
所有租户的元数据采集任务将统一在元仓租户中运行,在使用元数据中心功能前,您需要先在元仓租户中完成元数据中心的初始化设置,指定元数据采集任务运行时计算源信息。本文为您介绍如何进行元数据中心设置。
使用限制
元数据中心设置的计算引擎类型需和元仓设置的引擎类型一致。
MaxCompute、E-MapReduce5.x Hadoop、E-MapReduce3.x Hadoop、CDH5.x Hadoop、CDH6.x Hadoop、Cloudera Data Platform 7.x、华为 FusionInsight 8.x Hadoop、亚信DP5.3 Hadoop计算引擎支持使用元数据中心功能。
完成元数据中心初始化配置后,不支持重新初始化。
权限说明
支持元仓租户的超级管理员或系统管理员进行元数据中心初始化配置。
名词解释
元数据:是关于数据的数据,包括技术、业务、管理元数据。它描述了数据的特性、来源、格式和关系等信息,以便于数据的检索、使用和维护。
元数据中心:负责从各业务系统中抽取、加工、集中存储和管理元数据,以支持数据治理,并加强组织内部数据的组织、检索和分析能力。
元数据中心初始化配置
使用元仓租户的超级管理员或系统管理员账号,登录元仓租户。
在Dataphin首页,选择顶部菜单栏的管理中心 > 系统设置。
单击左侧导航栏系统运维下的元数据中心设置,进入元数据中心初始化配置页面。
您需根据元仓设置的计算引擎选择元数据中心初始化的计算源类型,支持MaxCompute和Hadoop下的计算引擎。
MaxCompute
参数
描述
计算源类型
选择MaxCompute计算引擎。
Endpoint
配置Dataphin实例所在MaxCompute地域的Endpoint。不同地域和不同网络类型的MaxCompute的Endpoint详情请参见MaxCompute Endpoint。
Project Name
此处为MaxCompute项目名称,非DataWorks工作空间名称。
您可以登录MaxCompute控制台,左上角切换地域后,即可在项目管理页签查看到具体的MaxCompute项目名。
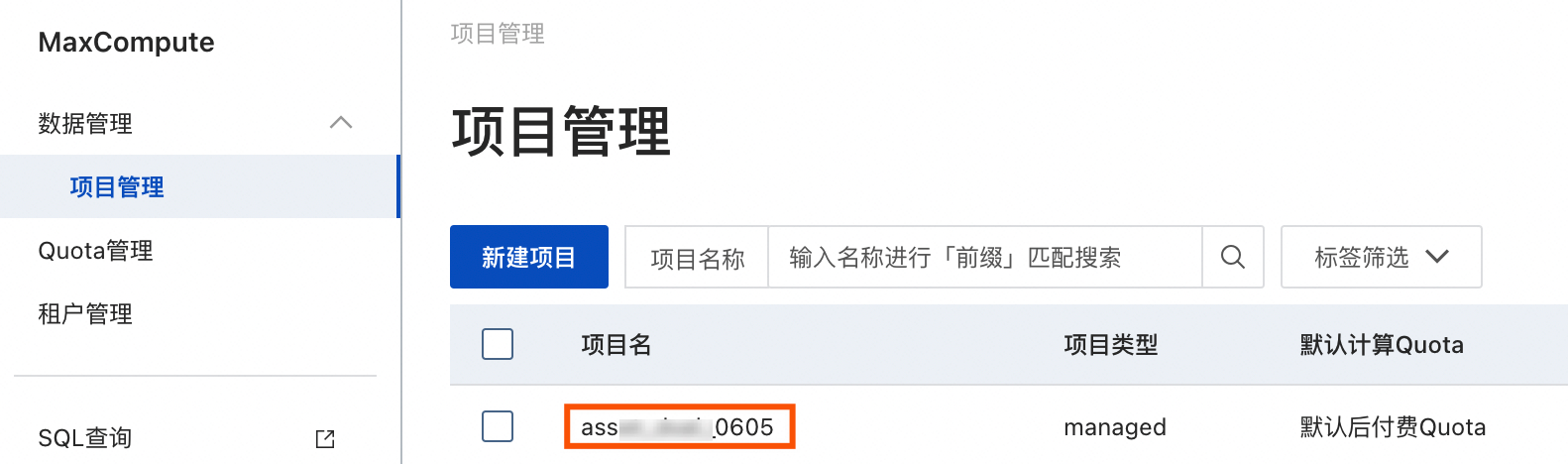
AccessKey ID、Access Key Secret
填写可以访问MaxCompute项目的账号的AccessKey ID和AccessKey Secret。
请使用已有AccessKey或者参考创建AccessKey重新创建。
说明为降低AccessKey泄露的风险,AccessKey Secret只在创建时显示一次,后续无法查看。请务必妥善保管。
为了保证Dataphin项目空间与MaxCompute项目正常连接,建议填写MaxCompute项目管理员的AccessKey。
