
前提条件
仅Apache Flink实时计算引擎支持使用Session集群调试SQL。
使用限制
Session集群最多支持采集1000条数据。
场景描述
在运行实时研发任务前,往往需要进行调试来验证任务的正确性,目前本地调试支持自动采样的数据源有限,不支持自动采样的数据源需要手动上传数据,流程繁琐且调试效率低,可通过Session集群进行调试,流式读取数据(即一边从来源表中读取数据,一边进行计算,与真实线上运行任务的结果一致,只是不会将结果写入到结果表中,而是写入到Dataphin自建的connector中,既方便调试人员查看和分析数据,又不会干扰线上生产环境的数据)。
解决方案及功能
创建自定义资源组,用于Session集群的实时任务调试,该资源组的CPU和内存资源,不少于3C12G,创建详情请参见新建自定义资源组。
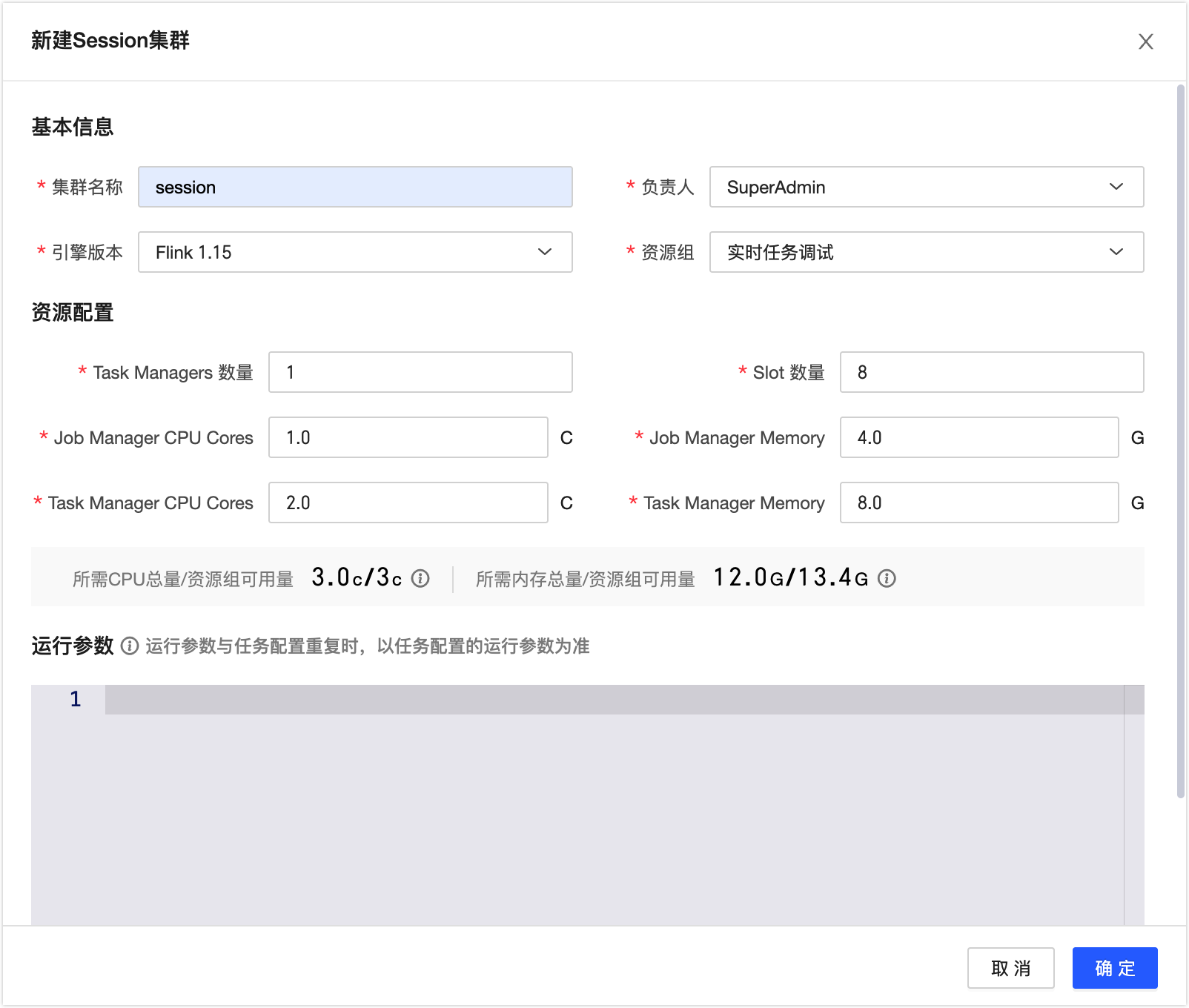
