
本文为您介绍资源调度的相关问题。
1、调度资源大盘无数据展示或展示时间未更新
需检查是否已安装Prometheus组件以及Prometheus是否连接正常。
若未安装Prometheus组件,请联系Dataphin部署团队。若已安装Prometheus组件,但显示的时间仍为旧时间段,这可能与Prometheus的连接异常有关。您可联系Dataphin运维团队进行排查或通过以下方法判断Prometheus是否连接异常:
登录Dataphin集群。
使用
kubectl get pods -n dataphin | grep rs语句查找rs Pod。使用
kubectl describe pod <pod名称> -n dataphin语句查找rs 主Pod。查看labels字段
dataphin-rs-scheduler-rpc-service状态是否为active。若状态为active则为主Pod,若状态为standby则为从Pod。使用
kubectl exec -it <pod名称> -n dataphin -- bash语句登录rs主Pod。使用
cd/home/admin/logs/dataphin-rs语句进入rs日志目录。查看日志信息中,是否有涉及Prometheus连接异常的信息,可使用
grep "failed to connect to" <日志文件>语句搜索。若包含Prometheus的信息,则为连接异常。
2、任务成功执行后被再次执行
需检查该任务是否存在上游依赖。若存在上游依赖,上游任务重跑后,将会触发下游任务重跑。
3、未展示资源设置页面
导入License后,才可查看管理中心 > 系统设置 > 资源设置页面。
4、运行任务时提示资源等待
需依次确认以下情况:
当前资源组是否有大量任务在运行。
是否存在许多运行时间较长的大型任务,这些任务持续运行将持续占用资源组的资源。
当前资源组的设置是否合理。可前往管理中心 > 系统设置 > 资源设置,配置资源组。
当前租户资源的配置是否合理。当前租户的资源值发生变化时,将联动该租户的资源组进行相应调整。
例如,当运行日志的最后提示内容类似于Sending to agent e405****-****-****-****-****2fc2时,表明任务已经成功下发至调度集群。但在调度集群创建任务Pod时可能出现了问题,具体可能的原因如下:
调度集群的剩余资源不足,无法创建新的任务Pod。
调度集群可能会出现故障,其中常见的问题包括网络插件异常和时钟异常。
4.1、租户资源不足时的建议
终止资源组中占用资源优先级较低的任务,释放资源。
提高对应租户资源组的分配比例。
错峰调度,避免在高峰期任务争夺资源。
根据资源使用率优化任务的资源配置(可在资源大盘中查看任务资源使用率)。
4.2、集群资源不足时的建议
终止资源组中占用资源优先级较低的任务,释放资源。
错峰调度,避免在高峰期任务争夺资源。
根据资源使用率优化任务的资源配置(可在资源大盘中查看任务资源使用率)。
集群资源扩容。
5、运行共享任务时提示资源等待,但实际资源充足。
如果资源充足,但出现资源等待的情况,可能是由于共享任务的并发数限制所致。若超过设置的共享任务并发数量,任务将会被阻塞并进入等待状态。
不同的共享类型任务,限制的并发数不同。
SQL类型默认值:默认创建⼀个共享容器Pod, ⼀个共享容器Pod可同时运⾏200个任务。
Python、Shell类型默认值:默认创建⼀个共享容器Pod,⼀个共享容器Pod可同时运⾏15个任务。
您可根据实际需求,改动共享容器Pod数和⼀个共享容器Pod同时运⾏任务数。

6、运行诊断中展示的占用资源实例是当前资源下的还是当前租户下的?
