
数据血缘是展示端(first mile ETL)到端(last mile BI)的血缘关系,明确追踪数据从产生、加工、融合、消费到最终消亡的整个生命周期,记录数据在生命周期内的来源、移动、转换及其依赖关系。本教程通过自动解析、手动配置和接口注册三种场景,帮助您了解数据血缘,并将数据血缘运用到数据开发流程,提升数据价值。
数据血缘价值
问题定位:当数据异常时,可通过血缘溯源问题源头数据,进行问题定位。
影响分析:上游表结构变更、数据修改,可快速评估对下游任务的影响。
数据治理:可通过资产清单查看数据加工链路是否清晰、合规,提升元数据质量,明确数据表负责人。
成本优化:识别长期未被使用的数据表,对其进行下线,节约存储与计算成本。
前提条件
需购买智能研发版才能使用规范规模。
需购买OpenAPI功能才能通过OpenAPI注册血缘。
数据准备
需创建一个zmx_devprod项目,用于离线集成任务、计算任务、逻辑表任务开发。
需创建一个LD_dev_prod_yy数据板块,详情请参见创建数据板块。
需创建一个主题域,详情请参见创建主题域。
需创建一个yy_shiti01实体,详情请参见创建及管理业务实体。
需创建一个mysql567数据源。
在MySQL数据源中创建一个dataphin05的数据库和wp_mysql_tab01、wp_mysql_tab02两张数据表,这两张表的表结构一致。
create table `wp_masql_tab01` ( `user_id` varchar(256) comment '用户ID', `name` varchar(256) comment '姓名', `gender` bigint comment '性别', `age` bigint comment '年龄', `phone_num` varchar(256) comment '手机号码' ) comment 'wp_masql_tab01'
血缘说明
系统在任务提交时,自动解析开发环境的表和字段血缘关系;发布时,自动解析生产环境的表和字段血缘关系。特别地,Basic项目下的任务提交即发布。单个任务提交或发布时支持解析不超过10万条血缘关系,超过则不予记录,在资产清单中无法展示。
删除任务将同步删除物理表关联的血缘关系,若仅删除物理表,未删除血缘关系关联的任务,则血缘关系仍然存在,在血缘图中对应表节点展示为未采集或已删除。
通过OpenAPI注册的血缘,系统调用成功后,血缘关系即刻生效。
自动解析数据血缘
适用场景:适用于集成同步任务、标准化SQL任务(如:MaxCompute_SQL任务、Hive_SQL任务)及逻辑表任务。
优势:零成本、自动化、准实时。数据开发者只需要按规范开发,血缘自动生成。
数据集成数据血缘
通过离线管道创建离线集成任务同步数据,系统自动建立源数据源与目标表之间的表级血缘和字段级血缘。
在Dataphin首页的顶部菜单栏中,选择研发 > 数据集成。
在顶部菜单栏中选择项目zmx_devprod。
在左侧导航栏中选择集成 > 离线集成。在右侧离线集成列表中单击
 图标,选择离线管道。
图标,选择离线管道。在创建离线管道对话框中,配置参数。
参数
描述
管道名称
输入数据血缘。
调度类型
选择手动节点。
描述(非必填)
可以填写对离线单条管道的简单描述,不超过1000个字符。
选择目录(非必选)
默认目录为离线管道。
单击确定,完成创建离线管道。
在离线单条管道开发页面,单击组件库。
在输入组件中选择MySQL输入组件,并将其拖动至管道画布中。
在输出组件中选择MaxCompute输出组件,并将其拖动至管道画布中。
连接MySQL输入组件和MaxCompute输出组件.
