
前提条件
需购买数据安全功能和X-数据安全功能才能使用X-数据安全。
已配置并开启X-数据安全,详情请参见智能应用。
场景描述
某金融公司管理着大量用户信息数据,如客户的姓名、手机号、身份证号、账户信息等。这些数据不仅是企业的核心资产,也是《数据安全法》和《个人信息保护法》等法规重点保护的对象。
公司需对所有数据表的用户信息字段进行分类分级(如分类为用户基础信息、分级为敏感等级L1-L4),以满足合规要求并防止敏感数据泄露。表数量庞大且字段复杂,传统的人工处理容易遗漏或出错,导致治理效率低且风险高。
解决方案与功能
X-数据安全智能应用新增支持了智能安全分类分级识别,借助大模型对数据表字段进行语义解析,结合DDL元数据、字段描述,智能推荐字段的安全分类与分级,精准高效,降低人工成本,提升治理效率。
在Dataphin首页的顶部菜单栏,选择超级X > X-数据安全,进入X-数据安全页面,单击添加治理数据按钮。
在添加数据来源面板中,选中需要分类分级扫描的资产,单击数据范围下的编辑图标。
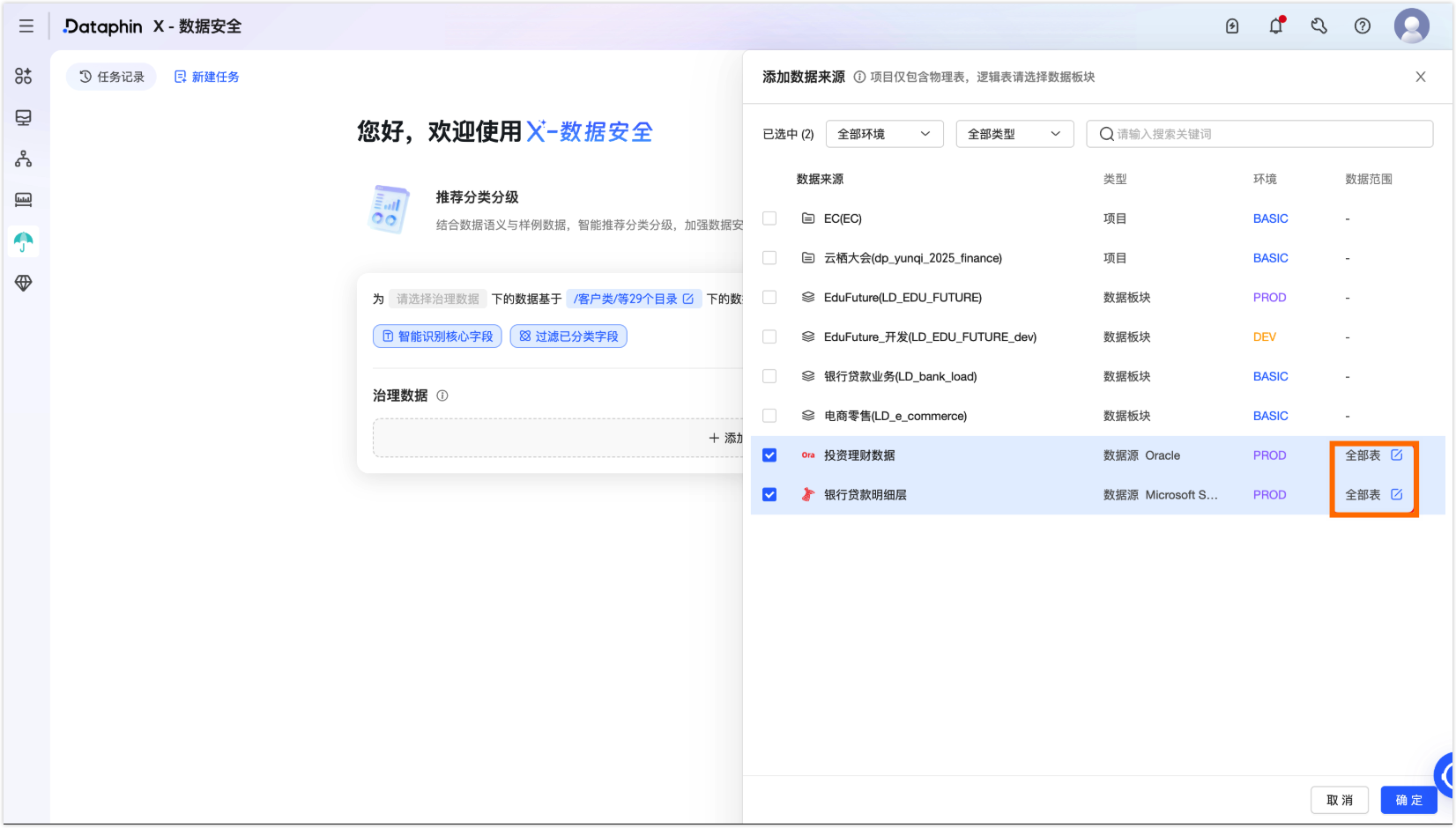
根据表名、资产标签等规则,圈选指定项目或板块中的表作为数据来源。