运行诊断中占用资源实例为当前租户下的实例。
7、已设置失败自动重跑次数,但任务运行超时后并未触发自动重跑。
任务运⾏超时默认不会触发任务失败⾃动重跑,任务超时失败⾃动重跑需要在运维 > 全局配置 > 运⾏配置 > 重跑配置中开启对应开关。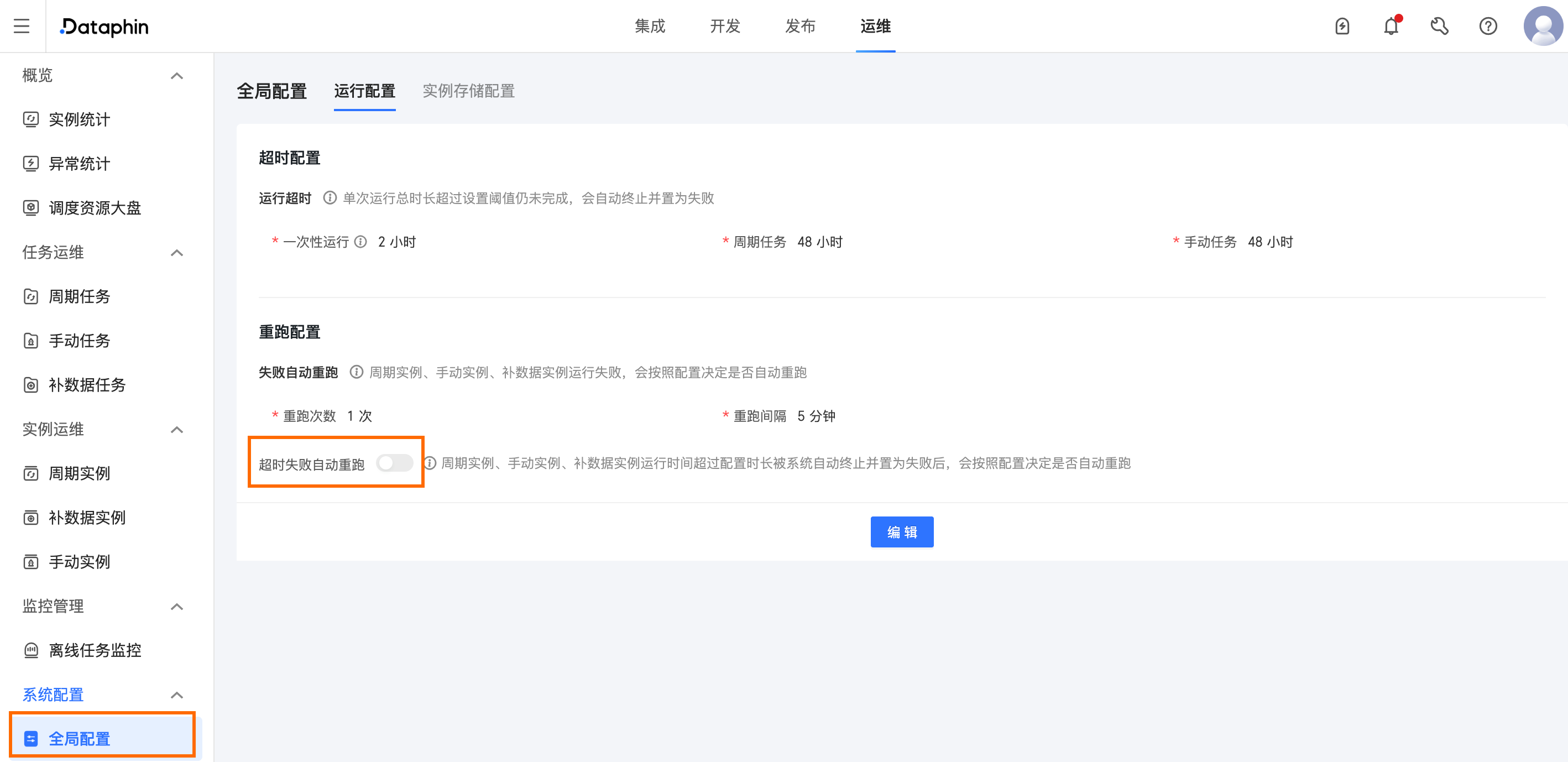
8、离线任务运行资源说明
离线任务运行资源详细说明请参见任务运行资源说明。
例如,Python共享任务类型,启动20个Pod,每个Pod处理50个任务,所需消耗的资源应按照以下方式计算。
一个Pod消耗的资源由基座资源和任务资源两部分组成。其中,基座资源为0.5核和4096MB(4G);Python任务资源默认为0.1核和256MB。由此,一个Pod所需的总资源为0.6核和4352MB。若部署20个Pod,则所需资源为20 * 0.6核 = 12核,20 * 4352MB = 87040MB(85G)。
9、运维⻚⾯查询实例列表信息时,提示503 Service Temporarily Unavailable。
建议您优先排查是否被WAF(WAF是⼀种⽹络安全⼯具,⽤于检测和阻⽌恶意流量、SQL注⼊、XSS攻击等)拦截。
10、运行日志部分内容的时间戳顺序存在乱序现象
