
Greenplum输入组件用于读取Greenplum数据源的数据。同步Greenplum数据源的数据至其他数据源的场景中,您需要先配置Greenplum输入组件读取的数据源,再配置数据同步的目标数据源。本文为您介绍如何配置Greenplum输入组件。
前提条件
已创建Greenplum数据源。具体操作,请参见创建Greenplum数据源。
进行Greenplum输入组件属性配置的账号,需具备该数据源的同步读权限。如果没有权限,则需要申请数据源权限。具体操作,请参见申请数据源权限。
操作步骤
在Dataphin首页顶部菜单栏,选择研发 > 数据集成。
在集成页面顶部菜单栏选择项目(Dev-Prod模式需要选择环境)。
在左侧导航栏中单击离线集成,在离线集成列表中单击需要开发的离线管道,打开该离线管道的配置页面。
单击页面右上角的组件库,打开组件库面板。
在组件库面板左侧导航栏中需选择输入,在右侧的输入组件列表中找到Greenplum组件,并拖动该组件至画布。
单击Greenplum输入组件卡片中的
 图标,打开Greenplum输入配置对话框。
图标,打开Greenplum输入配置对话框。在Greenplum输入配置对话框,配置参数。
参数
说明
步骤名称
即Greenplum输入组件的名称。Dataphin自动生成步骤名称,您也可以根据业务场景修改。命名规则如下:
只能包含中文、字母、下划线(_)、数字。
不能超过64个字符。
数据源
在数据源下拉列表中,展示当前Dataphin中所有Greenplum类型的数据源,包括您已拥有同步读权限的数据源和没有同步读权限的数据源。
对于没有同步读权限的数据源,您可以单击数据源后的申请,申请数据源的同步读权限。具体操作,请参见申请数据源权限。
如果您还没有Greenplum类型的数据源,单击新建,创建数据源。具体操作,请参见创建Greenplum数据源。
Schema
支持跨Schema读表,需选择来源表所在的Schema。如在数据源链接中已包含schema信息,则默认为配置的schema,也可选择其他有权限的schema。
来源表量
选择来源表量。来源表量包括单表和多表:
单表:适用于将一个表的业务数据同步至一个目标表的场景。
多表:适用于将多个表的业务数据同步至同一个目标表的场景。支持枚举形式、类正则形式以及两者混合形式,如
table_[001-100];table_102。
表匹配方式
可选择通用类规则或数据库正则。
说明仅当来源表量选择多表时,支持配置此项。
表
选择来源表:
如果来源表量选择了单表,可输入表名关键字进行搜索,或输入准确表名后单击精准查找。选择表后,系统将自动进行表状态检测。单击
 图标,可复制当前所选表的名称。
图标,可复制当前所选表的名称。如果来源表量选择了多表,则根据表匹配方式,可填写不同表达式来添加表。
表匹配方式选择通用类规则:在输入框中,输入表的表达式,筛选具有相同结构的表。 系统支持枚举形式、类正则形式及两者混合形式。例如,
table_[001-100];table_102;。表匹配方式选择数据库正则:在输入框中填写当前数据库支持的正则表达式,系统将根据此正则匹配目标库中的表。任务运行时将根据数据库正则即时匹配新的表范围进行同步
表达式填写完成后,可单击精准查找,在确认匹配详情对话框中,查看匹配表的列表。
切分键
