
场景
在缺乏数据的初期阶段,如何快速建立一个实时任务,跑通实时研发的整条链路?
在测试功能时,如何快速跑通测试全链路?
初次使用实时研发,不同的实时数据源选择connector的时候不知道要怎么选择;成功创建元表,但是任务编译的时候报错参数不全,应怎么处理?
解决方案
Dataphin在实时研发模块提供了引用示例代码功能,引用示例代码可自动生成代码,不仅能够让初次使用实时研发的用户迅速上手,快速走通实时研发的整条链路,而且可以减少学习数据源connector的成本。同时,引用示例代码将自动生成必填参数,可直接编译并运行,避免因缺少参数而编译报错的情况,极大地提升了开发效率。以下简单介绍模拟数据输入输出、Kafka实时数据处理、CDC实时数据同步入湖/入仓示例。
模拟数据输入输出
可以利用datagen connector模拟输入、print connector模拟输出,构造一个最简单的实时任务,走通实时研发的整条链路。
datagen connector:在缺乏实时数据的初期测试阶段,可以使用datagen connector生成模拟数据流,为Flink SQL任务提供稳定的测试数据,以便在无真实数据的情况下进行功能测试和性能调优。
print connector:在开发过程中,可以插入print connector输出中间结果至控制台或日志,用于即时验证数据处理逻辑的正确性,快速迭代优化SQL语句。
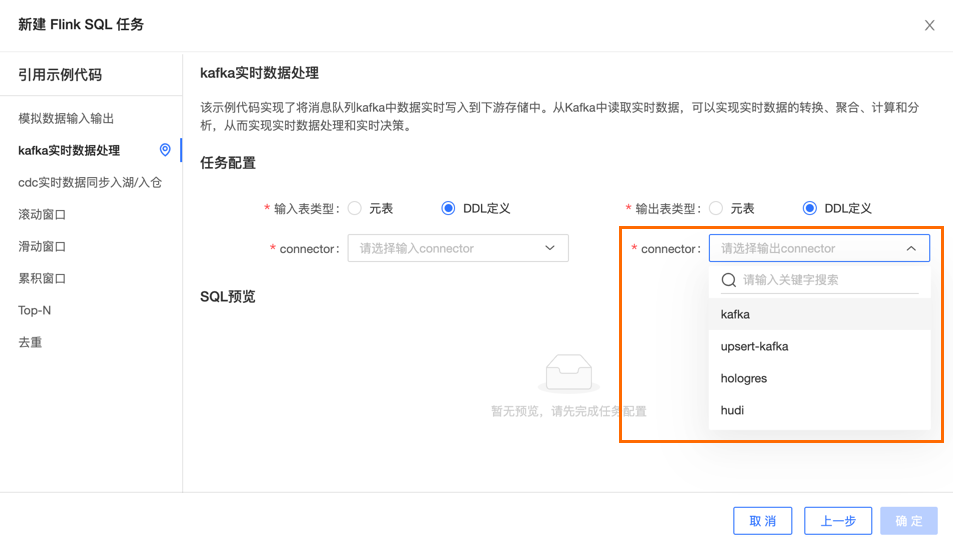
Kafka实时数据处理
在示例中,输入connector仅支持选择Kafka,但是输出connector可以选择Kafka、upsert Kafka、Hologres或Hudi,这能够有效帮助初次使用者解决因选择错误connector而导致的任务报错问题。
CDC实时数据同步入湖/入仓
通过示例代码,初次使用者可以直接选择相应数据源的connector,而无需在DDL中自行编写,从而降低了学习数据源connector的成本;同时,借助示例代码,Dataphin会自动生成对应任务的必填参数,避免因参数缺失导致的编辑错误。