分别单击输入和输出组件的
 图标,配置MySQL输入组件和MaxCompute输出组件,参数配置详情请参见配置MySQL输入组件、配置MaxCompute输出组件。
图标,配置MySQL输入组件和MaxCompute输出组件,参数配置详情请参见配置MySQL输入组件、配置MaxCompute输出组件。MySQL输入组件
参数
描述
步骤名称
使用默认名称。
来源表量
选择单表。
数据源
选择mysql567。
表
选择来源表wp_mysql_tab01。
输出字段
使用默认输出字段。
MaxCompute输出组件
参数
描述
步骤名称
使用默认名称。
数据源
选择项目/zmx_devprod。
表
创建目标表:
单击一键建表。
在代码输入框中,使用默认建表语句,并删除分区。
单击新建。
加载策略
选择覆盖数据。
映射关系
在映射关系中选择同行映射。
单击确定,完成输入和输出组件的配置。
单击离线管道顶部菜单栏的保存、运行图标,保存并运行离线管道,然后再单击提交和发布图标,提交离线管道后,再进行发布。
发布成功后,可在治理 > 资产清单页面的搜索框选择Dataphin资产,单击目标表wp_masql_tab01,在对象详情页面即可查看当前表的表级和字段级血缘。
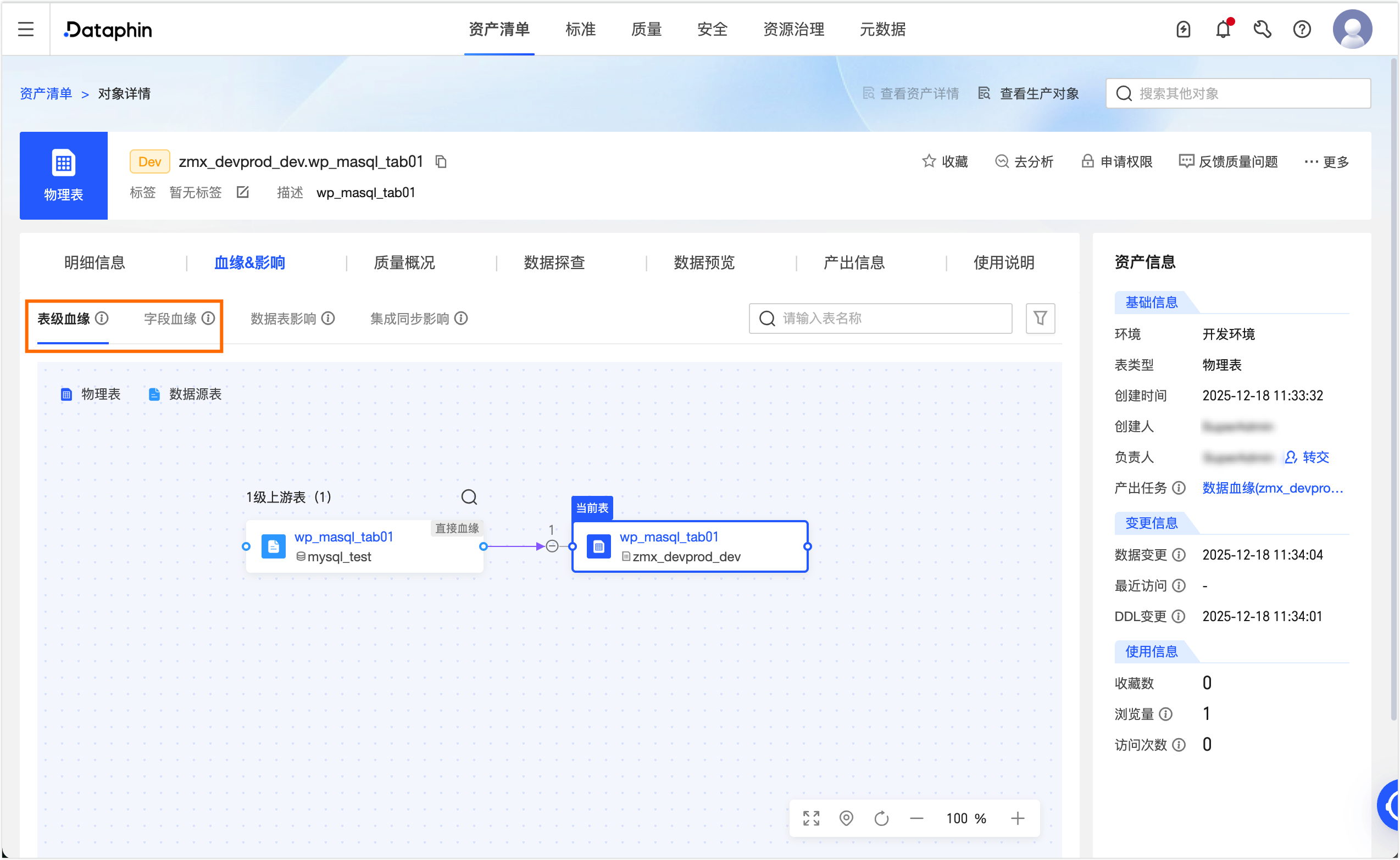