您可以将源数据表中字段类型为整型的某一列作为切分键,推荐使用主键或有索引的列作为切分键。读取数据时,根据配置的切分键字段进行数据分片,实现并发读取,可以提升数据同步效率。
批量读取条数
一次性读取数据的条数。在从源数据库读取数据时,可以配置一个特定的批量读取条数(如1024条记录),而不是一条一条地读取,以减少与数据源之间的交互次数,提高I/O效率,并降低网络延迟。
输入过滤
配置抽取数据的筛选条件,配置说明如下:
配置固定值,抽取对应的数据,例如
ds=20210101。配置变量参数,抽取某一部分数据,例如
ds=${bizdate}。
输出字段
输出字段区域展示了已选中表及筛选条件命中的所有字段。支持进行以下操作:
字段管理:如果不需要将某些字段输出至下游组件,则您可以删除对应的字段:
单个删除字段场景:如果需要删除少量的字段,则可以单击操作列下的
 图标,删除多余的字段。
图标,删除多余的字段。批量删除字段场景:如果需要删除大批量字段,则可以单击字段管理,在字段管理对话框选择多个字段后,单击
 左移动图标,将已选的输入字段移入到未选的输入字段并单击确定,完成字段的批量删除。
左移动图标,将已选的输入字段移入到未选的输入字段并单击确定,完成字段的批量删除。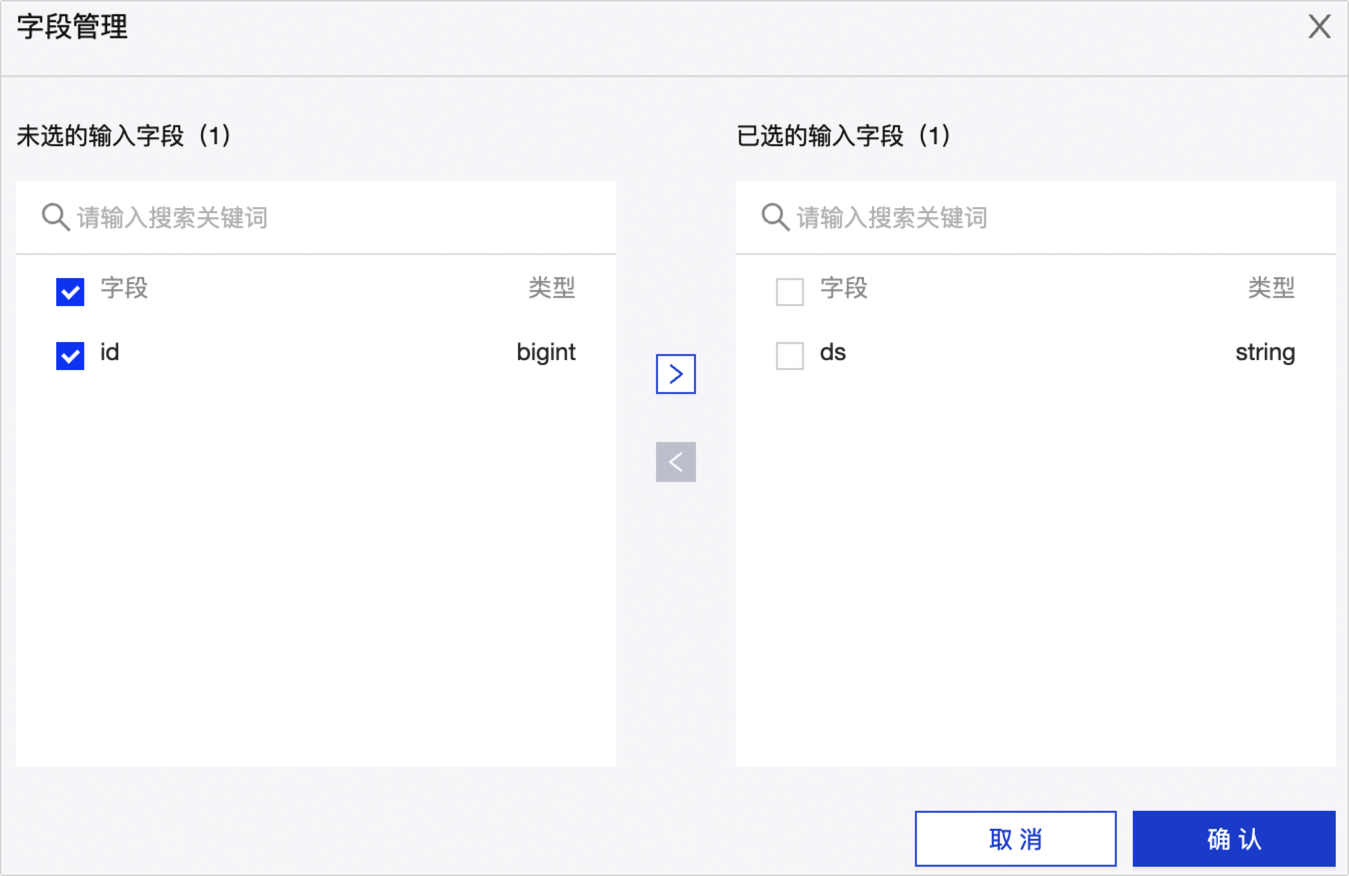
批量添加:单击批量添加,支持JSON、TEXT格式、DDL格式批量配置。
说明批量添加完成,单击确定后会覆盖已配置的字段信息。
以JSON格式批量配置,例如:
// 示例: [{ "index": 1, "name": "id", "type": "int(10)", "mapType": "Long", "comment": "comment1" }, { "index": 2, "name": "user_name", "type": "varchar(255)", "mapType": "String", "comment": "comment2" }]说明index表示指定对象的列编号,name表示引入后的字段名称,type表示引入后的字段类型。 例如,
"index":3,"name":"user_id","type":"String"表示把文件中的第4列引入,字段名为user_id,字段类型为String。以TEXT格式批量配置,例如:
// 示例: 1,id,int(10),Long,comment1 2,user_name,varchar(255),Long,comment2行分隔符用于分隔每个字段的信息,默认为换行符(\n),可支持换行符(\n)、半角分号(;)、半角句号(.)。
列分隔符用于分隔字段名与字段类型,默认半角逗号(,),可支持
','字段类型可缺省,默认为','。
以DDL格式批量配置,例如:
CREATE TABLE tablename ( user_id serial, username VARCHAR(50), password VARCHAR(50), email VARCHAR (255), created_on TIMESTAMP, );
新建输出字段:单击+新建输出字段,根据页面提示填写字段、类型、备注并选择映射类型。当前行完成配置后,单击
 图标保存。
图标保存。
单击确认,完成Greenplum输入组件的属性配置。
 图标保存。
图标保存。