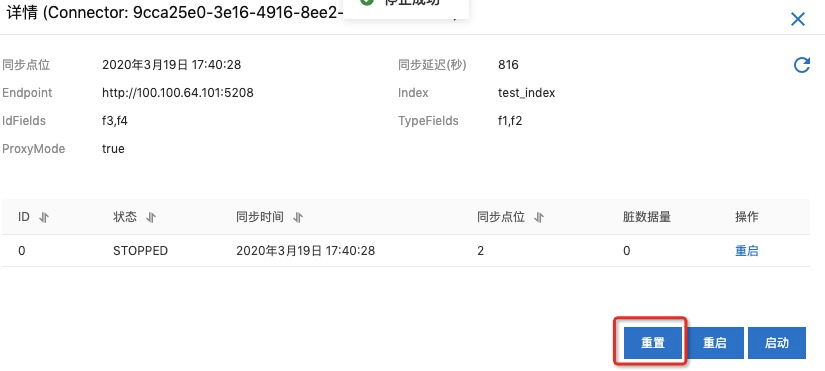
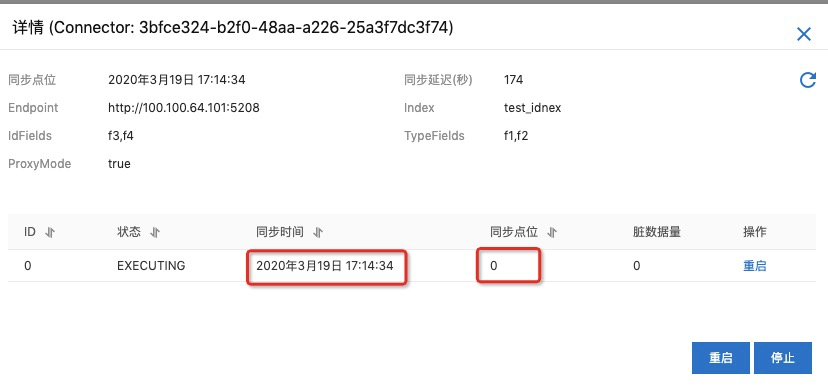
查看同步任务
可以点击对应connector的详情⻚⾯查看同步任务的运⾏状态和点位等信息, 包含同步点位、同步状态以及重启和停⽌等操作,如下图所示:
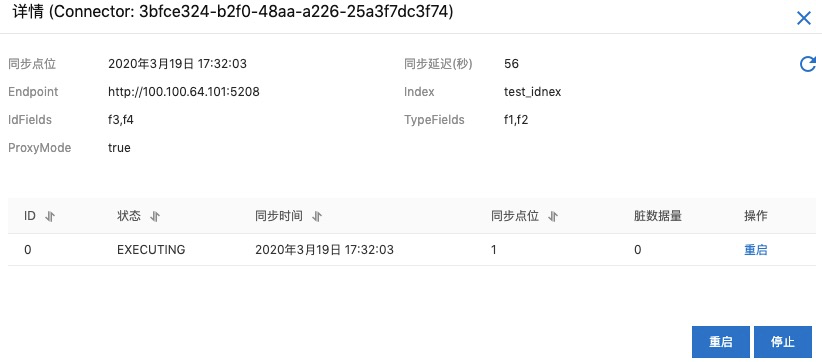
备注:需要先停止任务才可以进行充值点位操作
同步示例
本示例以阿里云ES6.7为例,展示DataHub同步到ES的完整操作。其中ES相关的操作均使用Kibana Dev Tools执行,其他操作方法请参考ES官方文档。
1. 创建ES index
