
离线物理表可帮助您统一配置与管理计算任务开发过程中用到的离线物理表,提升开发效率。
使用限制
若您未购买数据标准模块,不支持设置表中的数据标准字段。
若您未购买资产安全模块,不支持设置表中的数据分级、数据分类字段。
仅支持MaxCompute、Hadoop、Lindorm、Databricks、GaussDB(DWS)、AnalyticDB for PostgreSQL计算引擎。
创建离线物理表
步骤一:配置基本信息
在Dataphin首页的顶部菜单栏选择研发 > 数据研发。
在顶部菜单栏选择项目(Dev-Prod模式还需选择环境)。
在左侧导航栏选择数据处理 > 表管理。
在表管理列表中单击
 图标,选择离线物理表。
图标,选择离线物理表。在新建物理表配置向导中,配置以下参数。不同类型的计算引擎,所需配置参数不同。
MaxCompute计算引擎
参数
描述
表名称
输入离线物理表的名称,仅支持英文字母、数字和下划线(_),不超过128个字符。
目录
选择离线物理表所存放的目录。
若未创建目录,您可以新建文件夹,操作方法如下:
在页面左侧计算任务列表上方单击
 图标,打开新建文件夹对话框。
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称,类型选择为离线,并根据需要选择目录位置。
单击确定。
主题域(非必选)
选择表所归属的主题域。若无可选主题域,您可以进行创建。请参见创建主题域。
描述(非必填)
填写简单的描述,1000个字符以内。
Hadoop计算引擎
参数
描述
表名称
输入离线物理表的名称,仅支持英文字母、数字和下划线(_),不超过128个字符。
目录
选择离线物理表所存放的目录。
若未创建目录,您可以新建文件夹,操作方法如下:
在页面左侧计算任务列表上方单击
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称,类型选择为离线,并根据需要选择目录位置。
单击确定。
主题域(非必选)
选择表所归属的主题域。若无可选主题域,您可以进行创建,请参见创建主题域。
描述(非必填)
填写简单的描述,1000个字符以内。
存储格式
选择离线物理表的存储格式,当前支持选择以下格式。
hudi、delta(Delta Lake):当且仅当项目对应的计算源开启了Spark SQL时,支持选择;若当前项目对应的计算源未开启Spark SQL,但研发平台-表管理设置中的默认存储格式选择为hudi或delta(Delta Lake),则此处存储格式默认为引擎默认(建表语句中可另外指定)。
选择hudi,建表语句中存储格式子句为
using hudi;选择delta(Delta Lake),建表语句中存储格式子句为using delta。paimon
iceberg
parquet:建表语句中存储格式子句为
stored as parquet。avro:建表语句中存储格式子句为
stored as avro。rcfile:建表语句中存储格式子句为
stored as rcfile。orc:建表语句中存储格式子句为
stored as orc。textfile:建表语句中存储格式子句为
stored as textfile。sequencefile:建表语句中存储格式子句为
stored as sequencefile。
Lindom计算引擎
参数
描述
表名称
输入离线物理表的名称,仅支持英文字母、数字和下划线(_),不超过128个字符。
目录
选择离线物理表所存放的目录。
若未创建目录,您可以新建文件夹,操作方法如下:
在页面左侧计算任务列表上方单击