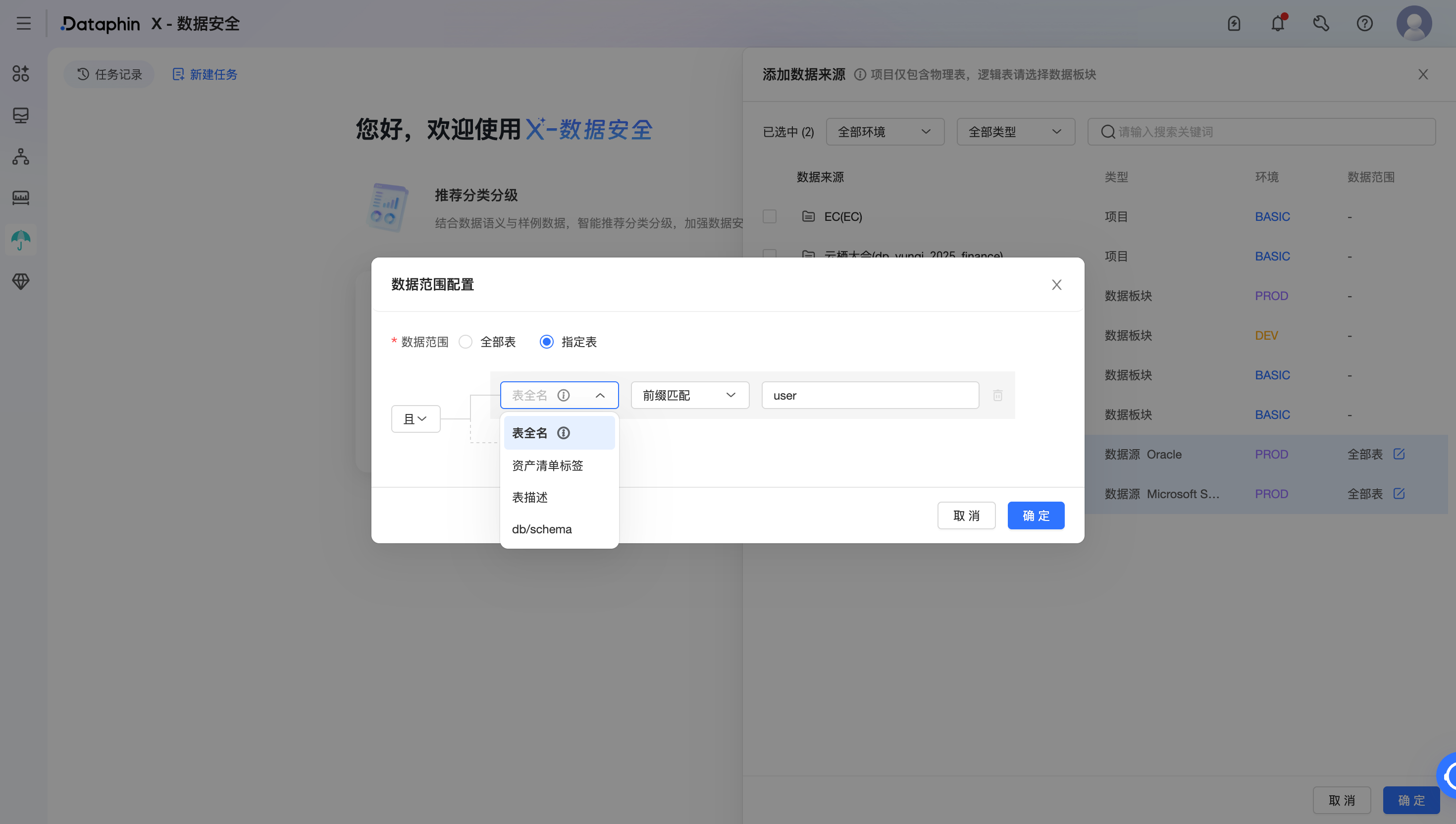
完成数据来源范围的配置后,选择基于用户相关分类的规则,单击
 图标,发起数据分类分级任务。
图标,发起数据分类分级任务。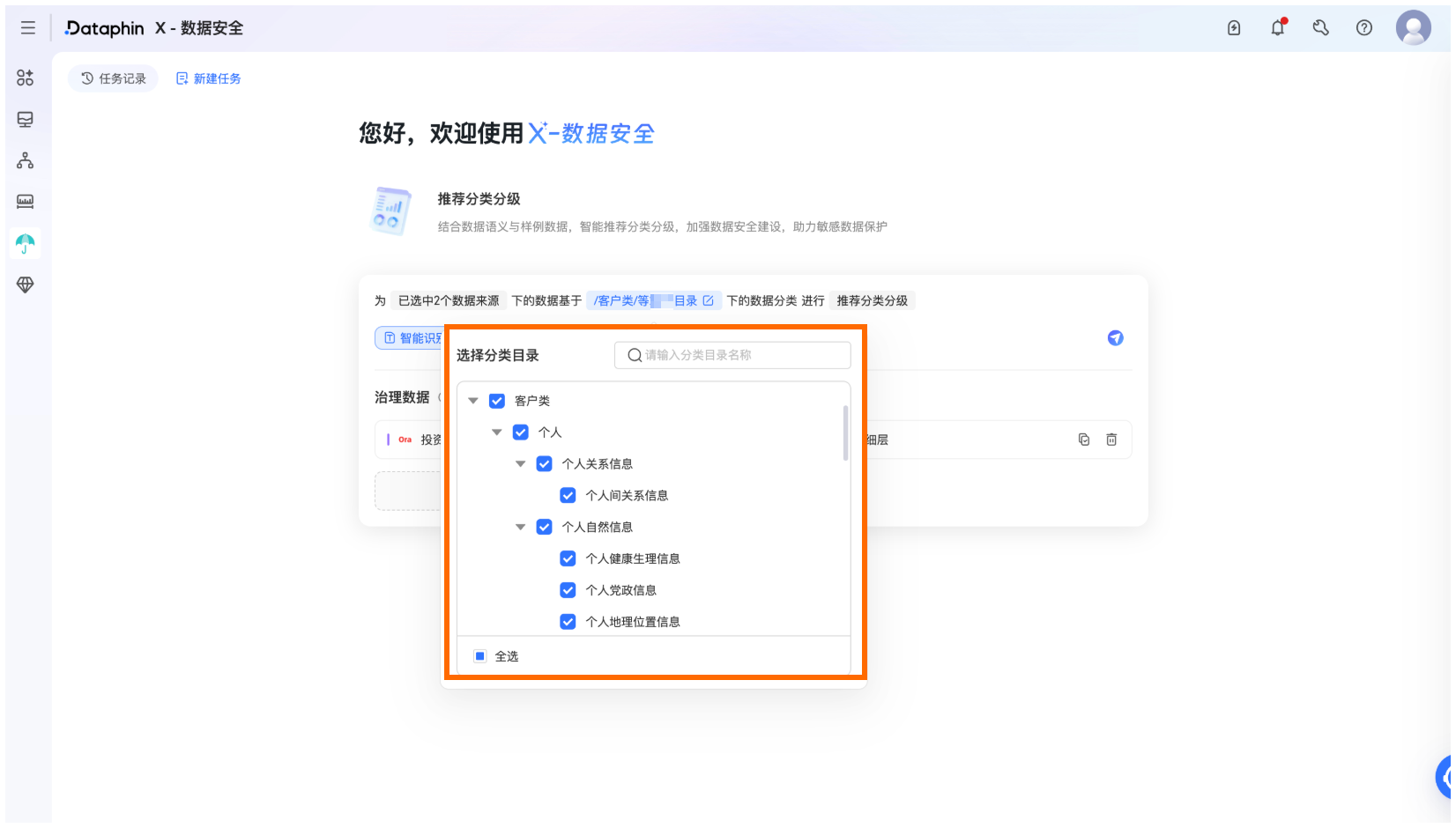
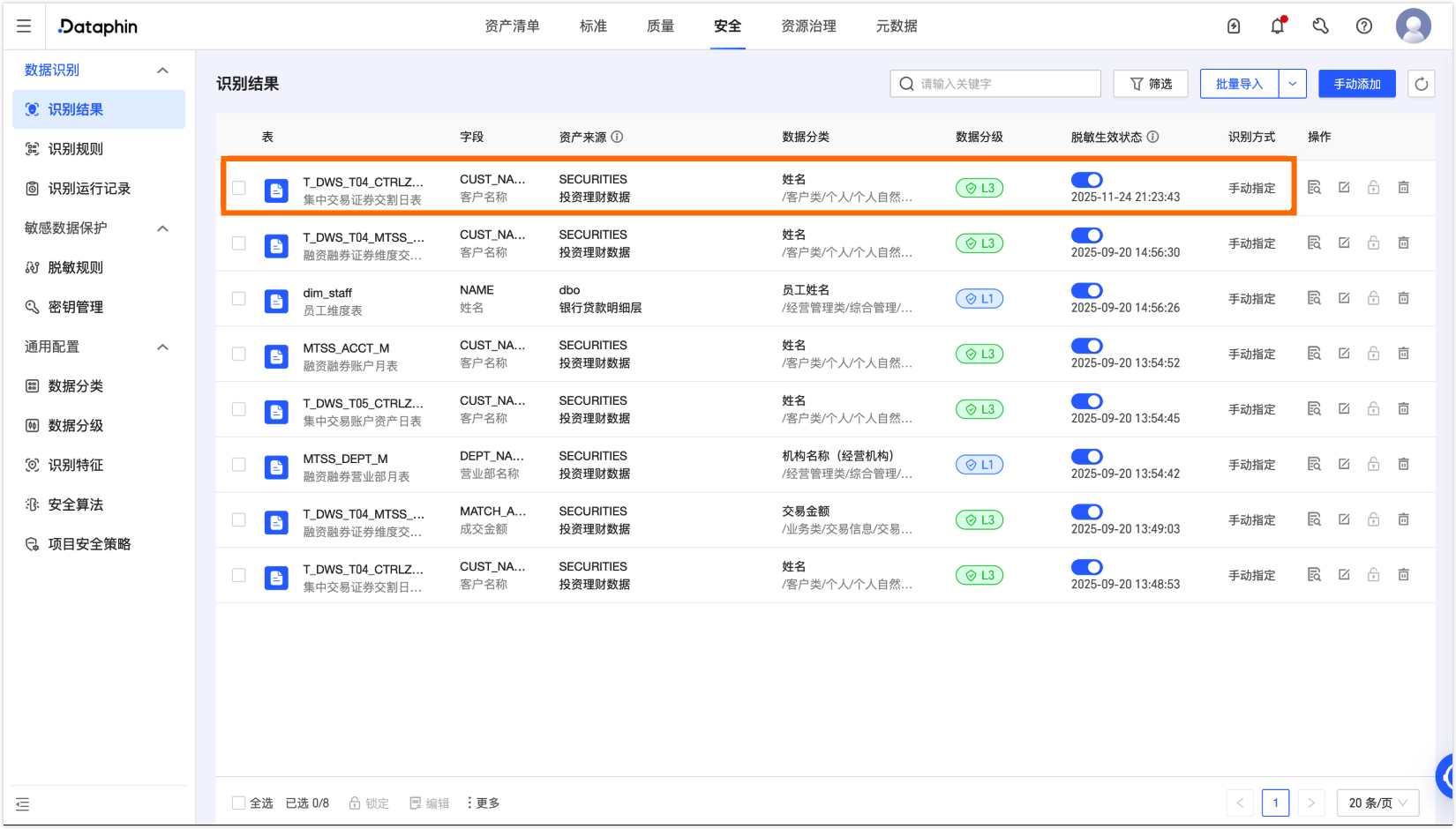