计算任务数据血缘
通过即席查询、SQL任务等编写DQL、DML,系统自动解析SQL语句中的SELECT...FROM...、INSERT...INTO...等逻辑,生成表与表、字段与字段、表与字段之间的血缘。
在Dataphin首页的顶部菜单栏中,选择研发 > 数据研发。
在顶部菜单栏中选择项目zmx_devprod。
在左侧导航栏中选择数据处理 > 计算任务。在右侧计算任务列表中单击
图标,选择数据库SQL。在新建数据库SQL任务对话框中,配置参数。
参数
描述
任务名称
输入数据血缘。
调度类型
选择手动任务。
选择目录
默认代码管理。
使用模板
关闭使用模板。
描述
填写对数据库SQL任务的简单描述,不超过1000个字符。
数据源类型
选择MySQL。
数据源
选择mysql567。
Database/Schema
选择dataphin05。
单击确定,在代码编辑区域,输入如下代码。
INSERT INTO wp_masql_tab02 SELECT * from wp_masql_tab01单击代码编辑区域顶部菜单栏的保存和运行图标,保存并运行数据库SQL,然后再单击提交和去发布,提交数据库SQL后,再进行发布。
发布成功后,可在治理 > 资产清单页面的搜索框选择其他系统资产,单击目标表wp_masql_tab02,在对象详情页面即可查看当前表的表级和字段级血缘。