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称,类型选择为离线,并根据需要选择目录位置。
单击确定。
主题域(非必选)
选择表所归属的主题域。若无可选主题域,您可以进行创建。请参见创建主题域。
描述(非必填)
填写简单的描述,1000个字符以内。
存储格式
选择离线物理表的存储格式,默认与研发平台-表管理设置中的默认存储格式一致,当前支持选择以下格式。
引擎默认(建表语句中可另外指定):建表语句无存储格式设置语句(using或stored as)。
iceberg
parquet
avro
rcfile
orc
textfile
sequencefile
Databricks计算引擎
参数
描述
表名称
输入离线物理表的名称,仅支持英文字母、数字和下划线(_),不超过128个字符。
目录
选择离线物理表所存放的目录。
若未创建目录,您可以新建文件夹,操作方法如下:
在页面左侧计算任务列表上方单击
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称,类型选择为离线,并根据需要选择目录位置。
单击确定。
主题域(非必选)
选择表所归属的主题域。若无可选主题域,您可以进行创建。请参见创建主题域。
描述(非必填)
填写简单的描述,1000个字符以内。
存储格式
选择离线物理表的存储格式,默认与研发平台-表管理设置中的默认存储格式一致,当前支持选择以下格式。
引擎默认(建表语句中可另外指定):建表语句无存储格式设置语句(using或stored as)。
avro
binaryfile
csv
delta(Delta Lake)
json
orc
parquet
text
GaussDB(DWS)/AnalyticDB for PostgreSQL计算引擎
参数
描述
表名称
输入离线物理表的名称,仅支持英文字母、数字和下划线(_),不超过63个字符。
目录
选择离线物理表所存放的目录。
若未创建目录,您可以新建文件夹,操作方法如下:
在页面左侧计算任务列表上方单击
图标,打开新建文件夹对话框。在新建文件夹对话框中输入文件夹名称,类型选择为离线,并根据需要选择目录位置。
单击确定。
主题域(非必选)
仅当项目所属板块已绑定业务板块时,支持选择主题域。
描述(非必填)
填写简单的描述,1000个字符以内。
配置完成后,单击下一步。
步骤二:配置字段列表
不同计算引擎支持的存储格式不同,详情请参见表管理设置。不同存储格式字段列表所支持的配置不同,详见下表。
Databricks计算引擎下的离线物理表,当存储格式为引擎默认(建表语句中可另外指定)时,字段列表所支持的配置与存储格式为delta(Delta Lake)时相同。
存储格式为hudi、delta(Delta Lake)、iceberg或paimon
在字段列表配置页面配置当前物理表的表字段、数据类型、数据分类等结构信息。
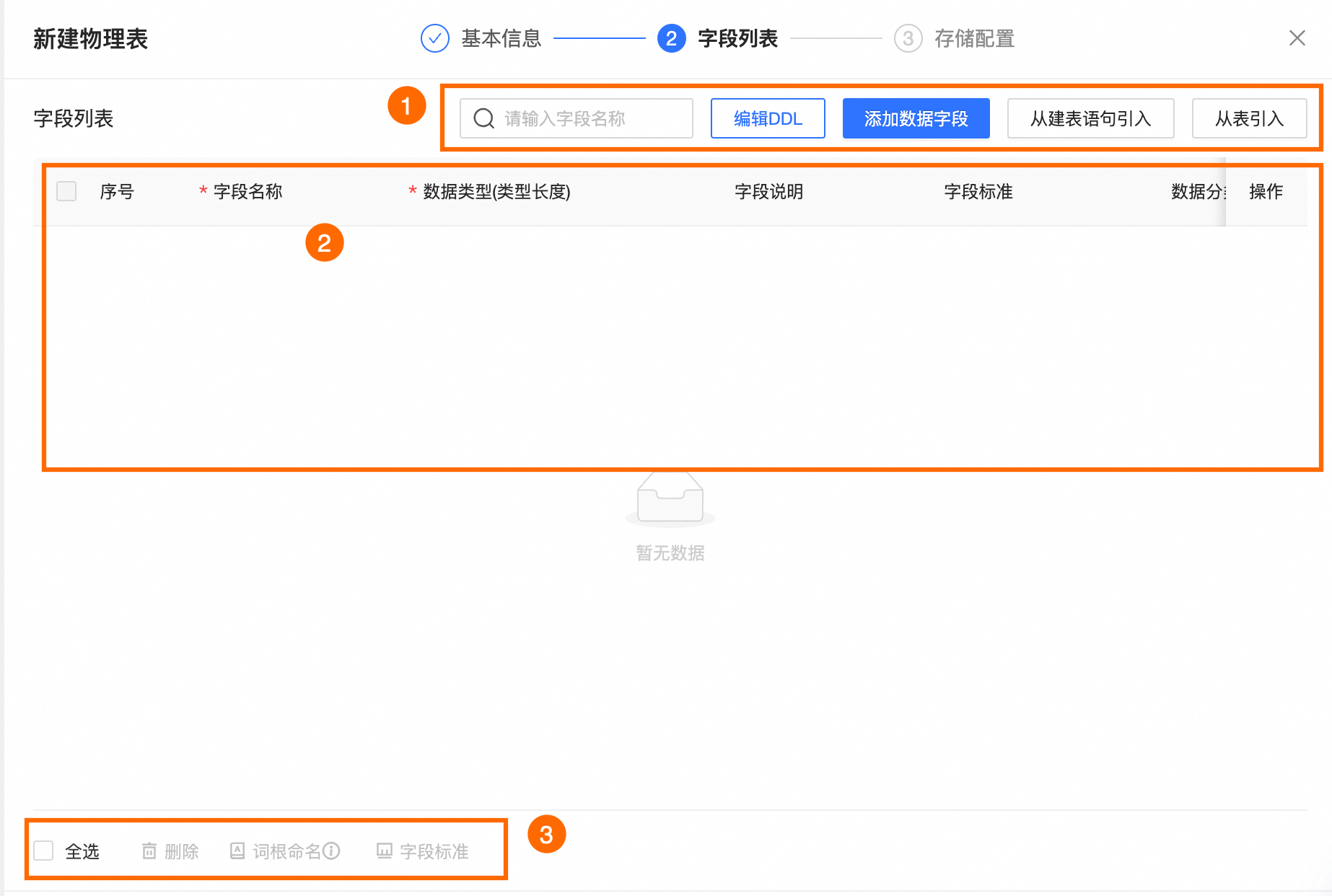
区块
说明
①字段列表操作
搜索:您可以通过表字段名称搜索所需字段。
编辑DDL:编辑当前物理表的DDL语句。
添加数据字段:单击添加数据字段,在新添加的字段行中填写字段名称、数据类型和字段说明等信息。
从建表语句引入:使用建表语句引入新字段。单击从建表语句引入,在从建表语句引入对话框中,按照下图操作指引,输入建表语句后单击解析SQL,在解析出的字段中选中所需引入的字段,并单击添加进行引入。
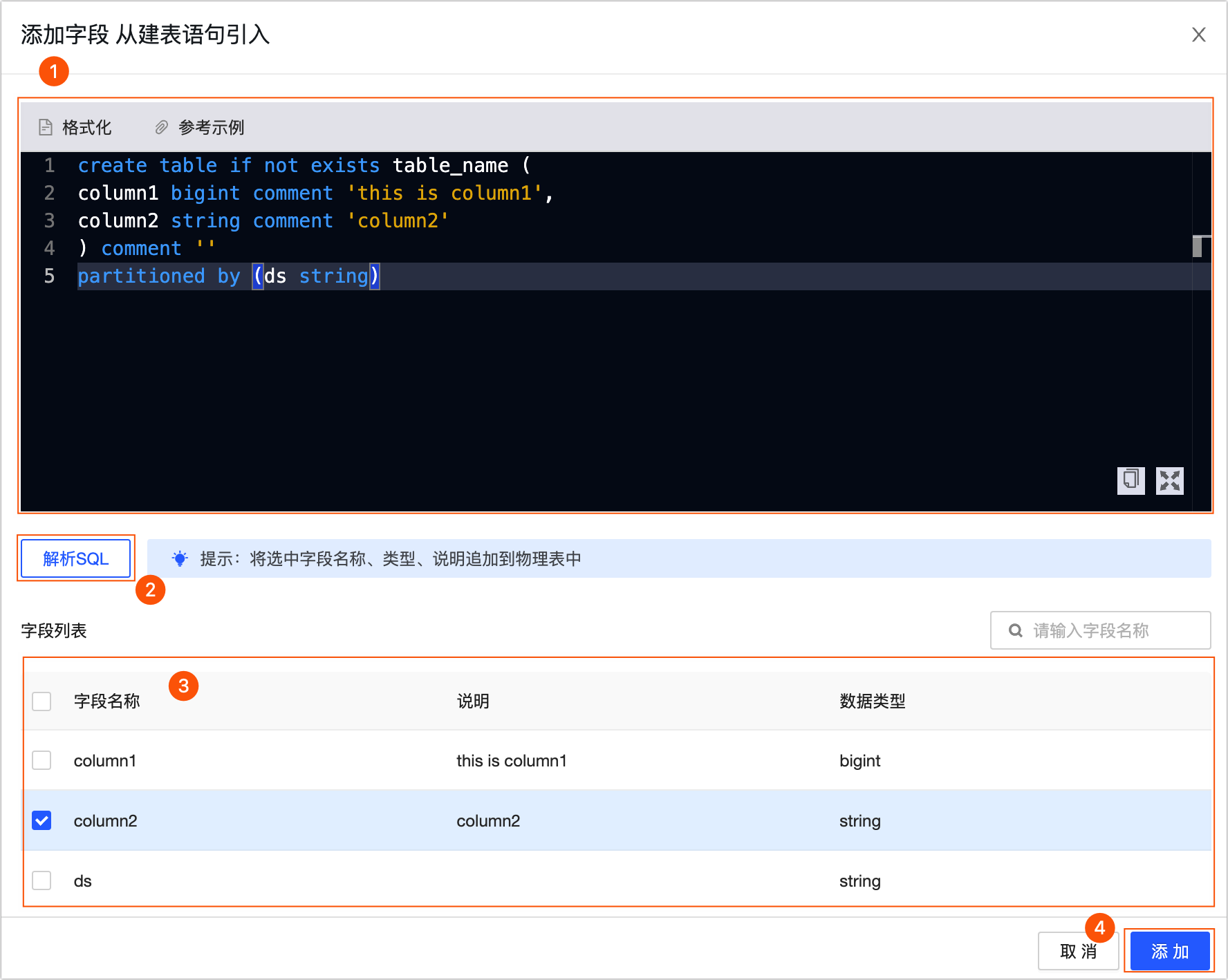
从表引入:单击从表引入,在从表引入对话框中,选择引入字段所在的来源表并选中所需引入字段,并单击添加进行引入。