为了保证元数据正常采集,请尽量不修改MaxCompute项目的AccessKey。
Hadoop
计算源类型:
HDFS集群存储:支持选择E-MapReduce5.x Hadoop、E-MapReduce3.x Hadoop、CDH5.x Hadoop、CDH6.x Hadoop、Cloudera Data Platform 7.x、华为 FusionInsight 8.x Hadoop、亚信DP5.3 Hadoop计算引擎。
OSS-HDFS集群存储:仅支持E-MapReduce5.x Hadoop计算引擎。
集群配置
HDFS集群存储
参数
描述
NameNode
NameNode用于管理HDFS中的文件系统名称空间及外部客户端的访问权限。
单击新增。
在新增NameNode对话框,填写NameNode的Hostname名称以及端口号,单击确定。
填写后自动生成对应的格式,例如
host=hostname,webUiPort=50070,ipcPort=8020。
配置文件
上传集群配置文件,用于配置集群参数。系统支持上传core-site.xml、hdfs-site.xml等集群配置文件。
若需使用HMS方式获取元数据,配置文件中必需上传hdfs-site.xml、hive-site.xml、core-site xmI 、hivemetastore-site.xml文件。若计算引擎类型为FusionInsight 8.X和E-MapReduce5.x Hadoop,还需上传hivemetastore-site.xml文件。
History Log
配置集群的日志路径。例如
tmp/hadoop-yarn/staging/history/done。认证方式
支持无认证和Kerberos认证方式。Kerberos是一种基于对称密钥技术的身份认证协议,常用于集群各组件间的认证。开启Kerberos能够提升集群的安全性。
如果您选择开启Kerberos认证,需配置以下参数:
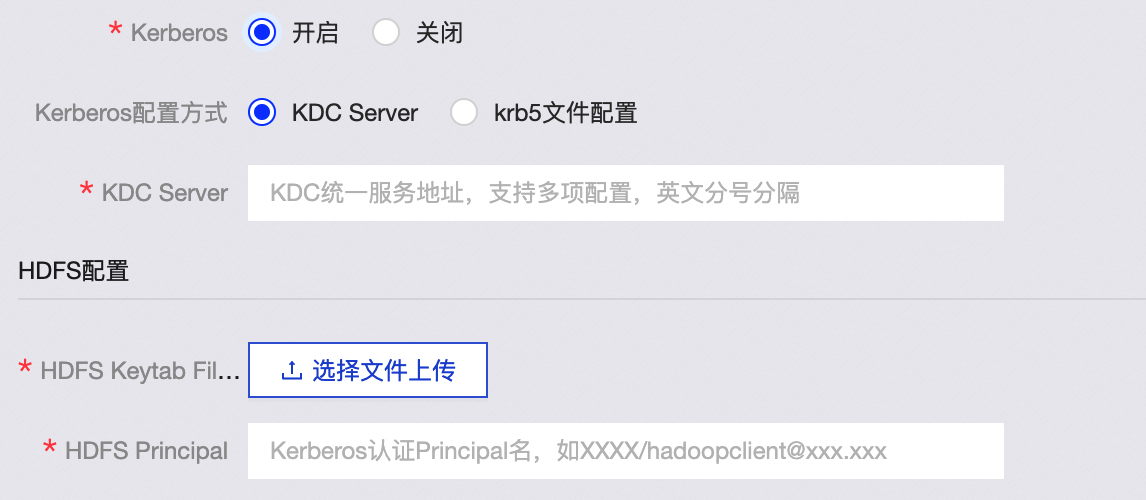
Kerberos配置方式
KDC Server:需输入KDC统一服务地址,辅助完成Kerberos认证。
krb5文件配置:需要上传Krb5文件进行Kerberos认证。
HDFS配置
HDFS Keytab File:需上传HDFS Keytab文件。
HDFS Principal:输入Kerberos认证的Principal名。例如
XXXX/hadoopclient@xxx.xxx。
OSS-HDFS集群存储
参数
描述
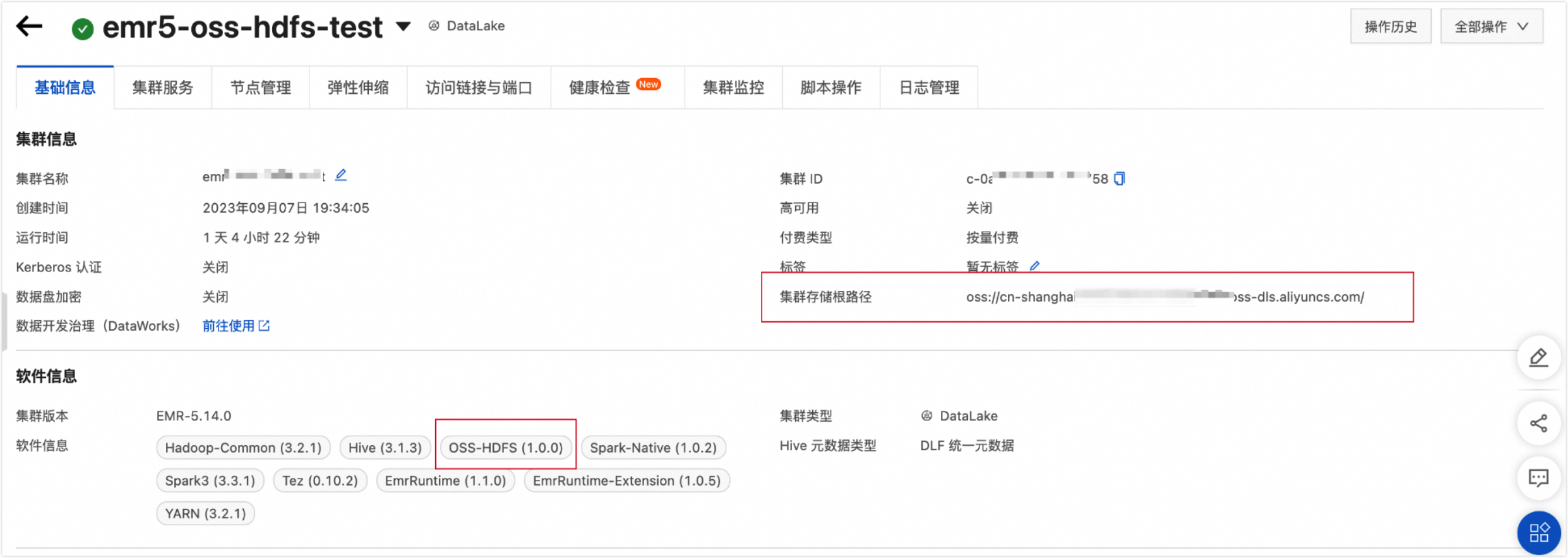
集群存储
可以通过以下方式查看集群存储类型。
未创建集群:可以通过E-MapReduce5.x Hadoop集群创建页面查看所创建的集群存储类型。如下图所示:

已创建集群:可以通过E-MapReduce5.x Hadoop集群的详情页查看所创建的集群存储类型。如下图所示:
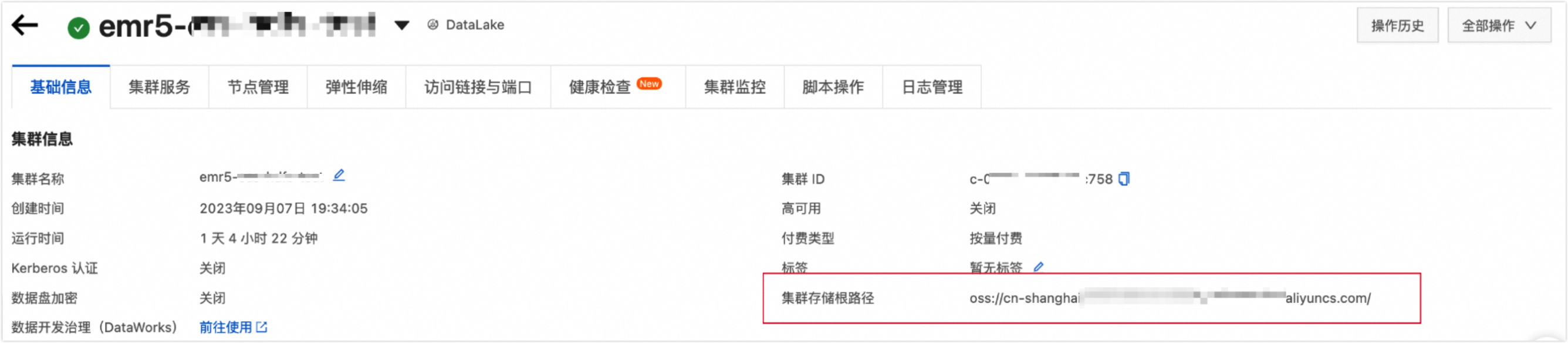
集群存储根目录
填写集群存储根目录。可以通过查看E-MapReduce5.x Hadoop集群信息进行获取。如下图所示:
 重要
重要若填写的路径中包括Endpoint,则Dataphin默认使用该Endpoint;若不包含,则使用core-site.xml中配置的Bucket级别的Endpoint;若未配置Bucket级别的Endpoint,则使用core-site.xml中的全局Endpoint。更多信息请参见阿里云OSS-HDFS服务(JindoFS 服务)Endpoint配置。
配置文件
上传集群配置文件,用于配置集群参数。系统支持上传core-site.xml、hive-site.xml等集群配置文件。若需使用HMS方式获取元数据,配置文件中必须上传hive-site.xml、core-site.xml、hivemetastore-site.xml文件。
History Log
配置集群的日志路径。例如
tmp/hadoop-yarn/staging/history/done。AccessKey ID、AccessKey Secret
填写访问集群OSS的AccessKey ID和AccessKey Secret。请使用已有AccessKey或者参考创建AccessKey重新创建。
说明为降低AccessKey泄露的风险,AccessKey Secret只在创建时显示一次,后续无法查看。请务必妥善保管。
重要此处填写的配置优先级高于core-site.xml中配置的AccessKey。
认证方式
支持无认证和Kerberos认证方式。Kerberos是一种基于对称密钥技术的身份认证协议,常用于集群各组件间的认证。开启Kerberos能够提升集群的安全性。如果您选择开启Kerberos认证,需要上传Krb5文件进行Kerberos认证。
Hive配置
参数
描述
JDBC URL
填写链接Hive的JDBC URL。
认证方式
当集群认证选择无认证时,Hive的认证方式支持选择无认证和LDAP。
当集群认证选择Kerberos时,Hive的认证方式支持选择无认证、LDAP和Kerberos。
说明当计算引擎为E-MapReduce3.x、E-MapReduce5.x、Cloudera Data Platform 7.x、亚信DP5.3、华为 FusionInsight 8.X,支持配置认证方式。
用户名、密码
访问Hive的用户名和密码。
无认证方式:需填写用户名;
LDAP认证方式:需填写用户名和密码。