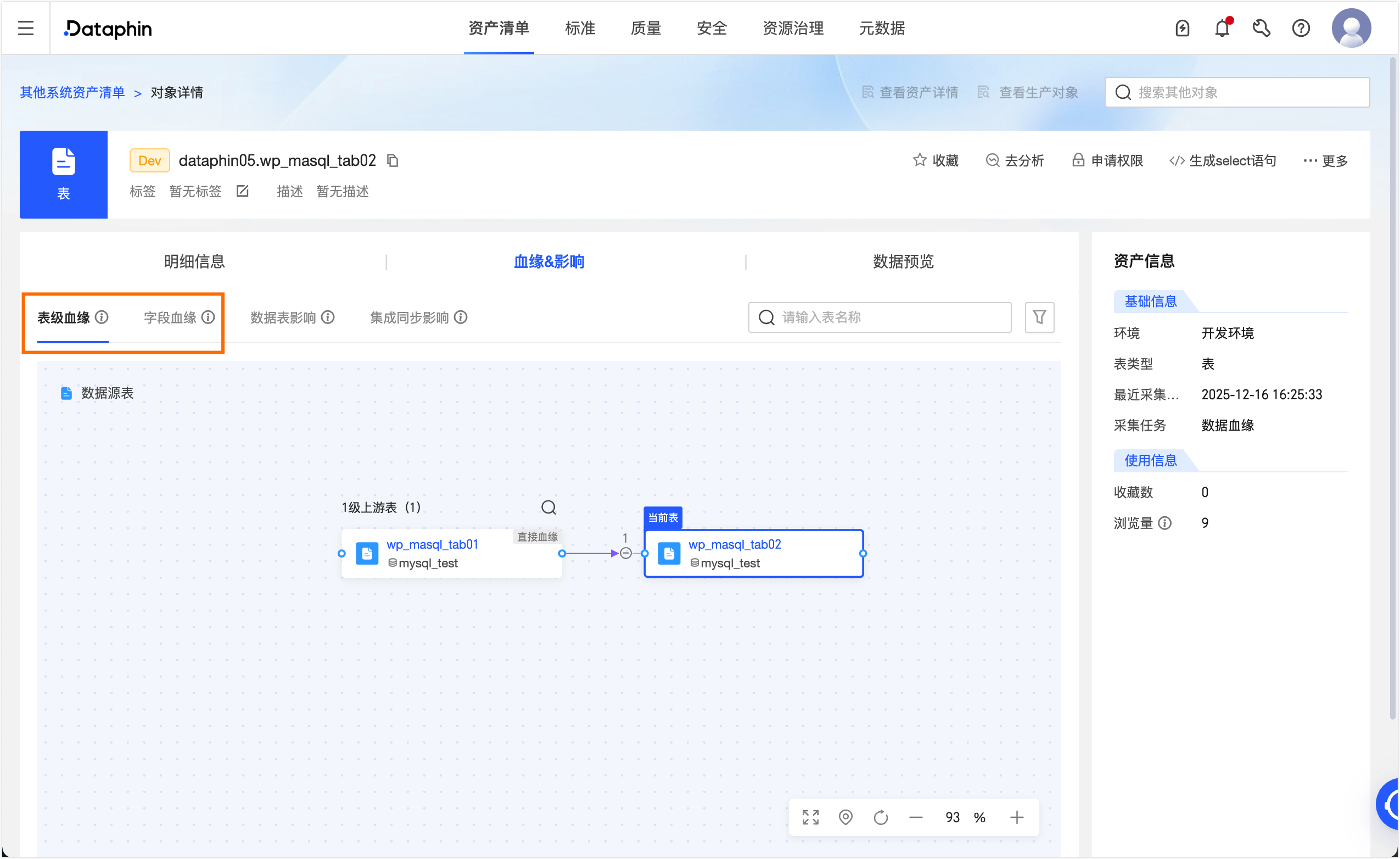
逻辑表任务数据血缘
通过数据开发创建逻辑表任务,系统自动建立上游任务与下游任务之间的血缘。
在Dataphin首页的顶部菜单栏中,选择研发 > 数据研发。
在顶部菜单栏中选择项目zmx_devprod。
在左侧导航栏中选择规范建模 > 维度逻辑表。在右侧维度逻辑表列表中单击
 图标,进入新建维度逻辑表对话框。
图标,进入新建维度逻辑表对话框。在新建维度逻辑表对话框中,配置参数,配置详情请参见新建普通维度逻辑表。
参数
描述
业务对象
选择普通对象/yy_shiti01。
数据时效
选择离线T+h。
逻辑表名
默认表名,无需修改。
中文名称
输入数据血缘。
描述信息
输入对维度逻辑表的简单描述,不超过1000个字符。
单击确定,进入逻辑表编辑导向页面,在表结构步骤中,选择主键yy_shiti01_id的数据类型为string后,单击底部的保存并下一步按钮。
在计算逻辑步骤中,单击页面右侧的来源配置按钮,在来源配置对话框中,配置参数。
参数
描述
来源类型
默认为物理表。
来源表名
选择
${zmx_devprod}.wp_masql_tab01。关联主键字段
选择user_id。