一般情况下可以ES默认可以自动创建index,因此可以忽略这一步。如果设置了不允许自动创建,那需要手动创建一下index,具体创建命令可参考ES官方文档。
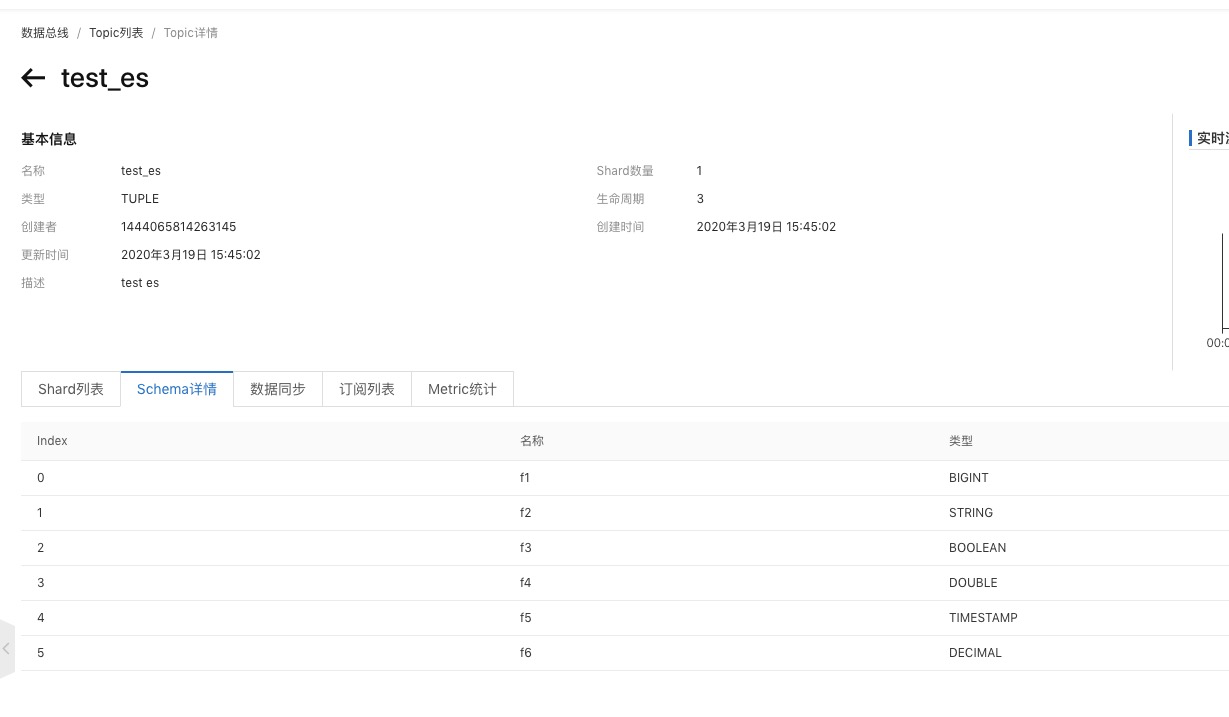
2. 建立DataHub Topic
备注:目前仅支持Tuple类型的Topic建立同步ES任务。
创建DataHub的过程可以参考创建Topic。
创建完成之后查看创建的Topic。
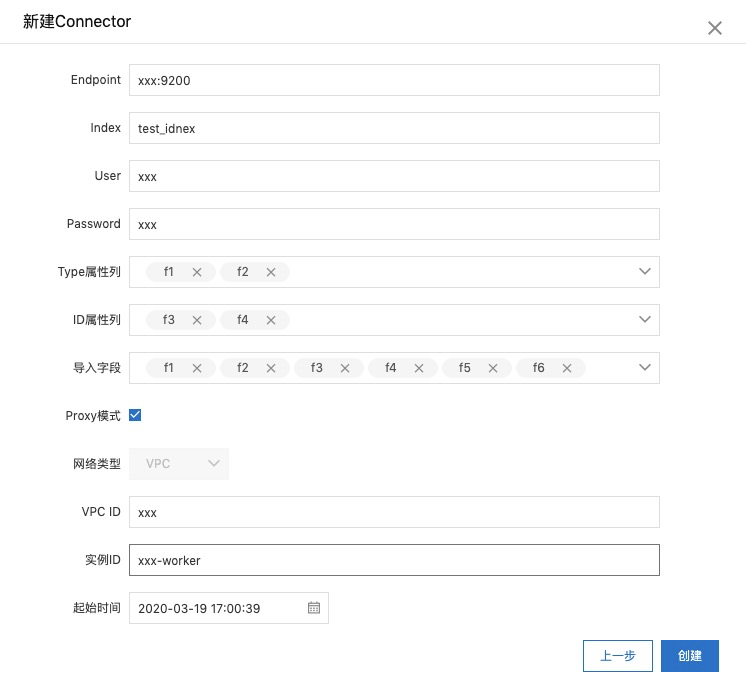
3. 建立同步ES任务
这里创建同步ES任务时,将f1和f2作为Type属性列,将f3和f4作为ID属性列,并将所有字段作为导入字段。