任务完成后,系统将生成分类分级推荐识别结果,可对每条识别结果进行审核。根据大模型的匹配度以及实际字段与分类的关联情况,选择应用或弃用推荐识别结果。
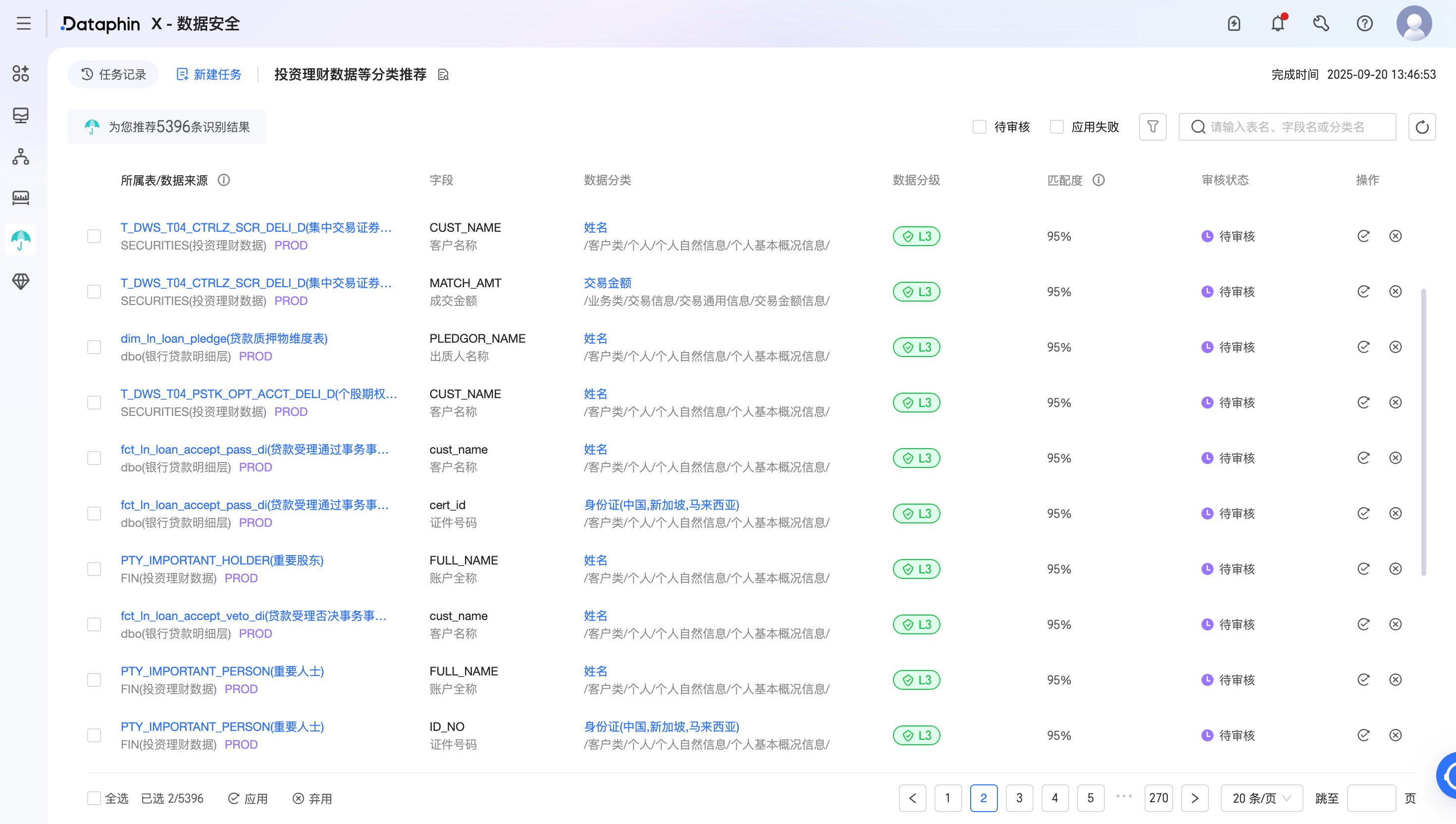
成功应用识别结果后,可在治理 > 数据安全 > 识别结果页面查看生效后的数据资产分类分级情况。

该文章对您有帮助吗?