
对于开源Flink实时计算引擎的实时实例,可在Dataphin中查看运行分析。运行分析不仅可以支持对实时实例信息进行分析、刷新等操作,也可以展示失败次数、反压情况、各Sink的数据输出、Checkpoint失败次数等信息。
权限说明
查看项目的运行分析,需要具备项目空间权限。
查看Apache Flink Dashboard需要填写用户名和密码,支持超级管理员、系统管理员、任务负责人、项目运维负责人查看用户名密码提示信息。
运行分析入口
在Dataphin首页的顶部菜单栏中,选择研发 > 任务运维。
在左侧导航栏选择实例运维 > 实时实例,在实时实例页面中,单击目标实例操作列的
 图标。
图标。
查看运行分析
在运行分析页面您可以查看各指标的运行情况。如下图所示:
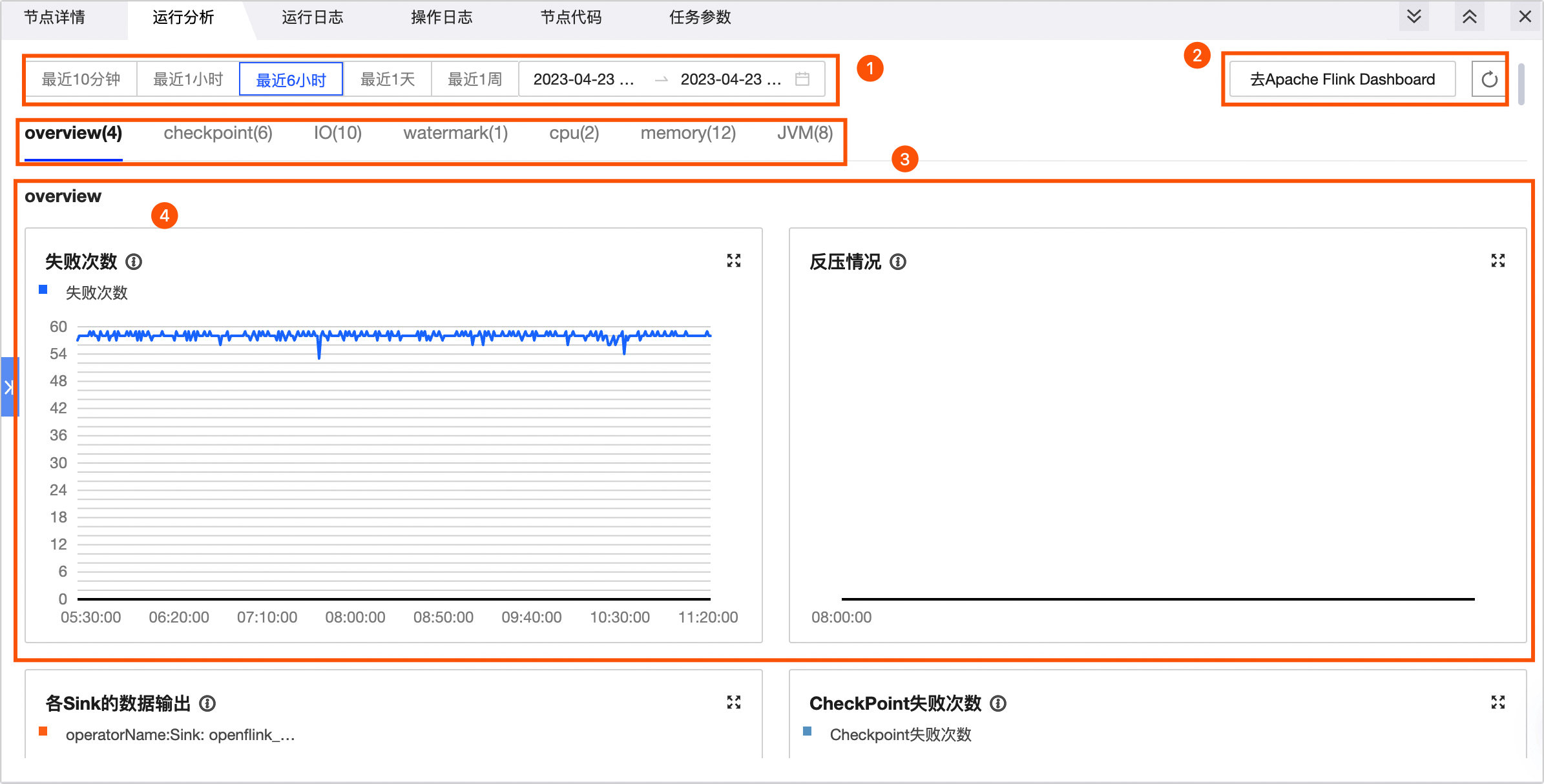
功能 | 描述 |
①时间区域选择 |
|
②去Apache Flink Dashboard与刷新 |
|
③实时监控指标 | Flink SQL或Flink Datastream任务,可查看以下指标:overview、checkpoint、IO、watermark、cpu、memory、JVM。各指标详情,请参见实时监控指标说明。 |
④指标数据统计 | 您可查看各指标在当前时间段内的数据情况。 |
指标统计说明
若所选择的时间区间小于或等于6小时,可查看每分钟采集的所有数据点。
若所选择的时间区间大于6小时且小于等于24小时,可查看从整点开始的每5分钟所采集的数据点,每个数据点为该时间点前5分钟的记数。
若所选择的时间区间大于24小时,可查看从整点开始的每10分钟所采集的数据点,每个数据点为该时间点前10分钟的记数。
实时监控指标说明
overview
监控指标 | 描述 | 单位 |
失败次数 | 当前时间段内任务的失败次数。 | 次数 |
反压情况 | 当前时间段内该任务是否存在反压。当前任务生产数据的速率比下游任务消费数据的速率要快时,将产生反压。 | 是或否 |
各Sink的数据输出 | Sink输出的情况(TPS)。 | 次/秒 |
Checkpoint失败次数 | 当前时间段内任务Checkpoint的失败次数。 | 次数 |
checkpoint
监控指标 | 细分类型 | 描述 | 单位 |
Checkpoint总数 (Num of Checkpoints) | Checkpoint总数 (totalNumberOfCheckpoints) | 当前时间段内任务Checkpoint总数。 | 个 |
失败的Checkpoint总数 (numberOfFailedCheckpoints) | 当前时间段内任务失败的Checkpoint数量。 | 个 | |
已完成的Checkpoint总数 (numberOfCompletedCheckpoints) | 当前时间段内任务已完成的Checkpoint数量。 | 个 | |
正在进行的Checkpoint总数 (numberOfInProgressCheckpoints) | 当前时间段内任务正在进行的Checkpoint数量。 | 个 | |
最近Checkpoint持续时间(lastCheckpointDuration) | 最近一个Checkpoint的持续时间 (lastCheckpointDuration) | 任务最近一个Checkpoint的持续时间。 如果Checkpoint耗时过长或者超时,可能由于状态过大、临时网络原因、Barrier未对齐或者数据存在反压等原因造成。 | 毫秒(ms) |