②字段列表
字段列表为您展示字段的序号、字段名称、数据类型、字段说明、字段标准、数据分类、数据分级等字段的详细信息。
序号:表字段序号。每新增1个字段,按序递增。
字段名称:表字段名称。您可输入词根的全称进行搜索,系统将自动匹配治理 > 数据标准 >词根中配置的词根。
数据类型:支持string、bigint、double、timestamp、decimal、文本、数值、日期时间及其他数据类型。
文本:varchar、char。
数值:int、smaIlint、tinyint、float。
日期时间:date。MaxCompute计算引擎支持datetime。
说明Hadoop计算引擎不支持datetime。
其他:boolean、binary。
字段说明:表字段说明信息,512个字符以内。
字段标准:选择字段的字段标准。如需创建标准,请参见新建和管理数据标准。
数据分类:选择字段的数据分类。如需创建数据分类,请参见新建数据分类。
数据分级:选择数据分类后,系统将自动识别数据级别。
同时您可以在操作列下对字段进行删除操作。
说明字段删除后不可撤销。
③批量操作
您可以批量选择表字段,进行以下操作。
删除:单击
 图标,批量删除已经选中的数据字段。
图标,批量删除已经选中的数据字段。词根命名:单击
 图标,系统将对字段的说明内容进行分词并匹配已经创建的词根,进行字段名称推荐。您可以在词根命名对话框中,将选中字段的名称替换为修改后的值。说明
图标,系统将对字段的说明内容进行分词并匹配已经创建的词根,进行字段名称推荐。您可以在词根命名对话框中,将选中字段的名称替换为修改后的值。说明若推荐的字段名称均不满足需求,您可以在修复后字段名称输入框中进行修改。
单击重置将重置修改后字段名称为系统的命中词根。
字段标准:单击
 图标,系统将根据字段名称进行字段标准推荐。您可以在字段标准对话框中,将字段设置为推荐的字段标准。
图标,系统将根据字段名称进行字段标准推荐。您可以在字段标准对话框中,将字段设置为推荐的字段标准。
完成字段添加后,单击下一步。
非hudi、delta(Delta Lake)、iceberg或paimon存储格式
在字段列表配置页面配置当前物理表的表字段、数据类型、数据分类等结构信息。
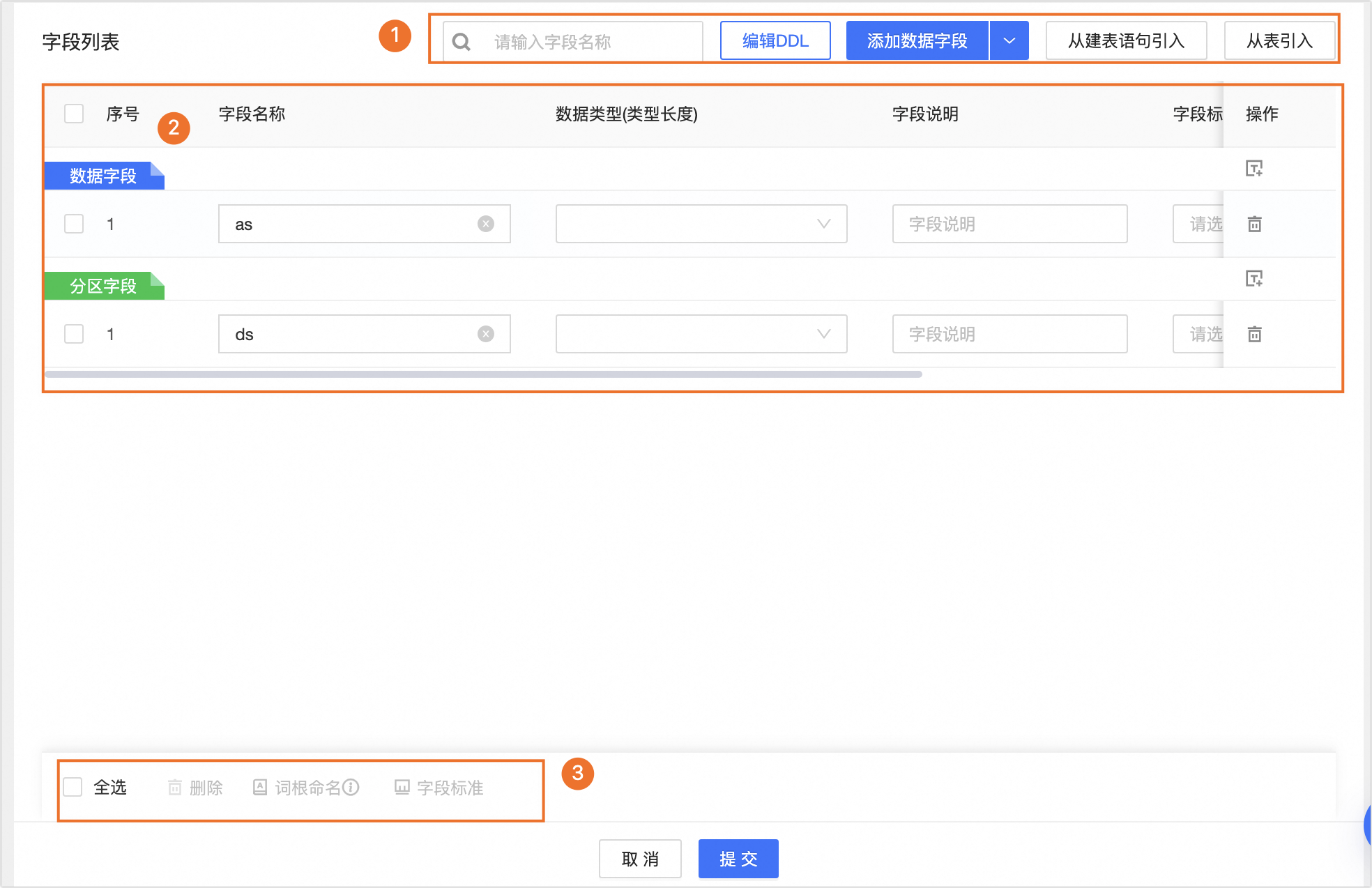
区块
说明
①字段列表操作
搜索:您可以通过表字段名称搜索所需字段。
编辑DDL:编辑当前物理表的DDL语句。
添加数据字段:单击添加字段,选择数据字段、分区字段或快捷添加日期分区字段类型,并在新添加的字段行中填写字段名称、数据类型和字段说明等信息。
添加数据字段:单击可在表字段中添加一行数据字段。
分区字段:单击可在表字段中添加一行分区字段。
快捷添加日期分区:单击可在表字段中添加一行日期分区。默认为
ds。
从建表语句引入:使用建表语句引入新字段。单击从建表语句引入,在从建表语句引入对话框中,按照下图操作指引,输入建表语句后单击解析SQL,在解析出的字段中选中所需引入的字段,并单击添加进行引入。
从表引入:单击从表引入,在从表引入对话框中,选择引入字段所在的来源表并选中所需引入字段,并单击添加进行引入。
②字段列表
字段列表为您展示字段的序号、字段名称、数据类型、字段说明、字段标准、数据分类、数据分级等字段的详细信息。
序号:表字段序号。每新增1个字段,自增+1。
字段名称:表字段名称。您可输入词根的全称进行搜索,系统将自动匹配治理 > 数据标准 >词根中配置的词根。
数据类型:支持string、bigint、double、timestamp、decimal、文本、数值、日期时间及其他数据类型。
文本:varchar、char。