Kerberos认证方式:无需填写。
Hive Keytab File
开启Kerberos认证后需配置该参数。
上传keytab文件,您可以在Hive Server上获取keytab文件。
Hive Principal
开启Kerberos认证后需配置该参数。
填写Hive Keytab File文件对应的Kerberos认证Principal名。例如
XXXX/hadoopclient@xxx.xxx。执行引擎
根据实际情况,选择合适的执行引擎。各计算引擎所支持的执行引擎不同。支持情况如下:
E-MapReduce 3.X:MapReduce、Spark。
E-MapReduce 5.X:MapReduce、Tez。
CDH 5.X:MapReduce。
CDH 6.X:MapReduce、Spark、Tez。
FusionInsight 8.X:MapReduce。
亚信DP 5.3 Hadoop:MapReduce。
Cloudera Data Platform 7.x:Tez。
说明设置了执行引擎后,元仓租户的计算设置、计算源、任务等都使用设置的Hive执行引擎。重新初始化后,计算设置、计算源、任务等将被初始化为新设置的执行引擎。
元数据获取方式
元数据获取方式支持元数据库和HMS(Hive Metastore Service)2种方式获取元数据。不同获取方式所配置信息不同。详情如下:
元数据库方式获取
参数
描述
数据库类型
仅支持MySQL作为Hive的元数据库类型。
支持的MySQL版本包括:MySQL 5.1.43、MYSQL 5.6/5.7和MySQL 8。
JDBC URL
填写目标数据库JDBC的链接地址。例如:链接地址格式为
jdbc:mysql://host:port/dbname。用户名、密码
目标数据库的用户名和密码。
HMS获取方式
使用HMS方式获取元数据库,开启Kerberos后,需上传Keytab File文件和填写Principal。
参数
描述
Keytab File
Hive metastore的Kerberos认证的Keytab文件。
Principal
Hive metastore的Kerberos认证的Principal。
当必填项信息配置完成后,单击连接测试,检测与Dataphin是否连通。
连接测试通过后,单击确定并开始初始化,并对权限、元仓初始化配置进行校验。
权限:校验本次操作人是否为元仓租户的超级管理员或系统管理员用户。
元仓初始化配置:校验元仓初始化配置是否已经成功。
校验通过后,开始初始化流程(创建计算源、项目、数据源及初始化DDL语句),流程通过后,完成元数据中心初始化设置。
相关文档
元数据中心初始化设置完成后,您可以将数据库中的元数据采集至Dataphin,进行分析、管理。详情请参见新建及管理元数据采集任务。