单击确定,再单击底部的保存并下一步按钮。
在调度&参数配置步骤的上游依赖区域,单击自动解析按钮,再单击节点(任务)名列下的点击补充,在点击补充对话框中,选择
virtual_root_node节点,单击保存并提交,再单击去发布。发布成功后,可在治理 > 资产清单页面的搜索框选择Dataphin资产,单击目标表dim_yy_shiti01_hf,在对象详情页面即可查看当前表的表级和字段级血缘。
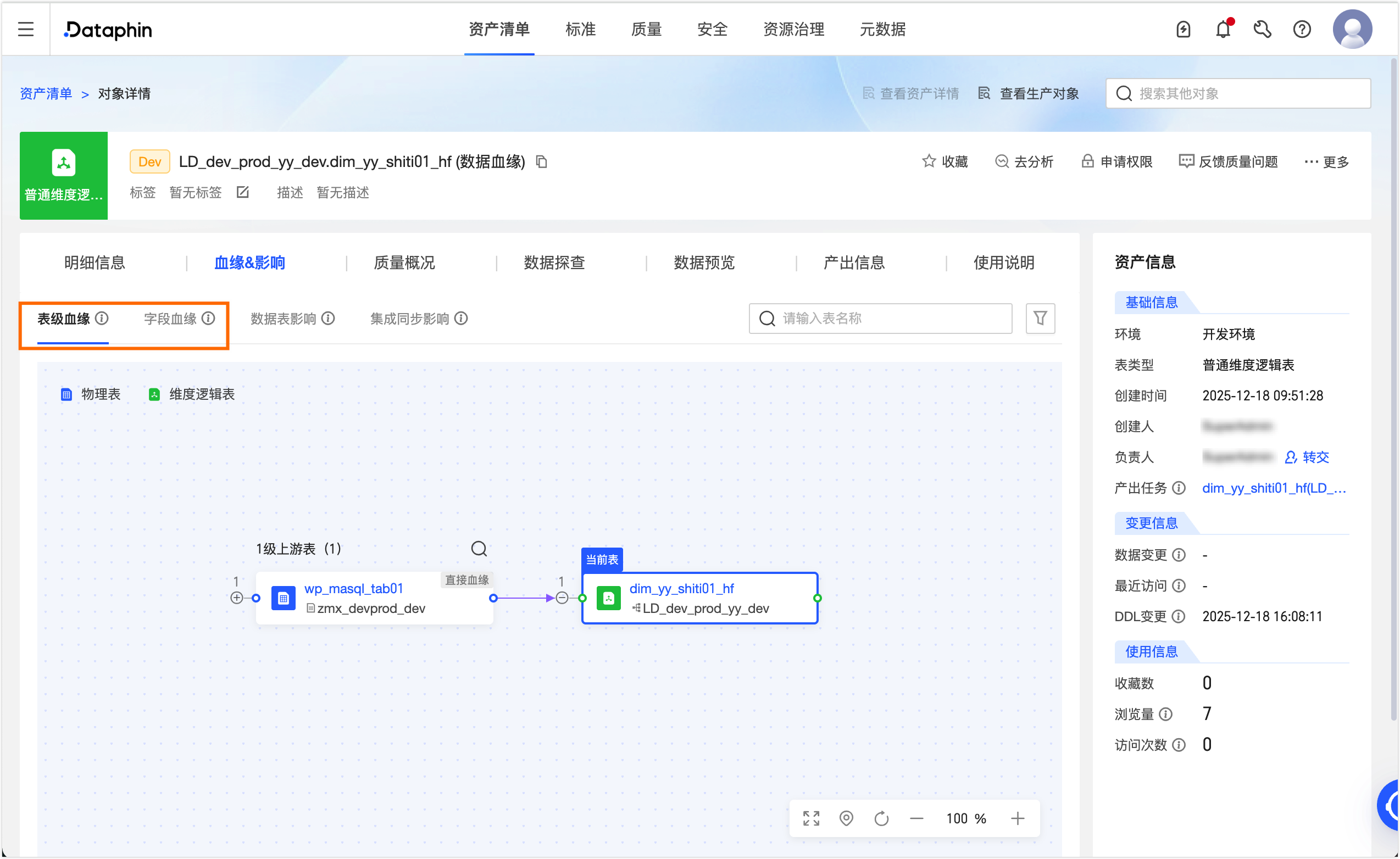
手动配置数据血缘
适用场景:适用于非SQL任务(如Python、Shell等)、存在无法通过SQL解析的复杂业务逻辑或线下约定的血缘关系、自动解析失败或未覆盖的特殊情况。
优势:弥补自动解析血缘的盲区。
在Dataphin首页的顶部菜单栏中,选择研发 > 数据研发。
在顶部菜单栏中选择项目zmx_devprod。
在左侧导航栏中选择数据处理 > 计算任务。在右侧计算任务列表中单击
图标,选择Python。在新建Python任务对话框中,配置参数。
参数
描述
任务名称
输入数据血缘_python。
调度类型
选择手动任务。
选择目录
默认为代码管理。
使用模板
关闭使用模板。
描述
输入对Python的简单描述,不超过1000个字符。