数值:int、smaIlint、tinyint、float。
日期时间:date。MaxCompute计算引擎支持datetime。
说明Hadoop计算引擎不支持datetime。
其他:boolean、binary。
字段说明:表字段说明信息,512个字符以内。
字段标准:选择字段的字段标准。如需创建标准,请参见新建和管理数据标准。
数据分类:选择字段的数据分类。如需创建数据分类,请参见新建数据分类。
数据分级:选择数据分类后,系统将自动识别数据级别。
同时您可以在操作列下对字段进行删除操作。
说明字段删除后不可撤销。
③批量操作
您可以批量选择表字段,进行以下操作。
删除:单击
图标,批量删除已经选中的数据字段。词根命名:单击
图标,系统将对字段的说明内容进行分词并匹配已经创建的词根,进行字段名称推荐。您可以在词根命名对话框中,将选中字段的名称替换为修改后的值。说明若推荐的字段名称均不满足需求,您可以在修复后字段名称输入框中进行修改。
单击重置将重置修改后字段名称为系统的命中词根。
字段标准:单击
图标,系统将根据字段名称进行字段标准推荐。您可以在字段标准对话框中,将字段设置为推荐的字段标准。
完成字段添加后,单击下一步。
GaussDB(DWS)/AnalyticDB for PostgreSQL计算引擎
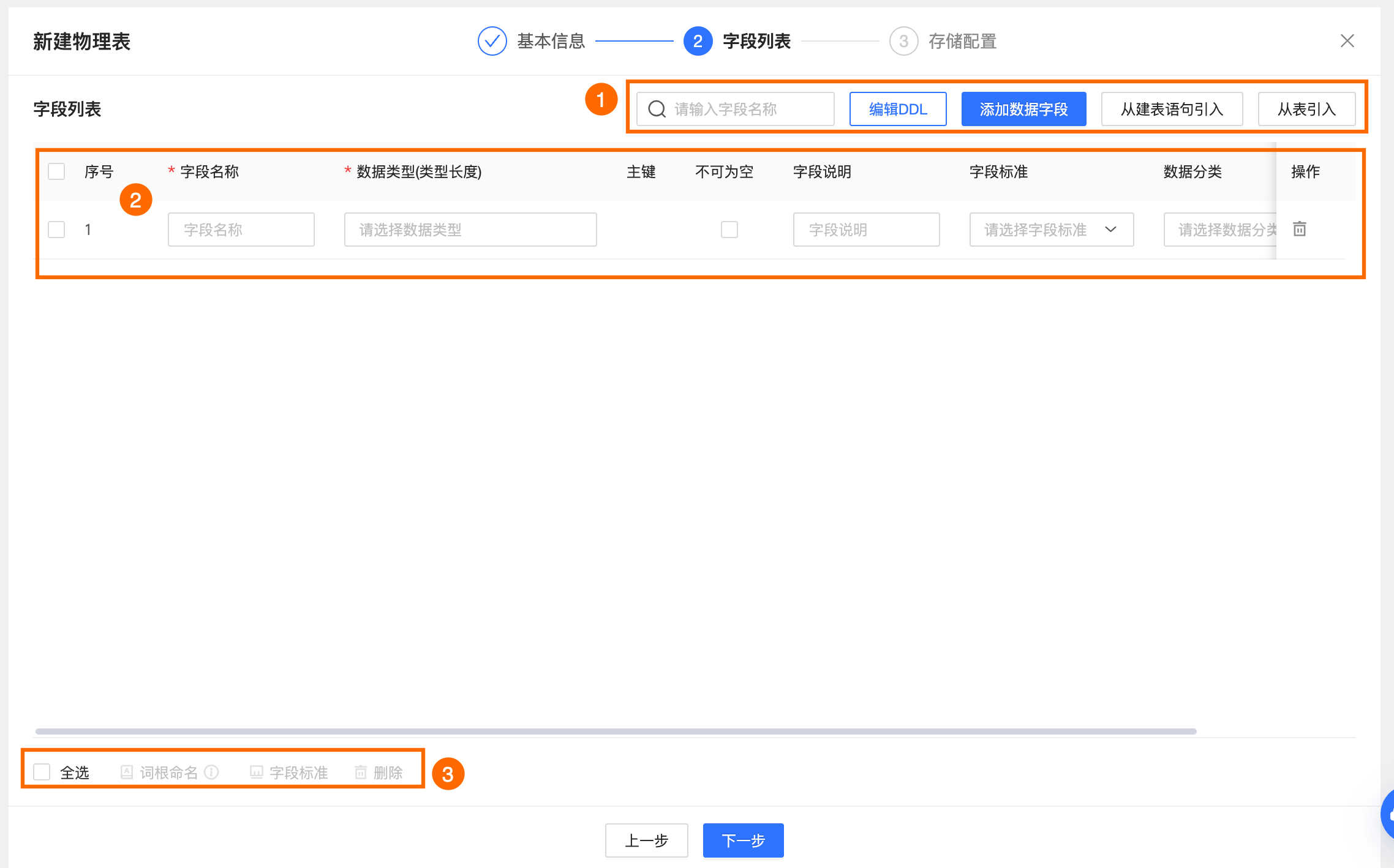
区块 | 说明 |
①字段列表操作 |
|
②字段列表 | 字段列表为您展示字段的序号、字段名称、数据类型(类型长度)、主键、不可为空、字段说明、字段标准、数据分类、数据分级等字段的详细信息。
同时您可以在操作列下对字段进行删除操作。 说明 字段删除后不可撤销。 |
③批量操作 | 您可以批量选择表字段,进行以下操作。
|
步骤三:存储配置
MaxCompute计算引擎、Hadoop计算引擎下不同存储格式存储配置所支持的配置不同,详见下表。
存储格式为hudi
参数 | 描述 |
数据更新类型(非必选) | 选择type,可选择cow(Copy on Write)或mor(Merge on Read)。 |
主键与合并排序键(非必选) |
|
数据分布 | 开启或关闭Partition,默认为关闭。 开启Partition后,还需选择Partitioned By,可选择字段列表中的一个或多个字段。 说明 Partitioned By不支持将所有字段作为分区字段,即列表中字段不可全选。 |
存储地址(非必填) | 输入Location(存储地址),支持使用全局变量,不超过512个字符。 说明 外部表可省略external关键词。若建表语句中包含location子句,则所创建的表为外部表。 |
参数配置完成后,单击提交。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
hudi编辑SQL的DDL语句可参见SQL DDL、Schema Evolution。
若Location(存储地址)为空,则建表语句中无location子句。
若当前计算引擎为Hadoop计算引擎,则使用Spark SQL;若当前计算引擎为Lindorm(计算引擎)或Databricks,则使用计算源默认SQL。
存储格式为delta(Delta Lake)
参数 | 描述 |
数据分布 |
说明
|
存储地址(非必填) | 输入Location(存储地址),支持使用全局变量,不超过512个字符。 说明 外部表可省略external关键词。若建表语句中包含location子句,则所创建的表为外部表。 |
参数配置完成后,单击提交。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