最近Checkpoint大小 (lastCheckpointSize) | 最近一个Checkpoint的大小 (lastCheckpointSize) | 任务最近一次实际上传的Checkpoint大小,可以在Checkpoint有瓶颈时协助分析Checkpoint性能。 | 字节(Byte) |
IO
监控指标 | 含义 | 监控指标 | 描述 | 单位 |
每秒输入字节总数。 (numBytesIn PerSecond) | 可查看上游流速的输入情况,协助您观察作业流量表现。 | 每秒本地读取数据的字节数 (numBytesInLocal PerSecond) | 每秒本地读取数据的字节数。 | 字节(Byte) |
每秒远端读取数据的字节数 (numBytesInRemote PerSecond) | 每秒远端读取数据的字节数。 | 字节(Byte) | ||
每秒本地读取网络缓冲区数据的字节数 (numBuffersIn Local PerSecond) | 每秒本地读取网络缓冲区数据的字节数。 | 字节(Byte) | ||
每秒远端读取网络缓冲区的数据的字节数 (numBuffersIn Remote PerSecond) | 每秒远端读取网络缓冲区的数据的字节数。 | 字节(Byte) | ||
每秒输出字节总数。 (numBytesOut PerSecond) | 可查看上游吞吐输出情况,协助您观察作业流量表现。 | 每秒输出字节数 (numBytesOut PerSecond) | 每秒输出字节数。 | 字节(Byte) |
每秒输出网络缓冲区的数据的字节数 (numBuffersOut PerSecond) | 每秒输出网络缓冲区的数据的字节数。 | 字节(Byte) | ||
每个Subtask每秒收到和输出的总数据量。 (Task numRecords I/O PerSecond) | 可根据该指标判断作业是否存在I/O瓶颈并且通过速率判断严重程度。 | 每秒接收的记录数 (numRecordsIn PerSecond) | 每秒接收的记录数。 | 个 |
每秒发出的记录数 (numRecordsOut PerSecond) | 每秒发出的记录数。 | 个 | ||
每个Subtask收到和输出的总数据量。 (Task numRecords I/O) | 可根据该指标判断作业是否存在I/O瓶颈。 | 接收的记录总数 (numRecordsIn) | 接收的记录总数。 | 个 |
发出的记录总数 (numRecordsOut) | 发出的记录总数。 | 个 |
watermark
监控指标 | 描述 | 单位 |
每个任务收到最近一个Watermark的时间 (Task InputWatermark) | 每个任务收到最近一个Watermark的时间,说明TM收到数据的延时情况。 | 毫秒(ms) |
cpu
监控指标 | 描述 | 单位 |
单个JM CPU使用率 (JM CPU Load) | 单个JM CPU使用率。如果该值长期大于100%,说明CPU很繁忙,负载很高。这可能会影响系统性能,导致系统卡顿、响应时间过长等问题。 | 个 |
单个TM CPU使用率 (TM CPU Load) | 单个TM CPU使用率。该值反映Flink对CPU时间片的占用情况,1个Core的CPU用满为100%,4个Core用满为400%。如果该值长期大于100%则说明CPU很繁忙。如果负载很高,但CPU使用率却比较低,可能因为频繁的读写操作导致不可中断睡眠状态的进程过多。 | 个 |
memory
监控指标 | 细分类型 | 描述 | 单位 |
JM 堆内存 (JM Heap Memory) | JM 堆内存已使用量 (JM Heap Memory Used) | JM 堆内存已使用量。 | 字节(Byte) |
