
本文为您介绍基于开源Flink实时引擎如何创建Flink SQL任务。
前提条件
在开始执行操作前,请确认项目已开启实时引擎并已配置Flink为计算源。具体操作,请参见创建通用项目。
权限说明
仅支持超级管理员、项目管理员和开发者创建Flink SQL计算任务。
步骤一:新建Flink SQL任务
在Dataphin首页的顶部菜单栏中,选择研发 > 数据研发。
在顶部菜单栏中选择项目(Dev-Prod模式还需选择环境)。
在左侧导航栏中选择数据处理 > 计算任务,在右侧计算任务列表中单击
 图标,选择Flink SQL。
图标,选择Flink SQL。在新建Flink SQL任务对话框,配置任务参数。
参数
说明
任务名称
名称的命名规则如下:
只能包含小写英文字母、数字、下划线(_)。
名称的长度范围为4~63个字符。
项目内的名称不支持重复。
名称仅支持以英文字母开头。
生产环境资源队列/开发环境资源队列
项目绑定的Flink计算源的部署模式为Kubernetes时,支持选择所有配置为实时任务的资源组(包括外部注册集群中的资源组)。
项目绑定的Flink计算源的部署模式为yarn时,下拉列表中包含当前项目所绑定Flink计算源管理的全部资源队列以及Session集群。
说明若您的项目空间为Basic模式,则仅支持配置生产环境资源队列。
生产环境引擎版本/开发环境引擎版本
选择任务运行的Flink引擎版本。Dataphin支持的引擎版本如下:
1.20.1
1.15.3
1.14.2
1.13.1
说明当生产/开发环境资源队列选择Session集群时,仅可选择1.20.1版本。
若您的项目空间为Basic模式,则仅支持配置引擎版本。
存储目录
选择任务所存放的目录。
若未创建目录,您可以新建文件夹,操作方法如下:
在页面左侧计算任务列表上方单击
 图标,打开新建文件夹对话框。
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称并根据需要选择目录位置。
单击确定。
新建方式
支持空白新建、引用示例代码和使用模板。
空白新建:创建普通空白的Flink SQL任务。
引用示例代码:引用系统内置的示例代码快速新建任务。
使用模板:基于实时计算任务模板快速新建任务。
描述
填写对Flink SQL任务的简单描述,1000字符以内。
单击确定。
步骤二:开发及预编译Flink SQL任务代码
在Flink SQL任务代码页面,编写任务的代码。
Dataphin支持原生DDL语句快速创建元表。当前Dataphin识别到原生
create table/create temporary table语句时,您可以单击编辑器 提示图标,快速创建元表。具体操作,请参见Flink SQL任务开发方式。
提示图标,快速创建元表。具体操作,请参见Flink SQL任务开发方式。代码编写完成后,可单击当前计算任务顶部菜单栏中的格式化按钮,使系统自动调整SQL代码格式。
单击顶部菜单栏中的预编译,校验代码任务的语法及权限问题。
若预编译成功,系统将提示预编译成功;若预编译失败,系统将提示预编译失败,可单击页面底部的Console,查看预编译失败日志。
步骤三:配置Flink任务
单击编辑器侧边栏配置。
在配置对话框中,配置Flink任务实时模式和离线模式的相关配置信息。