delta编辑SQL的DDL语句可参见AlTER TABLE。
若Location(存储地址)为空,则建表语句中无location子句。
若当前计算引擎为Hadoop计算引擎,则使用Spark SQL;若当前计算引擎为Lindorm(计算引擎)或Databricks,则使用计算源默认SQL。
存储格式为iceberg
参数 | 描述 |
Partition | 默认关闭,开启后需配置Partitioned By。 Partitioned By:可选择多个字段列表中的任意字段,同时支持手动输入字段,多个字段间使用半角逗号(,)分隔。 |
Location | 输入Location(存储地址),支持使用全局变量,不超过512个字符。 说明 外部表可省略 |
参数配置完成后,单击提交。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
若Location(存储地址)为空,则建表语句中无location子句。
若当前计算引擎为Hadoop计算引擎,则使用Spark SQL;若当前计算引擎为Lindorm(计算引擎),则使用计算源默认SQL。
存储格式为paimon
参数 | 描述 |
Primary Key | 选择一个或多个Primary Key(主键),选择完成后还需配置Table Mode。 |
Table Mode | 选择Table Mode(数据更新类型),可选择MOR、COW或MOW。 |
Partition | 默认关闭,开启后需配置Partitioned By。 Partitioned By:可选择一个或多个字段列表中的任意字段。 |
Location | 输入Location(存储地址),支持使用全局变量,不超过512个字符。 说明 外部表可省略 |
参数配置完成后,单击提交。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
若Location(存储地址)为空,则建表语句中无location子句。
当前计算引擎为Hadoop计算引擎,则使用Spark SQL。
其他存储格式
参数 | 描述 |
存储类型 | 可选择内部表或外部表。若选择外部表,还需配置Location。 |
Location | 输入Location(存储地址),支持使用全局变量,不超过512个字符。 |
参数配置完成后,单击提交。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
若当前计算引擎为Hadoop计算引擎,且存储格式选择为kudu,则使用Impala SQL。
MaxCompute计算引擎
MaxCompute内部表
参数
描述
存储类型
选择内部表。
是否事物表
选择是或否,若选择是,还可继续配置Primary Key,将表创建为Delta表。
Primary Key(非必选)
选择一个或多个主键,可选择字段列表中的所有字段。若选择多个主键,将按照选择顺序进行排序。
生命周期(非必填)
当前表的保存时间。支持输入正整数天,也可以快速选择7、14、30或360天。
MaxCompute外部表
参数
描述
存储类型
选择外部表。
存储格式
选择存储格式,默认与研发平台-表管理设置中的外部表默认存储格式一致。可选择parquet、avro、rcfile、orc、textfile或sequencefile。
Location
输入Location(存储地址),支持使用全局变量,不超过512个字符。
参数配置完成后,单击提交。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