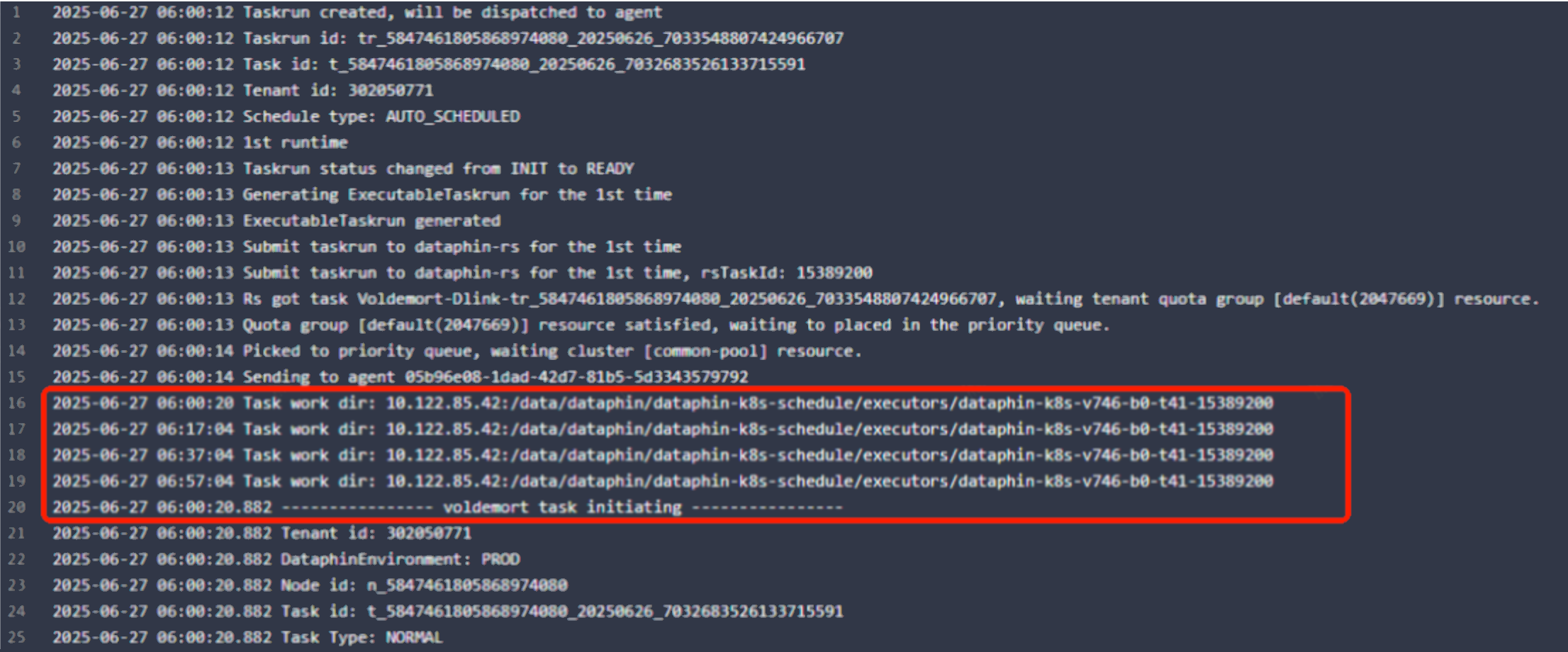
此处并非乱序,任务运行日志是由三阶段日志拼接而成的。其中,中间部分为服务端定期询问的日志,三阶段的日志不会整体按照时间进行排序。
11、需要调⽤OpenAPI的触发式节点,且使用Python开发,是否有对应的Python调⽤⽂档?
目前仅部分接口(包含公共云已上线以及运维相关的接口)支持使用Python开发。
相关文档:
触发式节点介绍:Dataphin v4.0,跨系统调度依赖再也不是难题
触发式节点开发说明:触发式节点开发说明
12、在代码中指定的资源注解已被注释,但在建议优化任务中仍然被纳入统计。
被注释的资源也会生效,彻底删除资源后才不会被纳入统计。
13、从低版本升级到高版本后,之前能够正常运行的OpenAPI接口运行报错,提示tenantId不能为空。
若从低于Dataphin V3.0版本进⾏升级,则会提示该错误。从Dataphin V3.x版本开始,tenantId为必填。
14、任务调度配置已设置为正常调度,但在运维的周期任务页面中显示为暂停状态。
检查该任务所属项目的周期性调度是否选择为已关闭,任务暂停调度,可改为选择开启,任务自动调度。