在管理中心 > 系统设置 > 资源设置的Session集群页签创建Session集群,配置Session集群的Task Managers数量、Slot数量,Job Manager CPU Cores、Job Manager Memory、Task Manager CPU Cores、Task Manager Memory等信息,如下图所示。
说明若自定义资源组时配置的调度资源过少,则Task Managers数量以及Job Manager和Task Manager可分配的CPU和内存资源都比较少,可能会导致性能瓶颈,特别是在处理高负载作业时,如果一个作业占用了大量的Task Manager资源,其他作业可能会受到影响,甚至可能出现作业执行缓慢或者失败的情况。
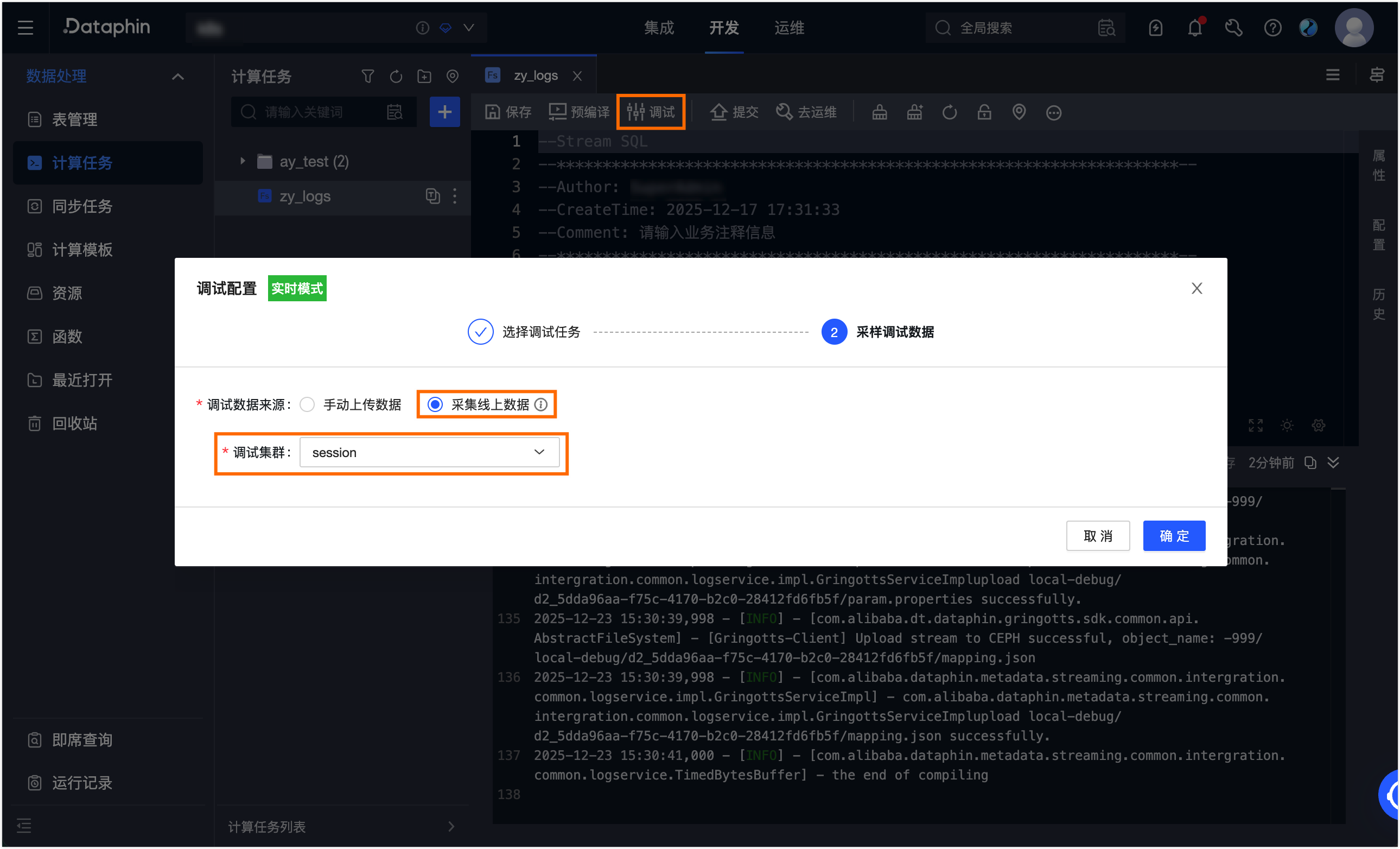
在研发 > 数据研发 > 计算任务页面创建Flink SQL任务,单击顶部菜单栏的调试,选择采集线上数据,并选择Session集群进行调试。
该文章对您有帮助吗?