GaussDB(DWS)/AnalyticDB for PostgreSQL计算引擎
表级约束(Table Constraint):单击新增约束,新增一行约束,需配置约束类型、约束设置和Deferrable策略。
参数
描述
约束类型
可选择主键、唯一约束或Check约束。
约束设置
当约束类型选择为主键时:可选择一个或多个数据类型为text、character varying(varchar)、bigint (int8)、smallint(int2)、integer(int/int4)的字段。
说明一个表仅支持设置一个主键约束。
如果已在字段列表中选择了主键,则系统将自动在表级约束添加主键约束,约束设置为字段列表中的选中字段。
当约束类型选择为唯一约束时:可选择一个或多个字段,字段列表中所有字段均可选。
当约束类型选择为Check约束时:可输入任意字符,不超过512个字符。
Deferrable策略
可选择not deferrable、initially immediate或initially deferred,默认为not deferrable。
说明当约束类型为Check约束时,不支持此参数。
单击删除图标,可删除对应行约束。
分布方式(Distributed By)(非必选):
AnalyticDB for PostgreSQL计算引擎:可选择RANDOMLY、BY(<columns>)或REPLICATED。
GaussDB(DWS)计算引擎:可选择REPLICATION、ROUNDROBIN或BY HASH(<columns>)。当选择BY HASH(<columns>)时,还需选择分布字段,可选项中包含字段列表中的所有字段。
分区(Partition):单击新增分区,新增一个分区字段,根据分区类型配置不同参数。单击删除图标,可删除对应分区字段(包含此分区中所有数据分区信息)。
分区类型为LIST、RANGE时:
分区字段:选择分区字段,或手动输入表达式。
AnalyticDB for PostgreSQL计算引擎(数据库版本6.x)仅支持单字段分区;AnalyticDB for PostgreSQL计算引擎(数据库版本7.x)、GaussDB(DWS)计算引擎支持输入表达式。
分区名称和分区值:单击添加图标,可添加一行数据分区;单击删除图标,可删除对应行的数据分区信息。
说明计算引擎为AnalyticDB for PostgreSQL(数据库版本6.x)时,系统将自动添加一行默认分区,默认分区的分区名称为非必填。当默认分区的分区名称为空时,需添加至少一个数据分区。
计算引擎为GaussDB(DWS)时,需添加至少一个数据分区。
计算引擎为AnalyticDB for PostgreSQL(数据库版本7.x)时,可不添加任何数据分区。
分区名称:仅支持英文、数字和下划线(_),长度不超过63个字符。
说明分区本身是一个表,完整分区表名格式默认为
<主表名称>_<分区层级#>_prt_<分区名>。分区值:
当分区类型为LIST时:支持任意字符,长度不超过512个字符。当输入的值为文本类型(例如,text、varchar、char)时,需加单引号('')。
当分区类型为RANGE时:需配置START、END、EVERY,可输入任意字符,长度不超过512个字符。当输入的值为文本类型(例如,text、varchar、char)时,需加单引号('')。
START和END还需选择INCLUSIVE或EXCLUSIVE,START默认选择INCLUSIVE;END默认选择EXCLUSIVE。
说明分区值的有效性取决于分区字段的类型。