说明Dataphin实时计算支持流批一体任务,使用统一的流批计算引擎,在一份代码上可同时配置流+批的任务配置,基于同一份代码生成不同模式下的实例。开启批处理需在任务配置页面开启离线模式并进行资源、调度依赖等相关配置。
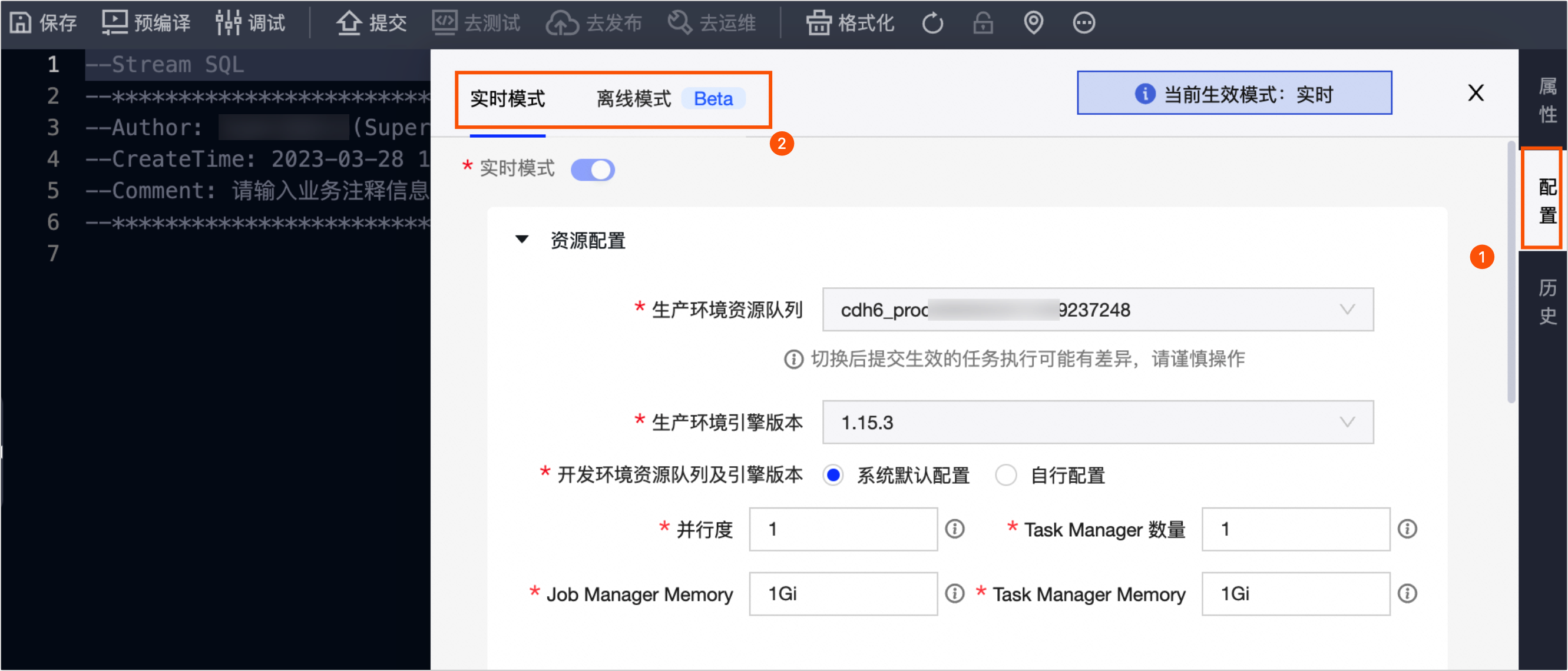
实时模式
资源配置(必选):配置任务生产环境和开发环境对应的资源队列、引擎版本以及任务的并行度、Task Manager 数量、Job Manager Memory和Task Manager Memory信息。配置说明,请参见配置Ververica Flink实时模式资源。
变量配置:变量参数配置是对计算任务代码中所用的变量进行赋值,从而支持变量参数可以自动被替换为相应的变量值。配置说明,请参见实时模式变量配置。
Checkpoint配置:配置Flink SQL任务的Checkpoint,可有效的帮助当前Flink SQL任务运行意外崩溃后,重新运行程序时恢复到崩溃前的状态。配置说明,请参见实时模式Checkpoint配置。
State配置:配置State中数据自动清理的周期。配置说明,请参见实时模式State配置。
运行参数:可以通过配置运行参数,控制Flink应用程序的执行行为和性能。配置说明,请参见实时模式运行参数配置。
依赖文件:配置任务依赖的资源文件。配置说明,请参见实时模式依赖文件配置。
依赖关系:配置依赖关系可帮助排查调试时快速了解数据的上下游任务。配置说明,请参见实时模式依赖关系配置。
离线模式(Beta)
重要项目绑定的实时计算源为开源Flink且部署模式为k8s(Kubernetes)不支持离线模式。
资源配置(必选):配置任务生产环境和开发环境对应的资源队列、引擎版本以及任务的并行度、Task Manager数量、Job Manager Memory、Task Manager Memory信息。配置说明,请参见配置开源Flink离线模式资源。
变量配置:变量参数配置是对计算任务代码中所用的变量进行赋值,从而支持变量参数可以自动被替换为相应的变量值。配置说明,请参见离线模式变量配置。
运行参数:可以通过配置运行参数,控制Flink应用程序的执行行为和性能。配置说明,请参见离线模式运行参数配置。
依赖文件:配置Flink SQL任务依赖的资源文件。配置说明,请参见离线模式依赖文件配置。
调度配置(必选):调度配置用于定义节点在生产环境的周期调度方式。您可以通过调度配置中调度属性,配置任务调度周期与生效日期等。配置说明,请参见离线模式调度配置。
依赖关系(必选):配置依赖关系可帮助排查调试时快速了解数据的上下游任务。配置说明,请参见离线模式依赖关系配置。
单击确定。
步骤四:调试Flink任务代码
Dataphin支持调试已开发的Flink代码。单击顶部菜单栏的调试按钮,可以对代码任务采样数据并进行本地调试,确保代码的正确性。
在调试配置对话框中选择实时模式-FLINK Stream任务(实时模式调试)或离线模式-FLINK Batch任务(离线模式调试)。
当前仅支持单种模式调试,选择模式后请采样对应模式表数据进行调试。
步骤五:提交Flink SQL任务
单击顶部菜单栏的提交按钮。
在提交对话框中查看提交内容和前置检查信息,并填写提交备注。
单击确定并提交。
如果项目的模式为Dev-Prod,则您需要发布Flink SQL任务至生产环境。具体操作,请参见管理发布任务。
后续步骤
提交成功后,您可在运维中心查看并运维Flink SQL任务,保证任务的正常运行。更多信息,参见查看并管理实时任务。