JM 堆内存已申请量 (JM Heap Memory Committed) | JM 堆内存已申请量。 | 字节(Byte) | |
JM 堆内存最大可用量 (JM Heap Memory Max) | JM 堆内存最大可用量。 | 字节(Byte) | |
JM的非堆内存 (JM NonHeap Memory) | JM 堆外内存已使用量 (JM NonHeap Memory Used) | JM 堆外内存已使用量。 | 字节(Byte) |
JM 堆外内存已申请量 (JM NonHeap Memory Committed) | JM 堆外内存已申请量。 | 字节(Byte) | |
JM 堆外内存最大可用量 (JM NonHeap Memory Max) | JM 堆外内存最大可用量。 | 字节(Byte) | |
TM 堆内存 (TM Heap Memory) | TM 堆内存已使用量 (TM Heap Memory Used) | TM 堆内存已使用量。 | 字节(Byte) |
TM 堆内存已申请量 (TM Heap Memory Committed) | TM 堆内存已申请量。 | 字节(Byte) | |
TM 堆内存最大可用量 (TM Heap Memory Max) | TM 堆内存最大可用量。 | 字节(Byte) | |
TM 堆外内存 (TM NonHeap Memory) | TM 堆外内存已使用量 (TM NonHeap Memory Used) | TM 堆外内存已使用量。 | 字节(Byte) |
TM 堆外内存已申请量 (TM NonHeap Memory Committed) | TM 堆外内存已申请量。 | 字节(Byte) | |
TM 堆外内存最大可用量 (TM NonHeap Memory Max) | TM 堆外内存最大可用量。 | 字节(Byte) |
JVM
监控指标 | 描述 | 单位 |
JM活跃线程总数 (JM Threads) | JM活跃线程总数。JM线程数过多时,会导致占用过大的内存空间,从而降低作业稳定性。 | 个 |
TM活跃线程总数 (TM Threads) | TM活跃线程总数(按 TM 聚合,多个 TM 多条线)。 | 个 |
JM年轻代垃圾回收器运行时间 (JM GC Time) | JM年轻代垃圾回收器运行时间。长时间GC会导致占用过大内存空间,从而影响作业性能。该指标协助您进行作业诊断,排查作业级别的故障原因。 | 毫秒(ms) |
TM年轻代垃圾回收器运行时间 (TM GC Time) | TM年轻代垃圾回收器运行时间。长时间GC会导致占用过大内存空间,从而影响作业性能。该指标协助您进行作业诊断,排查作业级别的故障原因。 | 毫秒(ms) |
JM年轻代垃圾回收器运行次数 (JM GC Count) | JM年轻代垃圾回收器运行次数。GC次数过多会导致占用过大内存空间,从而影响作业性能。该指标协助您进行作业诊断,排查作业级别的故障原因。 | 个 |
TM年轻代垃圾回收器运行次数 (TM GC Count) | TM年轻代垃圾回收器运行次数。GC次数过多会导致占用过大内存空间,从而影响作业性能。该指标协助您进行作业诊断,排查作业Task级别的故障原因。 | 个 |
TM自JVM启动以来已加载的类总数 (TM ClassLoader) | TM自JVM启动以来已加载的类总数。JM所在的JVM创建后加载类的总数或卸载类的总数过大,会导致占用过大内存空间,从而影响作业性能。 | 个 |
JM自JVM启动以来已加载的类总数 (JM ClassLoader) | JM自JVM启动以来已加载的类总数。JM所在的JVM创建后,加载类的总数或卸载类的总数过大,会导致占用过大的内存空间,从而影响作业性能。 | 个 |