分区类型为HASH:仅需配置分区字段,无需配置数据分区。分区字段配置说明同LIST和RANGE类型。
说明分布方式为REPLICATED的表,不支持分区。
当计算引擎为GaussDB(DWS)时,不支持多级分区。
仅当计算引擎为AnalyticDB for PostgreSQL(数据库版本7.x)时,分区类型支持选择HASH。
导入数据
提交离线物理表后,您可导入数据至离线物理表。
在表管理列表中单击目标离线物理表,可输入表名关键字搜索。
在表详情页面,单击导入数据,打开导入数据对话框。
在导入数据对话框的基础配置步骤中上传数据并配置导入参数。
参数
描述
上传文件
单击选择文件,上传需导入的数据文件。仅支持.txt、.csv类型的文件,文件大小不超过10MB。
分隔符
数据的分隔符,支持逗号(,)、水平制表符(\t)、竖线(|)、正斜线(/)。也可以输入指定其他分隔符。
字符集编码
选择上传的数据文件字符集编码。支持解析utf-8(无BOM)、utf-8(有BOM)、gbk、big5、gb2312、ascii、utf-16字符集。
首行为标题
根据上传的数据文件选择首行是否为标题。
目标分区
如果表为分区表,需输入导入数据的目标分区名称。
单击下一步。
在导入数据步骤中,配置数据表字段的映射关系。
映射关系:
同行映射:即按相同行数对应进行绑定为映射关系。
同名映射:即按相同名称对应进行绑定为映射关系。
导入文件数据列:支持设置为数据列、空值NULL或固定值。
单击开始导入,即可将数据导入到表中。
编辑离线物理表
提交离线物理表后,您可编辑物理表数据。
在表管理列表中单击目标离线物理表,可输入表名关键字搜索。
在表详情页面,单击编辑,打开物理表编辑页面。
不同类型的存储格式,支持编辑的参数不同,详见下表。
存储格式为hudi
页签
描述
基本信息
仅支持编辑表名称和描述,参数填写要求与创建离线物理表时一致。
字段列表
支持编辑和删除除hudi系统字段外其他字段的字段名称和字段类型。hudi系统字段包含:
_hoodie_commit_time
_hoodie_commit_seqno
_hoodie_record_key
_hoodie_partition_path
_hoodie_file_name
说明在修改字段名称、字段类型或添加/删除字段时,根据不同引擎的设置,可能会因不支持而报错。
存储配置
仅支持编辑type、primaryKey、preCombineField和Location。其中仅当当前数据表为外部表时,可编辑Location。
编辑完成后,单击提交,提交时使用计算源默认SQL。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
说明对存储格式为hudi的表(Hudi表)做重命名字段、删除字段、修改字段类型等操作时,如果遇到引擎报错,请联系引擎服务商检查引擎设置。
存储格式为delta(Delta Lake)
页签
描述
基本信息
仅支持编辑表名称和描述,参数填写要求与创建离线物理表时一致。
字段列表
支持编辑、删除已有字段,可添加新字段。字段填写要求与创建离线物理表时一致。
存储配置
数据分布
当Liquid Clustering开启时,支持关闭或重新选择Cluster By字段。
当Liquid Clustering关闭,且Partition也关闭时,可开启Liquid Clustering并指定Cluster By字段。
当Liquid Clustering关闭,且Partition也关闭时,Partition不可开启。
当Partition开启时,Liquid Clustering、Partition和Partitioned By均不支持修改。