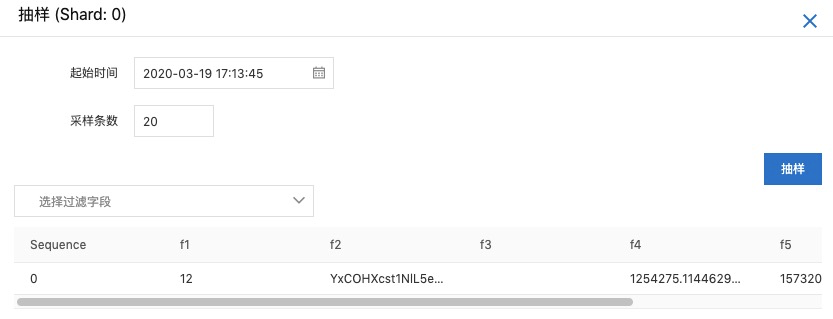
4. 向DataHub Topic写⼊数据
可以使⽤DataHub-SDK或者DataHub插件进⾏数据写⼊。
写入一条数据之后,在页面上进行抽样,查看一下写入的数据。
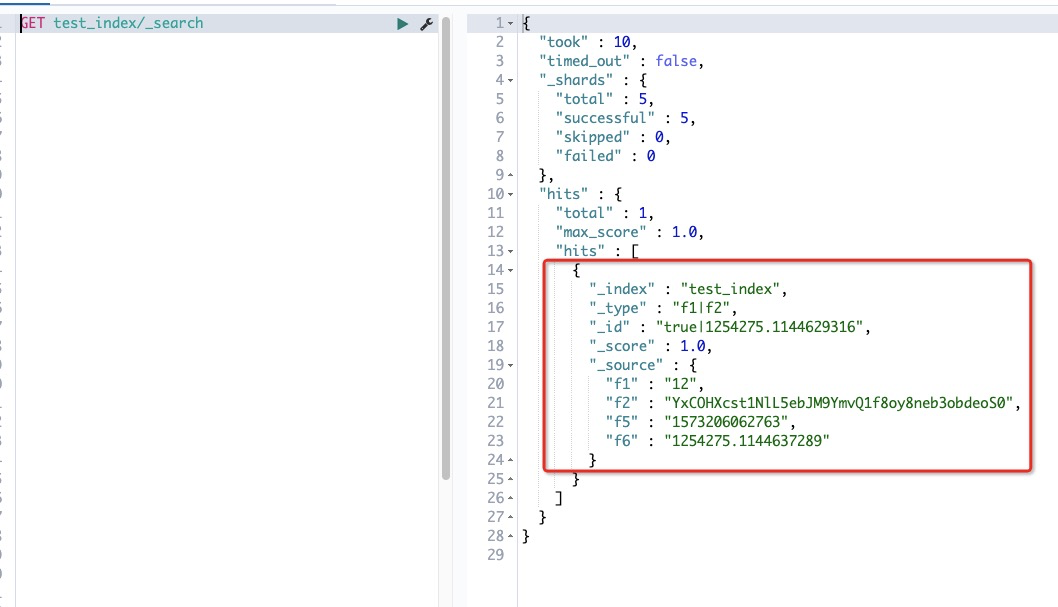
5. 确认同步数据
首先查看一下ES同步任务的点位。
这里可以看到同步任务的点位和同步时间发生了变化,同步时间就是刚刚数据写入DataHub的时间,同步点位变成了1(点位从0开始计算,点位为0表示第一条数据已经写入)。
然后在ES查看一下数据的同步情况,通过Kibana可以看到数据已经同步成功。