单击确定,在代码编辑区域输入脚本。
在右侧菜单栏单击血缘,在血缘配置面板中,单击配置输入表/配置输出表,在配置输入表/配置输出表对话框中,配置参数,血缘配置详情请参见自定义血缘配置。
参数
描述
所属环境
选择自动。
输入表/输出表
输入表选择zmx_devprod_dev.wp_masql_tab01。
输出表选择LD_dev_prod_yy_dev.dim_yy_shiti01_hf。
选中范围
选择全表。
单击确定,完成血缘配置。
单击代码编辑区域顶部菜单栏的保存和运行图标,保存并运行Python任务,然后再单击提交和去发布,提交Python任务后,再进行发布。
发布成功后,可在治理 > 资产清单页面的搜索框选择Dataphin资产,单击目标表wp_masql_tab01,在对象详情页面即可查看当前表的表级和字段级血缘。
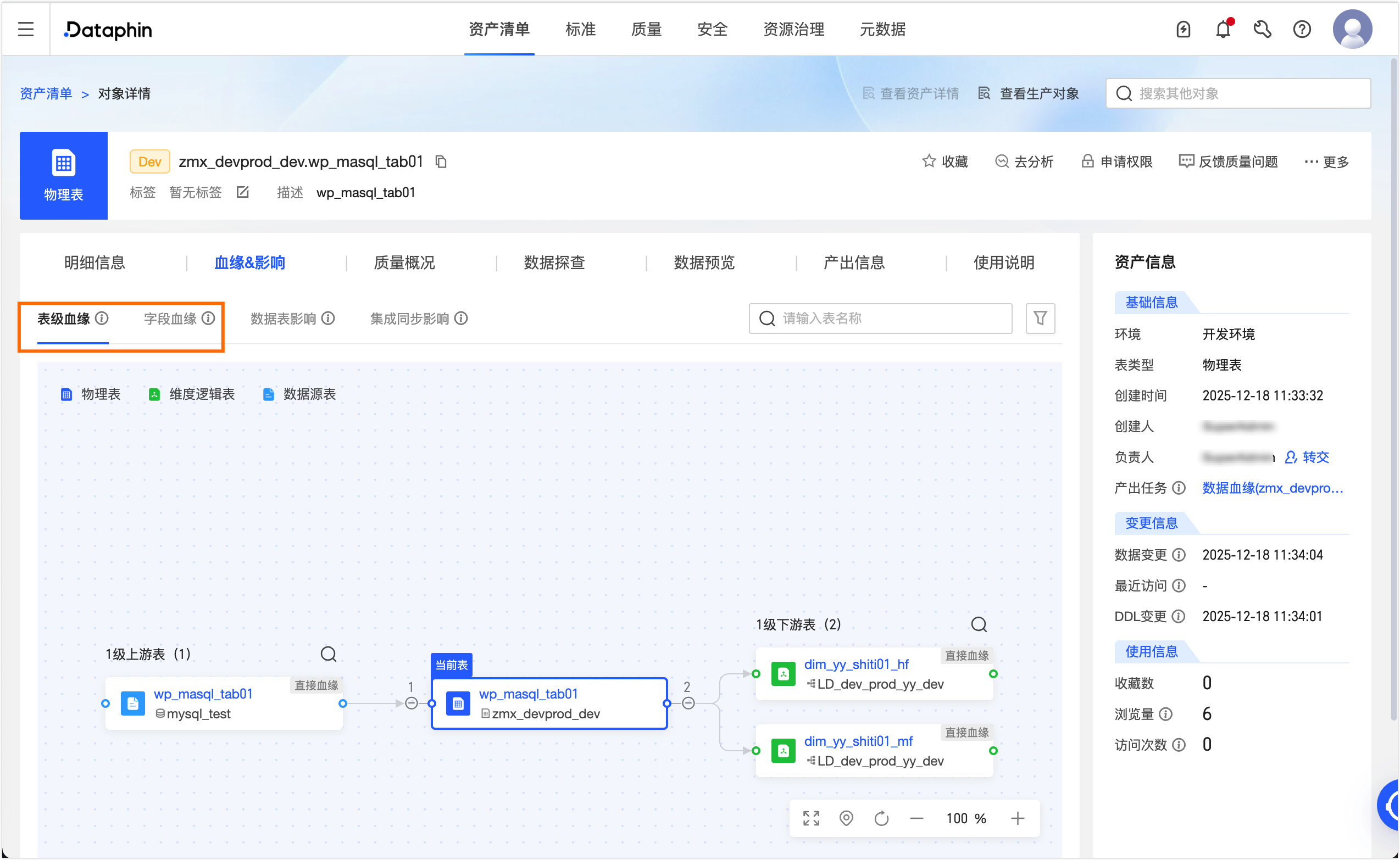
接口注册数据血缘
适用场景:用于将企业外部系统(如自建数据平台、第三方ETL工具、业务系统)产生的血缘,统一汇聚到Dataphin,形成企业级统一血缘视图。
优势:补全Dataphin系统上游(业务数据库)和下游(报表工具)的血缘。
操作方法:您可以按照指定格式注册血缘关系,Dataphin支持多种脚本语句,详情请参见注册血缘。