存储地址:仅当当前数据表为外部表时,支持编辑Location。
编辑完成后,单击提交,提交时使用计算源默认SQL。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
存储格式为iceberg
页签
描述
基本信息
仅支持编辑表名称和描述,参数填写要求与创建离线物理表时一致。
字段列表
支持编辑字段名称和字段类型,同时支持新增和删除字段。
说明在修改字段名称、字段类型或添加/删除字段时,根据不同引擎的设置,可能会因不支持而报错。
存储配置
仅当当前数据表为外部表时,可编辑Location。
编辑完成后,单击提交,若当前计算引擎为Hadoop计算引擎,则使用Spark SQL;若当前计算引擎为Lindorm(计算引擎),则使用计算源默认SQL。
在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
存储格式为paimon
页签
描述
基本信息
仅支持编辑表名称和描述,参数填写要求与创建离线物理表时一致。
字段列表
支持编辑字段名称和字段类型,同时支持新增和删除字段。
说明在修改字段名称、字段类型或添加/删除字段时,根据不同引擎的设置,可能会因不支持而报错。
存储配置
仅当当前数据表为外部表时,可编辑Location。
编辑完成后,单击提交,提交时使用Spark SQL。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
MaxCompute计算引擎
MaxCompute内部表
页签
描述
基本信息
仅支持编辑表名称和描述,参数填写要求与创建离线物理表时一致。
字段列表
支持编辑、删除已有字段,可添加新字段。字段填写要求与创建离线物理表时一致,当修改字段类型时会生成DDL。
支持取消选中字段的不可为空选项。
若当前表为内部事务表,已设置为主键的字段,不可取消选中且不可为空。
仅支持对已选中不可为空的字段做取消选中不可为空的操作。
存储配置
支持编辑生命周期,填写要求与创建离线物理表时一致。
MaxCompute外部表
页签
描述
基本信息
仅支持编辑表名称和描述,参数填写要求与创建离线物理表时一致。
字段列表
支持编辑、删除已有字段,可添加新字段。字段填写要求与创建离线物理表时一致,当修改字段类型时会生成DDL。
仅支持对已选中不可为空的字段做取消选中不可为空的操作。
存储配置
支持编辑存储地址(Location),参数填写要求与创建离线物理表时一致。
编辑完成后,单击提交。在提交对话框中查看并确认当前建表的SQL语句,确认后单击确定并提交。
说明如果变更中包含删除字段或修改字段类型等操作,须先在MaxCompute侧的项目级设置
setproject odps.schema.evolution.enable=true;。GaussDB(DWS)/AnalyticDB for PostgreSQL计算引擎
页签
描述
基本信息
仅支持编辑表名称、主题域和描述,参数填写要求与创建离线物理表时一致。
字段列表
支持编辑、删除已有字段,可添加新字段。字段填写要求与创建离线物理表时一致,当修改字段类型时会生成DDL。
支持修改字段的不可为空选项。
不支持重新选择主键,如有需要,您可通过编辑表级约束来修改主键。
存储配置
支持编辑表级约束和分布方式,填写要求与创建离线物理表时一致。分区信息可前往资产清单 > 对象详情 > 字段
后续步骤
如果您的开发模式是Dev-Prod模式,则需要发布离线物理表。更多信息,请参见管理发布任务。
如果您的开发模式是Basic模式,提交成功后的离线物理表可在资产目录进行管理。更多信息,请参见。